Amazon MSK Serverless 정식 출시 – 관리형 Kafka 클러스터 서버 관리 불필요
오늘 AWS는 Amazon MSK 서버리스를 정식 출시합니다. 서버 용량 계획 및 확장을 AWS에게 맡기고 Apache Kafka 클러스터 관리에서 발생하는 운영 오버헤드를 더 많이 줄일 수 있도록 지원합니다.
2019년 5월에는 고객이 Apache Kafka를 사용하여 데이터를 스트리밍할 수 있도록 지원하기 위해 Apache Kafka용 Amazon 관리형 스트리밍을 출시했습니다. Apache Kafka는 고객이 클릭스트림 이벤트, 트랜잭션 및 IoT 이벤트와 같은 스트리밍 데이터를 캡처할 수 있도록 지원하는 오픈 소스 플랫폼입니다. Apache Kafka는 스트리밍 데이터를 생성하는 애플리케이션(생산자)과 데이터를 사용하는 애플리케이션(소비자)을 분리하는 일반 솔루션입니다. Amazon MSK를 사용하면 완전관리형 Apache Kafka 클러스터를 사용하여 스트리밍 데이터를 실시간으로 손쉽게 수집하고 처리할 수 있습니다.
Amazon MSK는 프로덕션 환경에서 Apache Kafka를 설정, 확장 및 관리하는 데 필요한 작업을 줄여줍니다. Amazon MSK를 사용하면 몇 분 만에 클러스터를 생성하고 데이터 전송을 시작할 수 있습니다. Apache Kafka는 하나 이상의 브로커에서 클러스터로 실행됩니다. 브로커는 고가용성을 생성하기 위해 지정된 컴퓨팅 및 스토리지 용량이 여러 AWS 가용 영역에 분산되어 있는 인스턴스입니다. Apache Kafka는 사용자가 정의한 기간 동안 주제에 대한 레코드를 저장하고 해당 주제를 분할한 다음 이러한 파티션을 여러 브로커에 복제합니다. 데이터 생산자는 주제에 레코드를 쓰고 소비자는 주제에서 레코드를 읽습니다.
새 Amazon MSK 클러스터를 생성할 때는 브로커 수, 인스턴스 크기 및 각 브로커가 사용할 수 있는 스토리지를 결정해야 합니다. MSK 클러스터의 성능은 이러한 파라미터에 따라 달라집니다. 워크로드를 이미 알고 있는 경우 이러한 설정을 쉽게 제공할 수 있습니다. 하지만 새로운 워크로드에 대해 Amazon MSK 클러스터는 어떻게 구성해야 할까요? 또는 가변적이거나 예측할 수 없는 데이터 트래픽이 있는 애플리케이션의 경우는 어떻게 해야 할까요?
Amazon MSK 서버리스
Amazon MSK 서버리스는 애플리케이션에 온디맨드 스트리밍 용량과 스토리지를 제공하는 데 필요한 리소스를 자동으로 프로비저닝하고 관리합니다. 이는 용량이 얼마나 필요한지 모르거나, 애플리케이션에서 예측할 수 없거나, 매우 가변적인 처리량을 생성하고 유휴 용량에 대한 비용을 지불하고 싶지 않은 새로운 Apache Kafka 워크로드를 시작하기에 완벽한 솔루션입니다. 또한 클러스터의 프로비저닝, 확장 및 리소스 사용률 관리를 원치 않을 경우에도 유용합니다.
Amazon MSK 서버리스는 프라이빗 연결과 같은 다양한 보안 기능을 즉시 제공합니다. 즉, 트래픽이 AWS 백본, AWS Identity and Access Management(IAM) 액세스 제어 및 저장되고 전송 중인 데이터의 암호화를 벗어나지 않으므로 보안이 유지됩니다.
Amazon MSK 서버리스 클러스터는 애플리케이션 요구 사항에 따라 용량을 즉시 확장 및 축소합니다. Apache Kafka 클러스터가 수평으로 확장되면(즉, 더 많은 브로커가 추가됨) 추가된 용량을 활용하기 위해 파티션을 이러한 새 브로커로 이동해야 합니다. Amazon MSK 서버리스를 사용하면 브로커를 확장하거나 파티션 이동을 수행할 필요가 없습니다.
