Amazon File Cache 정식 출시 – AWS 기반 온프레미스 파일 시스템용 고성능 캐시
오늘 온프레미스를 포함하여 서로 다른 위치에 저장된 파일 데이터를 처리하도록 설계한 AWS의 새로운 고속 캐시 서비스인 Amazon File Cache의 정식 출시합니다.
Amazon File Cache는 원본 파일이 액세스 가능한 파일 시스템의 온프레미스에 있든 관계없이 빠르고 친숙한 POSIX 인터페이스를 사용하여 애플리케이션이 파일에 액세스할 수 있게 해서 가장 까다로운 클라우드 버스팅 및 하이브리드 워크플로를 가속화 및 단순화합니다. NFS v3 또는 Amazon Simple Storage Service(S3)에서 사용할 수 있습니다.
온프레미스 스토리지 인프라에 대량의 데이터 세트가 있고 월말 보고서를 실행하는 데 보통 2~3일이 소요된다고 가정해 보겠습니다. 가끔 발생하는 워크로드를 클라우드로 옮겨 처리 시간을 줄이기 위해 CPU와 메모리가 더 많은 대형 시스템에서 실행해야 합니다. 하지만 아직 데이터 세트를 클라우드로 이전할 준비가 되지 않았습니다.
여러 리전에 분산되어 있는 Amazon Simple Storage Service(S3)의 대규모 데이터 세트에 액세스할 수 있는 또 다른 시나리오를 상상해 보십시오. 이 데이터 세트를 활용하려는 애플리케이션은 기존(POSIX) 파일 시스템 액세스를 위해 코딩되며 awk, sed, pipes 등과 같은 명령줄 도구를 사용합니다. 애플리케이션에는 지연 시간이 1밀리초 미만인 파일 액세스가 필요합니다. S3 API를 사용하도록 소스 코드를 업데이트할 수 없습니다.
File Cache는 이러한 사용 사례와 다른 사례, 즉 비디오 파일, AI/ML 데이터 세트 등의 관리 및 변환에 대해 생각해 보는 데에 유용합니다. File Cache는 NFS v3 파일 시스템 또는 리전 하나 이상의 S3 버킷 앞에 파일 시스템 기반 캐시를 생성합니다. 오리진에서 파일 콘텐츠 및 메타데이터(예: 파일 이름, 크기, 권한)를 투명하게 로드하여 애플리케이션에 기존 파일 시스템으로 제공합니다. File Cache는 최근에 덜 사용한 캐시된 파일을 자동으로 릴리스하여 애플리케이션 캐시에 가장 많이 사용하는 파일을 이용할 수 있도록 합니다.
최대 8개의 NFS 파일 시스템 또는 8개의 S3 버킷을 캐시에 연결할 수 있고, 해당 내용은 통합된 파일 및 디렉토리 세트로 표시됩니다. 가상 머신 또는 컨테이너 등의 다양한 AWS 컴퓨팅 서비스에서 캐시에 액세스할 수 있습니다. File Cache와 온프레미스 인프라 간의 연결은 AWS Direct Connect 및/또는 사이트 간 VPN을 기반으로 하는 기존 네트워크 연결을 사용합니다.
File Cache를 사용하면 애플리케이션에서 1밀리초 미만의 일관된 지연 시간, 최대 수백 GB/s의 스루풋, 초당 최대 수백만 건의 작업 등의 이점을 누릴 수 있습니다. Amazon Elastic Block Store(Amazon EBS) 등의 다른 스토리지 서비스와 마찬가지로 성능은 캐시 크기에 따라 달라집니다. 캐시 크기는 최소 1.2TiB로 페타바이트 규모로 확장할 수 있습니다.
Amazon File Cache 작동 방식
작동 방식을 보여 드리기 위해 두 개의 기존 Amazon FSx for OpenZFS 파일 시스템에 파일 캐시를 생성합니다. 실제 시나리오에서는 온프레미스 파일 시스템에 캐시를 만들 가능성이 높습니다. 온프레미스 데이터 센터를 가지고 있지 않기 때문에 데모용 FSx for OpenZFS를 선택했습니다. 두 데모 OpenZFS 파일 시스템 모두 내 AWS 계정의 프라이빗 서브넷에서 액세스할 수 있습니다. 마지막으로 EC2 Linux 인스턴스에서 캐시에 액세스합니다.
