Amazon Athena 및 Amazon QuickSight를 활용한 2백년간 글로벌 기후 데이터 시각화
전 세계 기후 변화는 우리의 삶의 질에 심각한 영향을 미치고 있습니다. 이 때문에 향후 지속 가능성에 대한 조사도 증가하고 있습니다. 공공 및 민간 부문의 연구원은 기록된 기후의 역사를 연구하고 기후 예측 모델을 사용하여 미래를 계획하고 있습니다.
이 글은 기후 변화와 그 개념에 대한 설명을 돕기 위해 Global Historical Climatology Network Daily(GHCN-D)를 소개합니다. 그리고, Amazon Web Services(AWS) 서비스가 기후 변화 연구를 위해 어떻게 이 데이터에 대한 액세스를 향상시키는지에 대한 단계별 데모를 제공합니다. 데이터 과학자 및 엔지니어는 이전에 이 데이터를 쿼리하기 위해 고성능 컴퓨터에서 수백 개의 노드에 액세스해야 했습니다. 이제 AWS에서 몇 가지 단계만을 사용하여 동일한 데이터를 얻을 수 있습니다.
글로벌 기후 변화와 분석 현황
글로벌 기후 분석은 연구자가 기후 변화가 지구의 자연 자본과 생태계 자원에 미치는 영향을 분석하기 위해 필수적입니다. 이 활동을 위해서는 양질의 기후 데이터 세트가 필요하며, 이러한 데이터 세트는 규모와 복잡성 때문에 작업이 어려울 수 있습니다. 연구 결과에 확신을 갖기 위해 연구자들은 자신이 활용하는 기후 데이터 세트의 출처를 신뢰할 수 있어야 합니다. 예를 들어, 연구자들은 특정 식량 생산지의 기후가 식량 안보에 영향을 미치는 방식으로 변화했는가라는 질문에 대한 답을 찾고 있을 수 있습니다. 연구자들은 신뢰할 수 있고 정확한 데이터 세트를 쉽게 쿼리할 수 있어야 합니다.
미국의 National Centers for Environmental Information(NCEI)는 전 세계 기상 관측소의 관측에 기초한 기후 데이터로 구성된 데이터 세트를 보유하고 있습니다. 이 데이터 세트가 지상 관측소의 일별 날씨 요약을 위한 중앙 리포지토리인 Global Historical Climatology Network Daily(GHCN-D)입니다. 이 통계는 매일 업데이트되는 수백만 가지의 고품질 관측값으로 구성됩니다.
기록되는 가장 일반적인 파라미터는 일별 기온, 강우량 및 강설량입니다. 이는 가뭄, 홍수 및 극단적 날씨의 위험을 평가하는 데 유용한 파라미터입니다.
문제점
NCEI는 GHCN_D 데이터를 FTP 서버를 통해 CSV 형식으로 이용할 수 있게 연도별로 구성합니다. 데이터를 연도별로 구성하면 아카이브 전체 사본에는 255개가 넘는 파일이 필요합니다(아카이브에 저장된 첫해는 1763년). 과거 방식으로 이 데이터 세트를 작업하고자 할 경우 연구원은 데이터 세트를 다운로드하여 로컬에서 작업해야 합니다. 연구원이 분석을 위해 최신 데이터를 사용하려면 매일 이러한 다운로드를 반복해야 합니다.
연구자 입장에서 이러한 데이터로부터 통찰력을 이끌어내는 것은 어려울 수 있습니다. 기술력, 컴퓨팅 리소스 및 주제 전문 지식이 필요하기 때문에 연구자는 데이터에 완전히 몰두할 수 있어야 합니다.
효율적인 새로운 방식
AWS와 NOAA Big Data Project의 협업을 통해 GHCN_D 데이터 세트의 일별 스냅샷을 AWS에서 사용할 수 있습니다. 해당 데이터를 Amazon S3 버킷을 통해 공개적으로 액세스할 수 있습니다. 자세한 내용은 Registry of Open Data on AWS를 참조하십시오.
