Apache Airflow, Genie 및 Amazon EMR을 통한 빅데이터 워크플로 오케스트레이션 – 2부
AWS에서 빅 데이터 ETL 워크플로를 실행하는 대기업은 많은 내부 최종 사용자를 지원하는 대규모로 운영하며 수천 개의 동시 파이프라인을 실행합니다. 이러한 상황과 새로운 프레임워크 및 빅데이터 프로세싱 프레임워크의 최신 릴리스에 보조를 맞추기 위해 빅 데이터 플랫폼을 지속적으로 업데이트 및 확장해야 하는 필요성에 따라, 빅 데이터 플랫폼의 관리를 간소화할 뿐 아니라 빅 데이터 애플리케이션에 대한 간편한 액세스를 지원하는 효율적인 아키텍처 및 조직적 구조가 요구되고 있습니다.
이 게시물 시리즈의 1부에서는 Apache Airflow, Genie 및Amazon EMR을 사용하여 빅 데이터 워크플로를 관리하는 방법에 대해 배웠습니다.
이 게시물은 AWS CloudFormation 템플릿을 배포하고, Genie를 구성하고, Apache Airflow에서 작성한 예제 워크플로를 실행하는 방법을 단계별로 안내합니다.
사전 조건
이 단계별 안내를 위해서는 다음과 같은 사전 조건을 갖추어야 합니다.
솔루션 개요
이 솔루션은 AWS CloudFormation 템플릿을 사용하여 필수 리소스를 생성합니다.
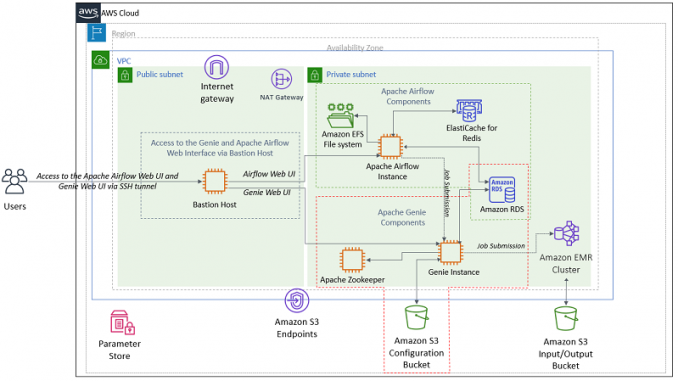
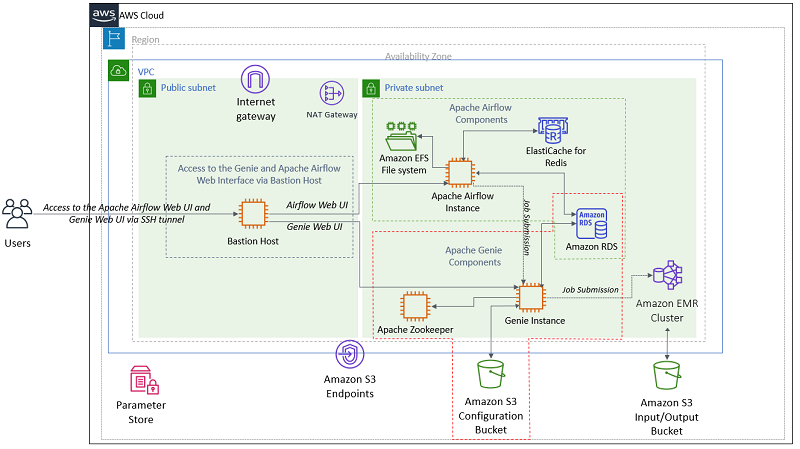
사용자는 배스천 호스트에 대한 SSH 터널을 통해 Apache Airflow 웹 UI 및 Genie 웹 UI에 액세스합니다.
Apache Airflow 배포는 Amazon ElastiCache for Redis를 Celery 백엔드로, Amazon EFS를 DAG를 저장할 마운트 지점으로, Amazon RDS PostgreSQL을 데이터베이스 서비스로 사용합니다.
Genie는 리더 선출을 위해 Apache Zookeeper, 구성(바이너리, 애플리케이션 종속성, 클러스터 메타데이터) 저장을 위해 Amazon S3 버킷을, 데이터베이스 서비스를 위해 Amazon RDS PostgreSQL을 사용합니다. Genie는 작업을 Amazon EMR 클러스터에 제출합니다.
이 게시물의 아키텍처는 데모 용도로 제공되었습니다. 프로덕션 환경에서는 Apache Airflow와 Genie 인스턴스가 Auto Scaling 그룹의 일부가 되어야 합니다. 자세한 내용은 Genie Reference Guide의 Deployment를 참조하십시오.
다음 다이어그램은 솔루션 아키텍처를 보여줍니다.

