Amazon MemoryDB for Redis 소개 – Redis 호환 높은 내구성의 인-메모리 데이터베이스 서비스
대화형 애플리케이션은 매우 신속하게 요청을 처리하고 대응해야 합니다. 이러한 요구 사항은 아키텍처의 모든 구성 요소까지 확장됩니다. 마이크로서비스를 채택하고 아키텍처가 서로 통신하는 많은 소규모 독립 서비스로 구성된 경우라면 더욱 중요합니다.
이러한 이유로 데이터베이스 성능은 애플리케이션의 성공에 매우 큰 역할을 합니다. 읽기 대기 시간을 마이크로초 단위로 줄이기 위해 인 메모리 캐시를 내구성이 뛰어난 데이터베이스 앞에 놓을 수 있습니다. 캐싱을 위해 많은 개발자가 오픈 소스 인 메모리 데이터 구조 저장소인 Redis를 사용합니다. 실제로 Stack Overflow의 2021 개발자 설문조사에 따르면 Redis는 5년 동안 가장 사랑을 받고 있는 데이터베이스입니다.
AWS에서 이 설정을 구현하려는 경우 데이터 손실을 최소화하기 위해 Amazon Aurora 또는 Amazon DynamoDB와 같은 내구성이 뛰어난 데이터베이스 서비스 앞에서 대기 시간이 짧은 캐시로 완전관리형 인 메모리 캐싱 서비스인 Amazon ElastiCache for Redis를 사용할 수 있습니다. 그러나 이 설정을 사용하려면 캐시가 데이터베이스와 동기화되도록 애플리케이션에 사용자 지정 코드를 도입해야 합니다. 또한, 캐시와 데이터베이스를 모두 실행하는 데 드는 비용도 발생합니다.
Amazon MemoryDB for Redis 소개
오늘 저는 Redis와 호환되고 내구성이 뛰어난 인 메모리 데이터베이스인 Amazon MemoryDB for Redis의 정식 출시를 발표하게 되어 기쁩니다. MemoryDB를 사용하면 데이터 내구성 및 고가용성을 갖춘 마이크로초 읽기 및 한 자릿수의 밀리초 쓰기 성능이 필요한 애플리케이션을 쉽고 비용 효율적으로 구축할 수 있습니다.
이제는 내구성이 뛰어난 데이터베이스 앞에 대기 시간이 짧은 캐시를 사용하는 대신, 아키텍처를 단순화하고 MemoryDB를 하나의 기본 데이터베이스로 사용할 수 있습니다. MemoryDB를 사용하면 모든 데이터가 메모리에 저장되므로 대기 시간이 짧고 처리량이 높은 데이터 액세스가 가능합니다. MemoryDB는 여러 가용 영역(AZ)에 데이터를 저장하는 분산 트랜잭션 로그를 사용하여 높은 내구성으로 빠른 장애 조치, 데이터베이스 복구 및 노드 재시작을 지원합니다.
MemoryDB는 오픈 소스 Redis와의 호환성을 유지하고 친숙한 Redis 데이터 유형, 파라미터 및 명령의 동일한 집합을 지원합니다. 즉, 오픈 소스 Redis에서 이미 현재 사용하고 있는 코드, 애플리케이션, 드라이버 및 도구를 MemoryDB와 함께 사용할 수 있습니다. 개발자는 문자열, 해시, 목록, 집합, 범위 쿼리가 포함된 정렬된 집합, 비트맵, 하이퍼로그 로그, 지형 공간 인덱스 및 스트림과 같은 많은 데이터 구조에 즉시 액세스할 수 있습니다. 또한, 기본 제공 복제, 최소 최근 사용(LRU) 제거, 트랜잭션 및 자동 파티셔닝과 같은 고급 기능에도 액세스할 수 있습니다. MemoryDB는 Redis 6.2와 호환되며, 오픈 소스에서 출시될 때 최신 버전을 지원합니다.
이 시점에서 MemoryDB가 ElastiCache와 어떻게 비교되는지 궁금해할 수 있습니다. 두 서비스 모두 Redis의 데이터 구조와 API에 대한 액세스 권한을 부여하기 때문입니다.
