Amazon SageMaker Serverless Inference – 서버리스 기계 학습 추론 기능
2021년 12월, AWS는 기본 인프라를 구성하거나 관리할 필요 없이 추론을 위한 기계 학습(ML) 모델을 배포할 수 있도록 Amazon SageMaker의 새로운 옵션으로 Amazon SageMaker Serverless Inference(평가판)를 도입했습니다. 오늘 Amazon SageMaker Serverless Inference가 정식 출시 되었음을 발표하게 되어 기쁘게 생각합니다.
ML 추론 사용 사례에 따라 모델 호스팅 인프라에 대한 요구 사항이 달라집니다. 광고 게재, 사기 탐지 또는 맞춤형 제품 추천 등의 사용 사례를 다루는 경우, 응답 시간이 수 밀리초 이하인 API 기반 온라인 추론을 찾고 있을 것입니다. 컴퓨터 비전(CV) 애플리케이션과 같은 대규모 ML 모델로 작업하는 경우, 몇 분 내에 더 큰 페이로드 크기에서 추론을 실행하도록 최적화된 인프라가 필요할 수 있습니다. 전체 데이터 집합 또는 대규모 데이터 배치에 대한 예측을 실행하려는 경우, 모델 제공 엔드포인트를 호스팅하는 대신 온디맨드 일회성 일괄 추론 작업을 실행할 수 있습니다. 챗봇 서비스와 같이 트래픽 패턴이 간헐적인 애플리케이션이나 문서에서 양식을 처리하거나 데이터를 분석하는 애플리케이션이 있는 경우라면 어떨까요? 이 경우 추론 요청 볼륨에 따라 컴퓨팅 용량을 자동으로 프로비저닝하고 확장할 수 있는 온라인 추론 옵션이 필요할 수 있습니다. 그리고 유휴 시간 동안에는 요금이 부과되지 않도록 컴퓨팅 용량을 완전히 끌 수 있어야 합니다.
완전관리형 ML 서비스인 Amazon SageMaker는 이러한 모든 사용 사례를 지원하기 위해 다양한 모델 추론 옵션을 제공합니다.
- 밀리초 단위로 지연 시간이 짧은 워크로드를 위한 SageMaker 실시간 추론
- 페이로드 크기가 크거나 처리 시간이 긴 추론을 위한 SageMaker 비동기식 추론
- 데이터 배치에 대한 예측을 실행하기 위한 SageMaker 배치 변환
- 트래픽 패턴이 간헐적이거나 드문 워크로드를 위한 SageMaker Serverless Inference
Amazon SageMaker Serverless Inference 세부 정보
ML 실무자와의 많은 대화를 통해, 모든 인프라가 관리되어 사용자는 추론 코드 개발에 집중할 수 있는 완전 관리형 ML 추론 옵션 요청을 선택했습니다. SageMaker Serverless Inference는 이제 이러한 간편한 배포를 제공합니다.
모델이 수신하는 추론 요청의 볼륨에 따라 SageMaker Serverless Inference는 컴퓨팅 용량을 자동으로 프로비저닝하고, 크기를 조정하고, 끕니다. 따라서 유휴 시간을 제외하고 추론 코드를 실행하는 데 필요한 컴퓨팅 시간과 처리된 데이터 양에 대해서만 비용을 지불하면 됩니다.
SageMaker의 내장 알고리즘 및 ML 프레임워크 제공 컨테이너를 사용하여 모델을 서버리스 추론 엔드포인트에 배포하거나 자체 컨테이너를 가져오도록 선택할 수 있습니다. 트래픽이 예측 가능하고 안정적이면 컨테이너 이미지를 변경할 필요 없이 서버리스 추론 엔드포인트에서 SageMaker 실시간 엔드포인트로 쉽게 업데이트할 수 있습니다. Serverless Inference를 사용하면 Amazon CloudWatch의 호출 수, 결함, 지연 시간, 호스트 지표 및 오류 등의 기본 제공 지표를 비롯한 SageMaker의 기능을 활용할 수도 있습니다.
