Amazon SageMaker JumpStart, Meta의 Llama 2 파운데이션 모델 지원
Amazon SageMaker JumpStart를 통해 AWS 고객이 Meta에서 개발한 Llama 2 파운데이션 모델(Foundation Model)을 사용할 수 있게 되었습니다. 대규모 언어 모델(LLM)의 Llama 2 제품군은 70억에서 700억 매개변수를 가진 사전 훈련 및 미세 조정된 생성 텍스트 모델 모음입니다. Llama-2-chat이라고 하는 미세 조정된 LLM은 대화형 활용 사례에 최적화되어 있습니다. 이러한 모델을 쉽게 시험해보고 기계 학습(ML)을 빠르게 시작할 수 있도록 알고리즘, 모델 및 ML 솔루션에 대한 액세스를 제공하는 기계 학습(ML) 허브인 SageMaker JumpStart와 함께 사용할 수 있습니다.
이 글에서는 Amazon SageMaker JumpStart를 통해 Llama 2 모델을 사용하는 방법을 살펴봅니다.
Llama 2 소개
Llama 2는 최적화된 트랜스포머 (Transformar) 아키텍처를 사용하는 자동 회귀 언어 모델입니다. Llama 2는 영어에 최적화되어 있고, 상업용 및 연구용으로 사용 가능합니다. 70억, 130억, 700억 등의 다양한 매개변수 크기와 사전 훈련 및 미세 조정된 변형으로 제공됩니다.
Meta에 따르면 튜닝된 버전은 지도 학습 기반 미세 조정(SFT) 및 사람의 피드백을 통한 강화 학습(RLHF)을 사용하여 유용성과 안전에 대한 요구 사항을 충족합니다. Llama 2는 공개적으로 사용 가능한 데이터 소스에서 2조 개의 데이터 토큰으로 사전 훈련되었습니다. 튜닝된 모델은 비서와 같은 채팅을 위한 반면 사전 훈련된 모델은 다양한 자연어 생성 작업에 맞게 조정할 수 있습니다. 개발자가 사용하는 모델의 버전에 관계없이, Meta의 책임 있는 사용 가이드는 적절한 안전 완화로 모델을 사용자 정의하고 최적화하는 데 필요할 수 있는 추가 미세 조정을 안내하는 데 도움을 줄 수 있습니다.
Amazon SageMaker JumpStart란?
