Amazon SageMaker Data Wrangler – 실시간 및 일괄 추론 지원 기능 출시
기계 학습 모델을 구축하려면 기계 학습 엔지니어가 데이터를 준비하기 위한 데이터 변환 파이프라인을 개발해야 합니다. 이 파이프라인을 설계하는 프로세스는 시간이 많이 걸리며 데이터 준비 파이프라인을 프로덕션 환경에 구현하려면 기계 학습 엔지니어, 데이터 엔지니어 및 데이터 과학자 간의 팀 간 협업이 필요합니다.
Amazon SageMaker Data Wrangler의 주요 목적은 데이터 준비 및 데이터 처리 워크로드를 쉽게 수행할 수 있도록 하는 것입니다. SageMaker Data Wrangler를 통해 고객은 단일 시각적 인터페이스에서 데이터 준비 프로세스와 데이터 준비 워크플로의 필요한 모든 단계를 간소화할 수 있습니다. SageMaker Data Wrangler는 신속하게 프로토타입을 만들고 데이터 처리 워크로드를 프로덕션에 배포하는 시간을 줄여 고객이 MLOps 프로덕션 환경에 쉽게 통합할 수 있도록 합니다.
그러나 모델 훈련을 위해 고객 데이터에 적용된 변환은 실시간 추론 중에 새로운 데이터에 적용되어야 합니다. 실시간 추론 엔드포인트에서 SageMaker Data Wrangler를 지원하지 않는 경우 고객은 전처리 스크립트에서 흐름의 변환을 복제하는 코드를 작성해야 합니다.
Amazon SageMaker Data Wrangler의 실시간 및 일괄 추론 지원 소개
이제 SageMaker Data Wrangler에서 실시간 및 일괄 추론을 위한 데이터 준비 흐름을 배포할 수 있게 되어 기쁘게 생각합니다. 이 기능을 사용하면 Amazon SageMaker에서 생성한 데이터 변환 흐름을 Amazon SageMaker 추론 파이프라인의 한 단계로 재사용할 수 있습니다.
실시간 및 일괄 추론에 대한 SageMaker Data Wrangler 지원은 데이터 변환 흐름 구현을 반복할 필요가 없기 때문에 프로덕션 배포 속도를 높입니다. 이제 SageMaker Data Wrangler를 SageMaker 추론과 통합할 수 있습니다. 추론 중에 데이터를 처리하는 데 Principal Component Analysis(주요 성분 분석) 및 one-hot encoding(원-핫 인코딩) 같은 작업을 포함하는 SageMaker Data Wrangler의 사용하기 쉬운 포인트 앤 클릭 인터페이스로 생성된 동일한 데이터 변환 흐름이 사용됩니다. 즉, 실시간 및 일괄 추론 애플리케이션을 위해 데이터 파이프라인을 재구축할 필요가 없으며 프로덕션에 더 빨리 도달할 수 있습니다.
실시간 및 일괄 추론 시작하기
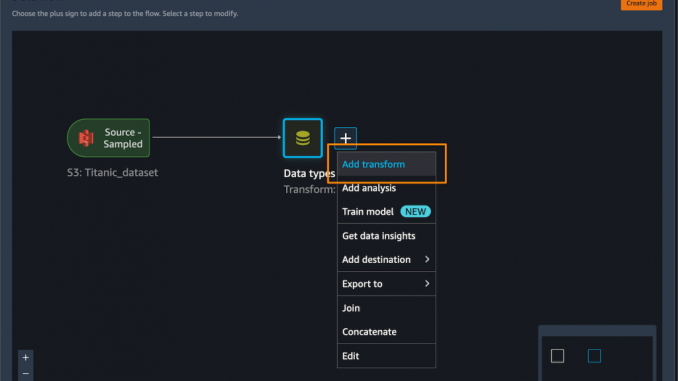
SageMaker Data Wrangler의 배포 지원을 사용하는 방법을 살펴보겠습니다. 이 시나리오에서는 SageMaker Data Wrangler 내부에 흐름이 있습니다. 해야 할 일은 SageMaker 추론 파이프라인을 사용하여 이 흐름을 실시간 및 일괄 추론에 통합하는 것입니다.