AWS Systems Manager Parameter Store에 관리자 암호 생성 및 저장
이 솔루션은 AWS Systems Manager Parameter Store를 사용하여 구성 스크립트에 사용되는 암호를 저장합니다. AWS Systems Manager Parameter Store를 사용하면 일반 텍스트 파라미터 이름과 암호화된 파라미터 값을 가진 보안 문자열 파라미터를 생성할 수 있습니다. Parameter Store는 AWS KMS를 사용하여 보안 문자열 파라미터의 파라미터 값을 암호화 및 암호 해독합니다.
AWS CloudFormation 템플릿을 배포하기 전에 다음 AWS CLI 명령을 실행합니다. 이러한 명령은 RDS 마스터 사용자, Airflow DB 관리자 및 Genie DB 관리자에 대한 암호를 저장할 AWS Systems Manager Parameter Store 파라미터를 생성합니다.
솔루션을 위한 Amazon S3 버킷 생성 및 S3에 솔루션 아티팩트 업로드
이 솔루션은 Amazon S3를 사용하여 솔루션에서 사용되는 모든 아티팩트를 저장합니다. AWS CloudFormation 템플릿을 배포하기 전에 Amazon S3 버킷을 생성하고 이 링크에서 솔루션에 필요한 아티팩트를 다운로드합니다.
솔루션에 필요한 아티팩트를 압축 해제하고 airflow 및 genie 디렉터리를 방금 생성한 Amazon S3 버킷에 업로드합니다. 나중에 AWS CloudFormation 템플릿에 파라미터로 추가해야 하므로 Amazon S3 루트 경로를 기록해 둡니다.
예를 들어, 다음 스크린샷에서는 geniestackbucket 루트 위치를 사용합니다.

생성한 Amazon S3 버킷의 값을 AWS CloudFormation 파라미터 GenieS3BucketLocation 및 AirflowBucketLocation에 사용합니다.
AWS CloudFormation 스택 배포
전체 솔루션을 시작하려면 [Launch Stack]을 선택합니다.

다음 표는 템플릿에 필요한 파라미터를 설명합니다. 테이블에 표시되지 않은 모든 파라미터에는 기본값을 수락하면 됩니다. 파라미터의 전체 목록은 AWS CloudFormation 템플릿을 참조하십시오.
| 파라미터 | 값 | |
| 구성 아티팩트의 위치 | GenieS3BucketLocation |
Genie 아티팩트 및 Genie의 설치 스크립트가 있는 S3 버킷입니다. 예: geniestackbucket |
AirflowBucketLocation |
Airflow 아티팩트가 있는 S3 버킷입니다. 예: geniestackbucket |
|
| 네트워킹 | SSHLocation |
Genie, Apache Zookeeper 및 Apache Airflow EC2 인스턴스에 대한 SSH를 수행할 IP 주소 범위입니다. |
| 보안 | BastionKeyName |
배스천 호스트 인스턴스에 대한 SSH 액세스를 지원하기 위한 기존 EC2 키 페어입니다. |
AirflowKeyName |
Apache Airflow 인스턴스에 대한 SSH 액세스를 지원하기 위한 기존 EC2 키 페어입니다. | |
ZKKeyName |
Apache Zookeeper 인스턴스에 대한 SSH 액세스를 지원하기 위한 기존 EC2 키 페어입니다. | |
GenieKeyName |
Genie에 대한 SSH 액세스를 지원하기 위한 기존 EC2 키 페어입니다. | |
EMRKeyName |
Amazno EMR 클러스터에 대한 SSH 액세스를 지원하기 위한 기존 Amazon EC2 키 페어입니다. | |
| 로깅 | emrLogUri |
Amazon EMR 클러스터 로그를 저장할 S3 위치입니다. 예: s3://replace-with-your-bucket-name/emrlogs/ |
배포 후 단계
Apache Airflow 및 Genie 웹 인터페이스에 액세스하려면 SSH를 설정하고 브라우저에 대한 SOCKS 프록시를 구성합니다. 다음 단계를 완료합니다.
- AWS CloudFormation 콘솔에서 생성할 스택을 선택합니다.
- [출력]을 선택합니다.
- 배스천 호스트 인스턴스의 퍼블릭 DNS를 찾습니다. 다음 스크린샷은 이 게시물에서 사용하는 인스턴스를 보여줍니다.