- MemoryDB는 데이터 내구성과 마이크로초 단위의 읽기 및 한 자릿수 밀리초 단위의 쓰기 대기 시간을 제공하기 때문에 애플리케이션에 대한 안전한 프라이머리 데이터베이스가 될 수 있습니다. MemoryDB를 사용하면 대화형 애플리케이션 및 마이크로서비스 아키텍처에 필요한 짧은 대기 시간을 달성하기 위해 데이터베이스 앞에 캐시를 추가하지 않아도 됩니다.
- 반면, ElastiCache는 읽기 및 쓰기 모두에 대해 마이크로초 단위의 대기 시간을 제공합니다. 그래서 기존 데이터베이스에서 데이터 액세스를 가속화하려는 워크로드를 캐싱하는 데 이상적입니다. ElastiCache는 데이터 손실이 허용되는 사용 사례(예: 다른 소스에서 빠르게 데이터베이스를 재구축할 수 있는 경우)에 대한 기본 데이터 스토어로 사용할 수도 있습니다.
Amazon MemoryDB 클러스터 생성
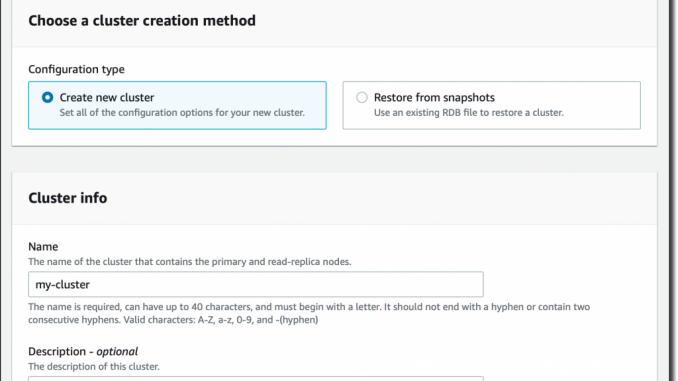
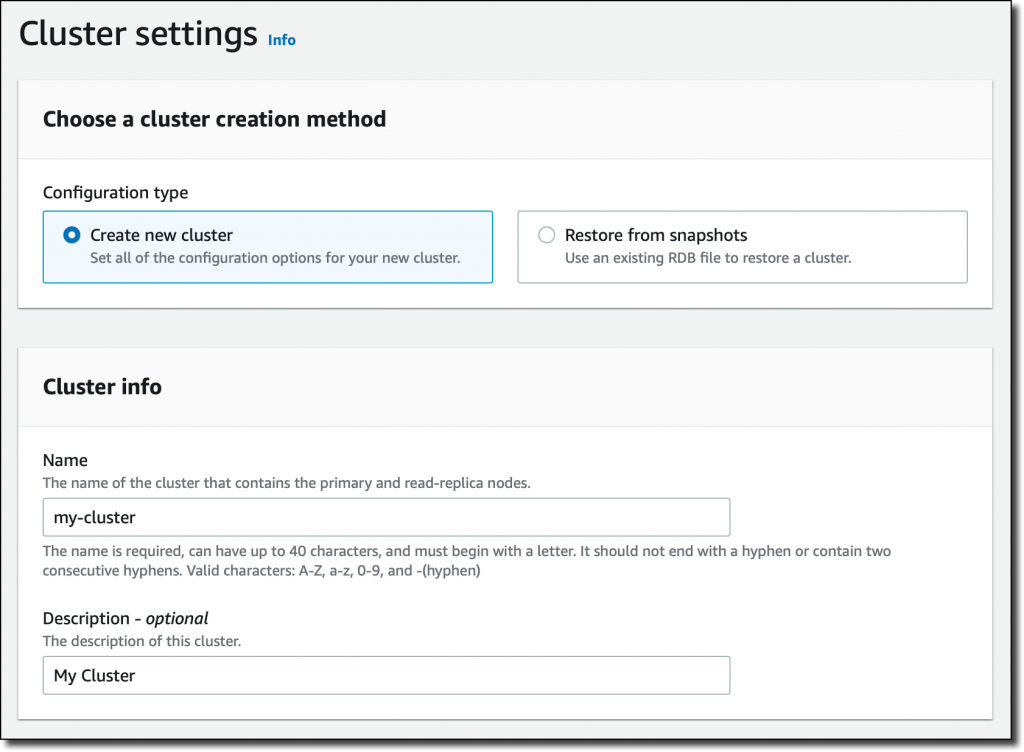
MemoryDB 콘솔에서 왼쪽 탐색 창의 링크를 따라 [클러스터(Clusters)] 섹션으로 이동하고 [클러스터 생성(Create cluster)]을 선택합니다. 그러면 [클러스터 설정(Cluster settings)]이 열리고, 여기에 클러스터에 대한 이름과 설명을 입력합니다.