먼저 데이터 세트에 몇 가지 변환을 적용하여 학습을 준비하겠습니다.
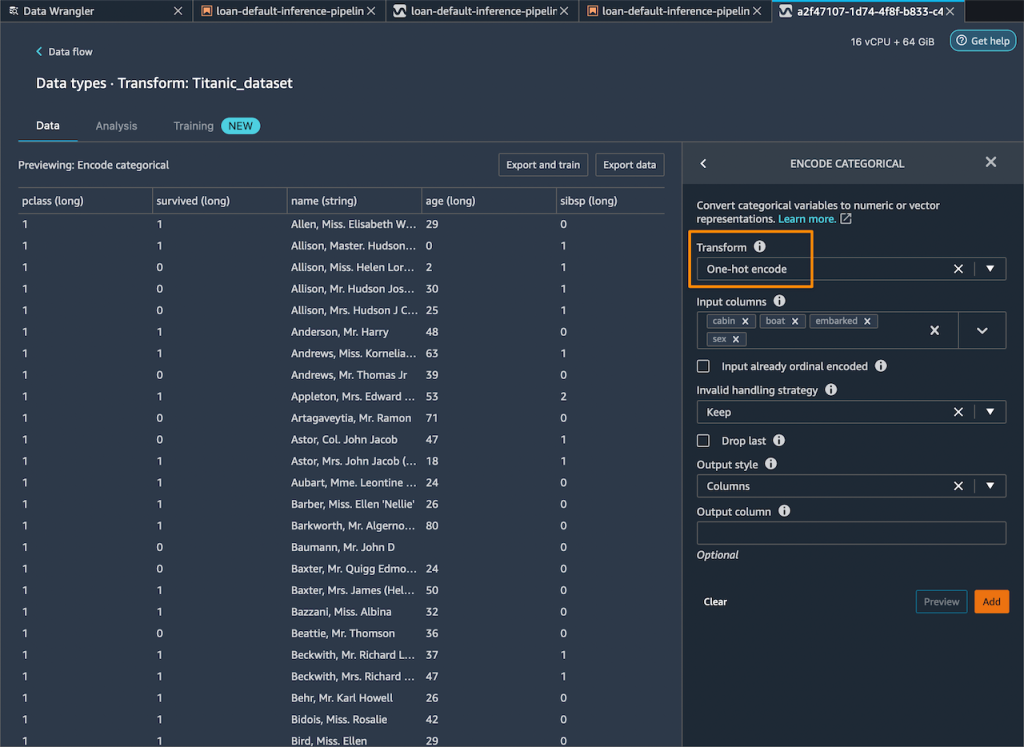
범주형 열에 원-핫 인코딩을 추가하여 새 기능을 생성합니다.
그런 다음 훈련 중에 사용할 수 없는 나머지 문자열 열을 모두 삭제합니다.

결과 흐름에는 이제 이 두 가지 변환 단계가 있습니다.