- 동적 포트 전달을 사용하여 마스터 노드에 대한 SSH 터널을 설정합니다.
이 단계별 안내에 참조된 클러스터의 퍼블릭 DNS 이름과 사용자 이름hadoop을 사용하지 않고 대신 배스턴 호스트 인스턴스의 퍼블릭 DNS를 사용하고 사용자hadoop을 사용자ec2-user로 대체합니다.
- 마스터 노드에 호스팅된 웹 사이트를 보기 위한 프록시 설정을 구성합니다..
이 단계별 안내에 있는 모든 단계는 수정할 필요가 없습니다.
이 프로세스는 텍스트 패턴을 기반으로 URL을 자동으로 필터링하고 프록시 설정을 Amazon EC2 인스턴스의 퍼블릭 DNS 이름 형식과 일치하는 도메인으로 제한할 수 있게 해 주는 SOCKS 프록시 관리 도구를 구성합니다.
Apache Airflow 및 Genie를 위한 웹 UI 액세스
Apache Airflow 및 Genie를 위한 웹 UI에 액세스하려면 다음 단계를 완료합니다.
- CloudFormation 콘솔에서 생성한 스택을 선택합니다.
- [출력]을 선택합니다.
- Apache Airflow 및 Genie 웹 UI에 대한 URL을 찾습니다. 다음 스크린샷은 이 게시물에서 사용하는 URL을 보여줍니다.

- 웹 브라우저에서 두 개의 탭을 엽니다. 이 탭은 Apache Airflow UI와 Genie UI를 위해 사용할 것입니다.
- 이전에 구성한 Foxy Proxy에 대해 브라우저 오른쪽 상단에 추가된 Foxy Proxy 아이콘을 선택하고 [Use proxies based on their predefined patterns and priorities]를 선택합니다. 다음 스크린샷은 프록시 옵션을 보여줍니다.