모든 MemoryDB 클러스터는 Virtual Private Cloud(VPC))에서 실행됩니다. 서브넷 그룹에서 VPC 중 하나를 선택하고 클러스터가 노드를 배포하는 데 사용할 서브넷 목록을 제공하여 서브넷 그룹을 생성합니다.

[클러스터 설정(Cluster settings)]에서 네트워크 포트, 노드 및 클러스터의 런타임 속성을 제어하는 파라미터 그룹, 노드 유형, 샤드 수 및 샤드당 복제본 수를 변경할 수 있습니다. 클러스터에 저장된 데이터는 샤드를 통해 파티셔닝됩니다. 샤드 수와 샤드당 복제본 수에 따라 클러스터의 노드 수가 결정됩니다. 각 샤드에 대해 프라이머리 노드와 복제본이 있으므로, 이 클러스터에는 8개의 노드가 있을 것으로 예상됩니다.
[Redis 버전 호환성(Redis version compatibility)]에서 [6.2]를 선택합니다. 다른 모든 옵션을 기본값으로 두고 [다음(Next)]을 선택합니다.

[고급 설정(Advanced settings)]의 [보안(Security)]에서 서브넷 그룹에 사용한 VPC의 [기본값(default)] 보안 그룹을 추가하고 이전에 생성한 액세스 제어 목록(ACL)을 선택합니다. MemoryDB ACL은 Redis ACL을 기반으로 하며 클러스터에 연결할 수 있는 사용자 자격 증명 및 권한을 제공합니다.
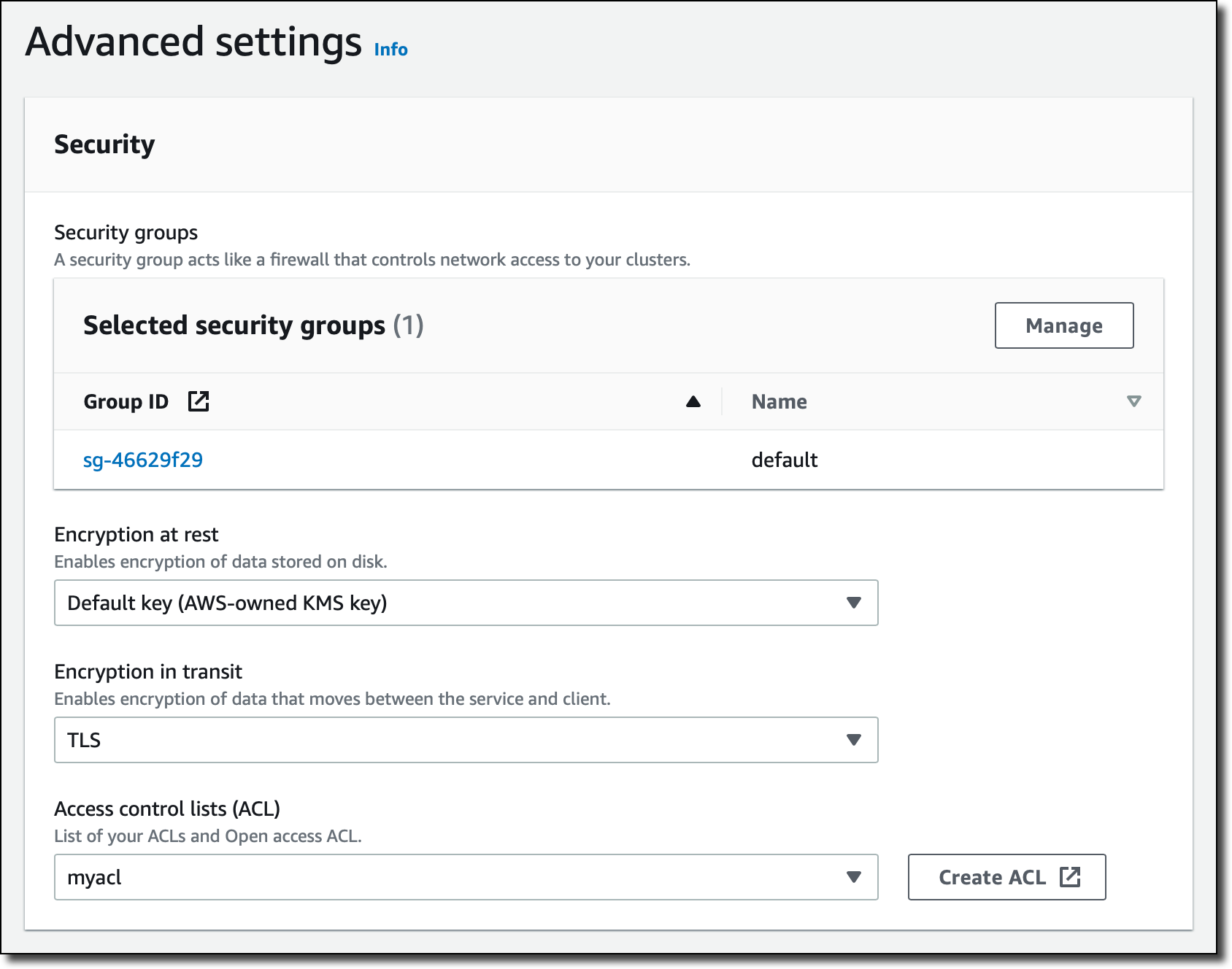
[스냅샷(Snapshot)] 섹션에서 MemoryDB가 자동으로 일일 스냅샷을 생성하고 보존 기간을 7일로 선택하는 기본값을 그대로 유지합니다.

[유지 관리(Maintenance)]에서 기본값을 그대로 두고 [생성(Create)]을 선택합니다. 이 섹션에서 중요한 클러스터 이벤트를 알리도록 Amazon Simple Notification Service(SNS) 주제도 제공할 수 있습니다.
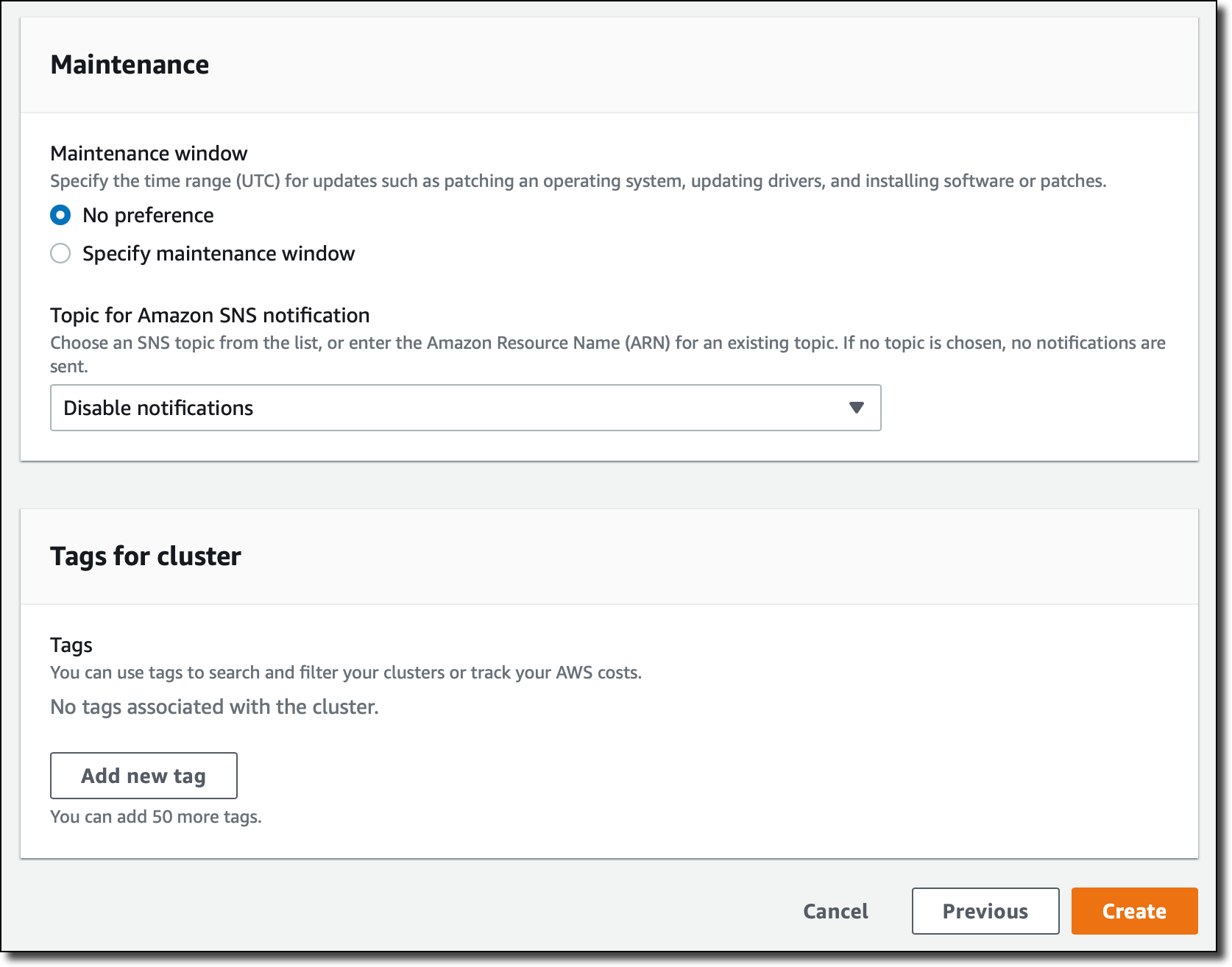
몇 분 후에 클러스터가 실행되며, Redis 명령줄 인터페이스 또는 Redis client를 사용하여 연결할 수 있습니다.
Amazon MemoryDB를 프라이머리 데이터베이스로 사용
