Amazon Rekognition – 이미지 관리 및 Amazon Polly – 음성 표식 및 속삭임 생성 기능 업데이트
지난 re:Invent 2016 행사에서 개발자들이 손쉽게 스마트 애플리케이션을 개발할 수 있는 딥러닝 기반의 이미지 인식 서비스인 Amazon Rekognition과 Amazon Polly 및 Amazon Lex 등을 출시하였습니다. 이들 인공 지능 서비스에 최근 새로운 기능을 추가하였습니다. 이 글에서는 최근 업데이트 기능에 대해 간단하게 알아보겠습니다.
Amazon Rekognition에 이미지 관리 기능
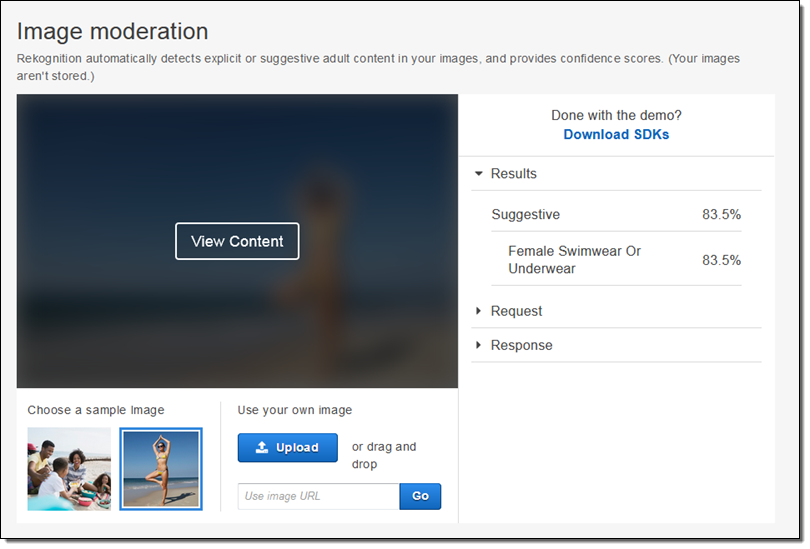
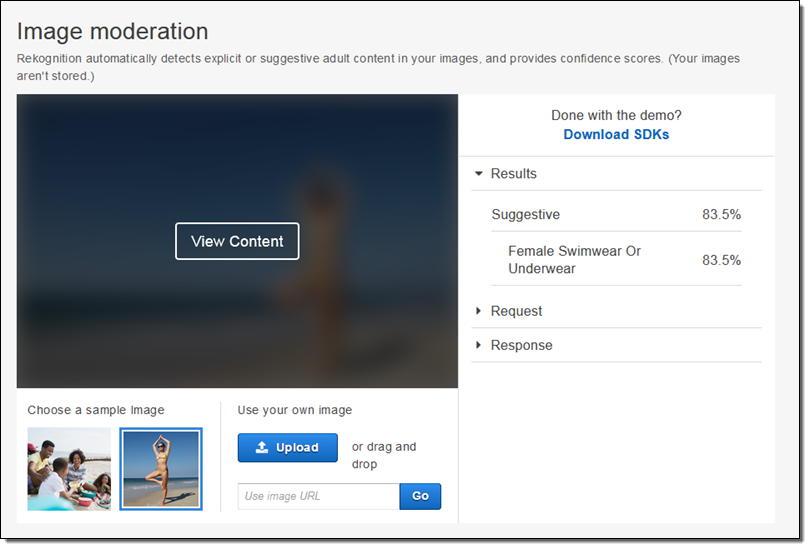
사용자가 프로필 사진에 대해 올린 경우, 사진이 적합하지 않은 콘텐츠인 경우 이미지를 식별할 수 있습니다. 상세한 레이블을 통해 허용 이미지 종류를 결정하는 미세 필터를 조정할 수 있습니다.
본 기능을 활용하려면 DetectModerationLabels 함수를 호출하면, 아래와 같은 응답을 통해 활용 가능합니다.
더 자세한 것은 Image Moderation 데모 기능을 통해 확인할 수 있습니다.
Amazon Polly 음성 표식 기능 및 속삭임 기능 출시
음성 표식(SppechMark) 기능은 개발자가 음성을 시각적 경험과 동기화 할 수 있습니다. 이 기능을 사용하면 음성을 얼굴 애니메이션과 동기화하거나 말한대로 단어의 강조 표시를 사용하여 립싱크와 같은 시나리오를 만들 수 있습니다. 음성 표식 메타 데이터는 합성된 음성을 설명하고 음성 오디오 스트림과 함께 사용함으로써 사운드, 단어, 문장 및 SSML 태그의 시작과 끝을 결정할 수 있습니다. 개발자는 립싱크 아바타를 만들고, 시각적으로 읽은 경험을 강조하고, Amazon Lumberyard와 같은 게임 엔진에 음성 기능을 통합하여 캐릭터에게 음성을 제공 할 수 있습니다.