이러한 방법으로 데이터를 사용할 수 있게 됨으로써 얻을 수 있는 이점은 다음과 같습니다.
- 데이터를 사용자 커뮤니티에서 전 세계적으로 사용할 수 있습니다. 사용자는 더 이상 작업을 위해 데이터를 다운로드할 필요가 없습니다. 누구나 동일하고 신뢰할 수 있는 사본으로 작업할 수 있습니다.
- 통찰력을 얻기 위한 시간이 단축됩니다. 연구원은 AWS 서비스를 이용하여 즉시 분석을 시작할 수 있습니다.
- 연구 비용이 절감됩니다. 연구원은 분석이 끝나는 즉시 리소스를 종료할 수 있습니다.
이 블로그 게시물은 Amazon S3, Amazon Athena, AWS Glue 및 Amazon QuickSight를 사용해서 데이터 세트에서 얼마나 빨리 통찰력을 얻을 수 있는지를보여주는 워크플로에 대해 설명합니다.
이 게시물에 소개된 워크플로는 다음과 같은 일반적인 단계를 따릅니다.
- NOAA 버킷에서 데이터 파일을 추출하고 데이터를 테이블로 사용할 수 있게 합니다.
- SQL을 사용하여 테이블에 포함된 데이터를 쿼리합니다.
- 쿼리를 사용하여 테이블을 만들고 프라이빗 Amazon S3 버킷에 테이블을 저장하여 분석 속도를 높이는 방법을 보여줍니다.
- 데이터를 시각화하여 통찰력을 얻습니다.
GHCN_D 데이터 세트 개요
GHCN-D는 전 세계의 기상 관측소로부터 얻은 일별 날씨 요약을 보유한 뛰어난 품질의 데이터 세트입니다. GHCN-D의 속성은 다음과 같습니다.
- 데이터는 다양한 국가 및 국제 네트워크의 기상 관측을 제공하는 약 30개의 출처로부터 통합되어 얻어집니다.
- 미국을 위한 포괄적인 데이터 세트이며 세계 곳곳에 대한 뛰어난 적용 범위를 지닙니다.
- 이 데이터 세트에는 일별 기상 관측 유형이 많이 있지만 대부분은 최대 기온, 최저 기온, 강수량, 강설량 및 눈 두께입니다. 이러한 관측값에는 다음 사항이 포함됩니다.
- 35,000개 이상의 기온 관측소
- 100,000개 이상의 강수량 관측소
- 50,000개 이상의 강설량 또는 눈 두께 관측소
- 단일 레코드에 사용되는 용어에 해당하는 개별 데이텀의 출처는 데이터 세트에 포함됩니다. 각 데이텀에는 품질 제어 플래그가 연결되어 있습니다.
- 데이터 세트는 매일 업데이트됩니다. 역사적 자료에 대해서는 매주 재처리 작업을 진행합니다.