- 각 탭에서 Apache Airflow 웹 UI 및 Genie 웹 UI에 대한 URL을 입력합니다.
이제 이 솔루션에서 워크플로를 실행할 준비가 완료되었습니다.
애플리케이션 리소스 준비
플랫폼 관리 엔지니어가 수행할 첫 번째 단계는 플랫폼에서 지원하는 빅 데이터 애플리케이션의 바이너리 및 구성을 준비하는 것입니다. 이 게시물에서는 Amazon EMR 클러스터가 릴리스 5.26.0을 사용합니다. Amazon EMR 릴리스 5.26.0에는 Hadoop 2.8.5 및 Spark 2.4.3이 설치되어 있으므로 빅 데이터 플랫폼에서 이 애플리케이션을 지원해야 합니다. 다른 EMR 릴리스를 사용하려는 경우, 해당 버전에 대한 바이너리와 구성을 준비합니다. 다음 섹션에서는 다른 EMR 릴리스 버전을 사용하는 경우를 위해 바이너리를 준비하는 단계를 안내합니다.
Genie 애플리케이션 리소스를 준비하려면 애플리케이션 리소스 생성 요청을 통해 Genie에 전송되는 필드가 포함된 YAML 파일을 생성합니다.
이 파일은 애플리케이션 이름, 유형, 버전, 태그, S3 상의 설정 스크립트 위치 및 애플리케이션 바이너리 위치와 같은, 애플리케이션에 대한 메타데이터 정보를 정의합니다. 자세한 내용은 Genie REST API Guide의 Create an Application을 참조하십시오.
애플리케이션 리소스를 위한 태그 구조
이 게시물은 애플리케이션 리소스에 다음과 같은 태그를 사용합니다.
- type – Spark, Hadoop, Hive, Sqoop 또는 Presto와 같은 애플리케이션 유형입니다.
- version – Hadoop의 2.8.5과 같은 애플리케이션 버전입니다.
다음 섹션은 애플리케이션 리소스를 위한 태그가 YAML 파일에 어떻게 정의되는지를 보여줍니다. Genie 리소스에 연결할 태그는 임의의 수만큼 추가할 수 있습니다. Genies에서는 플랫폼 관리자가 정의하는 태그 외에 자체 태그도 유지 관리하며 이러한 태그는 파일의 필드 ID 및 필드 이름에서 볼 수 있습니다.
Hadoop 2.8.5 애플리케이션 리소스 준비
이 게시물은 YAML 파일의 자동 생성을 제공합니다. 다음 코드는 결과 파일의 세부 정보를 보여줍니다.
이 파일은 s3://Your_Bucket_Name/genie/applications/hadoop-2.8.5/hadoop-2.8.5.yml에서도 바로 사용할 수 있습니다.
참고: 다음 단계는 제공된 자동 옵션을 사용하지 않고 대신 수동으로 이 과정을 완료하는 경우를 위해 참고용으로만 제공됩니다.
setupFile 및 종속성 레이블에서 참조하는 S3 객체는 S3 버킷에서 사용할 수 있습니다. 참고로 속성 setupFile 및 종속성에서 사용하는 아티팩트를 준비하는 단계는 다음과 같습니다.
https://www.apache.org/dist/hadoop/core/hadoop-2.8.5/에서hadoop-2.8.5.tar.gz를 다운로드합니다.hadoop-2.8.5.tar.gz를s3://Your_Bucket_Name/genie/applications/hadoop-2.8.5/에 업로드합니다.
Spark 2.4.3 애플리케이션 리소스 준비
이 게시물은 YAML 파일의 자동 생성을 제공합니다. 다음 코드는 결과 파일의 세부 정보를 보여줍니다.
이 파일은 s3://Your_Bucket_Name/genie/applications/spark-2.4.3/spark-2.4.3.yml에서도 바로 사용할 수 있습니다.
참고: 다음 단계는 제공된 자동 옵션을 사용하지 않고 대신 수동으로 이 과정을 완료하는 경우를 위해 참고용으로만 제공됩니다.
setupFile 및 종속성의 객체는 S3 버킷에서 사용할 수 있습니다. 참고로 속성 setupFile 및 종속성에서 사용하는 아티팩트를 준비하는 단계는 다음과 같습니다.
https://archive.apache.org/dist/spark/spark-2.4.3/에서spark-2.4.3-bin-hadoop2.7.tgz를 다운로드합니다.spark-2.4.3-bin-hadoop2.7.tgz를s3://Your_Bucket_Name/genie/applications/spark-2.4.3/에 업로드합니다.
spark-2.4.3-bin-hadoop2.7.tgz는 Hadoop 2.8.3이 아니라 Hadoop 2.7을 사용하므로 Hadoop 2.7을 실행하는 EMR 클러스터(릴리스 5.11.3)에서 Hadoop 2.7을 위한 EMRFS 라이브러리를 추출해야 합니다. 해당 라이브러리는 S3 버킷에 이미 제공되어 있습니다. 참고로 EMRFS 라이브러리를 추출하는 단계는 다음과 같습니다.
- 릴리스 5.11.3의 EMR 클러스터를 배포합니다.
- 다음 명령을 실행합니다.
명령 리소스 준비