시작하려면 브라우저를 열고 AWS Management Console로 이동합니다. 콘솔 검색 창에서 “Amazon FSx”를 검색하고 왼쪽 탐색 메뉴에서 캐시를 클릭합니다. 또는 콘솔의 File Cache 섹션으로 직접 이동합니다. 시작하려면 캐시 생성을 선택합니다.
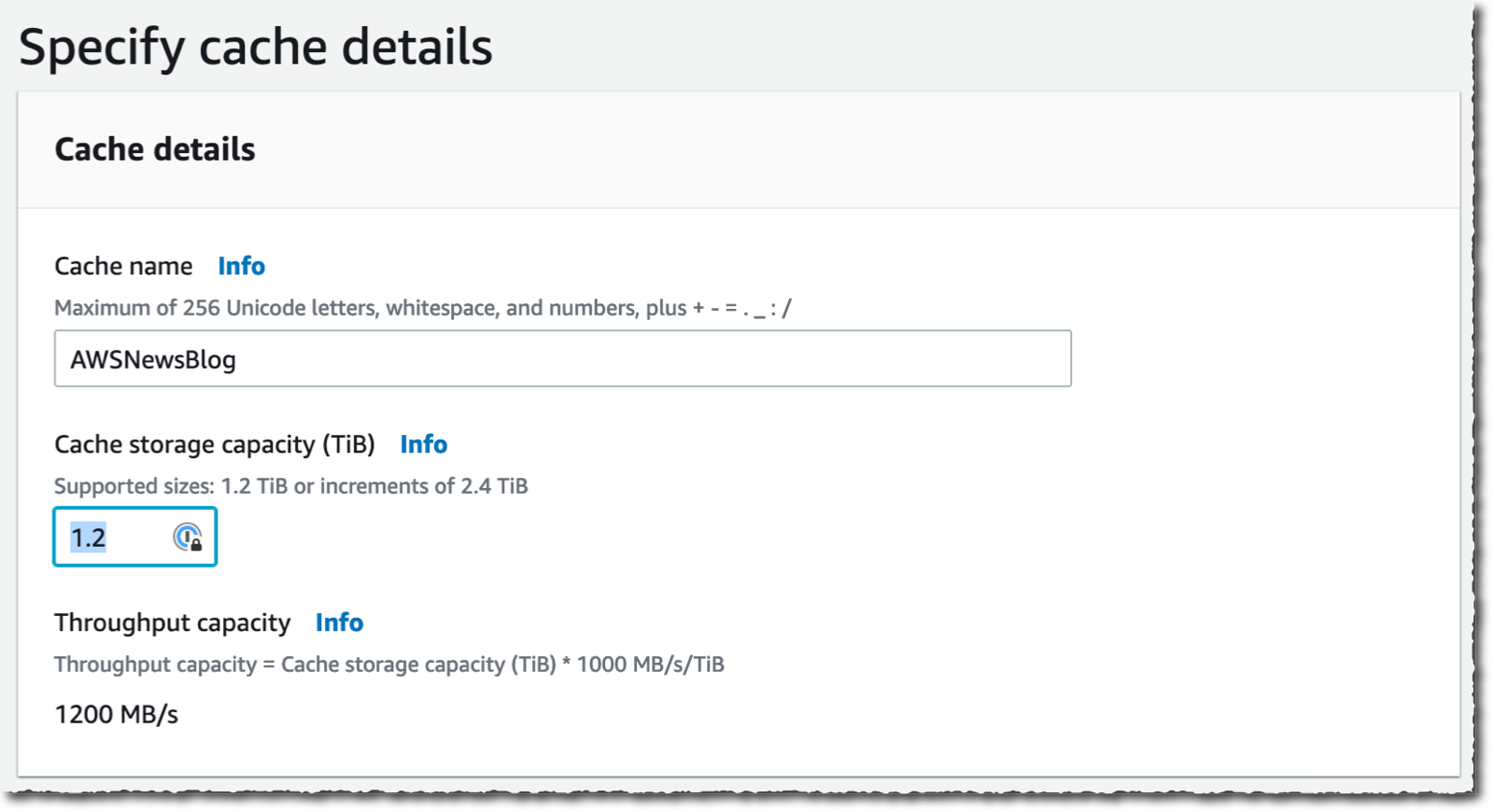
 내 캐시의 캐시 이름(이 데모에 대한 AWSNewsBlog) 및 캐시 스토리지 용량을 입력합니다. 스토리지 용량은 테비바이트로 표시됩니다. 최소값은 1.2TiB 또는 2.4TiB 증분값입니다. 큰 캐시 크기를 선택하면 처리량 용량이 증가하는 것을 알 수 있습니다.