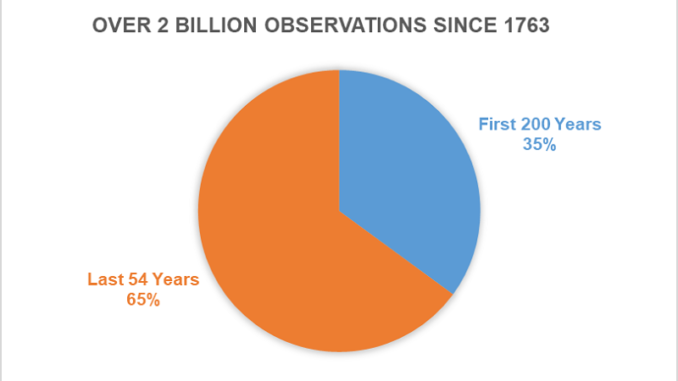
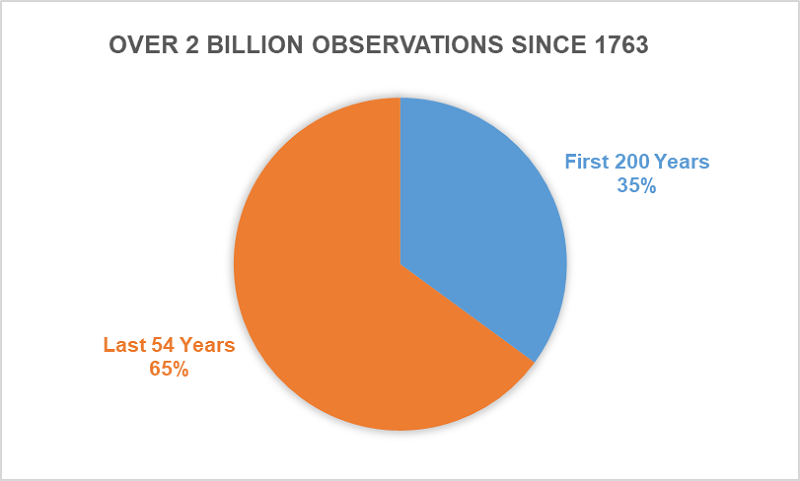
아래의 그래프에서 최근 수십 년간 데이터 볼륨이 어떻게 증가했는지 확인할 수 있습니다.

1763년~2018년. 1763년에는 관측값이 천 개도 되지 않습니다. 2017년에는 3천 4백만 건 이상의 관측값이 있습니다.
Amazon S3내 기후 데이터 구성
앞서 언급했듯이 GHCN-D 데이터 세트는 Amazon S3 버킷을 통해 액세스할 수 있습니다. 데이터 세트의 세부 내용은 Registry of Open Data on AWS(RODA)에 있습니다. RODA의 데이터 세트에 대한 방문 페이지에는 데이터 세트에 대한 매우 다양한 readme 파일에 대한 링크가 포함되어 있습니다. 이 readme에는 모든 찾아보기 테이블과 변수 정의가 포함되어 있습니다.
이 섹션에서는 데이터 세트 작업을 시작하는 데 필요한 관련 정보를 설명합니다.
데이터는 텍스트 또는 쉼표로 구분된 값(CSV) 형식이며 noaa-ghcn-pds라는 Amazon S3 버킷에 저장되어 있습니다.
noaa-ghcn-pds 버킷에는 가상 폴더가 포함되어 있는데 다음과 같이 구성되어 있습니다.
- noaa-ghcn-pds. 이는 두 개의 하위 디렉터리와 여러 유용한 파일이 포함된 버킷의 루트입니다. 이 실습에서는 ghcnd-stations.txt 파일만 사용합니다. 이 파일에는 GHCN_D 데이터 세트에 대한 데이터를 생성한 관측소에 대한 정보가 들어 있습니다. ghcnd-stations.txt 파일을 다운로드해야 합니다.
- noaa-ghcn-pds/csv/. 이 가상 폴더에는 1763년부터 현재까지의 모든 관측치가 .csv 파일로 저장되어 있으며, 매년 1개의 파일이 만들어집니다. 이 실습에서는 이 데이터를 단일 테이블로 비교합니다.
또한 이 실습을 위해 ‘ghcnd-stations.txt’의 데이터와 noaa-ghcn-pds/csv/에 들어있는 데이터가 추출되어 별도의 두 가지 테이블에 추가됩니다. 이러한 테이블은 분석의 기초가 됩니다.
테이블의 레이블 명은 다음과 같습니다.
- tblallyears. 이 테이블에는 1763년부터 현재까지 모든 레코드가 연도 단위의 .csv 파일에 저장되어 있습니다.
- tblghcnd_stations. 이 테이블에는 106,430개 이상의 기상 관측소에 대한 정보를 포함합니다.