네 가지 유형의 음성 표시가 있습니다.
- 문장 : 입력 텍스트에서 문장 요소를 지정합니다.
- 단어 : 입력 텍스트의 단어 요소를 나타냅니다.
- Viseme : 말한 소리에 해당하는 얼굴과 입의 위치를 보여줍니다.
- SSML (Speech Synthesis Markup Language) : SSML 입력 텍스트에서 <mark> 요소를 설명합니다.
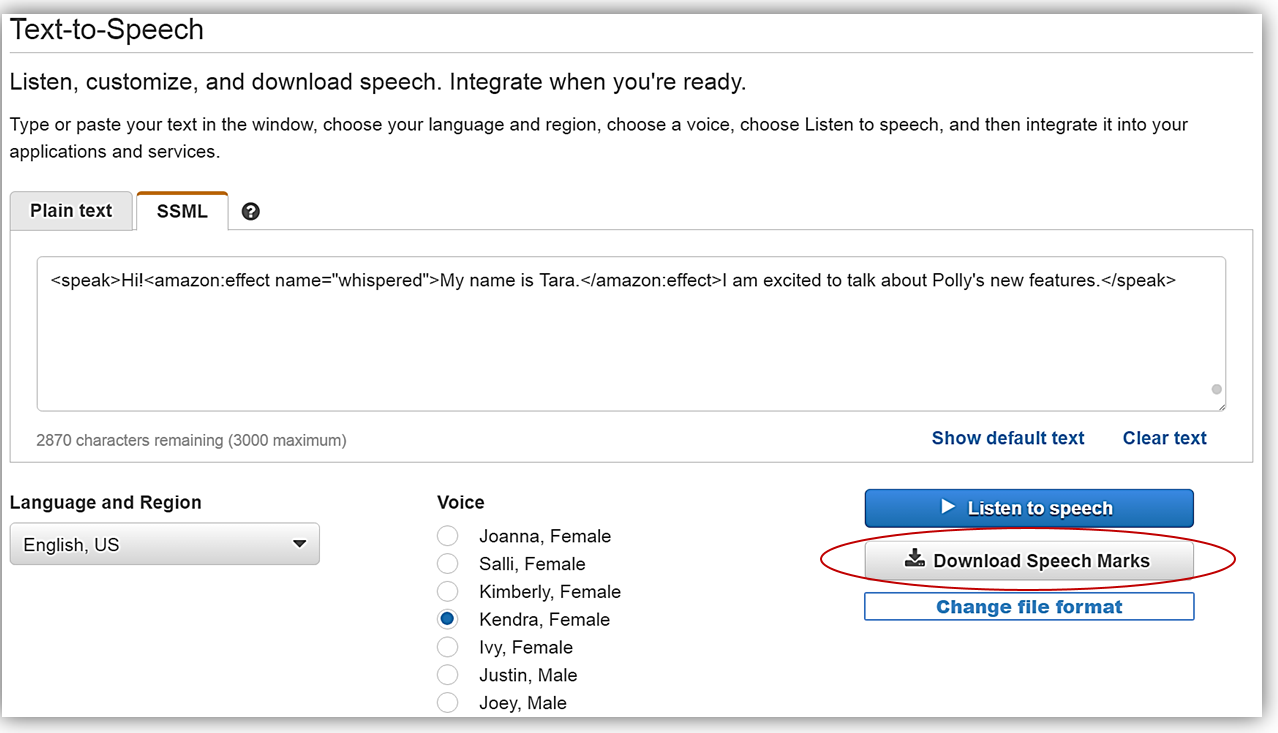
Amazon Polly에서 Change file format을 누른 후, File Format 옵션에서 Speech Marks를 선택합니다. Change 버튼을 눌러서 다운로드 포맷을 바꿀 수 있습니다.
