Amazon SageMaker Canvas – 바로 사용 가능 모델, 사용자 지정 텍스트 및 이미지 분류 모델 지원 기능 출시
오늘 Amazon SageMaker Canvas의 새로운 기능을 발표했습니다. 이 기능을 사용하면 비즈니스 분석가가 기계 학습(ML)을 통해 몇 분 만에 수천 줄의 문서, 이미지 및 텍스트에서 인사이트를 얻을 수 있습니다. 오늘부터 바로 사용할 수 있는 모델에 액세스하고 이전에 지원된 테이블 형식 데이터를 위한 사용자 지정 모델과 함께 사용자 지정 텍스트 및 이미지 분류 모델을 만들 수 있습니다. 이 모든 작업을 기계 학습 경험이나 코드 작성 없이도 가능합니다.
다양한 업계의 비즈니스 분석가는 AI/ML 솔루션을 적용하여 다양한 데이터에서 통찰력을 얻고 비즈니스 이해 관계자의 임시 분석 요청에 응답하기를 원합니다. 분석가는 워크플로우에 AI/ML을 적용함으로써 검사, 분류는 물론 원시 데이터, 이미지 또는 문서에서 인사이트를 추출하는 등 시간이 많이 걸리고 오류가 발생하기 쉬운 수동 프로세스를 자동화할 수 있습니다. 그러나 비즈니스 문제에 AI/ML을 적용하려면 기술 전문 지식이 필요하며 맞춤형 모델을 구축하려면 몇 주 또는 몇 달이 걸릴 수 있습니다.
2021년에 출시된 Amazon SageMaker Canvas는 비즈니스 분석가가 바로 사용할 수 있는 다양한 모델을 사용하거나 사용자 지정 모델을 생성하여 정확한 기계 학습 예측을 직접 생성할 수 있는 시각적 포인트 앤 클릭 서비스입니다.
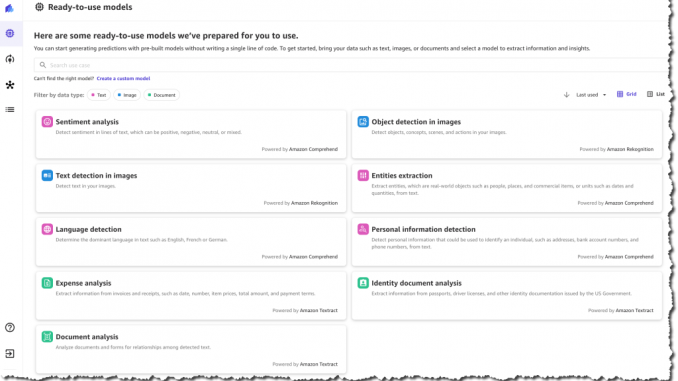
바로 사용 가능 모델
이제 AWS 고객은 SageMaker Canvas를 사용하여 몇 분 만에 수천 줄의 문서, 이미지 및 텍스트에서 정보를 추출하고 예측을 생성하는 데 사용할 수 있는 즉시 사용 가능한 모델에 액세스할 수 있습니다. 바로 사용할 수 있는 이러한 모델에는 감정 분석, 언어 감지, 항목 추출, 개인 정보 감지, 이미지 내 객체 및 텍스트 탐지, 청구서와 영수증에 대한 비용 분석, ID 문서 분석, 보다 일반화된 문서 및 양식 분석이 포함됩니다.
예를 들어, 즉시 사용할 수 있는 감정 분석 모델을 선택하고 소셜 미디어 및 고객 지원 티켓의 제품 리뷰를 업로드하여 고객이 제품에 대해 어떻게 생각하는지 빠르게 이해할 수 있습니다. 바로 사용할 수 있는 개인 정보 탐지 모델을 사용하면 이메일, 지원 티켓 및 문서에서 개인 식별 정보(PII)를 탐지하고 수정할 수 있습니다. 바로 사용할 수 있는 비용 분석 모델을 사용하면 스캔한 청구서 및 영수증에서 데이터를 쉽게 검색 및 추출하고 해당 데이터에 대한 인사이트를 얻을 수 있습니다.