관심 지점: 1763년 이후 .csv 파일에는 하나의 기상 관측소에 대한 데이터가 들어 있습니다. 해당 관측소는 이탈리아 밀라노의 중심에 위치해 있었습니다.
AWS 기반 분석 도구 살펴 보기
이 실습에서 일반적인 워크플로를 구현하기 위해 다음과 같은 도구를 사용합니다.
- 분석을 위해 데이터를 준비할 Amazon Simple Storage Service(Amazon S3) GHCN_D 데이터 세트는 Amazon S3의 버킷에 저장됩니다. 또한 프라이빗 버킷을 사용하여 쿼리에서 생성된 새 테이블을 저장합니다.
- Amazon Athena는 표준 SQL을 사용하여 Amazon S3에 저장된 데이터를 쿼리합니다.
- AWS Glue가 Amazon S3 버킷에 저장되어 있는 데이터를 Athena로 데이터를 추출하고 로드합니다. AWS Glue는 완전 관리형 추출, 변환 및 로드(ETL) 서비스입니다.
- AWS Glue Data Catalog는 Athena로 쿼리한 데이터를 카탈로그화합니다.
- Amazon QuickSight를 사용하여 시각화를 구축하고, 임시 분석을 수행하고, 데이터 세트에서 통찰력을 얻을 수 있습니다. Athena의 쿼리 및 테이블은 Amazon QuickSight에서 직접 읽을 수 있습니다. Amazon QuickSight는 Athena의 테이블에 대해 쿼리를 실행할 수도 있습니다.
이 게시물에 설명된 프로세스를 구현하려면 AWS 계정이 필요합니다. AWS 계정 생성에 대한 자세한 내용은 AWS 시작하기를 참조하십시오. 또한 버지니아 북부 AWS 리전에 프라이빗 Amazon S3 버킷도 만들어야 합니다. 자세한 내용은 버킷 만들기를 참조하십시오.
버킷을 만들 때 다음과 같은 빈 디렉터리가 있어야 합니다.
- [your_bucket_name]/stations_raw/
- [your_bucket_name]/ghcnblog/
- [your_bucket_name]/ghcnblog/stations/
- [your_bucket_name]/ghcnblog/allyears/
- [your_bucket_name]/ghcnblog/1836usa/
다음은 이 워크플로에서 다양한 AWS 서비스가 상호 작용하는 방법에 대한 개요입니다.
참고
AWS 서비스는 동일한 AWS 리전에 있습니다. Amazon S3 버킷 중 하나는 GHCN_D 데이터를 저장하고 있는 기존 버킷입니다. 다른 Amazon S3 버킷은 테이블을 저장하기 위해 사용합니다.

이 워크플로를 구성하기 위해 AWS 서비스가 함께 작동하는 방식.
아래 단계에서 콘솔을 사용할 수 있을 뿐만 아니라 AWS 명령줄 인터페이스 또는 여러 언어로 제공되는 소프트웨어 개발자 키트(SDK)를 사용할 수도 있습니다. 또한 Athena에서 작성한 쿼리는 예약된 방식으로 또는 AWS Lambda와 같은 서비스를 사용하여 선택한 트리거에 대응하도록 프로그래밍 할 수도 있습니다.
데이터 분석 워크플로
이제 도구와 데이터를 갖추었고 다음과 같은 작업을 수행할 준비가 되었습니다.
- 연간 .csv 파일을 추출하여 Amazon Athena의 테이블에 추가합니다.
- 관측소 텍스트 파일을 추출하여 Amazon Athena의 별도 테이블에 추가합니다.
연간 .csv 파일을 추출하여 Amazon Athena의 테이블에 추가
일별 기상 관측값의 전체 세트는 연도별로 Amazon S3 버킷의 한 폴더에서 .csv 형식으로 구성됩니다. 데이터에 대한 경로는 s3://noaa-ghcn-pds/csv/입니다.
각 파일의 이름은 1763.csv 처럼 연도명으로 시작되며 한 해에 하나씩 추가되어 현재까지 이름이 지정됩니다.