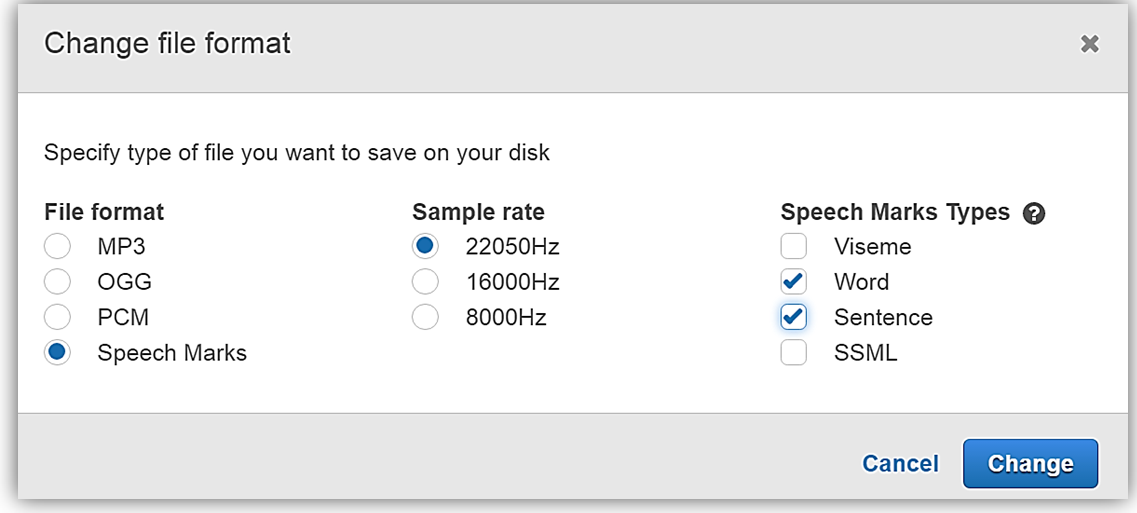
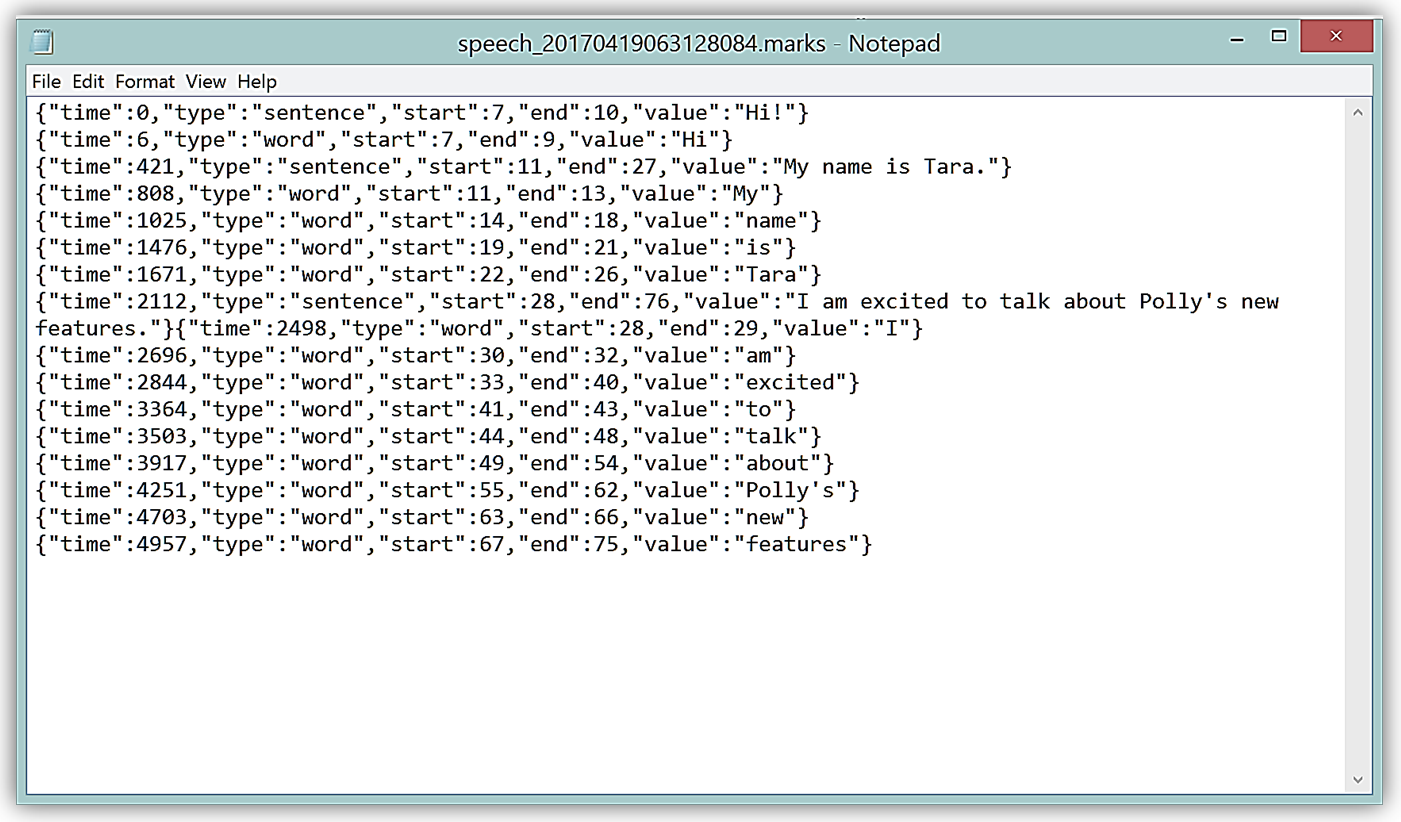
다운로드를 하면, 다음과 같이 음성 표식이 있는 텍스트 파일을 다운로드 할 수 있습니다.
