Amazon SageMaker, 모델 배포 서비스에 자동 스케일링 지원
AWS ML 플랫폼 팀의 제품 관리자인 Kumar Venkateswar로부터 Amazon SageMaker에서 새롭게 지원하는 자동 스케일링(Auto Scaling)에 대한 발표 내용을 자세하게 들어봅니다.
Amazon SageMaker를 사용하여 기계 학습(Machine Learning, ML) 모델을 손쉽게 구축하고 교육하고 배포한 고객사가 이미 수천여개에 달합니다. 오늘 부터 Amazon SageMaker용 자동 스케일링(Auto Scaling)으로 운영 ML 모델을 더욱 손쉽게 관리할 수 있게 되었습니다. 추론에 필요한 규모에 맞추어 수 많은 인스턴스를 수동으로 관리할 필요 없이 SageMaker에서 AWS 자동 스케일링 정책에 따라 인스턴스 개수가 자동으로 조정되도록 할 수 있습니다.
SageMaker는 많은 고객이 ML 프로세스를 쉽게 관리하도록 지원해왔습니다. 관리형 Jupyter 노트북과 관리형 배포 교육의 이점을 활용하는 고객들도 있었고, 기계 학습을 애플리케이션과 통합하는 과정에서 추론을 위한 SageMaker 호스트에 모델을 배포하는 고객들도 있었습니다.
SageMaker를 활용하면 추론 호스트의 운영 체제(OS) 또는 프레임워크에 패치를 적용하는 데 신경을 쓸 필요가 없고 가용 영역 전반에 추론 호스트를 구성할 필요도 없습니다. SageMaker에 모델을 배포하면 나머지 작업은 자동으로 처리됩니다.
지금까지는 추론에 필요한 규모를 제공하려면 엔드포인트(또는 다른 형태의 운영 환경)당 추론의 수와 유형을 지정해야 했습니다. 추론 볼륨이 바뀌면 인스턴스의 수 또는 유형을 변경할 수 있으며, 다운타임 없이 이 변경 사항은 각 엔드포인트에 다시 반영됩니다. 프로비저닝을 손쉽게 변경할 수 있도록 하는 것 외에, 고객들은 SageMaker를 더 쉽게 관리할 수 있도록 기능을 개선해줄 것을 요청했습니다.
SageMaker 콘솔, AWS Auto Scaling API 및 AWS SDK에서 Amazon SageMaker용 자동 스케일링을 사용하면 훨씬 쉽게 관리할 수 있습니다. 이제 추론 볼륨을 자세하게 모니터링하여 그에 따라 엔드포인트 구성을 변경할 필요 없이 고객이 AWS Auto Scaling에 적용할 조정 정책을 구성할 수 있습니다. 자동 스케일링은 정책에 정의된 Amazon CloudWatch 지표와 대상 값을 기준으로 실제 워크로드에 따라 인스턴스 개수를 늘리거나 줄입니다.
따라서 고객이 추론 용량을 자동으로 조정하면서 낮은 비용으로 예측 가능한 성능을 유지할 수 있습니다. 인스턴스당 목표 추론 처리량을 지정하고 각 운영 환경별 인스턴스 개수의 상한과 하한을 설정하기만 하면 됩니다. 그러면 SageMaker가 Amazon CloudWatch 경보를 사용하여 인스턴스당 처리량을 모니터링한 후 필요에 따라 프로비저닝된 용량을 늘리거나 줄입니다.
자동 스케일링을 사용하여 엔드포인트를 구성하고 나면 SageMaker가 배포된 모델을 지속적으로 모니터링하여 인스턴스 수를 자동으로 조정합니다. SageMaker는 애플리케이션 트래픽의 변화에 대응하여 처리량을 원하는 레벨로 유지합니다. 따라서 더 이상 최대 로드에 맞추어 불필요하게 많은 용량을 프로비저닝할 필요가 없으므로 운영 환경에서 모델을 손쉽게 관리하고 배포된 모델의 비용을 절감할 수 있습니다.
대신, 예상되는 최소 트래픽과 최대 트래픽을 수용할 수 있는 한도를 구성하면 Amazon SageMaker가 그 한도 내에서 작동하면서 비용을 최소한으로 유지합니다.
시작하는 방법 SageMaker 콘솔을 엽니다. 기존 엔드포인트의 경우 먼저 엔드포인트에 액세스하여 설정을 수정합니다.
그런 다음 Endpoint runtime settings 섹션으로 스크롤하여 운영 환경 형태를 선택하고 Configure auto scaling을 선택합니다.
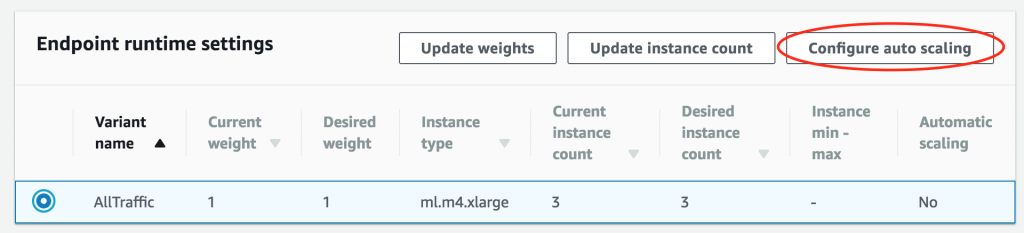
먼저 최대 및 최소 인스턴스 수를 구성합니다.