AWS 콘솔에서 AWS Athena를 클릭합니다. 그러면 Athena의 메인 대시보드로 이동합니다. 여기에서 AWS Glue 데이터 카탈로그를 클릭합니다. AWS Glue로 이동하게 됩니다.
AWS Glue에서 왼편에 있는 테이블 섹션을 선택합니다. 그런 다음, Add table 드롭 다운 메뉴에서 Add table manually를 선택하십시오. 다음과 같은 정보를 추가할 수 있는 일련의 양식이 나옵니다.
- 아래와 같이 테이블 속성을 설정합니다.
- 새로운 테이블 이름(예: tblallyears) 지정
- 데이터베이스 생성 및 ghcnblog로 이름 지정
그러면 데이터베이스가 Athena 대시보드에 나옵니다.
- 데이터 스토어를 추가합니다.
- Specified path in another account 옵션을 선택하고 텍스트 상자에 다음 경로를 입력하십시오. s3://noaa-ghcn-pds/csv/
- 데이터 형식을 선택합니다.
- CSV를 선택한 다음 Comma를 구분 기호로 선택하십시오.
- 스키마를 정의합니다.
- 다음 열을 문자열 변수로 추가합니다.
- id
- year_date
- element
- data_value
- m_flag
- q_flag
- s_flag
- obs_time
- 다음 열을 문자열 변수로 추가합니다.
변수 및 데이터 구조에 대한 자세한 설명은 readme 파일을 참조하십시오.
- OK와 Finish를 순서대로 선택합니다.
이제 Athena 대시보드로 돌아가서 작성한 데이터베이스를 선택합니다. 테이블이 왼쪽의 테이블 목록에 보여집니다. 이제 테이블 오른쪽의 ‘Preview table’ 옵션을 선택하여 데이터를 미리 확인할 수 있습니다.
CTAS를 이용한 쿼리 속도 향상
마지막 단계로 CREATE TABLE AS SELECT(CTAS)라는 SQL문을 사용하여 테이블을 작성합니다. 프라이빗 Amazon S3 버킷에 테이블을 저장합니다.
이 단계를 통해 쿼리 속도가 크게 향상됩니다. 이 프로세스에서 데이터를 한 번 추출하고, 추출한 데이터를 프라이빗 Amazon S3 버킷에 열 형식(Parquet)으로 저장하기 때문입니다.
다음 두 가지 예제를 통해 속도 향상을 설명할 수 있습니다.
- 고유한 기상 관측소를 의미하는 고유 ID를 모두 계산하는 쿼리는 약 55초 동안 약 88GB의 데이터를 스캔합니다.
- 변환된 데이터에 대한 동일한 쿼리는 약 13초 동안 약 5GB의 데이터를 스캔합니다.
이 마지막 단계에서 테이블을 생성하기 위해 다음을 수행합니다.
- Athena 콘솔을 엽니다.
- 대시보드에서 New query를 선택한 다음, 아래 예제와 같은 쿼리를 입력합니다. 버킷 이름과 같이 특정 상황에 적용할 수 있는 정보를 입력해야 합니다.
- 데이터 형식이 Parquet인지 확인하십시오.
- 테이블 이름을 tblallyears_qa로 지정합니다.
- 프라이빗 Amazon S3 버킷에서 다음 경로를 이 폴더에 추가합니다. [your_bucket_name]/ghcnblog/allyearsqa/. your_bucket_name을 특정한 버킷 이름으로 바꿉니다.
새 테이블은 Athena 대시보드의 왼쪽에 나열된 데이터베이스에 나옵니다. 이 테이블을 앞으로 진행하면서 계속 사용할 것입니다.