Amazon SageMaker JumpStart를 통해 ML 실무자는 공개적으로 사용 가능한 다양한 파운데이션 모델 중에서 선택할 수 있습니다. ML 실무자는 네트워크 격리 환경에서 전용 Amazon SageMaker 인스턴스에 기초 모델을 배포하고 모델 교육 및 배포를 위해 SageMaker를 사용하여 모델을 사용자 지정할 수 있습니다.
Amazon SageMaker Studio에서 클릭 몇 번으로 또는 SageMaker Python SDK를 통해 프로그래밍 방식으로 Llama 2를 검색 및 배포할 수 있으므로 Amazon SageMaker Pipelines, Amazon SageMaker Debugger 또는 컨테이너 로그와 같은 SageMaker 기능을 사용하여 모델 성능 및 MLOps 제어를 파생할 수 있습니다. 이 모델은 AWS 보안 환경과 VPC 제어에 배포되어 데이터 보안을 보장합니다. Llama 2 모델은 현재 Amazon SageMaker Studio에서 처음에는 us-east-1 및 us-west-2 리전에서 사용할 수 있습니다.
Llama 2 모델 살펴보기
SageMaker Studio UI 및 SageMaker Python SDK에서 SageMaker JumpStart를 통해 파운데이션 모델에 액세스할 수 있습니다. 이 섹션에서는 SageMaker Studio에서 모델을 검색하는 방법을 살펴봅니다.
SageMaker Studio는 데이터 준비에서 ML 모델 구축, 훈련 및 배포에 이르기까지 모든 ML 개발 단계를 수행하기 위해 특별히 제작된 도구에 액세스할 수 있는 단일 웹 기반 시각적 인터페이스를 제공하는 통합 개발 환경(IDE)입니다. SageMaker Studio 시작 및 설정 방법에 대한 자세한 내용은 Amazon SageMaker Studio를 참조하시기 바랍니다.
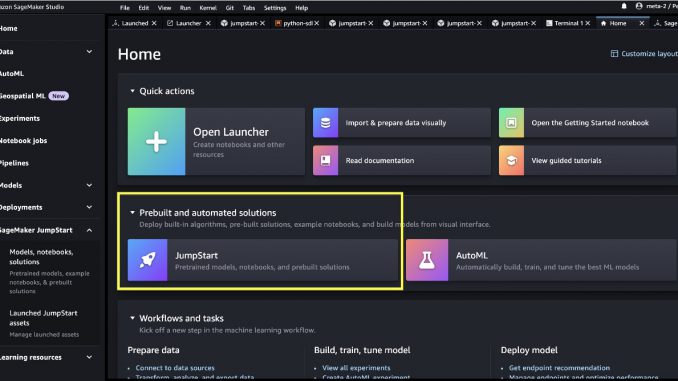
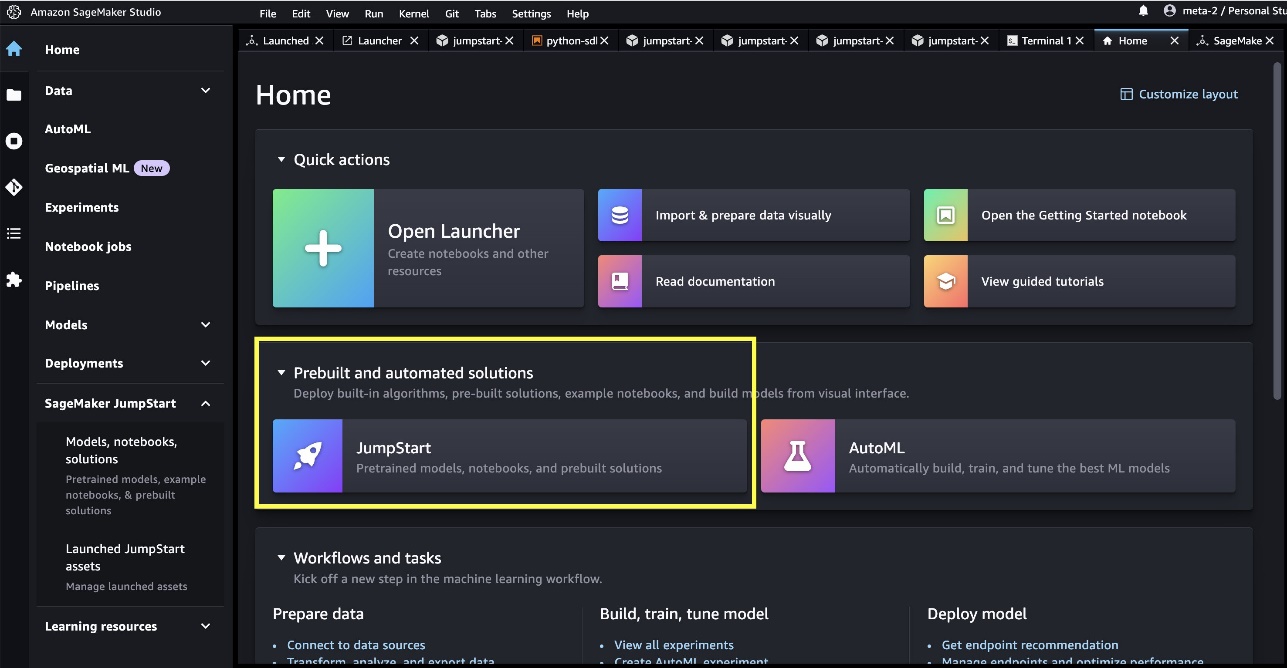
SageMaker Studio에서 Prebuilt and automated solutions 에서 사전 훈련된 모델, 노트북 및 사전 구축된 솔루션이 포함된 SageMaker JumpStart에 액세스할 수 있습니다 .

