Amazon SageMaker Data Wrangler – 신규 SaaS 애플리케이션 데이터 소스 지원
데이터는 기계 학습의 원동력입니다. 기계 학습에서 데이터 준비는 원시 데이터를 추가 처리 및 분석에 적합한 형식으로 변환하는 프로세스입니다. 데이터 준비를 위한 일반적인 프로세스는 데이터를 수집한 다음 정리하고 레이블을 지정하고 마지막으로 검증 및 시각화하는 것으로 시작됩니다. 고품질의 데이터를 올바로 얻는 프로세스는 보통 복잡하고 시간이 많이 걸릴 수 있습니다.
이것이 바로 AWS에서 기계 학습(ML) 워크로드를 구축하는 고객들이 Amazon SageMaker Data Wrangler의 기능을 높이 평가하는 이유입니다. SageMaker Data Wrangler를 통해 고객은 단일 시각적 인터페이스에서 데이터 준비 프로세스를 간소화하고 데이터 준비 워크플로의 필수 프로세스를 완료할 수 있습니다. Amazon SageMaker Data Wrangler는 ML용 데이터를 집계하고 준비하는 데 걸리는 시간을 줄이는 데 도움이 됩니다.
그러나 데이터의 확산으로 인해 일반적으로 고객은 제조 데이터를 위한 SAP OData, 고객 파이프라인을 위한 Salesforce, 웹 애플리케이션 데이터를 위한 Google Analytics와 같은 외부 SaaS(Software-as-a-Service) 애플리케이션을 비롯한 여러 시스템에 데이터가 분산되어 있습니다. ML을 사용하여 비즈니스 문제를 해결하려면 고객은 이러한 모든 데이터 소스를 통합해야 합니다. 현재 Amazon S3 또는 Amazon Redshift로 데이터를 수집하기 위해 자체 솔루션을 구축하거나 타사 솔루션을 사용해야 합니다. 이러한 솔루션은 설치가 복잡하고 비용 효율적이지 않을 수 있습니다.
Amazon SageMaker Data Wrangler 소개, SaaS 애플리케이션을 데이터 소스로 지원
오늘부터 Amazon SageMaker Data Wrangler에서 ML에 대한 외부 SaaS 애플리케이션 데이터를 집계하여 ML용 데이터를 준비할 수 있다는 사실을 공유하게 되어 기쁩니다. 이 기능을 사용하면 Amazon AppFlow를 통해 40개 이상의 SaaS 애플리케이션을 데이터 소스로 사용하고 Amazon SageMaker Data Wrangler에서 이러한 데이터를 사용할 수 있습니다. AppFlow의 AWS Glue 데이터 카탈로그에 데이터 소스를 등록하면 Data Wrangler SQL 탐색기를 사용하여 이러한 데이터 소스에서 테이블과 스키마를 찾아볼 수 있습니다. 이 기능은 Amazon AppFlow를 사용하는 SaaS 애플리케이션과 SageMaker Data Wrangler 간의 원활한 데이터 통합을 제공합니다.
다음은 이 새로운 기능에 대한 간단한 미리 보기입니다.