관측소 텍스트 파일을 추출하여 Amazon Athena의 별도 테이블에 추가
관측소 텍스트 파일에는 위치, 국적 및 ID와 같은 기상 관측소에 대한 정보가 들어 있습니다. 이 데이터는 연간 관측값과는 별개의 파일로 보관됩니다. 날씨 관측값의 지리적 분포를 확인하기 위해 이 데이터를 가져와야 합니다. 이 파일을 다루는 작업은 좀 더 복잡하지만 이 데이터를 Athena로 가져오는 단계는 앞서 수행한 작업과 유사합니다.
이 데이터를 Athena로 가져오기 위해서는 다음을 수행합니다.
- ghcnd-stations text 파일을 다운로드합니다.
- 스프레드시트 프로그램에서 파일을 열고 폭이 구분된 고정 데이터 가져오기 기능을 사용합니다. 열의 고정 너비는 FORMAT OF “ghcnd-stations.txt” file이라는 섹션의 readme 파일에 설명되어 있습니다.
- 데이터를 성공적으로 가져온 후 스프레드시트를 .csv 텍스트 파일로 저장합니다.
- 새로운 .csv 파일을 [your_bucket_name]/stations_raw/에 복사합니다. your_bucket_name을 특정한 버킷 이름으로 바꿉니다.
- 이 새로운 .csv 파일을 사용하여 이 게시물의 앞부분에서 설명한 AWS Glue의 Add table 프로세스 단계를 따르십시오.
- 다음과 같은 필드 이름을 사용합니다.
- id
- latitude
- longitude
- elevation
- state
- name
- gsn_flag
- hcn_flag
- wmo_id
- 테이블 이름을 tblghcnd_stations라고 지정합니다.
- 다음과 같은 필드 이름을 사용합니다.
- 테이블이 생성되면 이 게시물 앞부분에서 설명한 것처럼 이 테이블에 대한 CREATE TABLE AS SELECT(CTAS) 단계를 수행합니다.
- 새로운 테이블 이름을 tblghcnd_stations라고 지정합니다.
- [your_bucket_name]/ghcnblog/stations/에 새로운 테이블을 저장합니다. your_bucket_name을 특정한 버킷 이름으로 바꿉니다.
GHCN_D의 가장 중요한 두 가지 데이터 세트가 이제 Athena에 있습니다.
다음 섹션에서는 이러한 테이블에 대한 쿼리를 실행하고 Amazon QuickSight를 사용하여 결과를 시각화합니다.
실험 데이터 분석 및 시각화
두 개의 테이블이 생성되었으므로 통찰력을 얻기 위해 쿼리하고 시각화를 수행할 준비가 되었습니다.
실험 데이터 분석
Athena 쿼리 창에서 다음 쿼리를 실행하여 데이터 세트의 크기를 확인합니다.
쿼리 #1: 1763년 이후 관측값의 총 개수:
쿼리 #2: 1763년 이후의 관측소 수 :
지구상 평균 기상 파라미터
다음은 1763년 이후 지구 평균 최고 기온(섭씨), 평균 최저 기온(섭씨) 및 평균 강우량(mm)을 계산하는 쿼리입니다.
쿼리에서 data_value를 String 변수에서 Real 변수로 변환해야 합니다. 또한 기온과 강수량 측정값이 각 단위의 10분의 1이기 때문에 10으로 나누어야 합니다. 이러한 세부 사항 및 구성 요소 코드(TMIB, TMAX 및 PRCP)에 대한 자세한 내용은 readme 파일을 참조하십시오.
이 데이터 세트에서 이와 같이 간단한 쿼리를 실행하고 결과가 정확하다고 수용할 수 있다면 편리할 것입니다.
이전 쿼리는 1763년 이후 전 세계의 기상 관측소가 균일하고 균등하게 분포되어 있다고 가정합니다. 실제로 기상 관측소의 수와 분포는 시간이 지남에 따라 변했습니다.
시간 변화에 따른 기상 관측소 수의 증가를 시각화
다음 쿼리는 Amazon QuickSight를 사용하여 1763년 이후 매년 기상 관측소의 수를 시각화합니다.