각 Amazon MSK 서버리스 클러스터는 최대 200MBps의 쓰기 처리량과 400MBps의 읽기 처리량을 제공합니다. 또한 파티션당 최대 5MBps의 쓰기 처리량과 10MBps의 읽기 처리량을 할당합니다.
Amazon MSK 서버리스 요금은 처리량을 기준으로 책정됩니다. 자세한 내용은 MSK의 요금 페이지를 참조하세요.
이제 작동하는 모습을 살펴보겠습니다.
본인이 모바일 게임 스튜디오의 설계자이고 새로운 게임을 출시하려고 한다고 상상해 보세요. 여러분은 게임 마케팅에 투자했고 새로운 플레이어가 많을 것이라 기대합니다. 게임은 클릭스트림 데이터를 백엔드 애플리케이션으로 전송합니다. 데이터는 실시간으로 분석되어 플레이어의 행동을 예측합니다. 이러한 예측을 통해 게임은 현재 플레이어의 행동에 맞는 실시간 제안을 제공하여 게임에 더 오래 머물도록 장려합니다.
게임은 클릭스트림 데이터를 Apache Kafka 클러스터로 전송합니다. Amazon MSK 서버리스 클러스터를 사용하는 경우 새 게임이 시작될 때 클러스터의 용량을 처리량에 맞게 조정하므로 클러스터 확장에 대해 걱정할 필요가 없습니다.
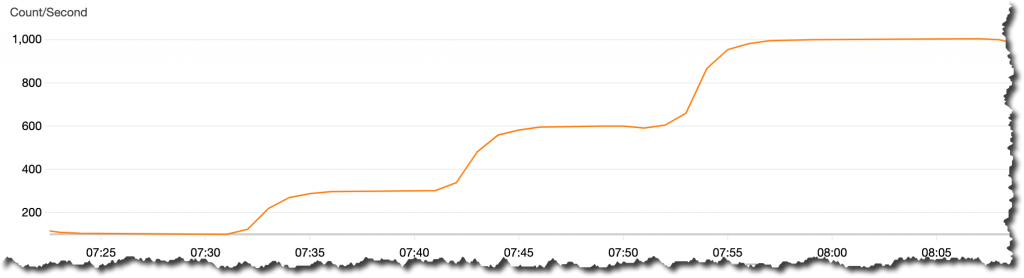
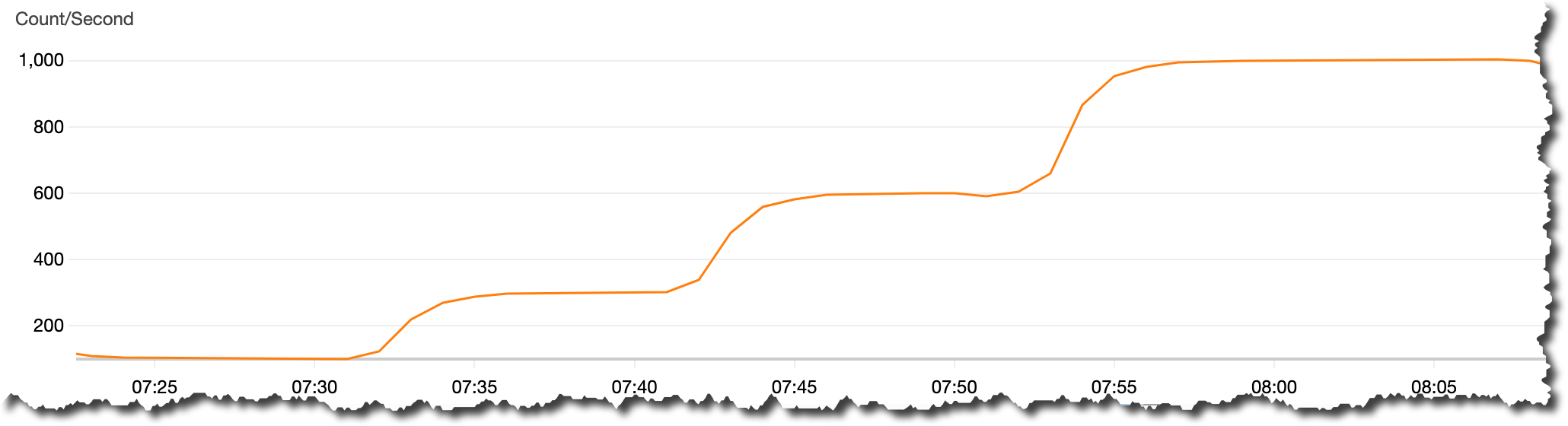
다음 이미지에서 새 게임 출시 발표 날짜의 그래프를 볼 수 있습니다. 클러스터가 사용 중인 지표 MessagesInPerSec이 주황색으로 표시되어 있습니다. 그리고 초당 메시지 수가 100개에서 먼저 증가하고 있음을 알 수 있습니다. 이는 출시 전의 기본 수입니다. 그런 다음 점점 더 많은 플레이어가 게임을 다운로드하고 플레이함에 따라 초당 300, 600 및 1,000개의 메시지로 증가합니다. 이를 통해 레코드의 볼륨이 계속 증가할 것이란 확신을 가지게 됩니다. Amazon MSK 서버리스는 애플리케이션 처리량이 서비스 한도 내로 유지되는 한 모든 레코드를 수집할 수 있습니다.