Amazon SageMaker Data Wrangler의 이 새로운 기능은 SaaS 애플리케이션과 AWS 서비스 간에 데이터를 안전하게 교환할 수 있는 완전 관리형 통합 서비스인 Amazon AppFlow와의 통합을 사용하여 작동합니다. Amazon AppFlow를 사용하면 Salesforce, SAP 및 Amplitude와 같은 SaaS 애플리케이션과 지원되는 모든 서비스 간에 Amazon S3 또는 Amazon Redshift로 양방향 데이터 통합을 설정할 수 있습니다.
그런 다음 Amazon AppFlow를 사용하여 AWS Glue 데이터 카탈로그에서 데이터를 카탈로그화할 수 있습니다. 이 기능은 Amazon AppFlow를 사용하여 Amazon S3 대상 커넥터용 AWS Glue 데이터 카탈로그와의 통합을 생성할 수 있는 새로운 기능입니다. 이 새로운 통합을 통해 고객은 크롤러를 실행할 필요 없이 Amazon AppFlow 흐름 구성에서 바로 몇 번의 클릭만으로 SaaS 데이터 애플리케이션을 AWS Glue 데이터 카탈로그에 카탈로그화할 수 있습니다.
흐름을 설정하고 이를 AWS Glue 데이터 카탈로그에 삽입하면 Amazon SageMaker Data Wrangler에서 이 데이터를 사용할 수 있습니다. 그런 다음 평소처럼 데이터를 준비할 수 있습니다. Amazon Athena 쿼리를 작성하여 데이터를 미리 보고, 여러 소스의 데이터를 결합하거나, 데이터를 가져와서 ML 모델 교육을 준비할 수 있습니다.
이 기능을 사용하면 몇 가지 간단한 단계를 수행하여 Amazon AppFlow를 통해 Amazon SageMaker Data Wrangler로 SaaS 애플리케이션 간에 원활하게 데이터를 통합할 수 있습니다. 이 통합은 40개 이상의 SaaS 애플리케이션을 지원하며, 지원되는 애플리케이션의 전체 목록은 Supported source and destination applications(지원되는 소스 및 대상 애플리케이션) 설명서를 참조하세요.
Amazon AppFlow용 Amazon SageMaker Data Wrangler 지원 시작하기
이 기능이 어떻게 작동하는지 자세히 살펴보겠습니다. 이 시나리오에서는 Salesforce에서 데이터를 가져와서 Amazon SageMaker Data Wrangler를 사용하여 데이터를 준비해야 합니다.
이 기능을 사용하기 시작하려면 먼저 Amazon AppFlow에서 데이터 소스를 AWS Glue 데이터 카탈로그에 등록하는 흐름을 생성해야 합니다. 이미 Salesforce 계정에 연결되어 있으며, 이제 흐름을 생성하기만 하면 됩니다.

한 가지 중요한 점은 Amazon SageMaker Data Wrangler에서 SaaS 애플리케이션 데이터를 사용할 수 있게 하려면 Amazon S3를 대상으로 하는 흐름을 만들어야 한다는 것입니다. 그런 다음 AWS Glue Data Catalog settings(AWS Glue 데이터 카탈로그 설정)에서 Create a Data Catalog table(데이터 카탈로그 테이블 생성)을 활성화해야 합니다. 이 옵션은 Salesforce 데이터를 AWS Glue 데이터 카탈로그에 자동으로 카탈로그화합니다.

이 페이지에서는 필요한 AWS Glue 데이터 카탈로그 권한이 있는 사용자 역할을 선택하고 데이터베이스 이름과 테이블 이름 접두사를 정의해야 합니다. 또한 이 섹션에서는 JSON, CSV 또는 Apache Parquet 형식으로 데이터 형식 기본 설정을 정의하고 파일 이름 섹션에 타임스탬프를 추가하려는 경우 파일 이름 기본 설정을 정의할 수 있습니다.

Amazon AppFlow 및 AWS Glue 데이터 카탈로그에 SaaS 데이터를 등록하는 방법에 대해 자세히 알아보려면 Cataloging the data output from an Amazon AppFlow flow(Amazon AppFlow 흐름에서 데이터 출력 카탈로그 작업) 설명서 페이지를 참조하세요.
SaaS 데이터 등록을 마치면 IAM 역할이 AppFlow의 Data Wrangler의 데이터 소스를 볼 수 있는지 확인해야 합니다. 다음은 IAM 역할의 정책 예입니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "glue:SearchTables",
"Resource": [
"arn:aws:glue:*:*:table/*/*",
"arn:aws:glue:*:*:database/*",
"arn:aws:glue:*:*:catalog"
]
}
]
} AWS Glue 데이터 카탈로그로 데이터 카탈로그 작업을 활성화하면 Amazon SageMaker Data Wrangler가 이 새로운 데이터 소스를 자동으로 검색할 수 있으며, Data Wrangler SQL Explorer를 사용하여 테이블과 스키마를 찾아볼 수 있습니다.
이제 Amazon SageMaker Data Wrangler 대시보드로 전환한 다음Connect to data sources(데이터 소스에 연결)을 선택할 차례입니다.

다음 페이지에서 Create connection(연결을 생성)하고 가져올 데이터 소스를 선택해야 합니다. 이 섹션에서는 사용할 수 있는 모든 연결을 볼 수 있습니다. Salesforce 연결을 이미 사용할 수 있음을 확인할 수 있습니다.

데이터 소스를 추가하려는 경우 Set up new data sources(새 데이터 소스 설정) 섹션에 통합할 수 있는 외부 SaaS 애플리케이션 목록을 볼 수 있습니다. 외부 SaaS 애플리케이션을 데이터 소스로 인식하는 방법을 알아보려면 How to enable access(액세스 활성화 방법)을 선택하여 자세히 알아볼 수 있습니다.