참고: 이 단계를 완료하려면 Amazon QuickSight에 가입해야 합니다. 가입 프로세스 중에 Amazon QuickSight 데이터 소스 권한을 관리하라는 메시지가 표시됩니다. 이때 Amazon S3 버킷과 Athena에 액세스 권한을 부여하려면 다음 절차의 3단계를 수행하십시오.
수행할 단계를 다음과 같습니다.
- Amazon QuickSight 콘솔을 엽니다.
- 대시보드의 오른쪽 끝에 있는 Manage QuickSight(QuickSight 관리)를 선택합니다.
- Account Setting(계정 설정)을 선택한 다음 Manage QuickSight permissions(QuickSight 권한 관리)를 선택하십시오. Athena에 액세스하고 새 테이블이 포함된 Amazon S3 버킷을 읽을 수 있도록 Amazon QuickSight 권한을 부여합니다.
- 화면 왼쪽 상단의 로고를 선택하여 Amazon QuickSight로 돌아갑니다.
- Amazon QuickSight 대시보드에서 New analysis(새 분석)를 선택한 다음 New data set(새 데이터 세트)를 선택합니다.
- Create a Data Set(데이터 세트 생성) 타일에서 Athena를 선택합니다. 데이터 소스의 이름을 지정합니다(예: ghcnblog). 그런 다음, Create data source(데이터 출처 작성)를 선택합니다.
- 사용자 지정 SQL을 추가하는 옵션을 선택한 후 다음 예와 같이 SQL을 추가합니다.
- Confirm query(쿼리 확인)을 선택합니다.
- Directly query your data(데이터 직접 쿼리)를 선택합니다.
- Visualize(시각화)를 선택합니다.
- 그래프를 만들려면 꺾은 선형 차트 그래프를 선택하십시오. X축에 year(연도)를 추가하고 Value field wells에 number_of_stations(관측소 수)를 추가합니다. 옵션은 시각화 대시보드의 왼쪽에 나옵니다.

시간 변화에 따라 GHCN_D에서 사용되는 글로벌 기상 관측소의 수.
결과로 얻은 그래프는 전 세계의 관측소 수와 분포가 시간에 따라 변화해왔음을 보여줍니다.
미국의 관측 발전 확인
1836년은 데이터 세트에 첫 번째 미국 관측소가 나오는 해입니다. 미국의 관측 발전에 대한 통찰을 얻기 위해 주요 데이터 출처(tblallyears_qa)에서 미국 데이터의 하위 집합을 추출했습니다. 이 데이터 세트는 1836년부터 2016년까지 30년마다 데이터를 제공합니다.
이 쿼리는 대형 데이터 집합을 생성합니다. 성능을 높이려면 앞에서 설명한 절차에 따라 쿼리를 Amazon S3 버킷에 저장된 테이블로 저장하십시오.
이 작업을 한 단계에서 수행하는 쿼리가 다음 그림에 나옵니다.
이 테이블은 Amazon Athena 대시보드에 tbl1836every30thyear로 표시되며 분석의 기초가 됩니다.
Amazon QuickSight 콘솔에서 다음의 SQL을 사용하여 새로운 데이터 세트를 생성합니다.
- Confirm query(쿼리 확인)을 선택합니다.
- Directly query your data(데이터 직접 쿼리)를 선택합니다.
- Visualize(시각화)를 선택합니다.
그 결과 시각화 대시보드로 돌아갑니다. 이 대시보드에서 Points on a map(맵 위의 점) 시각화를 선택하고 다음과 같이 필드를 설정합니다.
- Geospatial(지역): 주
- Size(크기): number_of_stations(관측소의 수), 개수로 집계
- Color(색상): 연도
그 결과로 다음과 같이 1836년부터 2016년까지 30년 단위로 GHCN_D에서 사용되는 기상 관측소의 증가를 보여주는 미국 지도를 얻게 될 것입니다. 1836년에는 관측소가 하나였습니다. 2016년까지 수천 개로 늘었습니다.