플랫폼 관리 엔지니어의 다음 단계는 플랫폼에서 지원하는 Genie 명령을 준비하는 것입니다.
이 게시물에서는 워크플로가 Apache Spark를 사용합니다. 이 섹션은 Apache Spark 유형의 명령 리소스를 준비하는 단계를 보여줍니다.
Genie 명령 리소스를 준비하려면 명령 리소스 생성 요청을 통해 Genie에 전송되는 필드가 포함된 YAML 파일을 생성합니다.
이 파일은 명령 이름, 유형, 버전, 태그, S3 상의 설정 스크립트 위치 및 명령 실행 중 사용할 파라미터와 같은, 명령에 대한 메타데이터 정보를 정의합니다. 자세한 내용은 Genie REST API Guide의 Create a Command를 참조하십시오.
명령 리소스를 위한 태그 구조
이 게시물은 명령 리소스에 다음과 같은 태그를 사용합니다.
- type – spark-submit와 같은 명령 유형입니다.
- version – Spark의 2.4.3과 같은 명령 버전입니다.
다음 섹션은 명령 리소스를 위한 태그가 YAML 파일에 어떻게 정의되는지를 보여줍니다. Genies에서는 플랫폼 관리자가 정의하는 태그 외에 자체 태그도 유지 관리하며 이러한 태그는 파일의 필드 ID 및 필드 이름에서 볼 수 있습니다.
spark-submit 명령 리소스 준비
이 게시물은 YAML 파일의 자동 생성을 제공합니다. 다음 코드는 결과 파일의 세부 정보를 보여줍니다.
이 파일은 s3://Your_Bucket_Name/genie/commands/spark-2.4.3_spark-submit/spark-2.4.3_spark-submit.yml에서도 사용할 수 있습니다.
setupFile의 객체는 S3 버킷에서 사용할 수 있습니다.
클러스터 리소스 준비
또한 이 게시물은 클러스터 준비를 위한 단계를 자동화했습니다. 이러한 단계는 앞에서 설명한 것과 유사하지만 클러스터 리소스에 적용되는 프로세스를 따릅니다.
Amazon EMR 클러스터를 시작하는 동안 사용자 정의 스크립트가 클러스터에 대한 메타데이터 세부 정보가 포함된 YAML 파일을 생성하여 S3에 업로드합니다. 자세한 내용은 Genie REST API Guide의 Create a Cluster를 참조하십시오.
또한 이 스크립트는 Amazon EMR 라이브러리를 추출하여 S3에 업로드합니다. 다음 단계는 클러스터를 Genie에 등록하는 프로세스를 설명합니다.
이 스크립트는 s3://Your_Bucket_Name/genie/scripts/genie_register_cluster.sh에서 사용할 수 있습니다.
클러스터 리소스를 위한 태그 구조
이 게시물은 클러스터 리소스에 다음과 같은 태그를 사용합니다.
- cluster.release – Amazon EMR 릴리스 이름입니다. 예: emr-5.26.0
- cluster.id – Amazon EMR 클러스터 ID입니다. 예:
j-xxxxxxxx - cluster.name – Amazon EMR 클러스터 이름입니다.
- cluster.role – 이 클러스터에 연결된 역할입니다. 이 게시물에서는 역할이 batch입니다. 다른 역할로는 ad hoc 또는 Presto 등이 가능합니다.
클러스터 리소스에 대한 새 태그를 추가하거나 s3://Your_Bucket_Name/genie/scripts/genie_register_cluster.sh를 편집하여 기존 태그의 값을 변경할 수 있습니다.
애플리케이션 수명 주기 환경 또는 필수 사용자 정의 jar를 식별하는 태그 등 다른 태그 조합을 사용할 수도 있습니다.
Genies에서는 플랫폼 관리자가 정의하는 태그 외에 자체 태그도 유지 관리하며 이러한 태그는 파일의 필드 ID 및 필드 이름에서 볼 수 있습니다. 여러 클러스터가 동일한 태그를 공유하는 경우, Genie는 기본적으로 동일한 태그에 연관된 여러 클러스터에 걸쳐 무작위로 작업을 분배합니다. 자세한 내용은 Genie Reference Guide의 Cluster Load Balancing을 참조하십시오.
Genie에 리소스 등록
지금까지는 이전 섹션에서 언급된 모든 구성 작업이 사용자를 위해 사전에 준비되었습니다.
다음 섹션은 리소스를 Genie에 등록하는 방법을 보여줍니다. 이 섹션에서는 구성 명령을 실행하기 위해 SSH를 통해 배스천에 연결합니다.
애플리케이션 리소스 등록
이전 섹션에서 준비한 애플리케이션 리소스를 등록하려면 배스천 호스트에 SSH하고 다음 명령을 실행합니다.
리소스 정보를 보려면 Genie 웹 UI로 이동하여 [Applications] 탭을 선택합니다. 다음 스크린샷을 참조하십시오. 이 스크린샷은 두 개의 애플리케이션 리소스, 즉 Apache Spark(버전 2.4.3)를 위한 리소스 및 Apache Hadoop(버전 2.8.5)을 위한 리소스를 보여줍니다.