평가판 출시 이후 SageMaker Serverless Inference에 SageMaker Python SDK 및 모델 레지스트리에 대한 지원이 추가되었습니다. SageMaker Python SDK는 SageMaker에서 ML 모델을 빌드하고 배포하기 위한 오픈 소스 라이브러리입니다. SageMaker 모델 레지스트리를 사용하면 모델을 카탈로그화하고, 버전을 지정하고, 프로덕션에 배포할 수 있습니다.
정식 버전 출시에 더해 새로운 기능인 SageMaker Serverless Inference는 엔드포인트당 최대 동시 호출 수 제한을 200개(평가판에서는 50개)로 늘렸습니다. 따라서 트래픽이 많은 워크로드에 Amazon SageMaker Serverless Inference를 사용할 수 있습니다. Amazon SageMaker Serverless Inference는 이제 Amazon SageMaker를 사용할 수 있는 모든 AWS 리전에서 사용할 수 있습니다. 단, AWS GovCloud(미국) 및 AWS 중국 리전은 제외됩니다.
일부 고객이 이미 SageMaker Serverless Inference의 이점을 활용하기 시작했습니다.
“Bazaarvoice는 기계 학습을 활용하여 사용자 생성 콘텐츠를 조정하고 적시에 신뢰할 수 있는 방식으로 고객에게 원활한 쇼핑 경험을 제공합니다. 그러나 다양한 고객 기반에서 글로벌 규모로 운영하려면 매우 다양한 모델이 필요하며, 그 중 다수는 자주 사용되지 않거나 콘텐츠의 급격한 폭증으로 인해 크기를 신속하게 조정해야 합니다. Amazon SageMaker Serverless Inference는 두 가지 장점을 모두 제공합니다. 콘텐츠가 급증하는 동안 빠르고 원활하게 확장되고 자주 사용되지 않는 모델의 비용을 절감합니다.” – Lou Kratz 박사, Bazaarvoice 수석 연구 엔지니어
“Transformers는 기계 학습을 변화시켰으며 Hugging Face는 자연어 처리부터 오디오 및 컴퓨터 비전에 이르기까지 기업 전반에 걸쳐 채택을 주도하고 있습니다. 전 세계 기계 학습 팀의 새로운 개척지는 비용 효율적인 방식으로 크고 강력한 모델을 배포하는 것입니다. Amazon SageMaker Serverless Inference를 테스트한 결과, 인프라를 분리하면서 간헐적인 트래픽 워크로드에 대한 비용을 대폭 절감할 수 있었습니다. 우리는 SageMaker Serverless Inference를 통해 Hugging Face 모델을 즉시 사용할 수 있도록 지원하여 고객이 기계 학습 비용을 훨씬 더 절감할 수 있도록 지원했습니다.” – Jeff Boudier, Hugging Face 제품 디렉터
이제 SageMaker Serverless Inference를 시작하는 방법을 살펴보겠습니다.
이 데모에서는 ‘제품이 마음에 들어요!’와 같은 전자 상거래 고객 리뷰를 긍정적(1), 중립(0) 및 부정적(-1) 감정으로 변환하는 텍스트 분류기를 구축했습니다. 여성 전자 상거래 의류 리뷰 데이터 집합을 사용하여 Hugging Face Transformers 라이브러리 및 모델 허브에서 RoBERTa 모델을 미세 조정했습니다. 이제 훈련된 모델을 Amazon SageMaker Serverless Inference 엔드포인트에 배포하는 방법을 보여드리겠습니다.
Amazon SageMaker Serverless Inference 엔드포인트에 모델 배포
SageMaker 콘솔, AWS SDK, SageMaker Python SDK, AWS CLI 또는 AWS CloudFormation을 사용하여 서버리스 추론 엔드포인트를 생성, 업데이트, 설명 및 삭제할 수 있습니다. 이 첫 번째 예제에서는 SageMaker Python SDK를 사용하여 추상화를 통해 모델 배포 워크플로를 단순화합니다. SageMaker Python SDK를 사용하여 요청에 따라 페이로드를 인라인으로 전달해 엔드포인트를 호출할 수도 있습니다. 조금 있다가 보여드리겠습니다.