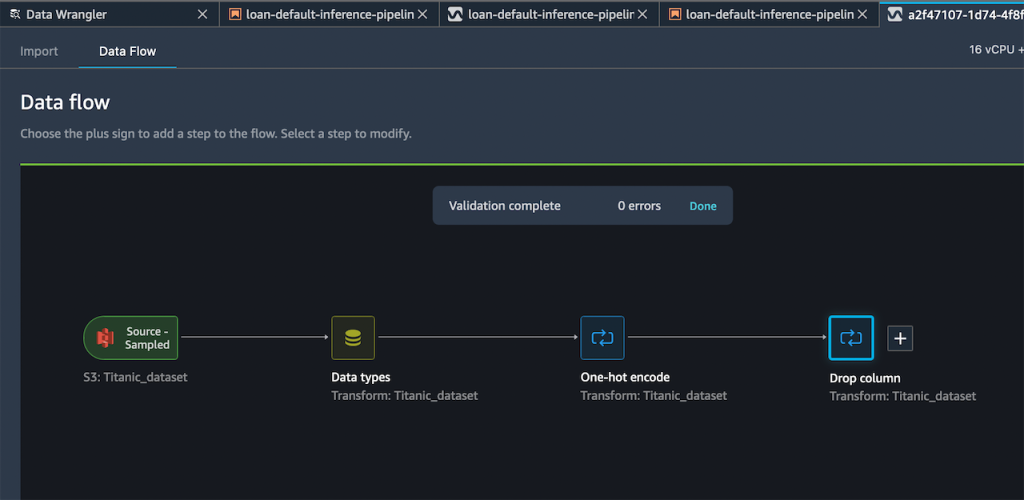
추가한 단계가 괜찮다면 Export to(내보내기) 메뉴를 확장할 수 있으며, SageMaker Inference Pipeline(via Jupyter Notebook)으로 내보낼 수 있는 옵션이 있습니다.

SageMaker Inference Pipeline으로 Export to(내보내기)를 선택하면 SageMaker Data Wrangler가 SageMaker Data Wrangler 흐름을 추론과 통합하기 위해 완전히 사용자 정의된 Jupyter Notebook을 준비할 것입니다. 이렇게 생성된 Jupyter Notebook은 몇 가지 중요한 작업을 수행합니다. 먼저, SageMaker 파이프라인에서 데이터 처리 및 모델 학습 단계를 정의합니다. 다음 단계는 파이프라인을 실행하여 Data Wrangler로 데이터를 처리하고 처리된 데이터를 사용하여 실시간 예측을 생성하는 데 사용할 모델을 학습하는 것입니다. 그런 다음 Data Wrangler 흐름과 학습된 모델을 추론 파이프라인으로 실시간 엔드포인트에 배포합니다. 마지막으로, 내 엔드포인트를 호출하여 예측을 수행합니다.

이 기능은 Amazon SageMaker Autopilot을 사용하므로 ML 모델을 쉽게 구축할 수 있습니다. SageMaker Data Wrangler 단계의 출력인 변환된 데이터 세트를 제공하고 예측할 대상 열을 선택하기만 하면 됩니다. 나머지는 Amazon SageMaker Autopilot에서 처리하여 다양한 솔루션을 탐색하여 최상의 모델을 찾을 것입니다.

use_automl_step 변수가 있는 노트북에서는 SageMaker Autopilot에서 AutoML을 학습 단계로 사용하는 것이 기본적으로 활성화됩니다. AutoML 단계를 사용할 때는 추론 중에 예측하려는 데이터의 열인target_attribute_name 값을 정의해야 합니다. 또는 XGBoost 알고리즘을 사용하여 모델을 훈련시키려는 경우 use_automl_step을 False로 설정할 수 있습니다.