애플리케이션에 명령 등록 및 연결
다음 단계는 Genie 명령 리소스를 특정 애플리케이션에 등록하는 것입니다. 이 게시물에서는 spark-submit가 Apache Hadoop 및 Apache Spark에 의존하므로 spark-submit 명령을 두 애플리케이션 모두에 연결합니다.
파일 genie_register_command_resources_and_associate_applications.py에서 애플리케이션을 정의하는 순서가 중요합니다. Apache Spark는 Apache Hadoop에 의존하므로 파일은 Apache Hadoop을 먼저 참조한 다음 Apache Spark를 참조합니다. 다음 코드를 참조하십시오.
명령 리소스를 등록하고 이전 단계에서 등록한 애플리케이션 리소스에 연결하려면 배스천 호스트에 SSH하고 다음 명령을 실행합니다.
등록한 명령과 해당 명령에 연결된 애플리케이션을 보려면 Genie 웹 UI로 이동하여 [Commands] 탭을 선택합니다.
다음 스크린샷은 명령 세부 정보와 해당 명령에 연결된 애플리케이션을 보여줍니다.

Amazon EMR 클러스터 등록
앞에서 언급된 바와 같이 이 솔루션에서 배포된 Amazon EMR 클러스터는 클러스터가 Amazon EMR 단계를 통해 시작할 때 해당 클러스터를 등록합니다. Amazon EMR 클러스터가 사용하는 스크립트는 s3://Your_Bucket_Name/genie/scripts/genie_register_cluster.sh에서 액세스할 수 있습니다. 또한 스크립트는 클러스터가 종료되었을 때 클러스터의 Genie 등록 해제를 자동화합니다.
Genie 웹 UI에서 [Clusters] 탭을 선택합니다. 이 페이지는 현재 클러스터 리소스를 보여줍니다. 등록 단계에서 클러스터 S3 위치에 업로드된 구성 파일의 위치도 확인할 수 있습니다.
다음 스크린샷은 클러스터 세부 정보 및 구성 파일(yarn-site.xml, core-site.xml, mapred-site.xml)의 위치를 보여줍니다.