미국 내 관측소 수의 증가.
흥미롭게도 일부 주에서는 1986년보다 1956년에 관측소가 더 많았습니다. 이런 특징은 다음 그림에서도 나옵니다. 그림의 데이터는 이전 데이터 세트에서 도출되었습니다.

이 히트 맵은 시간 변화에 따른 주당 관측소의 수를 보여줍니다. 이것은 30년 단위의 스냅샷입니다.
데이터레이크 내 데이터 확인하기
이제 GHN_D 데이터의 데이터 레이크가 생겼습니다. 어셈블된 도구를 사용하여 데이터를 자유롭게 실험할 수 있습니다. 이제 이 거대한 데이터 세트에서 쿼리와 시각화를 구성하여 통찰력을 얻을 수 있습니다.
다음 그림은 생성된 히트 맵을 보여줍니다. 시간 경과에 따른 미국 주에서의 평균 최저 기온을 보여줍니다. 앞서 예와 마찬가지로 30년 단위의 스냅샷을 볼 수 있습니다. 즉, 30년마다 연간 평균값이 생성됩니다.

이 히트 맵은 시간 경과에 따른 각 주의 최저 기온을 보여줍니다. 1836년부터 시작한 30년마다의 연간 평균.
요약
요즘 뉴스 헤드라인은 기후 변화 및 지속 가능성에 관한 이야기로 가득하며 이에 대한 연구 및 분석의 중요성이 날로 증가하고 있습니다.
이 게시물은 AWS 서비스가 연구원, 분석가 및 과학자가 GHCN_D 데이터 세트를 완전히 사용하는 데 필요한 기술 능력 수준을 어떻게 낮추었는지 설명했습니다.
이 GHCN-D는 AWS에서 사용할 수 있습니다. 자세한 내용은 Registry of Open Data on AWS에서 확인할 수 있습니다. 이 데이터는 기후 변화 및 기후 영향을 연구하는 연구원이 이용할 수 있습니다.
이 블로그 게시물은 연구원이 Amazon Athena, AWS Glue 및 Amazon S3를 통해 중요한 데이터를 분석하는 데 사용할 수 있는 일반적인 워크플로와 Amazon QuickSight를 사용하여 통찰력을 시각화하는 방법을 보여주었습니다.
이러한 데이터를 활용할 수 있게 함으로써 Amazon은 과거에 GHCN_D를 이용하기 위해 요구되었던 무거운 작업 부담을 제거하고 새로운 연구와 발견에 대한 기회를 넓혔습니다.
 Joe Flasher는 Amazon Web Services의 Open Geospatial Data 책임자로 클라우드에서 데이터를 가장 효율적으로 분석할 수 있도록 지원합니다. Joe는 지난 10년간 공동 작업자 및 유지 관리자로서 지형 데이터 및 오픈 소스 프로젝트를 활용해 왔습니다. 그는 Landsat Advisory Group의 회원으로 활동해 왔고 GIS 소프트웨어 제작에서 우주 왕복선 비행에 이르기까지 다양한 프로젝트에 참여했습니다.
Joe Flasher는 Amazon Web Services의 Open Geospatial Data 책임자로 클라우드에서 데이터를 가장 효율적으로 분석할 수 있도록 지원합니다. Joe는 지난 10년간 공동 작업자 및 유지 관리자로서 지형 데이터 및 오픈 소스 프로젝트를 활용해 왔습니다. 그는 Landsat Advisory Group의 회원으로 활동해 왔고 GIS 소프트웨어 제작에서 우주 왕복선 비행에 이르기까지 다양한 프로젝트에 참여했습니다.
 Conor Delaney 박사는 환경 데이터 과학자입니다.
Conor Delaney 박사는 환경 데이터 과학자입니다.
Source: Amazon Athena 및 Amazon QuickSight를 활용한 2백년간 글로벌 기후 데이터 시각화


Leave a Reply