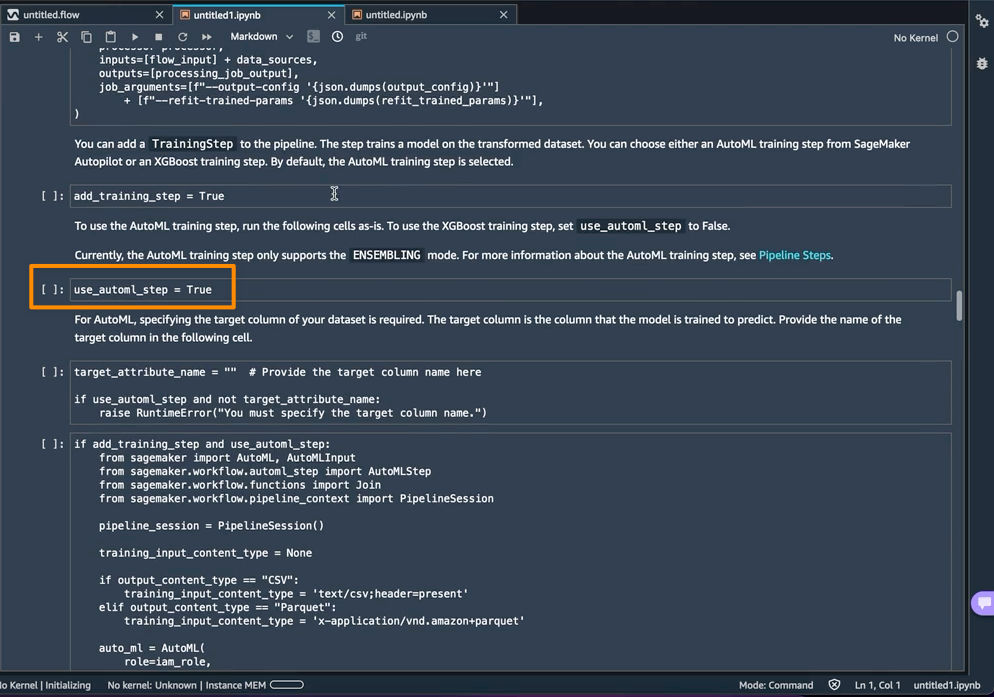
반면에 이 노트북 외부에서 학습한 모델을 대신 사용하려면 노트북의 Create SageMaker Inference Pipeline(SageMaker Inference Pipeline 생성) 섹션으로 바로 건너뛰면 됩니다. 여기서는 byo_model 변수의 값을 True로 설정해야 합니다. 또한 모델이 위치해 있는 Amazon Simple Storage Service(S3) URI인 algo_model_uri 값도 제공해야 합니다. 노트북으로 모델을 학습할 때 이러한 값은 자동으로 채워집니다.
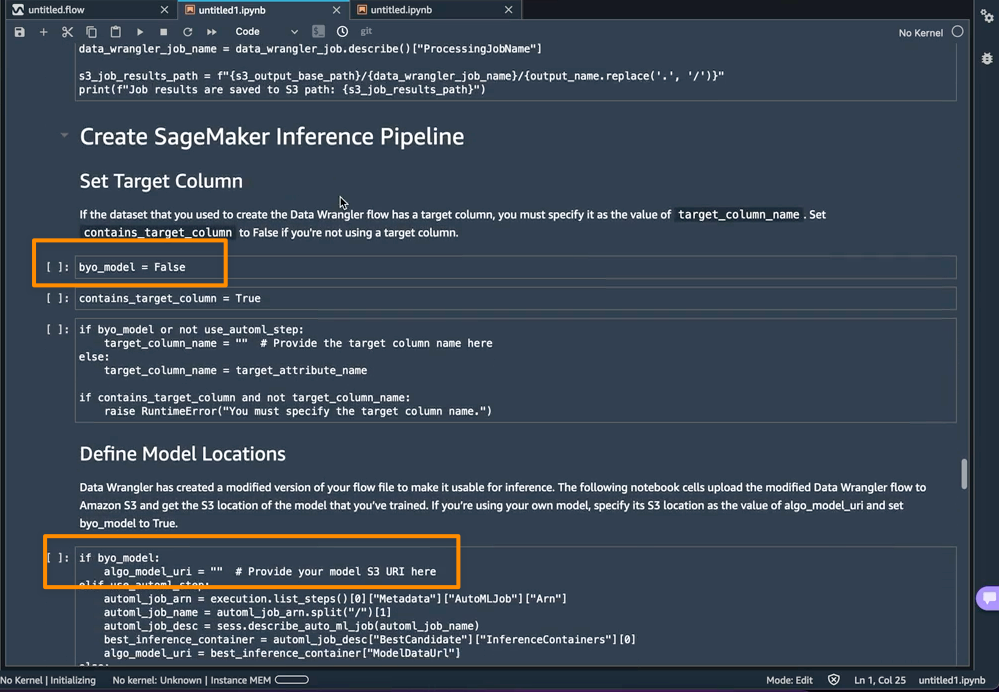
또한 이 기능은 SageMaker Studio 인스턴스의 data_wrangler_inference_flows 폴더 내에 타르볼을 저장합니다. 이 파일은 추론 시 적용할 데이터 변환 단계가 포함된 SageMaker Data Wrangler 흐름의 수정된 버전입니다. 노트북에서 S3로 업로드되므로 추론 파이프라인에서 SageMaker Data Wrangler 전처리 단계를 생성하는 데 사용할 수 있습니다.