Amazon MSK 서버리스를 시작하는 방법
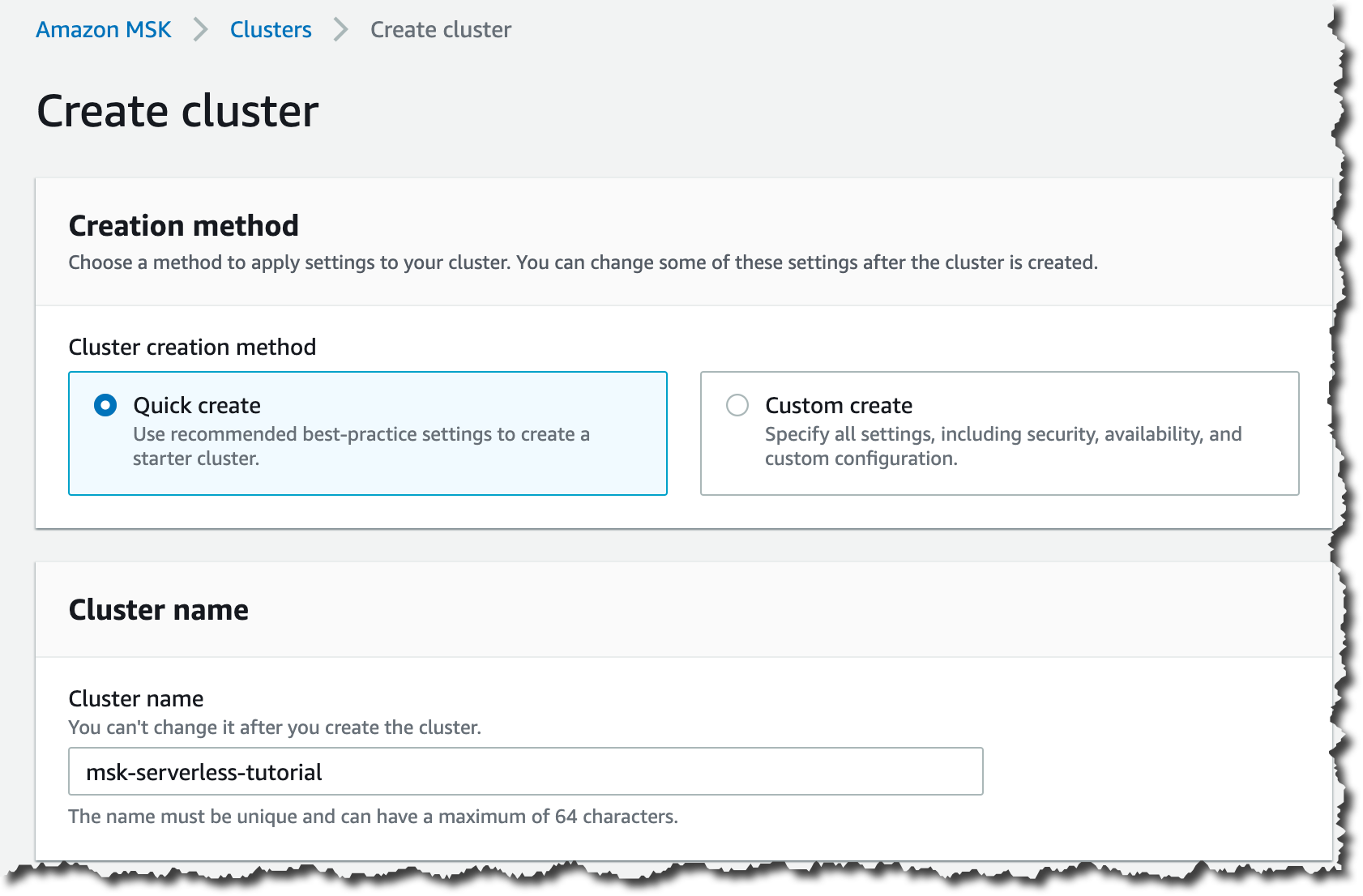
서비스에 용량 구성을 제공할 필요가 없으므로 Amazon MSK 서버리스 클러스터를 생성하는 방법은 매우 간단합니다. Amazon MSK 콘솔 페이지에서 새 클러스터를 생성할 수 있습니다.
