Amazon EC2 고성능 GPU 인스턴스 타입 P4d, 서울 리전 출시
지난해 11월 클라우드에서 기계 학습 모델 훈련 및 고성능 컴퓨팅 애플리케이션을 위해 NVIDIA A100 Tensor Core GPU로 구동되는 Amazon EC2 P4d 인스턴스를 출시하였습니다. 클라우드에서 400Gbps 인스턴스 네트워킹을 지원하는 최초의 인스턴스로서 이전 세대 P3 및 P3dn 인스턴스에 비해 딥 러닝 모델의 평균 2.5 배 더 나은 성능을 포함하여 ML 모델을 훈련하는 데 최대 60 % 낮은 비용을 제공합니다.
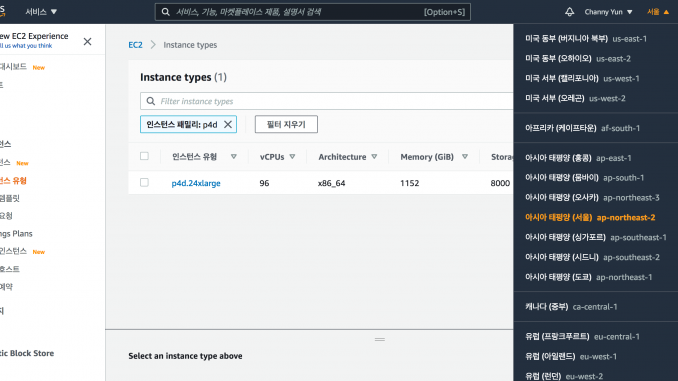
이제 EC2 P4d 인스턴스를 서울 리전에서도 사용할 수 있게 되었습니다. 이를 통해 고성능 기계 학습 모델 학습을 원하는 분들에게 도움이 될 것으로 생각합니다.

이 글에서는 Amazon EC2 P4d Instance Deep Dive 글을 기반으로 현재 기계 학습 워크로드 및 아키텍처에 통합하는 방법에 대해 자세히 설명합니다.
Amazon EC2 P4d 인스턴스에는 총 96 개의 vCPU와 1.1TB의 RAM 및 8TB의 NVMe 로컬 스토리지가 포함 된 듀얼 소켓 Intel Cascade Lake 8275CL 프로세서가 함께 제공됩니다. P4d에는 NVSwitch 및 400Gbps EFA (Elastic Fabric Adapter) 지원 네트워킹이 포함 된 8 개의 40GB NVIDIA Tesla A100 GPU도 제공됩니다. 본 인스턴스 구성은 기계 학습 (ML), 고성능 컴퓨팅 (HPC) 및 분석을 아우르는 고객을위한 최신 컴퓨팅 세대를 나타냅니다.

P4d의 개선 사항 중 하나는 네트워킹 스택에 있습니다. 이 새로운 인스턴스 유형은 EFA 및 GPUDirect RDMA을 지원하는 400Gbps를 제공합니다. 따라서 CPU를 우회하여 지점 간 GPU 대 GPU 통신 (노드 간)을 활용할 수 있습니다.
P4d 인스턴스 사양 및 성능
로컬 임시 NVMe 스토리지
p4d 인스턴스 유형은 8TB의 로컬 NVMe 스토리지와 함께 제공됩니다. 각 장치의 최대 읽기/쓰기 처리량은 2.7GB/s입니다. GPU에 입력 할 로컬 네임 스페이스 및 스테이징 영역을 생성하려면 모든 드라이브의 로컬 RAID 0을 생성 할 수 있습니다. 그 결과 총 읽기 처리량은 약 16GB / s입니다. 다음 표에는 이 구성에서 NVMe 드라이브의 I/O 테스트가 요약되어 있습니다.
| FIO-테스트 | 블록 크기 | 스레드 | 대역폭 | |
| 1 | 순차 읽기 | 128k | 96 | 16.4GiB / s |
| 2 | 순차적 쓰기 | 128k | 96 | 8.2GiB / s |
| 3 | 랜덤 읽기 | 128k | 96 | 16.3GiB / s |
| 4 | 랜덤 쓰기 | 128k | 96 | 8.1GiB / s |
NVSwitch
p4d 인스턴스 유형과 함께 도입 된 NVSwitch입니다. 노드의 모든 GPU는 최대 600GB/s 양방향 대역폭의 풀 메시 토폴로지로 서로 연결됩니다. NVIDIA 통신 집합 라이브러리 (NCCL)를 사용하는 ML 프레임 워크 및 HPC 애플리케이션은이 모든 통신 계층을 최대한 활용할 수 있습니다.