바로 사용할 수 있는 이러한 모델은 Amazon Rekognition, Amazon Comprehend, 및 Amazon Textract를 포함하여 AWS AI 서비스를 기반으로 합니다.

사용자 지정 텍스트 및 이미지 분류 모델
비즈니스별 사용 사례에 맞게 학습된 사용자 지정 모델이 필요한 고객은 SageMaker Canvas를 사용하여 텍스트 및 이미지 분류 모델을 만들 수 있습니다.
SageMaker Canvas를 사용하여 사용자 지정 텍스트 분류 모델을 만들어 필요에 따라 데이터를 분류할 수 있습니다. 예를 들어, 여러분이 고객 지원을 제공하는 회사에서 비즈니스 분석가로 일한다고 가정해 보겠습니다. 고객 지원 에이전트는 고객과 상담할 때 티켓을 만들고 티켓 유형(예: ‘사고’, ‘서비스 요청’ 또는 ‘문제’)을 기록해야 합니다. 이 필드는 종종 잊혀지기 때문에 보고가 완료되면 데이터를 분석하기가 어렵습니다. 이제 SageMaker Canvas를 사용하여 사용자 지정 텍스트 분류 모델을 만들고 기존 고객 지원 티켓 정보 및 티켓 유형으로 훈련시킨 다음 누락된 데이터가 있는 보고서를 작성할 때 이를 사용하여 향후 티켓 유형을 예측할 수 있습니다.
SageMaker Canvas를 사용하여 자체 이미지 데이터 세트를 사용하여 사용자 지정 이미지 분류 모델을 만들 수도 있습니다. 예를 들어 여러분이 스마트폰을 제조하는 회사에서 비즈니스 분석가로 일한다고 가정해 보겠습니다. 직무의 일환으로 보고서를 준비하고 품질 평가 및 동향과 관련된 비즈니스 이해 관계자의 질문에 응답해야 합니다. 휴대폰을 조립할 때마다 사진이 자동으로 촬영되고, 일주일이 지나면 모든 이미지를 받게 됩니다. 이제 SageMaker Canvas를 사용하여 일반적인 제조 결함을 식별하도록 훈련된 새로운 사용자 지정 이미지 분류 모델을 만들 수 있습니다. 그런 다음 매주 모델을 사용하여 이미지를 분석하고 생산된 휴대폰의 품질을 예측할 수 있습니다.
SageMaker Canvas 실행
여러분이 전자 상거래 회사의 비즈니스 분석가라고 가정해 보겠습니다. 여러분은 이번 시즌의 모든 신제품에 대한 고객 심리를 이해해야 합니다. 이해관계자들은 다음 달에 구매해야 할 재고를 결정하기 위해 결과를 항목 범주별로 집계한 보고서를 요구합니다. 예를 들어, 새 가구 제품이 긍정적인 반응을 얻었는지 알고 싶어합니다. 새 제품에 대한 리뷰가 포함된 스프레드시트와 전자 상거래 플랫폼의 모든 제품을 분류하는 오래된 파일이 제공되었습니다. 하지만 이 파일에는 아직 새 제품이 포함되어 있지 않습니다.
이 문제를 해결하려면 SageMaker Canvas를 사용할 수 있습니다. 먼저, 즉시 사용 가능한 감정 분석 모델을 사용하여 각 리뷰에 대한 감정을 이해하고 긍정적, 부정적 또는 중립으로 분류해야 합니다. 그런 다음 기존 제품을 기반으로 새 제품의 카테고리를 예측하는 사용자 지정 텍스트 분류 모델을 만들어야 합니다.
바로 사용할 수 있는 모델 — 감정 분석
각 리뷰의 감정을 빠르게 파악하려면 제품 리뷰를 대량으로 업데이트하고 모든 감정 예측이 포함된 파일을 생성하면 됩니다.