SageMaker JumpStart 랜딩 페이지에서 솔루션, 모델, 노트북 및 기타 리소스를 찾아볼 수 있습니다. Foundation Models: Text Generation에서 두 개의 주력 Llama 2 모델을 찾을 수 있습니다.
| Llama 2 모델이 표시되지 않으면 종료했다가 다시 시작하여 SageMaker Studio 버전을 업데이트하시기 바랍니다. 더 자세한 것은 Studio 앱 종료 및 업데이트를 참고하시기 바랍니다. |

다른 네 가지 모델도 함께 볼 수 있습니다. Explore all Text Generation Models을 선택 하거나 검색창에 llama라고 쳐 보시면 됩니다.

모델 카드를 선택하여 라이선스, 훈련에 사용된 데이터, 사용 방법 등 모델에 대한 세부 정보를 볼 수 있습니다. 모델을 사용하려면, Deploy 및 Open Notebook 버튼을 클릭하면 됩니다.

두 버튼 중 하나를 선택하면, 최종 사용자 라이선스 계약 및 수락 가능한 사용 정책이 팝업에 표시됩니다.

동의하면 모델 사용을 위한 다음 단계로 진행됩니다.
모델 배포
Deploy를 선택하고, 사용 조건을 확인하며, 바로 모델 배포가 시작됩니다. 또는 Open Notebook를 선택하여 표시되는 예시 노트북을 통해 배포할 수 있습니다. 예제 노트북은 추론을 위해 모델을 배포하고 리소스를 정리하는 방법에 대한 종단 간 지침을 제공합니다.
노트북을 사용하여 배포하려면 먼저 model_id로 지정된 적절한 모델을 선택합니다. 다음 코드를 사용하여 SageMaker에서 선택한 모델을 배포할 수 있습니다.
이렇게 하면 기본 인스턴스 유형 및 기본 VPC 구성을 포함한 기본 구성으로 SageMaker에 모델이 배포됩니다. JumpStartModel에서 기본값이 아닌 값을 지정하여, 배포 구성을 변경할 수 있습니다. 배포 후 SageMaker predictor를 통해 배포된 엔드포인트에 대해 추론을 실행할 수 있습니다.
미세 조정된 채팅 모델(Llama-2-7b-chat, Llama-2-13b-chat, Llama-2-70b-chat)은 사용자와 채팅 도우미 간의 채팅 기록을 수락하고 후속 채팅을 생성합니다. 사전 훈련된 모델(Llama-2-7b, Llama-2-13b, Llama-2-70b)에는 문자열 프롬프트가 필요하며 제공된 프롬프트에서 텍스트 완성을 수행합니다. 다음 코드를 참조하세요.
accept_eula의 기본 값은 false로 설정됩니다. 엔드포인트에 제대로 호출하려면, accept_eula=true로 설정하셔야 합니다. 그렇게 함으로서 사용자 라이선스 계약 및 사용 제한 정책에 동의하게 됩니다. 사용권 계약을 다운로드할 수도 있습니다.
Custom_attributes은 사용권 계약(EULA)를 통과하는 데 사용되는 키/값 쌍입니다. 키와 값은 =로 구분되고 쌍은 ;으로 구분됩니다. 사용자가 동일한 키를 두 번 이상 전달하면 마지막 값이 유지되고 스크립트 처리기로 전달됩니다(즉, 이 경우 조건 논리에 사용됨). 예를 들어, accept_eula=false이면; accept_eula=true가 서버에 전달된 다음 accept_eula=true가 유지되고 스크립트 처리기로 전달됩니다.
Inference parameters는 엔드 포인트에서 텍스트 생성 프로세스를 제어합니다. 최대 새 토큰 제어값은 모델에서 생성된 출력의 크기를 나타냅니다. 이는 모델의 어휘가 영어 어휘와 동일하지 않고 각 토큰이 영어 단어가 아닐 수 있기 때문에 단어 수와 같지 않음에 유의하시기 바랍니다. Temperature는 출력의 임의성을 제어합니다. 더 높은 온도는 더 창의적이고 환각적인 결과를 낳습니다. 모든 추론 매개변수는 선택 사항입니다.
다음 표는 SageMaker JumpStart에서 사용할 수 있는 모든 Llama 모델과 model_ids, 기본 인스턴스 유형 및 이러한 각 모델에 대해 지원되는 최대 총 토큰 수(입력 토큰 수와 생성된 토큰 수의 합계)를 정리한 것입니다.
| 모델명 | 모델 ID | 최대 총 토큰 | 기본 인스턴스 유형 |
| Llama-2-7b | meta-textgeneration-llama-2-7b | 4096 | ml.g5.2xlarge |
| Llama-2-7b-chat | meta-textgeneration-llama-2-7b-f | 4096 | ml.g5.2xlarge |
| Llama-2-7b-2-13b | meta-textgeneration-llama-2-13b | 4096 | ml.g5.12xlarge |
| Llama-2-7b-2-13b-chat | meta-textgeneration-llama-2-13b-f | 4096 | ml.g5.12xlarge |
| Llama-2-7b-2-70b | meta-textgeneration-llama-2-70b | 4096 | ml.g5.48xlarge |
| Llama-2-7b-2-70b-chat | meta-textgeneration-llama-2-70b-f | 4096 | ml.g5.48xlarge |
SageMaker 엔드 포인트의 제한 시간은 60초입니다. 따라서 모델이 4096개의 토큰을 생성할 수 있더라도 텍스트 생성에 60초 이상이 소요되면 요청이 실패합니다. 7B, 13B 및 70B 모델의 경우, max_new_tokens총 토큰 수를 4K 미만으로 유지하면서 각각 1500, 1000 및 500보다 크지 않도록 할 필요가 있습니다.
Llama-2-70b에 대한 추론 및 예제 프롬프트
이제 질문에 대한 텍스트 생성을 위해 Llama 모델을 사용할 수 있습니다. 텍스트 생성을 통해 질문에 답하기, 언어 번역, 감정 분석 등과 같은 다양한 작업을 수행할 수 있습니다. 엔드포인트에 대한 샘플은 다음과 같습니다.
다음은 몇 가지 샘플 예제 프롬프트와 모델에서 생성된 텍스트입니다. 모든 출력은 추론 매개변수로 생성됩니다. {"max_new_tokens":256, "top_p":0.9, "temperature":0.6}.
다음 예에서는 모델에 사용할 수 있는 훈련 샘플을 제공하는 상황 내 학습과 함께 Llama 모델을 사용하는 방법을 보여줍니다. 배포된 모델에 대해서만 추론하고 이 프로세스 중에 모델 가중치는 변경되지 않습니다.
Llama-2-70b-chat에 대한 추론 및 예제 프롬프트
실시간 대화 사용 사례에 최적화된 Llama-2-Chat 모델의 경우, 채팅 모델 엔드포인트에 대한 입력은 채팅 도우미와 사용자 간의 이전 대화 기록입니다. 지금까지 진행된 대화와 관련하여 상황에 맞는 질문을 할 수 있습니다. 채팅 도우미의 동작을 정의하는 페르소나와 같은 시스템 구성을 제공할 수도 있습니다. 엔드포인트에 대한 입력 페이로드는 다음 코드와 같습니다.
다음은 몇 가지 샘플 예제 프롬프트와 모델에서 생성된 텍스트입니다. 모든 출력은 추론 매개변수로 생성됩니다. {"max_new_tokens": 512, "top_p": 0.9, "temperature": 0.6}.
다음 예에서 사용자는 파리의 관광지에 대해 채팅 도우미와 대화를 나눴습니다. 다음으로 사용자는 채팅 도우미가 추천하는 첫 번째 옵션에 대해 문의합니다.
다음 예에서는 시스템 구성을 설정합니다.