P4d는 다양한 데이터 경로 도메인 (NUMA, PCIe 스위치, NVLink)에서 전체 통신이 가능한 이전 세대 P3/P3dn 인스턴스와 비교하여 최적화 된 전체 통신을 위해 전체 메시 NVLink 토폴로지를 사용합니다. NCCL을 통해 액세스되는이 새로운 토폴로지는 다중 GPU 워크로드의 성능을 향상시킵니다.
NVSwitch를 최적으로 사용하려면 인스턴스에서 모든 GPU 애플리케이션 부스트 클럭이 최대 값으로 설정되었는지 확인합니다.
다중 인스턴스 GPU (MIG)
이제 사용자 수준에서 각 GPU 슬라이스가 서로 분리 된 상태에서 GPU를 여러 GPU 슬라이스로 분할하는 것을 제어 할 수 있습니다. 이를 통해 여러 사용자가 성능에 영향을주지 않고 동일한 GPU에서 서로 다른 워크로드를 실행할 수 있습니다. 다음 단계에서 MIG 구현의 예를 안내합니다.
새로 시작된 모든 인스턴스에서 MIG는 비활성화됩니다. 따라서 다음 명령을 사용하여 활성화해야 합니다.
ubuntu@ip-172-31-34-6:~# sudo nvidia-smi -mig 1
Enabled MIG Mode for GPU 00000000:10:1C.0
지원되는 MIG 프로필 목록을 얻을 수 있습니다.
다음으로 7 개의 슬라이스를 생성하고 각 슬라이스에 대한 컴퓨팅 인스턴스를 생성 할 수 있습니다.
GPU를 최대 7 개의 슬라이스로 분할 할 수 있습니다. GPU를 Docker 컨테이너로 전달하려면 런타임에 인덱스 쌍을 지정할 수 있습니다.
MIG를 사용하면 성능 저하없이 동일한 GPU에서 여러 개의 작은 워크로드를 실행할 수 있습니다. 이 기능을 추가 AWS 서비스와 통합함에 따라이 기능에 대한 추가 블로그를 추가하겠습니다.
EFA를 통한 NVIDIA GPUDirect RDMA
multiGPU 기능에 최적화 된 워크로드를 위해 EFA 패브릭을 통한 GPUDirect를 도입했습니다. 이를 통해 지연 시간을 줄이고 성능을 향상시키기 위해 여러 p4d 노드에서 직접 GPU-GPU 통신이 가능합니다. 아래 코드 샘플은 EFA를 통해 GPUDirect RDMA를 사용하기위한 템플릿으로 사용할 수 있습니다.
P4d를 통한 기계 학습 최적화방법
최신 Deep Learning AMI (DLAMI)를 사용하여 p4d에 대해 앞서 언급 한 모든 이점을 빠르게 시작할 수 있습니다. DLAMI는 이제 CUDA11과 최신 NVLink 및 cuDNN SDK 및 드라이버와 함께 제공되어 p4d를 활용합니다.
TensorFloat32 – TF32
TF32는 p4d.24xlarge 인스턴스에 처음으로 도입 된 NVIDIA의 새로운 19 비트 정밀도 데이터 유형입니다. 이 데이터 유형은 대부분의 주류 모델에 대한 훈련 및 검증 정확도의 손실이 거의 또는 전혀없이 성능을 향상시킵니다. 개별 알고리즘에 대한 더 자세한 벤치 마크가 있습니다. (그러나 p4d.24xlarge에서는 주요 딥 러닝 모델에 대해 p3dn.24xlarge의 FP32에 비해 약 2.5 배 증가 할 수 있습니다.)