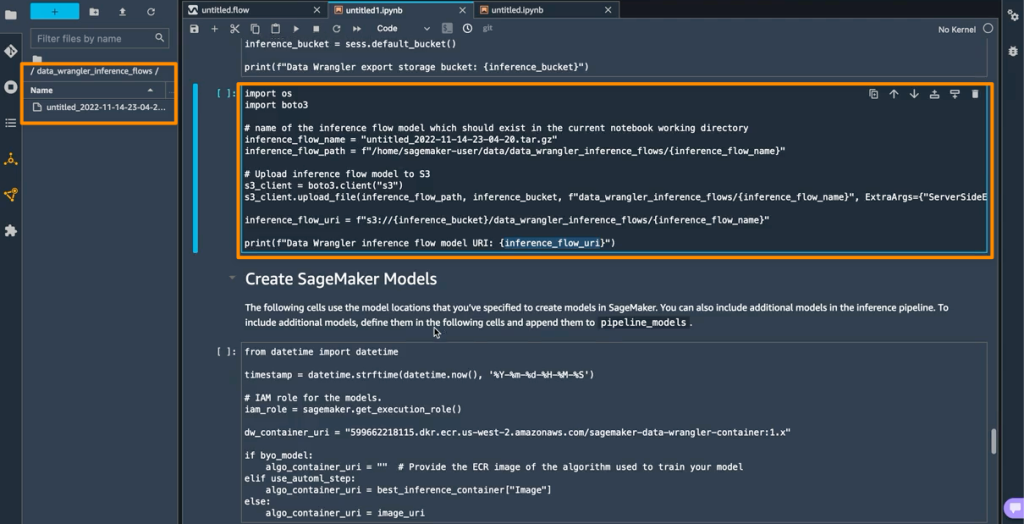
다음 단계는 이 노트북에서 두 개의 SageMaker 모델 객체를 만드는 것입니다. 첫 번째 객체 모델은 변수 data_wrangler_model이 있는 SageMaker Data Wrangler 모델 객체이고, 두 번째 모델은 변수 algo_model이 있는 알고리즘의 모델 객체입니다. 객체 data_wrangler_model은 예측을 위해 algo_model로 처리된 데이터 형식으로 입력을 제공하는 데 사용됩니다.
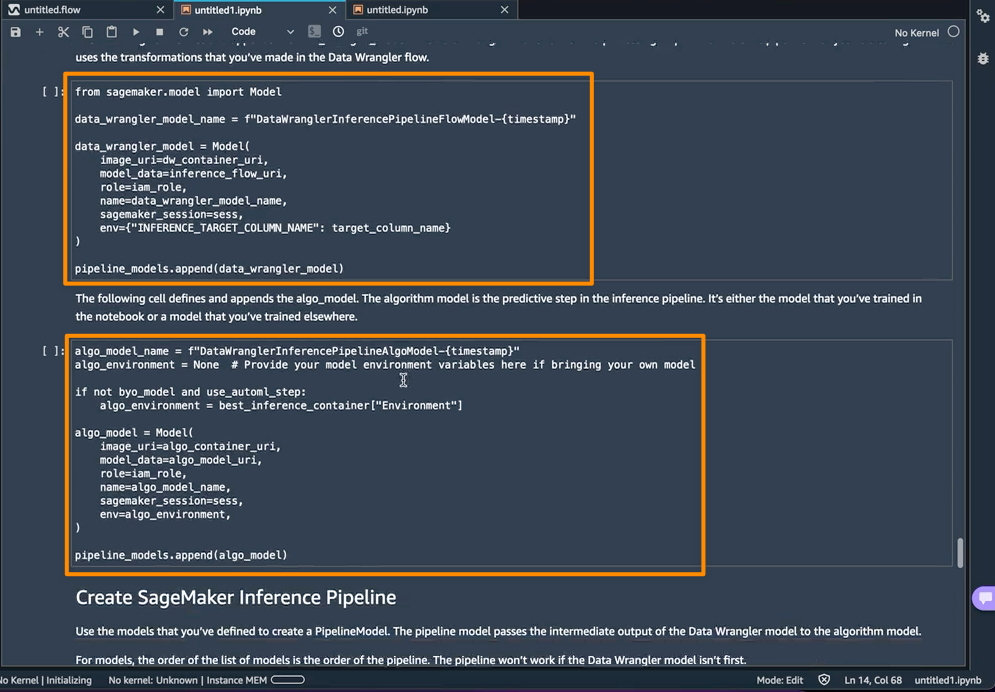
이 노트북의 마지막 단계는 SageMaker 추론 파이프라인 모델을 만들어 엔드포인트에 배포하는 것입니다.