내 캐시의 캐시 이름(이 데모에 대한 AWSNewsBlog) 및 캐시 스토리지 용량을 입력합니다. 스토리지 용량은 테비바이트로 표시됩니다. 최소값은 1.2TiB 또는 2.4TiB 증분값입니다. 큰 캐시 크기를 선택하면 처리량 용량이 증가하는 것을 알 수 있습니다.
 네트워킹 및 암호화에 제공한 기본값을 확인 및 수락합니다. 네트워킹의 경우 캐시 네트워크 인터페이스에 연결할 VPC, 서브넷 및 보안 그룹을 선택할 수 있습니다. 파일 액세스 시 지연 시간을 최소화하려면 컴퓨팅 서비스와 동일한 서브넷에 캐시를 배포하는 것이 좋습니다. 암호화의 경우 AWS KMS 관리 키(기본값)를 사용하거나 자체 키를 선택할 수 있습니다.
네트워킹 및 암호화에 제공한 기본값을 확인 및 수락합니다. 네트워킹의 경우 캐시 네트워크 인터페이스에 연결할 VPC, 서브넷 및 보안 그룹을 선택할 수 있습니다. 파일 액세스 시 지연 시간을 최소화하려면 컴퓨팅 서비스와 동일한 서브넷에 캐시를 배포하는 것이 좋습니다. 암호화의 경우 AWS KMS 관리 키(기본값)를 사용하거나 자체 키를 선택할 수 있습니다.
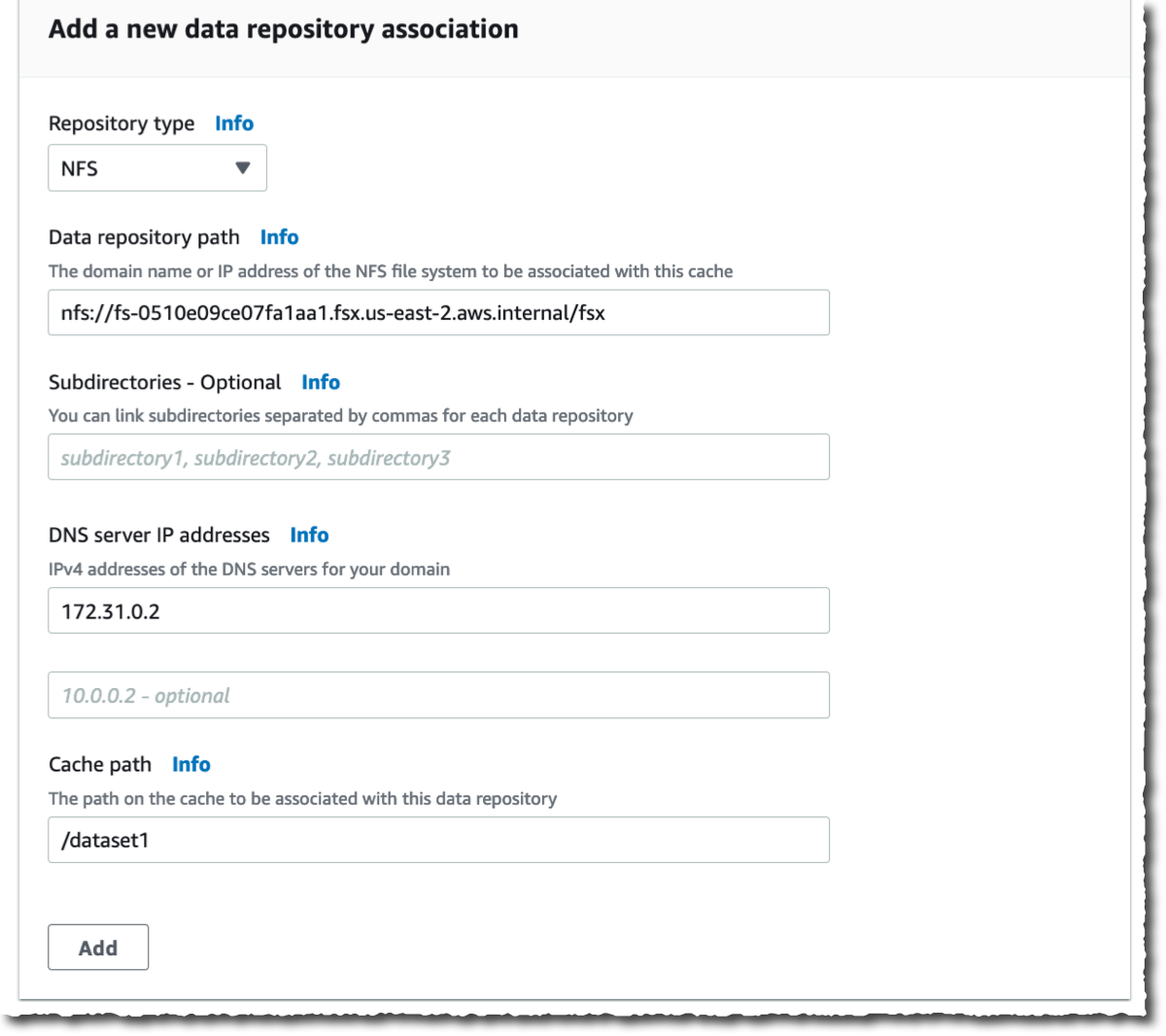
그런 다음 데이터 리포지토리 연결을 생성합니다. 이것은 캐시와 데이터 소스 간의 링크입니다. 데이터 소스는 NFS 파일 시스템이나 S3 버킷 또는 접두사일 수 있습니다. 하나의 캐시에 대해 최대 8개의 데이터 리포지토리 연결을 생성할 수 있습니다. 캐시에 대한 모든 데이터 리포지토리 연결의 유형은 동일합니다. 모두 NFS v3이거나 모두 S3입니다. 둘 다 필요하다면 두 개의 캐시를 생성할 수 있습니다.
이 데모에서는 AWS 계정에 두 개의 OpenZFS 파일 시스템을 연결하기로 했습니다. 이미 온프레미스에 있는 서버를 포함하여 모든 NFS v3 서버에 연결할 수 있습니다. 캐시 경로를 사용하면 소스 파일 시스템을 캐시에서 마운트할 위치를 선택할 수 있습니다. 데이터 리포지토리 경로는 NFS v3 또는 S3 데이터 리포지토리의 URL입니다. 형식은 nfs://hostname/path 또는 s3://bucketname/path입니다.