빠른 생성(Quick create) 클러스터 생성 방법을 선택합니다. 이 방법은 스타터 클러스터를 생성하고 클러스터의 이름을 입력하는 모범 사례 설정을 제공합니다.
그런 다음 일반 클러스터 속성에서 클러스터 유형을 선택합니다. 서버리스(Serverless) 옵션을 선택하여 Amazon MSK 서버리스 클러스터를 생성합니다.

마지막으로 기본적으로 구성할 모든 클러스터 설정이 표시됩니다. 클러스터를 생성한 후에는 이러한 설정 대부분을 변경할 수 없습니다. 이러한 설정에 대해 다른 값이 필요한 경우 사용자 정의 생성(Custom create) 방법을 사용하여 클러스터를 생성해야 할 수 있습니다. 기본 설정이 제대로 작동하면 클러스터를 생성합니다.

클러스터를 생성하는 데는 몇 분이 소요되며, 그 후에는 클러스터 요약 페이지에 활성(Active) 상태가 표시됩니다.
이제 클러스터가 준비되었으므로 Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스를 사용하여 레코드 송수신을 시작할 수 있습니다. 이를 위한 첫 번째 단계는 새 IAM 정책과 IAM 역할 생성입니다. 인스턴스에서 클러스터에 액세스하려면 IAM을 사용하여 인스턴스를 인증해야 합니다.
Amazon MSK 서버리스는 IAM과 통합되어 Apache Kafka 워크로드에 대한 세분화된 액세스 제어를 제공합니다. IAM 정책을 사용하면 Apache Kafka 클라이언트에 최소 권한 액세스 권한을 부여할 수 있습니다.
IAM 정책 생성(Create the IAM policy)
다음 JSON을 사용하여 새 IAM 정책을 생성합니다. 이 정책은 클러스터에 연결하고, 주제를 생성하고, 데이터를 전송하며, 주제의 데이터를 사용할 수 있는 권한을 부여합니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:Connect"
],
"Resource": "arn:aws:kafka:<REGION>:<ACCOUNTID>:cluster/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3"
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:DescribeTopic",
"kafka-cluster:CreateTopic",
"kafka-cluster:WriteData",
"kafka-cluster:ReadData"
],
"Resource": "arn:aws:kafka:<REGION>:<ACCOUNTID>:topic/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3/msk-serverless-tutorial"
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:AlterGroup",
"kafka-cluster:DescribeGroup"
],
"Resource": "arn:aws:kafka:<REGION>:<ACCOUNTID>:group/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3/*"
}
]
}
리전 및 계정 ID를 사용자 고유의 것으로 바꿔야 합니다. 또한 클러스터, 주제 및 그룹 ARN을 교체해야 합니다. 이러한 ARN을 가져오려면 클러스터 요약 페이지로 이동하여 클러스터 ARN을 가져올 수 있습니다. 주제 ARN 및 그룹 ARN은 클러스터 ARN을 기반으로 합니다. 여기서 클러스터와 주제의 이름은 msk-serverless-tutorial입니다.