시작하려면 바로 사용할 수 있는 모델 페이지에서 감정 분석을 찾은 다음 배치 예측에서 새 데이터 세트 가져오기를 선택합니다.
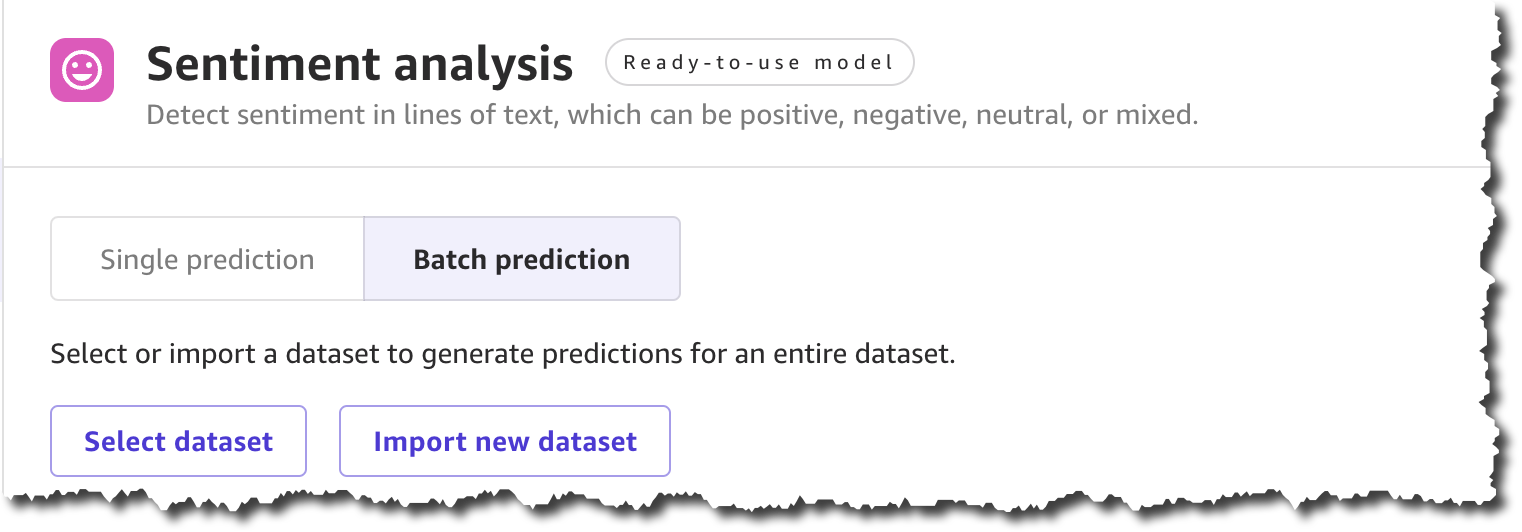
새 데이터 세트를 생성할 때 로컬 시스템에서 데이터 세트를 업로드하거나 Amazon Simple Storage Service(Amazon S3)를 사용할 수 있습니다. 이 데모에서는 파일을 로컬로 업로드합니다. 이 예제에 사용된 모든 상품 리뷰는 Amazon 고객 리뷰 데이터 세트에서 찾을 수 있습니다.
파일을 업로드하고 데이터 세트 생성을 완료한 후 예측을 생성할 수 있습니다.