DNS 서버 IP 주소를 사용하면 File Cache가 NFS 서버의 DNS 이름을 확인할 수 있습니다. 이는 제 예시처럼 DNS 확인이 비공개일 때 유용합니다 VPC에 배포한 NFS v3 서버를 연결하고, AWS에서 제공하는 DNS 서버를 사용하는 경우 VPC의 DNS 서버 IP 주소는 VPC 범위 + 2입니다. 제 예시에서 VPC CIDR 범위는 172.31.0.0이므로 DNS 서버 IP 주소는 172.31.0.2입니다.
추가 버튼을 클릭하는 것을 잊지 마십시오! 그렇지 않으면 입력이 무시됩니다. 작업을 반복하여 더 많은 데이터 리포지토리를 추가할 수 있습니다.
 |
 |
두 개의 데이터 리포지토리에 들어갔으면 다음을 선택하고 선택한 내용을 검토합니다. 준비가 되면 캐시 생성을 선택합니다.

몇 분 후 캐시 상태가  사용 가능으로 변경됩니다.
사용 가능으로 변경됩니다.

마지막 부분은 워크로드가 배포된 머신에 캐시를 마운트하는 것입니다. File Cache는 씬 뒤에서 Lustre를 사용합니다. 설명서에 설명된 대로 우선 Linux용 Lustre 클라이언트를 설치해야 합니다. 완료되면 콘솔에서 연결 버튼을 선택하여 Lustre 클라이언트를 다운로드 및 설치하고, 캐시 파일 시스템을 마운트하는 지침을 받습니다. 이를 위해 동일한 VPC에서 실행 중인 EC2 인스턴스에 연결합니다. 그런 다음 다음을 입력합니다.
이를 위해 동일한 VPC에서 실행 중인 EC2 인스턴스에 연결합니다. 그런 다음 다음을 입력합니다.
sudo mount -t lustre -o relatime,flock file_cache_dns_name@tcp:/mountname /mnt이 명령은 두 가지 옵션을 사용하여 캐시를 마운트합니다.
relatime–atime(inode 액세스 시간) 데이터를 유지하지만 파일에 액세스한 각 시간을 유지하지는 않습니다. 이 옵션을 활성화하면atime데이터는atime데이터가 마지막으로 업데이트되거나(mtime) 또는 해당 파일에 대한 마지막 액세스가 특정 기간 이전일 때(기본값은 하루)에 한하여 수정됩니다.relatime은 적절한 작업을 위한 자동 캐시 제거가 필요합니다.flock– 캐시에 대한 파일 잠금을 활성화합니다. 파일 잠금을 활성화하지 않으려면 flock 없이 mount 명령을 사용합니다.