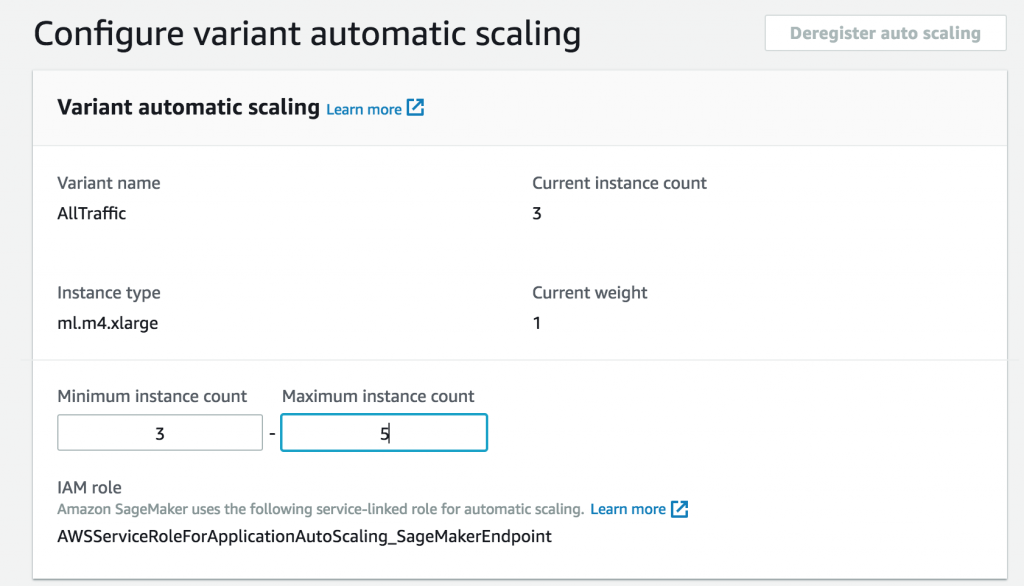
다음으로, 이전 로드 테스트 결과에 따라 인스턴스를 추가하는 데 기준이 될 인스턴스당 처리량을 선택합니다.
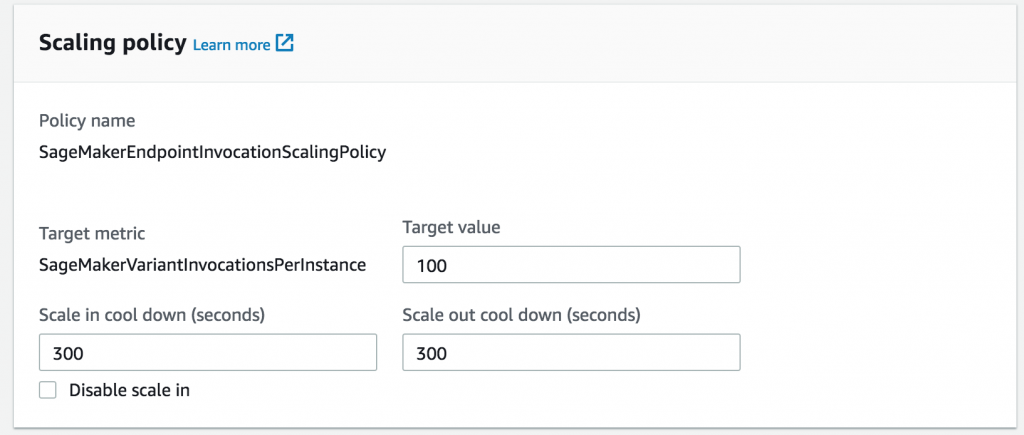
필요한 경우 워크로드의 변화 폭이 큰 기간 동안 잦은 변동을 방지하기 위해 조정을 중단하거나 재개하는 쿨다운 기간을 설정할 수도 있습니다. 이 기간을 설정하지 않으면 SageMaker가 기본값으로 작동합니다.
이걸로 끝입니다. 이제 추론이 늘어남에 따라 엔드포인트가 자동으로 조정됩니다.
사용량에 따른 일반적인 SageMaker 결제 방식에 따라 요금을 지불하므로, 상대적으로 사용량이 적은 기간에 사용하지 않은 용량의 요금을 더 이상 지불할 필요가 없습니다.
Amazon SageMaker의 Auto Scaling은 오늘부터 미국 동부(버지니아 북부 및 오하이오), EU(아일랜드), 미국 서부(오레곤) AWS 리전에서 사용할 수 있습니다. 자세한 내용은 Amazon SageMaker Auto Scaling 설명서를 참고하십시오.
(역자주. SageMaker를 통해 딥러닝 학습 및 모델 구축과 배포에 대해서는 한국어로 진행된 온라인 세미나 자료 및 동영상을 참고하시기 바랍니다.)
 Kumar Venkateswar는 Amazon SageMaker, Amazon Machine Learning 및 AWS Deep Learning AMI를 포함한 AWS ML 플랫폼 팀의 제품 관리자입니다. 여가 시간에 Kumar는 바이올린을 연주하거나 매직: 더 게더링 게임을 즐깁니다.
Kumar Venkateswar는 Amazon SageMaker, Amazon Machine Learning 및 AWS Deep Learning AMI를 포함한 AWS ML 플랫폼 팀의 제품 관리자입니다. 여가 시간에 Kumar는 바이올린을 연주하거나 매직: 더 게더링 게임을 즐깁니다.


Leave a Reply