먼저 원하는 서버리스 구성으로 엔드포인트 구성을 생성해 보겠습니다. 메모리 크기와 최대 동시 호출 수를 지정할 수 있습니다. SageMaker Serverless Inference는 선택한 메모리에 비례하여 컴퓨팅 리소스를 자동 할당합니다. 더 큰 메모리 크기를 선택하면 컨테이너가 더 많은 vCPU에 액세스할 수 있습니다. 일반적으로 메모리 크기는 적어도 모델 크기만큼 커야 합니다. 선택할 수 있는 메모리 크기는 1024MB, 2048MB, 3072MB, 4096MB, 5120MB 및 6144MB입니다. 이 RoBERTa 모델의 경우 5120MB의 메모리 크기와 동시 호출 최대 다섯 개로 구성해 보겠습니다.
import sagemaker
from sagemaker.serverless import ServerlessInferenceConfig
serverless_config = ServerlessInferenceConfig(
memory_size_in_mb=5120,
max_concurrency=5
)
이제 모델을 배포해 보겠습니다. estimator.deploy() 메서드를 사용하여 서버리스 추론 엔드포인트 구성과 함께 SageMaker 훈련 예측기에서 직접 모델을 배포할 수 있습니다. 이 예제에서는 사용자 지정 추론 코드도 제공합니다.
endpoint_name="roberta-womens-clothing-serverless-1"
estimator.deploy(
endpoint_name = endpoint_name,
entry_point="inference.py",
serverless_inference_config=serverless_config
)
SageMaker Serverless Inference는 Python용 AWS SDK(Boto3)를 사용할 때 모델 레지스트리도 지원합니다. 이 게시물의 뒷부분에서 모델 레지스트리에서 모델을 배포하는 방법을 보여드리겠습니다.
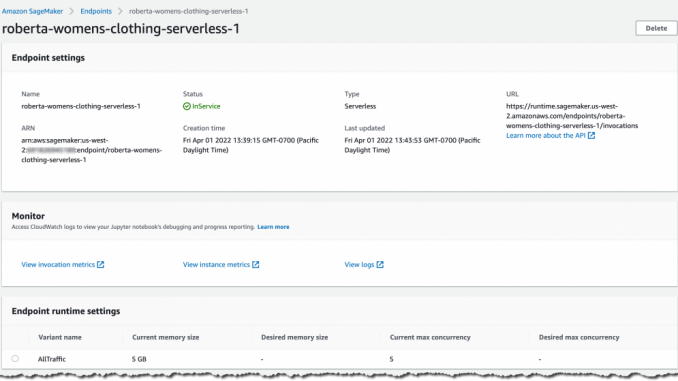
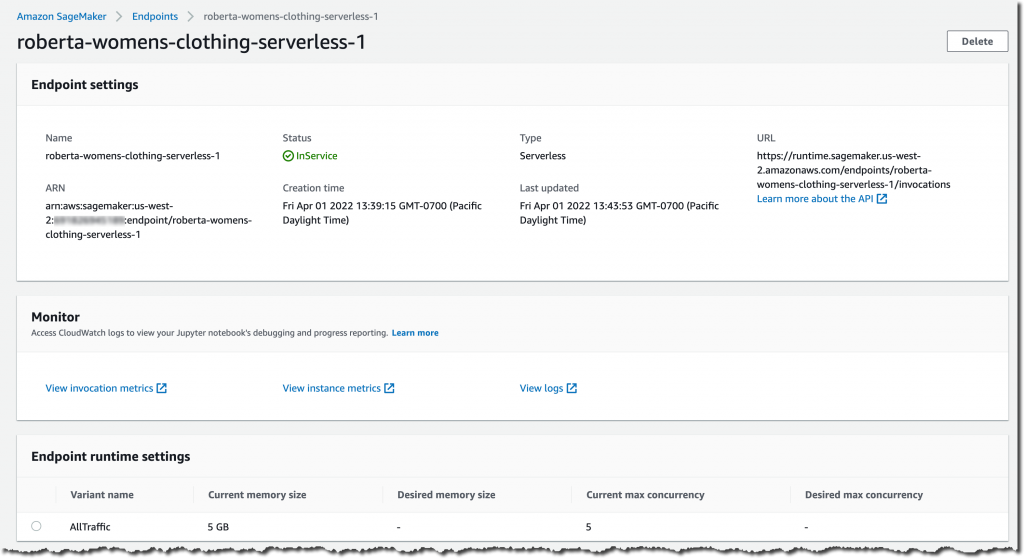
서버리스 추론 엔드포인트 설정과 배포 상태를 확인해 보겠습니다. SageMaker 콘솔로 이동하여 배포된 추론 엔드포인트로 이동합니다.