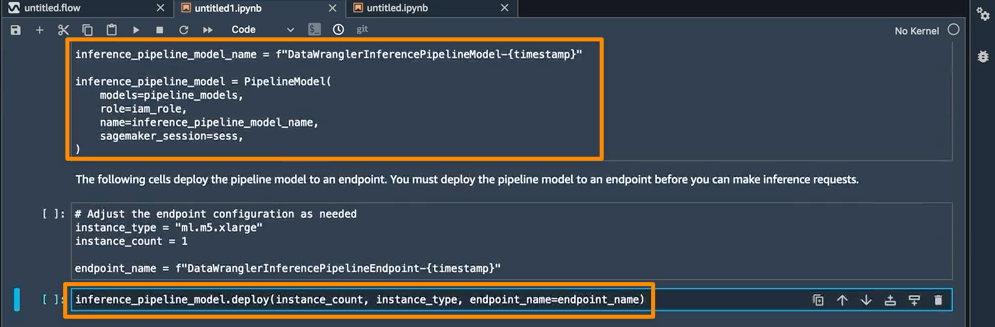
배포가 완료되면 예측에 사용할 수 있는 추론 엔드포인트가 제공됩니다. 이 기능을 통해 추론 파이프라인은 SageMaker Data Wrangler 흐름을 사용하여 추론 요청의 데이터를 훈련된 모델이 사용할 수 있는 형식으로 변환합니다.
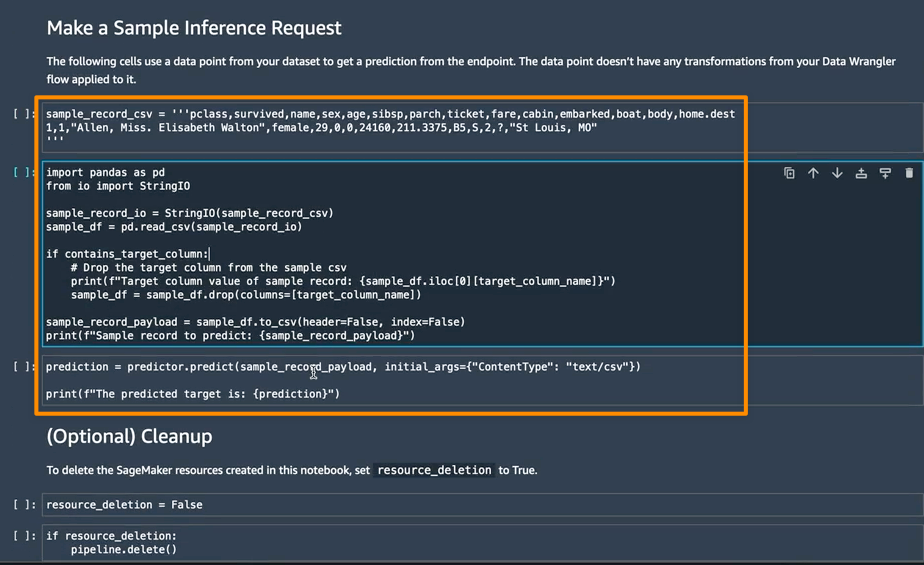
다음 섹션에서는 Make a Sample Inference Request(샘플 추론 요청 만들기)에서 개별 노트북 셀을 실행할 수 있습니다. 이는 처리되지 않은 데이터에서 단일 데이터 포인트로 엔드포인트를 호출하여 엔드포인트가 작동하는지 빠르게 확인해야 하는 경우에 유용합니다. Data Wrangler는 이 데이터 포인트를 노트북에 자동으로 배치하므로 따로 수동으로 제공할 필요가 없습니다.