클러스터에 명령 연결
이제 모든 애플리케이션, 명령 및 클러스터를 등록했으며 명령이 의존하는 애플리케이션에 해당 명령을 연결했습니다. 마지막 단계는 해당 명령을 실행하도록 구성된 특정 Amazon EMR 클러스터에 해당 명령을 연결하는 것입니다.
다음 단계를 완료합니다.
- 배스천 호스트에 SSH합니다.
- 선호하는 텍스트 편집기로
/tmp/genie_assets/scripts/genie_link_commands_to_clusters.py를 엽니다. - 코드에서 다음 줄을 찾습니다.
# Change cluster_name below
clusters = [{'cluster_name' : 'j-xxxxxxxx', 'commands' :
['spark-2.4.3_spark-submit']}]
- 파일에서
j-xxxxxxxx를cluster_name으로 교체합니다.
클러스터의 이름을 보려면 Genie 웹 UI로 이동하여 [Clusters]를 선택합니다. - 명령을 특정 Amazon EMR 클러스터에 연결하려면 다음 명령을 실행합니다.
명령이 이제 클러스터에 연결되었습니다.
Genie 웹 UI에서 [Commands] 탭을 선택합니다. 이 페이지는 현재 명령 리소스를 보여줍니다. spark-2.4.3_spark_submit를 선택하고 명령과 연관된 클러스터를 확인합니다.
다음 스크린샷은 명령 세부 정보와 해당 명령에 연결된 클러스터를 보여줍니다.

Genie에 모든 리소스가 구성되었으며 이제 작업 요청을 수신할 수 있습니다.
Apache Airflow 워크플로 실행
워크플로 코드 및 데이터 세트에 대한 상세한 설명을 제공하는 것은 이 게시물의 범위를 벗어납니다. 이 섹션은 Apache Airflow가 이 게시물에서 제공된 GenieOperator를 통해 Genie에 작업을 제출하는 방법에 대한 세부 정보를 제공합니다.
GenieOperator for Apache Airflow
GenieOperator를 사용하면 데이터 엔지니어가 명령 및 작업이 실행되어야 할 클러스터를 식별하는 태그의 조합을 정의할 수 있습니다.
다음 코드 예에서 클러스터 태그는 ‘emr.cluster.role:batch‘이며 명령 태그는 ‘type:spark-submit‘ 및 ‘version:2.4.3‘입니다.
속성 command_arguments는 spark-submit 명령에 대한 인수를 정의하고 dependencies는 Apache Spark 애플리케이션(PySpark)을 위한 코드 위치를 정의합니다.
GenieOperator를 위한 코드는 s3://Your_Bucket_Name/airflow/plugins/genie_plugin.py에서 찾을 수 있습니다.
DAG에 대한 인수 중 하나는 Genie 연결 ID(genie_conn_id)입니다. 이 연결은 Apache Airflow 인스턴스의 자동 설정 과정에 생성되었습니다. 이 연결과 그 외의 기존 연결을 보려면 다음 단계를 완료합니다.
- Apache Airflow 웹 UI에서 [Admin]을 선택합니다.
- [Connections]를 선택합니다.
다음 스크린샷은 연결 세부 정보를 보여줍니다.

DAG에 참조된 Airflow 변수 s3_location_genie_demo는 설치 프로세스 과정에 설정되었습니다. 구성된 Apache Airflow 변수를 모두 보려면 다음 단계를 완료합니다.
- Apache Airflow 웹 UI에서 [Admin]을 선택합니다.
- [Variables]를 선택합니다.
다음 스크린샷은 [Variables] 페이지를 보여줍니다.

워크플로 트리거
이제 movie_lens_transfomer_to_parquet DAG의 실행을 트리거할 수 있습니다. 다음 단계를 완료합니다.
- Apache Airflow 웹 UI에서 [DAGs]를 선택합니다.
- 해당 DAG 옆에 있는 [Off]를 [On]으로 변경합니다.
다음 스크린샷은 [DAG] 페이지를 보여줍니다.

이 예제 DAG에 대해 이 게시물은 movielens 데이터 세트의 작은 하위 집합을 사용합니다. 이 데이터 세트는 널리 사용되는 오픈 소스 데이터 세트로서, 데이터 과학 알고리즘을 탐색하는 데 사용할 수 있습니다. 각 데이터 세트 파일은 단일 헤더 행을 가진 CSV(쉼표로 분리된 값) 파일입니다. 모든 파일은 솔루션 S3 버킷의 s3://Your_Bucket_Name/airflow/demo/input/csv 아래에서 사용할 수 있습니다.
movie_lens_transfomer_to_parquet는 입력 파일을 CSV에서 Parquet으로 변환하는 Spark 작업을 트리거하는 간단한 워크플로입니다.
다음 스크린샷은 DAG의 그래픽적인 표현을 보여줍니다.