필요한 경우 SageMaker 콘솔에서 서버리스 추론 엔드포인트를 생성, 업데이트 또는 삭제할 수도 있습니다. Amazon SageMaker Studio에서 엔드포인트 탭과 서버리스 추론 엔드포인트를 선택하여 엔드포인트 구성 세부 정보를 검토합니다.

엔드포인트 상태가 InService로 표시되면 추론 요청 전송을 시작할 수 있습니다.
이제 몇 가지 샘플 예측을 실행해 보겠습니다. 미세 조정된 RoBERTa 모델은 검토 텍스트가 포함된 JSON Lines 형식의 추론 요청을 입력 기능으로 분류할 것으로 예상합니다. JSON Lines 텍스트 파일은 줄 바꿈 문자로 구분된 여러 줄로 구성되며 각 줄은 유효한 JSON 객체입니다. 이 형식은 모델 추론 과정과 같이 한 번에 한 레코드씩 처리되는 데이터를 저장하는 데 이상적인 형식입니다. Amazon SageMaker 개발자 안내서에서 추론을 위한 JSON Lines 및 기타 일반적인 데이터 형식에 대해 자세히 알아볼 수 있습니다. 다음 코드는 모델에 허용되는 추론 요청 형식에 따라 다르게 보일 수 있습니다.
from sagemaker.predictor import Predictor
from sagemaker.serializers import JSONLinesSerializer
from sagemaker.deserializers import JSONLinesDeserializer
sess = sagemaker.Session(sagemaker_client=sm)
inputs = [
{"features": ["I love this product!"]},
{"features": ["OK, but not great."]},
{"features": ["This is not the right product."]},
]
predictor = Predictor(
endpoint_name=endpoint_name,
serializer=JSONLinesSerializer(),
deserializer=JSONLinesDeserializer(),
sagemaker_session=sess
)
predicted_classes = predictor.predict(inputs)
for predicted_class in predicted_classes:
print("Predicted class {} with probability {}".format(predicted_class['predicted_label'], predicted_class['probability']))
결과는 샘플 검토를 해당 감정 클래스로 분류한 것으로 다음과 유사하게 표시됩니다.
Predicted class 1 with probability 0.9495596289634705
Predicted class 0 with probability 0.5395089387893677
Predicted class -1 with probability 0.7887083292007446
모델 레지스트리에서 SageMaker Serverless Inference 엔드포인트로 모델을 배포할 수도 있습니다. 이 방법은 현재 Python용 AWS SDK(Boto3)를 통해서만 지원됩니다. 또 다른 간단한 데모를 안내해 드리겠습니다.
SageMaker 모델 레지스트리에서 모델 배포
Boto3를 사용하여 모델 레지스트리에서 모델을 배포하기 위해, 먼저create_model() 메서드를 호출하여 모델 버전에서 모델 객체를 생성해 보겠습니다. 그런 다음 모델 객체의 컨테이너의 일부로 모델 버전의 Amazon 리소스 이름(ARN)을 전달합니다.
import boto3
import sagemaker
sm = boto3.client(service_name='sagemaker')
role = sagemaker.get_execution_role()
model_name="roberta-womens-clothing-serverless"
container_list =
[{'ModelPackageName': <MODEL_PACKAGE_ARN>}]
create_model_response = sm.create_model(
ModelName = model_name,
ExecutionRoleArn = role,
Containers = container_list
)
다음으로 서버리스 추론 엔드포인트를 생성합니다. 서버리스 추론 엔드포인트를 생성, 업데이트, 설명 및 삭제할 때 SageMaker 콘솔, AWS SDK, SageMaker Python SDK, AWS CLI 또는 AWS CloudFormation을 사용할 수 있음을 기억하세요. 일관성을 위해 이 두 번째 예에서는 Boto3를 계속 사용합니다.