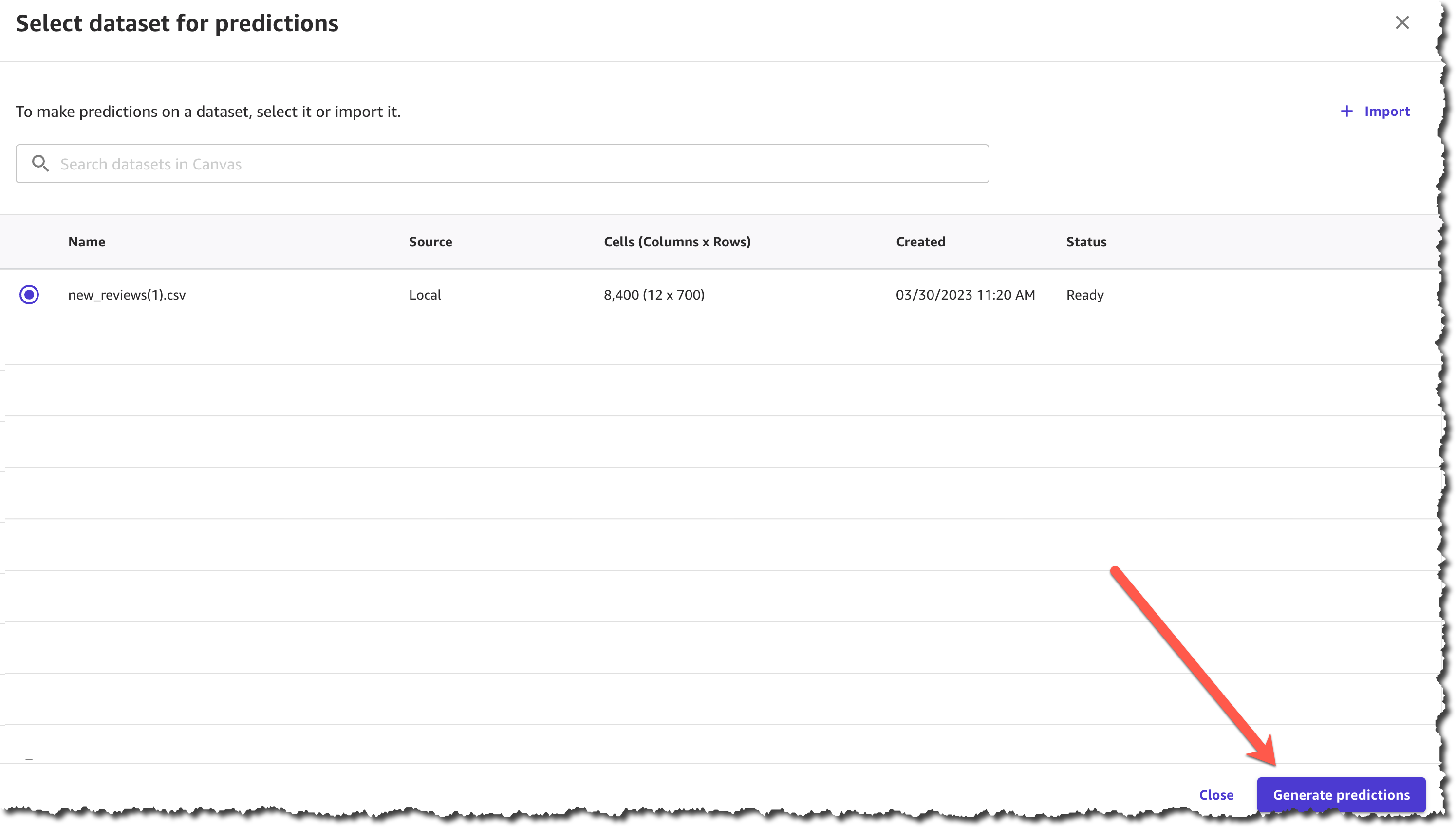
예측 생성은 데이터 세트의 크기에 따라 1분도 채 걸리지 않으며 결과를 보거나 다운로드할 수 있습니다.

이 예측의 결과는 .csv 파일로 다운로드하거나 SageMaker Canvas 인터페이스에서 볼 수 있습니다. 각 제품 리뷰에 대한 감정을 확인할 수 있습니다.

이제 작업의 첫 번째 부분이 준비되었습니다. 각 리뷰의 감정을 포함하는 .csv 파일이 생겼습니다. 다음 단계는 해당 제품을 범주로 분류하는 것입니다.