이제 데이터 세트를 가져오고 Salesforce 연결을 선택하겠습니다.

다음 페이지에서 연결 설정을 정의하고 Salesforce에서 데이터를 가져올 수 있습니다. 이 구성을 마치면 Connect(연결)을 선택합니다.

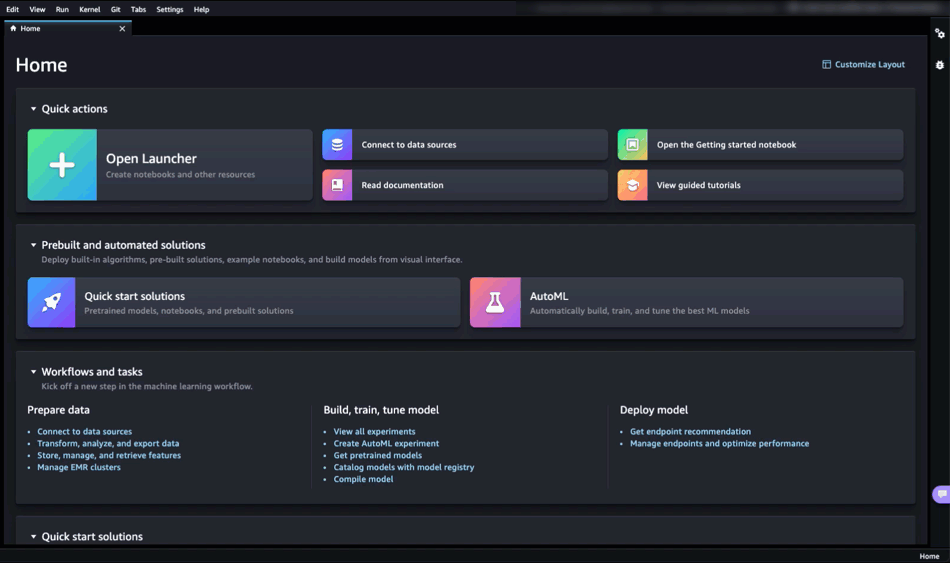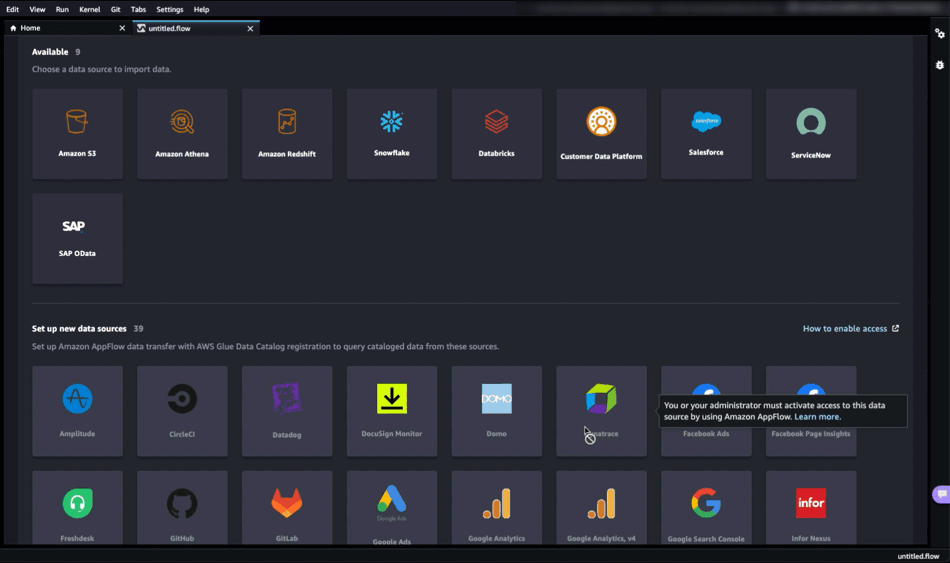