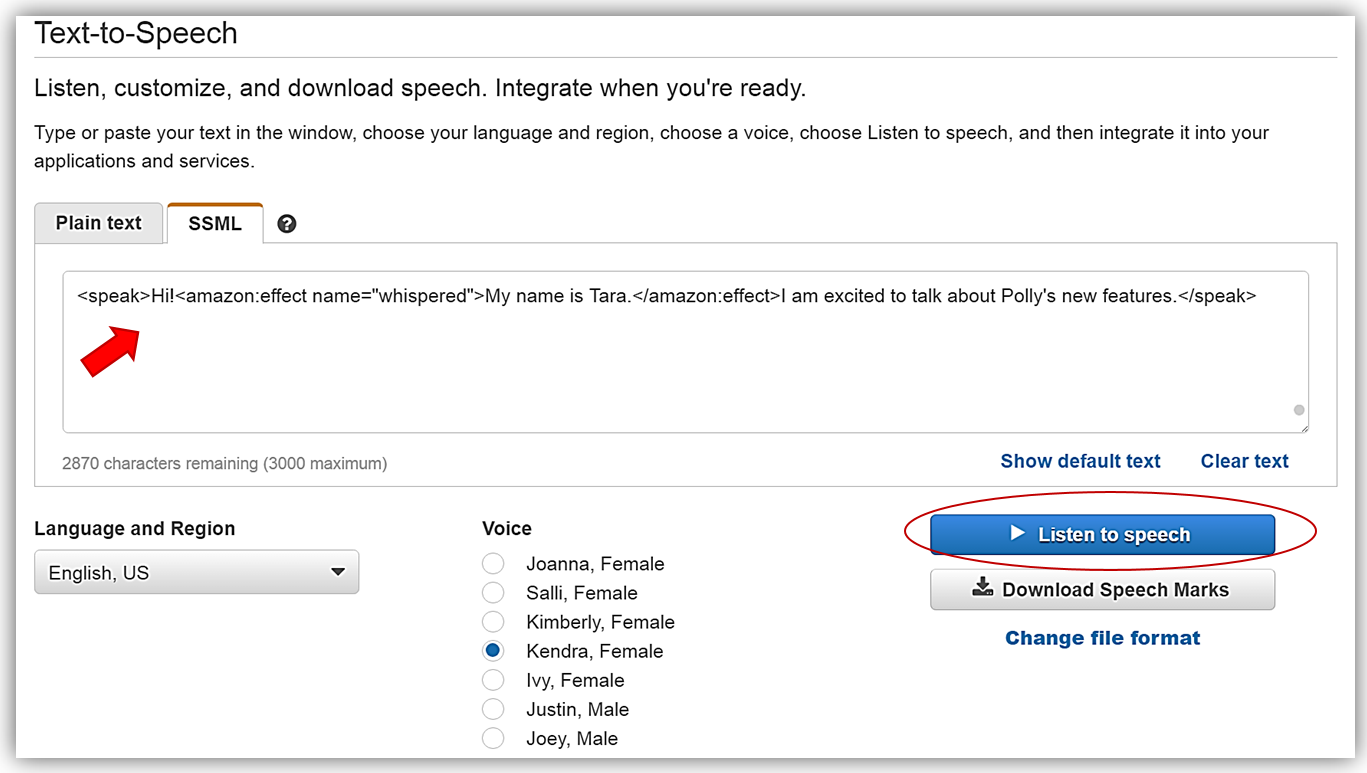
속삭임 기능은 개발자가 Text-to-Speech 출력을 수정할 수있는 표현형 음성 기능에서 피치, 템포 및 소리 크기에 대한 음성 효과입니다. 속삭이는 기능을 사용하면 개발자는 <amazon:effect name=”whispered”> SSML 요소를 사용하여 속삭이는 음성으로 말한 입력 텍스트의 단어를 가질 수 있습니다.
<speak>Hi!<amazon:effect name="whispered">My name is Tara.</amazon:effect>I am excited to talk about Polly's new features.</speak>
위의 마크업을 복사 한 후, Listen to speech 버튼을 누르면 “My name is Tara” 는 속삭임 소리로 들리게 됩니다.
본 기능 업데이트에 대한 자세한 소개는 아래를 참고하세요.
– Channy;
Source: Amazon Rekognition – 이미지 관리 및 Amazon Polly – 음성 표식 및 속삭임 생성 기능 업데이트


Leave a Reply