주요 사항
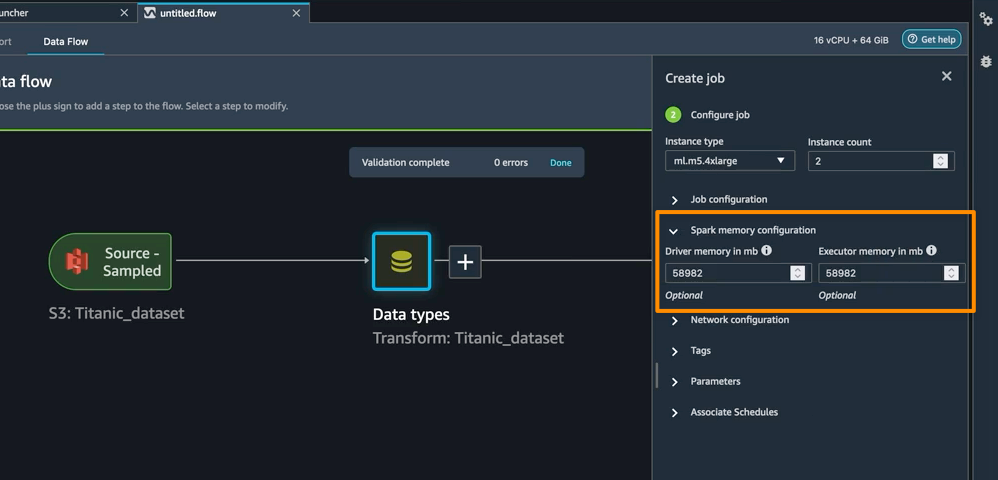
Enhanced Apache Spark configuration(향상된 Apache Spark 구성) – SageMaker Data Wrangler의 이번 릴리스에서는 이제 Amazon S3에 데이터를 저장할 때 Apache Spark가 SageMaker Data Wrangler 작업의 출력을 분할하는 방법을 쉽게 구성할 수 있습니다. 대상 노드를 추가할 때 Amazon S3에 기록될 파일 수에 해당하는 파티션 수를 설정하고, 분할 기준으로 사용할 열 이름을 지정하여 해당 열의 값이 다른 레코드를 Amazon S3의 다른 하위 디렉터리에 쓸 수 있습니다. 또한 제공된 노트북에서 구성을 정의할 수도 있습니다.

또한 Create job(작업 생성) 워크플로의 일부로 SageMaker Data Wrangler 처리 작업에 대한 메모리 구성을 정의할 수 있습니다. 노트북의 일부로 유사한 구성을 찾을 수 있습니다.
Availability(가용성) – SageMaker Data Wrangler는 데이터 처리 워크로드를 위한 향상된 Apache Spark 구성뿐만 아니라 실시간 및 일괄 추론을 지원하며 Data Wrangler가 현재 지원하는 모든 AWS 리전에서 일반적으로 사용할 수 있습니다.
실시간 및 일괄 추론 배포를 지원하는 Amazon SageMaker Data Wrangler를 시작하려면 AWS 설명서를 참조하세요.
즐거운 빌드되세요
– Donnie
Source: Amazon SageMaker Data Wrangler – 실시간 및 일괄 추론 지원 기능 출시


Leave a Reply