"arn:aws:kafka:<REGION>:<ACCOUNTID>:cluster/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3"
"arn:aws:kafka:<REGION>:<ACCOUNTID>:topic/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3/msk-serverless-tutorial"
"arn:aws:kafka:<REGION>:<ACCOUNTID>:group/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3/*"그런 다음 EC2 사용 사례로 새 역할을 만들고 이 정책을 역할에 연결합니다.

새 EC2 인스턴스 생성(Create a new EC2 instance)
이제 클러스터와 역할이 준비되었으므로 새 Amazon EC2 인스턴스를 생성합니다. 클러스터와 동일한 VPC, 서브넷 및 보안 그룹에 인스턴스를 추가합니다. 네트워킹 설정의 클러스터 속성 페이지에서 해당 정보를 찾을 수 있습니다. 또한 인스턴스를 구성할 때 이전 단계에서 방금 생성한 역할을 연결합니다.

준비가 완료되면 인스턴스를 시작합니다. 동일한 인스턴스를 사용하여 메시지를 생성하고 사용하게 됩니다. 이렇게 하려면 인스턴스에서 Apache Kafka 클라이언트 도구를 설정해야 합니다. Amazon MSK 개발자 안내서를 따라 인스턴스를 준비할 수 있습니다.
레코드 생성 및 사용(Producing and consuming records)
모든 구성이 완료되었으므로 Amazon MSK 서버리스를 사용하여 레코드 송수신을 시작할 수 있습니다. 가장 먼저 해야 할 일은 주제 생성입니다. EC2 인스턴스에서 Apache Kafka 도구를 설치한 디렉터리로 이동하여 부트스트랩 서버 엔드포인트를 내보냅니다.
cd kafka_2.13-3.1.0/bin/
export BS=boot-abc1234.c3.kafka-serverless.us-east-2.amazonaws.com:9098Amazon MSK 서버리스를 사용하는 경우 이 서버에는 단 하나의 주소만 있으며 이 주소는 클러스터 페이지의 클라이언트 정보에서 찾을 수 있습니다.

다음 명령을 실행하여 이름이 msk-serverless-tutorial인 주제를 만듭니다.
./kafka-topics.sh --bootstrap-server $BS
--command-config client.properties
--create --topic msk-serverless-tutorial --partitions 6이제 레코드 전송을 시작할 수 있습니다. 서비스가 높은 처리량에서 작동하는지 확인하기 위해서 Apache Kafka 생산자 성능 테스트 도구를 사용할 수 있습니다. 이 도구를 사용하면 정의된 처리량과 특정 크기로 동시에 많은 메시지를 MSK 클러스터에 보낼 수 있습니다. 이 성능 테스트 도구를 사용하여 실험하고 초당 메시지 수와 레코드 크기를 변경하며 클러스터가 어떻게 작동하고 용량을 조정하는지 확인합니다.
./kafka-topics.sh --bootstrap-server $BS
--command-config client.properties
--create --topic msk-serverless-tutorial --partitions 6마지막으로 메시지를 수신하려면 새 터미널을 열고 동일한 EC2 인스턴스에 연결한 다음 Apache Kafka 소비자 도구를 사용하여 메시지를 수신합니다.
cd kafka_2.13-3.1.0/bin/
export BS=boot-abc1234.c3.kafka-serverless.us-east-2.amazonaws.com:9098
./kafka-console-consumer.sh
--bootstrap-server $BS
--consumer.config client.properties
--topic msk-serverless-tutorial --from-beginningAmazon MSK 서버리스 클러스터의 모니터링 페이지에서 클러스터가 어떻게 작동하는지 확인할 수 있습니다.

가용성
Amazon MSK 서버리스는 미국 동부(오하이오), 미국 동부(버지니아 북부), 미국 서부(오레곤), EU(프랑크푸르트), EU(아일랜드), EU(스톡홀름), 아시아 태평양(싱가포르), 아시아 태평양(시드니) 및 아시아 태평양(도쿄) 리전에서 정식 출시되었습니다.
Amazon MSK 서버리스 기능 페이지에서 이 서비스와 해당 요금에 대해 자세히 알아보세요.
– Marcia
Source: Amazon MSK Serverless 정식 출시 – 관리형 Kafka 클러스터 서버 관리 불필요


Leave a Reply