이 예제 DAG에서는 transform_to_parquet_movies가 완료된 후에 4개의 작업을 병렬로 실행하는 것이 가능할 수 있습니다. 다음 코드 예제에서 볼 수 있듯이 DAG 동시성이 3으로 설정되어 있으므로 3개의 작업만 동시에 실행될 수 있습니다.
Genie 작업 UI 검토
GenieOperator for Apache Airflow에서 작업을 Genie에 제출합니다. 작업 세부 정보를 보려면 Genie 웹 UI에서 [Jobs] 탭을 선택합니다. 제출된 작업, 해당 인수, 작업을 실행하는 클러스터 및 작업 상태와 같은 세부 정보를 볼 수 있습니다.
다음 스크린샷은 [Jobs] 페이지를 보여줍니다.

이제 새 Amazon EMR 클러스터를 프로비저닝하고, Genie 태그 “emr.cluster.role”에 대한 새 값(예: “production”)으로 등록하고, 클러스터를 명령 리소스에 연결하고, DAG의 일부 작업이 사용하는 GenieOperator에서 태그 조합을 업데이트하는 등의 작업으로 이 아키텍처를 실험해 볼 수 있습니다.
지우기
향후 요금이 발생하는 것을 방지하려면 이 게시물을 위해 생성한 리소스와 S3 버킷을 삭제합니다.
마무리
이 게시물은 Genie, Apache Airflow 및 Amazon EMR을 위한 데모 환경을 설정하는 AWS CloudFormation 템플릿을 배포하는 방법을 보여줍니다. 또한 이 게시물은 Genie를 구성하고 GenieOperator for Apache Airflow를 사용하는 방법을 시연합니다.
 Francisco Oliveira는 AWS의 빅 데이터 솔루션 선임 아키텍트입니다.. 그는 오픈 소스 기술과 AWS를 통해 빅 데이터 솔루션을 구축하는 데 초점을 맞추고 있습니다. 그는 여가 시간에 새로운 스포츠와 여행을 즐기며 국립 공원을 탐색하는 것을 좋아합니다.
Francisco Oliveira는 AWS의 빅 데이터 솔루션 선임 아키텍트입니다.. 그는 오픈 소스 기술과 AWS를 통해 빅 데이터 솔루션을 구축하는 데 초점을 맞추고 있습니다. 그는 여가 시간에 새로운 스포츠와 여행을 즐기며 국립 공원을 탐색하는 것을 좋아합니다.

Jelez Raditchkov는 AWS에서 NoSQL AWS Professional Services 업무를 선도하고 있습니다. 그는 NoSQL, Graph 및 Search 영역에 대한 집중화된 지원을 통해 고객이 원하는 비즈니스 결과를 실현할 수 있도록 돕고 있습니다. 이전에 그는 AWS Professional Services의 수석 데이터 레이크 아키텍트였습니다.
AWS NoSQL 전용 데이터베이스 서비스에 대한 자세한 내용은 https://aws.amazon.com/nosql/을 참조하십시오.

Prasad Alle는 AWS Professional Services의 선임 빅 데이터 컨설턴트입니다. 그는 AWS 엔터프라이즈 및 전략적 고객을 위한 확장 가능하고 신뢰적인 빅 데이터, 기계 학습, 인공 지능 및 IoT 솔루션을 선도하고 구축하는 일을 하고 있습니다. 그의 관심 분야는 고급 엣지 컴퓨팅, 엣지에서의 기계 학습과 같은 다양한 기술로까지 확장되어 있습니다. 그는 시간이 남으면 가족과 함께 보내는 시간을 즐깁니다.
Source: Apache Airflow, Genie 및 Amazon EMR을 통한 빅데이터 워크플로 오케스트레이션 – 2부


Leave a Reply