고객 데이터 관리는 많은 비즈니스 프로세스의 중요한 구성 요소입니다. 그래서 새 Amazon MemoryDB 클러스터의 내구성을 테스트하기 위해 이를 고객 데이터베이스로 사용하려고 합니다. 간단히 말해서, Python에서 REST API를 사용하여 Redis 클러스터로부터 하나 또는 모든 고객 데이터를 생성, 업데이트 및 삭제하고 이를 가져올 수 있는 간단한 마이크로서비스를 구축해 보겠습니다.
다음은 server.py 구현 코드입니다.
from flask import Flask, request
from flask_restful import Resource, Api, abort
from rediscluster import RedisCluster
import logging
import os
import uuid
host = os.environ['HOST']
port = os.environ['PORT']
db_host = os.environ['DBHOST']
db_port = os.environ['DBPORT']
db_username = os.environ['DBUSERNAME']
db_password = os.environ['DBPASSWORD']
logging.basicConfig(level=logging.INFO)
redis = RedisCluster(startup_nodes=[{"host": db_host, "port": db_port}],
decode_responses=True, skip_full_coverage_check=True,
ssl=True, username=db_username, password=db_password)
if redis.ping():
logging.info("Connected to Redis")
app = Flask(__name__)
api = Api(app)
class Customers(Resource):
def get(self):
key_mask = "customer:*"
customers = []
for key in redis.scan_iter(key_mask):
customer_id = key.split(':')[1]
customer = redis.hgetall(key)
customer['id'] = customer_id
customers.append(customer)
print(customer)
return customers
def post(self):
print(request.json)
customer_id = str(uuid.uuid4())
key = "customer:" + customer_id
redis.hset(key, mapping=request.json)
customer = request.json
customer['id'] = customer_id
return customer, 201
class Customers_ID(Resource):
def get(self, customer_id):
key = "customer:" + customer_id
customer = redis.hgetall(key)
print(customer)
if customer:
customer['id'] = customer_id
return customer
else:
abort(404)
def put(self, customer_id):
print(request.json)
key = "customer:" + customer_id
redis.hset(key, mapping=request.json)
return '', 204
def delete(self, customer_id):
key = "customer:" + customer_id
redis.delete(key)
return '', 204
api.add_resource(Customers, '/customers')
api.add_resource(Customers_ID, '/customers/<customer_id>')
if __name__ == '__main__':
app.run(host=host, port=port)이는 requirements.txt 파일로, 애플리케이션에 필요한 Python 모듈을 나열합니다.
동일한 코드가 MemoryDB, ElastiCache 또는 모든 Redis 클러스터 데이터베이스에서 작동합니다.