사용자 지정 텍스트 분류 모델
제품 제목을 기반으로 새 제품을 범주로 분류하려면 SageMaker Canvas에서 새 텍스트 분류 모델을 훈련시켜야 합니다.
SageMaker Canvas에서 텍스트 분석 유형의 새 모델을 생성합니다.

모델을 만드는 첫 번째 단계는 모델을 훈련하는 데 사용할 데이터 세트를 선택하는 것입니다. 새 컬렉션을 제외한 모든 제품이 포함된 지난 시즌의 데이터 세트를 사용하여 이 모델을 훈련시킵니다.
데이터 세트 가져오기가 완료되면 예측하려는 데이터가 포함된 열, 이 경우 product_category 열과 예측을 수행하기 위한 모델의 입력으로 사용될 열, product_title 열을 선택해야 합니다.
구성을 마치면 모델 빌드를 시작할 수 있습니다. 빌드에는 두 가지 모드가 있습니다.
- 퀵 빌드는 15~30분 내에 모델을 반환합니다.
- 표준 빌드는 완료하는 데 2~5시간이 걸립니다.
빌드 모드 간의 차이점에 대해 자세히 알아보려면 설명서를 확인하세요. 이 데모에서는 데이터 세트가 50,000행 미만이므로 퀵 빌드를 선택합니다.

모델을 빌드하면 모델의 성능을 분석할 수 있습니다. SageMaker Canvas는 80-20 접근 방식을 사용합니다. 즉, 데이터 세트의 80% 데이터를 사용하여 모델을 훈련시키고 데이터의 20% 를 사용하여 모델을 검증합니다.
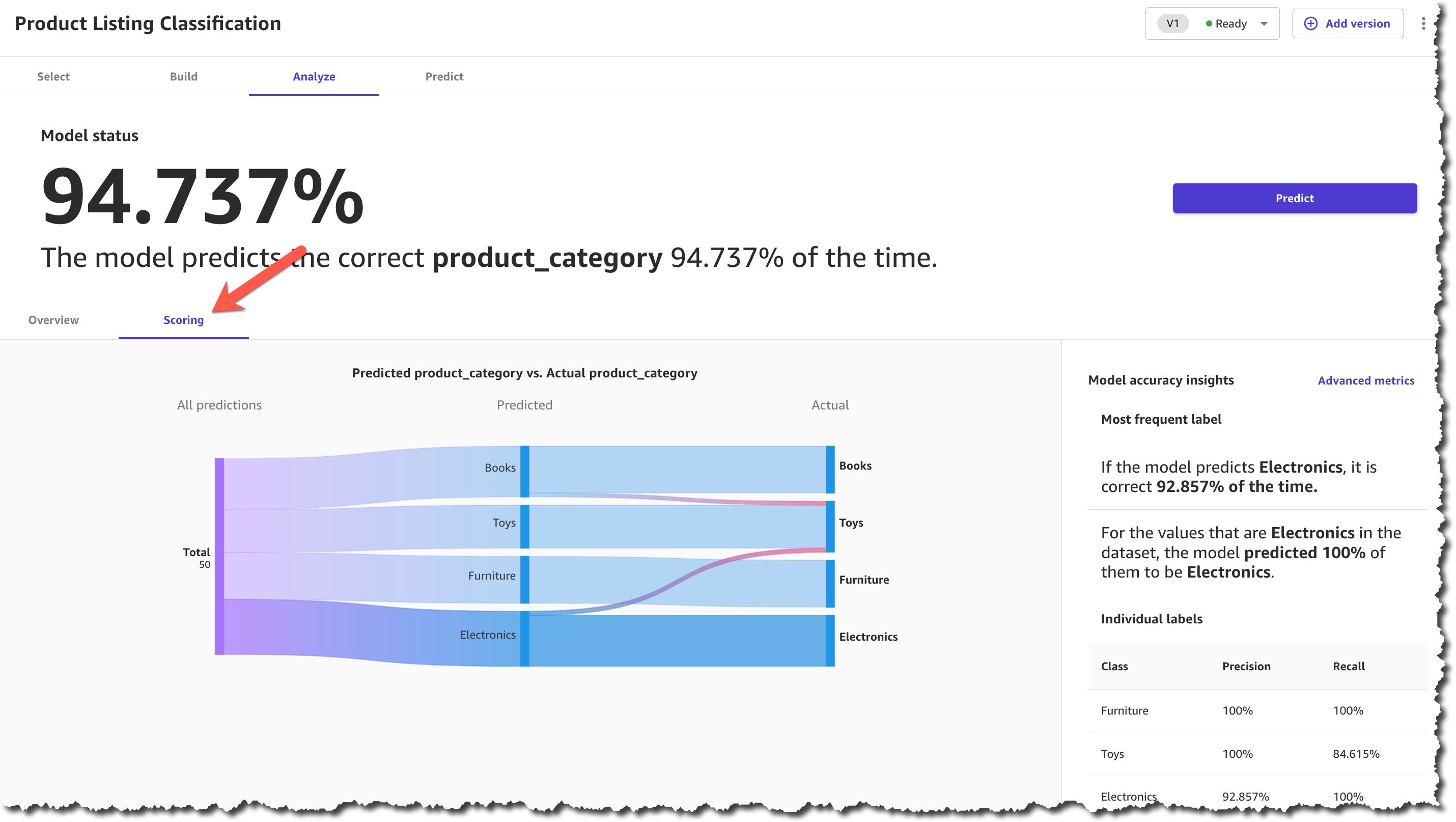
모델 빌드가 완료되면 모델 점수를 확인할 수 있습니다. 채점 섹션에서는 각 범주에 대한 예측이 얼마나 정확했는지를 시각적으로 확인할 수 있습니다. 설명서에서 모델 성능을 평가하는 방법에 대해 자세히 알아볼 수 있습니다.