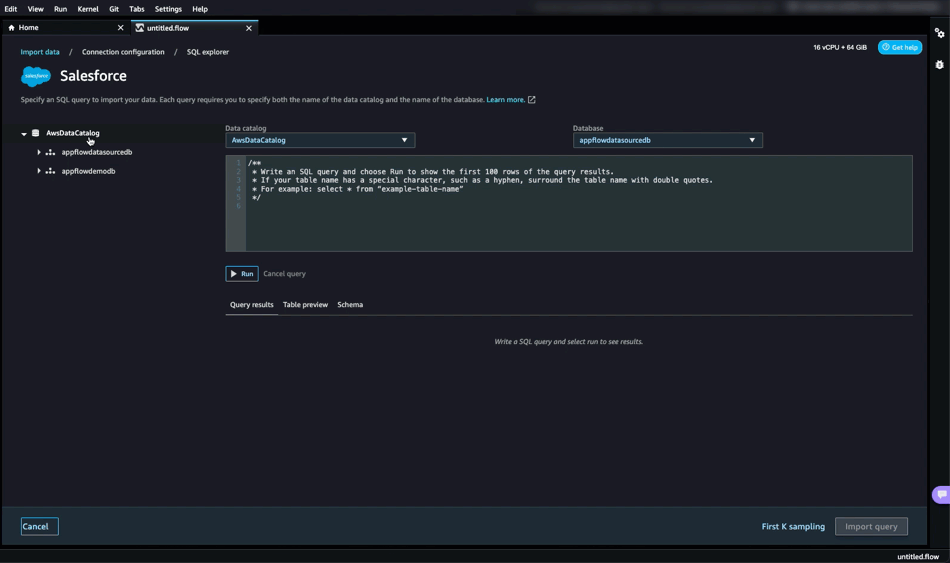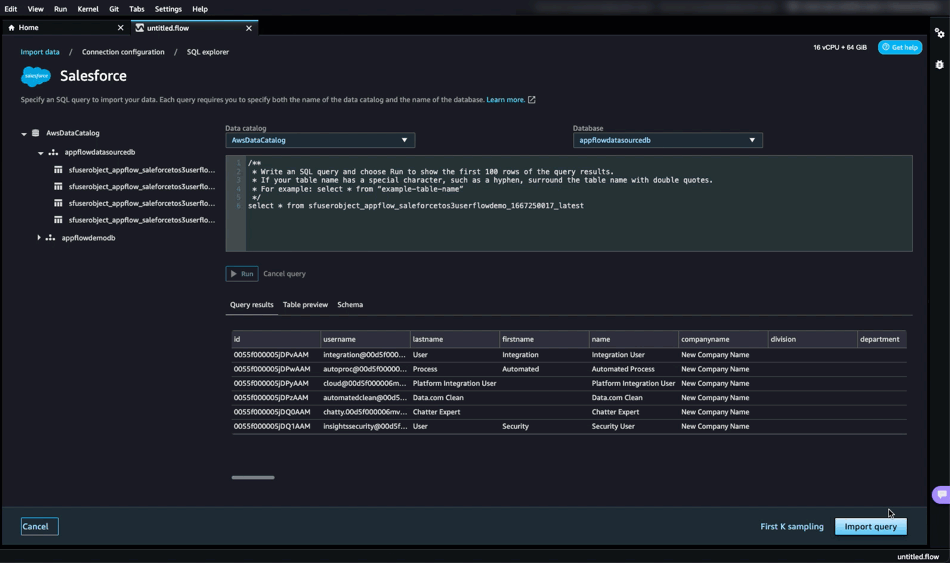
다음 페이지에서 Amazon AppFlow와 AWS Glue 데이터 카탈로그로 이미 구성한 Salesforce 데이터가 appflowdatasourcedb라는 것을 볼 수 있습니다. 필요한 데이터인지 검토할 수 있도록 테이블 미리 보기와 스키마도 확인할 수 있습니다.