일단 탑재하면 내 EC2 인스턴스에서 실행되는 프로세스는 평소처럼 캐시에 있는 파일에 액세스할 수 있습니다. 캐시 생성 시 정의한 대로 첫 번째 ZFS 파일 시스템은 /dataset1의 캐시 내에서 사용할 수 있고, 두 번째 ZFS 파일 시스템은 /dataset2로 사용할 수 있습니다.
$ echo "Hello File Cache World" > /mnt/zsf1/greetings
$ sudo mount -t lustre -o relatime,flock fc-0280000000001.fsx.us-east-2.aws.internal@tcp:/r3xxxxxx /mnt/cache
$ ls -al /mnt/cache
total 98
drwxr-xr-x 5 root root 33280 Sep 21 14:37 .
drwxr-xr-x 2 root root 33280 Sep 21 14:33 dataset1
drwxr-xr-x 2 root root 33280 Sep 21 14:37 dataset2
$ cat /mnt/cache/dataset1/greetings
Hello File Cache World
Amazon CloudWatch 지표와 AWS CloudTrail 로그 모니터링을 사용하여 캐시의 활동과 상태를 관찰 및 측정할 수 있습니다.
File Cache 리소스에 대한 CloudWatch 지표는 다음 세 가지 범주로 구성됩니다.
- 프런트엔드 I/O 지표
- 백엔드 I/O 지표
- 캐시 프론트엔드 사용률 지표
평소처럼 지표가 대시보드를 생성하거나 또는 지표가 정의한 임계값에 도달할 때 알림을 받을 임계값을 정의할 수 있습니다.
주의 사항
File Cache를 사용하거나 사용할 예정일 때 염두에 두어야 할 몇 가지 주요 사항이 있습니다.
먼저, File Cache는 저장 데이터를 암호화하고 전송 중 데이터의 암호화를 지원합니다. 저장 데이터는 항상 AWS Key Management Service(AWS KMS)에서 관리하는 키를 사용하여 암호화합니다. 서비스 소유 키 또는 자체 키(고객 관리형 CMK)를 사용할 수 있습니다.
둘째, File Cache는 데이터 리포지토리에서 캐시로 데이터를 가져오는 두 가지 옵션, 즉 지연 로드 및 사전 로드를 제공합니다. 지연 로드는 아직 캐시되지 않은 경우 요청 시 데이터를 가져오고, 사전 로드는 워크로드를 시작하기 전 사용자 요청 시 데이터를 가져옵니다. 지연 로딩이 기본값입니다. 메타데이터와 데이터를 캐시로 가져올 때까지 기다리지 않고 워크로드를 시작할 수 있으므로 대부분의 워크로드에 적합합니다. 사전 로드는 액세스 패턴이 첫 바이트 지연 시간에 민감한 경우에 유용합니다.
요금 및 가용성
File Cache를 사용할 때는 선결제 비용이나 고정 요금이 없습니다. 프로비저닝된 캐시 스토리지 용량과 메타데이터 스토리지 용량에 따라 요금이 청구됩니다. 세부 정보는 요금 페이지에서 확인할 수 있습니다. File Cache 자체뿐만 아니라 S3 요청 비용, AWS Direct Connect 요금 및 파일 캐시와 데이터 소스 간의 AZ 간, 리전 간 및 인터넷 송신 트래픽에 대한 일반적인 데이터 전송 요금을 지불합니다.
File Cache는 미국 동부(오하이오), 미국 동부(버지니아 북부), 미국 서부(오레곤), 아시아 태평양(싱가포르), 아시아 태평양(시드니), 아시아 태평양(도쿄), 캐나다(중부), 유럽(프랑크푸르트), 유럽(아일랜드) 및 유럽(런던) 리전에서 정식 출시되었습니다.
지금 바로 첫 번째 File Cache를 생성해 보십시오!
Source: Amazon File Cache 정식 출시 – AWS 기반 온프레미스 파일 시스템용 고성능 캐시


Leave a Reply