모형의 예측률이 높은지 확인한 후 계속해서 예측을 생성할 수 있습니다. 이 단계는 감정 분석에 바로 사용할 수 있는 모델과 유사합니다. 단일 제품 또는 제품 세트에 대해 예측을 수행할 수 있습니다. 배치 예측의 경우 데이터 세트를 선택하고 모델이 예측을 생성하도록 해야 합니다. 이 예시에서는 바로 사용할 수 있는 모델에서 선택한 것과 동일한 데이터 세트, 즉 리뷰를 포함한 데이터 세트를 선택합니다. 데이터 세트의 제품 수에 따라 몇 분 정도 걸릴 수 있습니다.
예측이 준비되면 결과를 .csv 파일로 다운로드하거나 각 제품이 어떻게 분류되었는지 확인할 수 있습니다. 예측 결과에서는 모델 빌드 프로세스 중에 제공된 범주를 기반으로 각 제품에 하나의 범주만 할당합니다.

이제 분석을 수행하고 고객 리뷰를 기반으로 한 새 컬렉션을 통해 각 제품 범주의 성과를 평가하는 데 필요한 모든 리소스를 확보했습니다. SageMaker Canvas를 사용하면 코드를 한 줄도 작성하지 않고도 바로 사용할 수 있는 모델에 액세스하고 사용자 지정 텍스트 분류 모델을 만들 수 있었습니다.
정식 출시
SageMaker Canvas에서 바로 사용할 수 있는 모델과 사용자 지정 텍스트 및 이미지 분류 모델에 대한 지원은 SageMaker Canvas를 사용할 수 있는 모든 AWS 리전에서 사용할 수 있습니다. SageMaker Canvas 제품 세부 정보 페이지를 방문하여 새로운 기능과 가격 책정에 대해 자세히 알아볼 수 있습니다.
– Marcia
Source: Amazon SageMaker Canvas – 바로 사용 가능 모델, 사용자 지정 텍스트 및 이미지 분류 모델 지원 기능 출시


Leave a Reply