그런 다음 SageMaker Data Wrangler SQL Explorer 내에서 SQL 쿼리를 수행해 이 데이터를 사용하여 데이터 세트를 구축하기 시작합니다. 그런 다음 Import query(쿼리 가져오기)를 선택합니다.

그런 다음 데이터 세트의 이름을 정의합니다.

이제 데이터 준비 프로세스를 시작할 수 있습니다. Analysis(분석) 탭으로 이동하여 데이터 인사이트 보고서를 실행할 수 있습니다. 분석을 통해 데이터 품질 문제와 예측하고자 하는 ML 문제를 기반으로 문제를 해결하기 위해 다음에 사용해야 하는 변환에 대한 보고서가 제공됩니다. 데이터 분석 기능을 사용하는 방법에 대해 자세히 알아보려면 Accelerate data preparation with data quality and insights in the Amazon SageMaker Data Wrangler(Amazon SageMaker Data Wrangler 데이터 품질 및 인사이트로 데이터 준비 가속화) 블로그 게시물을 참조하세요.
이 경우에는 필요하지 않은 열이 몇 개 있는데 이 열을 삭제해야 합니다. Add step(단계 추가)를 선택합니다.

제가 좋아하는 기능 중 하나는 Amazon SageMaker Data Wrangler가 수많은 ML 데이터 변환을 제공한다는 것입니다. 이를 통해 하나의 대시보드에서 데이터 정리, 변환 및 특성 추출 프로세스를 간소화할 수 있습니다. 변환 데이터에 대해 SageMaker Data Wrangler가 제공하는 기능에 대한 자세한 내용은 이 Transform Data (데이터 변환) 설명서 페이지를 참조하세요.
이 목록에서 Manage columns(열 관리)를 선택합니다.

그런 다음 Transform(변환) 섹션에서 Drop column(열 삭제) 옵션을 선택합니다. 그런 다음 필요하지 않은 열을 몇 개 선택합니다.

작업을 마치면 필요하지 않은 열이 제거되고 방금 만든 Drop column(열 삭제) 데이터 준비 단계가 Add step(단계 추가) 섹션에 나열됩니다.

또한 Amazon SageMaker Data Wrangler 내에서 데이터 흐름을 시각적으로 볼 수 있습니다. 이 예시에서는 데이터 흐름이 아주 기본적입니다. 하지만 데이터 준비 프로세스가 복잡할 때 이 시각적 보기를 통해 모든 데이터 준비 단계를 쉽게 볼 수 있습니다.

이제 Salesforce 데이터로 필요한 작업을 수행할 수 있습니다. 예를 들어 Export to(내보내기)를 선택하고 Add destination(대상 추가) 메뉴에서 Amazon S3를 선택하여 데이터를 Amazon S3로 직접 내보낼 수 있습니다. 이 경우에는 Add destination(대상 추가)를 선택한 다음 Amazon S3를 선택하여 데이터를 처리한 후 Amazon S3에 데이터를 저장하도록 Data Wrangler를 지정합니다.

Amazon SageMaker Data Wrangler는 예약된 작업을 사용하여 동일한 데이터 준비 흐름을 자동화할 수 있는 유연성을 제공합니다. 또한 SageMaker Inference Pipeline(via Jupyter Notebook) 및 SageMaker Feature Store(via Jupyter Notebook)를 통해 특성 추출을 자동화하고 SageMaker Inference Pipeline(via Jupyter Notebook)을 통해 추론 엔드포인트에 배포할 수 있습니다.

주요 사항
Related news(관련 뉴스) – 이 기능을 사용하면 Amazon SageMaker Data Wrangler를 사용하여 데이터를 쉽게 집계 및 준비할 수 있습니다. 이 기능은 Amazon AppFlow 및 AWS Glue 데이터 카탈로그와의 통합이므로 Amazon AppFlow now supports AWS Glue Data Catalog integration and provides enhanced data preparation(Amazon AppFlow, 이제 AWS Glue 데이터 카탈로그 통합 지원 및 향상된 데이터 준비 제공) 페이지에서 자세히 알아볼 수 있습니다.
Availability(가용성) – Amazon SageMaker Data Wrangler는 현재 Amazon AppFlow에서 지원하는 모든 리전에서 사용할 수 있는 데이터 소스로 SaaS 애플리케이션을 지원합니다.
Pricing(요금) – Amazon SageMaker Data Wrangler에서 SaaS 애플리케이션 지원을 사용하는 데는 추가 비용이 들지 않지만 Amazon SageMaker Data Wrangler에서 데이터를 가져오기 위해 Amazon AppFlow를 실행하는 데는 비용이 듭니다.
이 기능에 대해 자세히 알아보려면 Import Data From Software as a Service (SaaS) Platforms(서비스형 소프트웨어(SaaS) 플랫폼에서 데이터 가져오기) 설명서 페이지를 방문하여 시작하기 안내서에 따라 Amazon SageMaker Data Wrangler로 데이터 집계 및 SaaS 애플리케이션 데이터 준비를 시작하세요.
즐겁게 빌드해보세요!
— Donnie
Source: Amazon SageMaker Data Wrangler – 신규 SaaS 애플리케이션 데이터 소스 지원


Leave a Reply