여기 에서 기계 학습 모델을 업데이트 하여 일반 DNN 및 Bert를 포함하여 오늘날 고객이 사용하는 인기 알고리즘의 예 (다음 차트 참조)를 보여줍니다.
| DNN | P3dn FP32 (imgs / sec) | P3dn FP16 (imgs / sec) | P4d 처리량 TF32 (imgs / sec) | P4d 처리량 FP16 (imgs / sec) | p3dn TF32 / FP32를 통한 P4d | P3dn FP16을 통한 P4d |
| Resnet50 | 3057 | 7413 | 6841 | 15621 | 2.2 | 2.1 |
| Resnet152 | 1145 | 2644 | 2823 | 5700 | 2.5 | 2.2 |
| Inception3 | 2010 | 4969 | 4808 | 10433 | 2.4 | 2.1 |
| Inception4 | 847 | 1778 | 2025 | 3811 | 2.4 | 2.1 |
| VGG16 | 1202 | 2092 | 4532 | 7240 | 3.8 | 3.5 |
| Alexnet | 32198 | 50708 | 82192 | 133068 | 2.6 | 2.6 |
| SSD300 | 1554 | 2918 | 3467 | 6016 | 2.2 | 2.1 |
BERT Large – Wikipedia / Books Corpus
| GPU | 시퀀스 길이 | 배치 크기 / GPU : 혼합 정밀도, TF32 | Gradient Accumulation : 혼합 정밀도, TF32 | 처리량 – 혼합 정밀도 | P4d / p3dn 혼합 정밀 속도 향상 | P4d / p3 혼합 정밀 속도 향상 |
| 1 | 128 | 64,64 | 1024,1024 | 372 | 2.2 | 2.8 |
| 4 | 128 | 64,64 | 256,256 | 1493 | 2 | 3.3 |
| 8 | 128 | 64,64 | 128,128 | 2936 | 2.1 | 2.9 |
| 1 | 512 | 16,8 | 2048,4096 | 77 | 2.6 | 2.6 |
| 4 | 512 | 16,8 | 512,1024 | 303 | 2.6 | 2.7 |
| 8 | 512 | 16,8 | 256,512 | 596 | 2.4 | 3.1 |
다른 코드 예제는 github.com/NVIDIA/DeepLearningExamples 에서 찾을 수 있습니다.
자체 AMI를 구축하거나 조직에서 유지 관리하는 AMI를 확장하려는 경우 Packer 스크립트를 제공하는 github repo를 사용하여 Amazon Linux 2 또는 Ubuntu 18.04 버전 용 AMI를 구축 할 수 있습니다.
스택에는 다음 구성 요소가 포함됩니다.
- NVIDIA 드라이버 450.80.02
- CUDA 11
- NVIDIA Fabric Manager
- cuDNN 8
- NCCL 2.7.8
- EFA 최신 드라이버
- AWS-OFI-NCCL
- FSx 커널 및 클라이언트 드라이버 및 유틸리티
- 인텔 OneDNN
- NVIDIA 런타임 Docker
Amazon P4d 인스턴스 를 Amazon EKS , AWS Batch 및 Amazon Sagemaker 등에서도 사용 가능합니다.더 자세한 것은 아래 블로그 글을 참고하세요.
- Deploying managed P4d Instances in Amazon Elastic Kubernetes Service with NVIDIA GPUDirectRDMA
- Utilizing NVIDIA Multi-Instance GPU (MIG) in Amazon EC2 P4d Instances on Amazon Elastic Kubernetes Service (EKS)
한국 고객은 온 디맨드 인스턴스, 예약 인스턴스, 스팟 인스턴스, 전용 호스트 또는 Savings Plan의 일부로 P4d 인스턴스를 구매할 수 있습니다. 도입 문의나 질문이 있는 경우, EC2 P4d 담당자에게 알려주시기 바랍니다.
– Channy(윤석찬)


Leave a Reply