MemoryDB 클러스터와 동일한 VPC에서 Linux Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스를 시작합니다. MemoryDB 클러스터에 연결할 수 있도록 [기본값(default)] 보안 그룹을 할당합니다. 또한, 인스턴스에 SSH 액세스 권한을 부여하는 다른 보안 그룹을 추가합니다.
server.py 및 requirements.txt 파일을 인스턴스에 복사한 다음 종속성을 설치합니다.
이제 마이크로서비스를 시작합니다.
다른 터미널 연결에서 curl을 사용하여 /customers 리소스에서 HTTP POST를 사용하여 데이터베이스에서 고객을 생성합니다.
결과로, 데이터가 저장되고 고유 ID(Python 코드에서 생성된 UUIDv4)가 필드에 추가되었음을 확인할 수 있습니다.
모든 필드는 customer:<id> 형식의 키와 함께 Redis Hash에 저장됩니다.
이전 명령을 몇 번 더 반복하여 세 명의 고객을 생성합니다. 고객 데이터는 동일하지만 각 데이터의 ID는 고유합니다.
이제 HTTP GET을 사용하여 /customers 리소스에 대한 모든 고객 목록을 가져옵니다.
코드에는 SCAN 명령을 사용하여 일치하는 키에 반복자가 있습니다. 응답에서 세 고객에 대한 데이터를 볼 수 있습니다.
고객 중 한 명이 방금 모든 잔액을 소비했습니다. ID(/customers/<id>)를 포함하는 고객 리소스의 URL에서 HTTP PUT을 통해 필드를 업데이트합니다.
코드는 Redis Hash의 필드를 요청의 데이터로 업데이트합니다. 이 경우 balance를 0으로 설정합니다. ID별로 고객 데이터를 가져와서 업데이트를 확인합니다.
응답에서 잔액이 업데이트되었음을 알 수 있습니다.
이것이 Redis의 뛰어난 기능입니다! 몇 줄의 코드만으로 마이크로서비스의 골격을 만들 수 있습니다. 또한, MemoryDB는 백엔드에 다른 데이터베이스를 추가하지 않고도 프로덕션에 필요한 내구성과 고가용성을 제공합니다.
워크로드에 따라 노드를 추가 또는 제거하거나 더 크거나 작은 노드 유형으로 이동하여 MemoryDB 클러스터를 각각 수평 또는 수직으로 크기를 조정할 수 있습니다. MemoryDB는 복제본을 추가하여 읽기 크기 조정을 지원하고 샤딩을 통해 쓰기 크기 조정을 지원합니다. 크기 조정 작업 중에 클러스터는 계속 온라인 상태를 유지하고 읽기 및 쓰기 작업을 지원합니다.
가용성 및 요금
Amazon MemoryDB for Redis는 현재 미국 동부(버지니아 북부), EU(아일랜드), 아시아 태평양(뭄바이) 및 남아메리카(상파울루)에서 지원되며, 곧 더 많은 AWS 리전이 추가될 예정입니다.
AWS 관리 콘솔, AWS Command Line Interface(CLI) 또는 AWS SDK를 사용하여 몇 분 안에 MemoryDB 클러스터를 생성할 수 있습니다. AWS CloudFormation 지원도 곧 제공 예정입니다. 노드에 관해 현재 MemoryDB는 R6g Graviton2 인스턴스를 지원합니다.
ElastiCache for Redis에서 MemoryDB로 마이그레이션하기 위해 ElastiCache 클러스터의 백업을 생성하고 MemoryDB 클러스터로 복원할 수 있습니다. 또한, Amazon Simple Storage Service(Amazon S3)에 저장된 Redis Database Backup(RDB) 파일에서 새 클러스터를 생성할 수도 있습니다.
MemoryDB를 사용하면 노드당 온디맨드 인스턴스 시간, 클러스터에 기록된 데이터 볼륨 및 스냅샷 스토리지를 기준으로 사용한 만큼의 비용을 지불할 수 있습니다. 자세한 내용은 MemoryDB 요금 페이지를 참조하세요.
자세히 알아보기
간단한 개요를 보려면 아래 비디오를 확인하세요.
오늘부터 기본 데이터베이스로 Amazon MemoryDB for Redis를 사용해보세요.
— Danilo
Source: Amazon MemoryDB for Redis 소개 – Redis 호환 높은 내구성의 인-메모리 데이터베이스 서비스


Leave a Reply