노트북 실행을 완료한 후 프로세스에서 생성한 모든 리소스가 삭제되고, 요금 청구가 중지되도록 모든 리소스를 삭제해야 합니다.
이 게시물에서는 SageMaker Studio에서 Llama 2 모델을 시작하는 방법을 설명했습니다. 이를 통해 수십억 개의 매개변수가 포함된 6개의 Llama 2 기초 모델에 액세스할 수 있습니다. 이러한 파운데이션 모델은 사전 훈련을 받았기 때문에 별도 훈련 및 인프라 비용을 낮추고 사용 사례에 맞게 사용자 지정할 수 있습니다. 더 자세한 것은 SageMaker JumpStart을 통한 파운데이션모델 시작하기를 살펴보세요.
– June Won, Product Manager, Amazon SageMaker JumpStart
– Dr. Vivek Madan, Applied Scientist, Amazon SageMaker JumpStart
– Dr. Kyle Ulrich, Applied Scientist, Amazon SageMaker JumpStart
– Dr. Ashish Khetan, Applied Scientist, Amazon SageMaker JumpStart
– Sundar Ranganathan, Global Head of GenAI/Frameworks GTM Specialists
이 글은 AWS Machine Learning Blog의 Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart 한국어 번역입니다.
Source: Amazon SageMaker JumpStart, Meta의 Llama 2 파운데이션 모델 지원


Leave a Reply