첫 번째 예와 마찬가지로, 먼저 원하는 서버리스 구성으로 엔드포인트 구성을 생성합니다. 엔드포인트에 대해 메모리 크기는 5120MB로, 동시 호출 수는 최대 5개로 지정합니다.
endpoint_config_name="roberta-womens-clothing-serverless-ep-config"
create_endpoint_config_response = sm.create_endpoint_config(
EndpointConfigName = endpoint_config_name,
ProductionVariants=[{
'ServerlessConfig':{
'MemorySizeInMB' : 5120,
'MaxConcurrency' : 5
},
'ModelName':model_name,
'VariantName':'AllTraffic'}])
다음으로 create_endpoint() 메서드를 호출하여 SageMaker Serverless Inference 엔드포인트를 생성합니다.
endpoint_name="roberta-womens-clothing-serverless-2"
create_endpoint_response = sm.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name)
엔드포인트 상태가 InService로 표시되면 추론 요청 전송을 시작할 수 있습니다. 다시 일관성을 위해 Boto3 및 SageMaker 런타임 클라이언트 invoke_endpoint() 메서드를 사용하여 샘플 예측을 실행하도록 선택합니다.
sm_runtime = boto3.client("sagemaker-runtime")
response = sm_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/jsonlines",
Accept="application/jsonlines",
Body=bytes('{"features": ["I love this product!"]}', 'utf-8')
)
print(response['Body'].read().decode('utf-8'))
{"probability": 0.966135561466217, "predicted_label": 1}
SageMaker Serverless Inference를 위해 모델을 최적화하는 방법
SageMaker Serverless Inference는 자동으로 기본 컴퓨팅 리소스의 크기를 조정하여 요청을 처리합니다. 엔드포인트가 한동안 트래픽을 수신하지 않으면 컴퓨팅 리소스를 축소합니다. 엔드포인트가 갑자기 새 요청을 수신하는 경우 엔드포인트가 요청을 처리하기 위해 컴퓨팅 리소스를 확장하는 데 약간의 시간이 걸릴 수 있습니다.
이 콜드 스타트 시간은 모델 크기와 컨테이너의 시동 시간에 따라 크게 달라집니다. 콜드 스타트 시간을 최적화하기 위해 지식 증류(Knowledge Distillation), 양자화(Quantization) 또는 모델 가지치기(Model Pruning)와 같은 기술을 적용하여 모델 크기 최소화를 시도할 수 있습니다.
지식 증류는 더 큰 모델(교사 모델)을 사용해 더 작은 모델(학생 모델)을 훈련시켜 동일한 태스크를 해결합니다. 양자화는 모델 파라미터를 나타내는 숫자의 정밀도를 32비트 부동 소수점 숫자에서 16비트 부동 소수점 또는 8비트 정수로 줄입니다. 모델 가지치기는 훈련 과정에 거의 기여하지 않는 중복 모델 파라미터를 제거합니다.
가용성 및 요금
Amazon SageMaker Serverless Inference는 이제 Amazon SageMaker를 사용할 수 있는 모든 AWS 리전에서 사용할 수 있습니다. 단, AWS GovCloud(미국) 및 AWS 중국 리전은 제외됩니다.
SageMaker Serverless Inference를 사용하면 추론 요청을 처리하는 데 사용된 컴퓨팅 용량(밀리초 단위로 청구)과 처리된 데이터 양에 대해서만 비용을 지불합니다. 컴퓨팅 용량 요금은 선택한 메모리 구성에 따라 달라집니다. 자세한 가격 정보는 SageMaker 요금 페이지를 참조하세요.
Amazon SageMaker Serverless Inference 지금 시작하기
Amazon SageMaker Serverless Inference에 대해 자세히 알아보려면 Amazon SageMaker 기계 학습 추론 웹페이지를 참조하세요. 다음은 바로 시작하는 데 도움이 되는 SageMaker Serverless Inference 예제 노트북입니다. SageMaker 콘솔에서 사용해 보고 의견이 있으면 공유해 주시기 바랍니다.
– Antje
Source: Amazon SageMaker Serverless Inference – 서버리스 기계 학습 추론 기능


Leave a Reply