Amazon HealthLake – 클라우드 기반 의료 데이터 저장, 변환 및 분석 서비스 제공
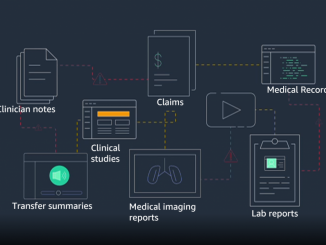
Amazon HealthLake – 클라우드 기반 의료 데이터 저장, 변환 및 분석 서비스 제공 의료 기관은 가족력과 임상 관찰부터 진단 및 약물 치료에 이르기까지 매일 방대한 양의 환자 정보를 수집합니다. 그리고 더 나은 의료 서비스를 제공하기 위해 환자의 건강 정보를 포괄적으로 이해하고자 이러한 모든 데이터를 사용합니다. 현재 이 데이터는 다양한 시스템(전자 의료 기록, 실험실 시스템, 의료 이미지 리포지토리 등)에 분산되어 있으며 수십 개의 호환되지 않는 형식으로 존재합니다. Fast Healthcare Interoperability Resources(FHIR)와 같은 새로운 표준의 목표는 이러한 시스템에서 구조화된 데이터를 설명하고 교환하기 위한 일관된 형식을 제공하여 이 과제를 해결하는 것입니다. 그러나 이러한 데이터 대부분은 의료 기록(예: 임상 기록), 문서(예: PDF 실험실 보고서), 양식(예: 보험 청구), 이미지(예: 엑스레이, MRI), 오디오(예: 녹음된 대화) 및 시계열 데이터(예: 심전도 검사)에 포함된 구조화되지 않은 정보이며, 이러한 정보를 추출하는 작업은 쉽지 않습니다. 의료 기관에서 이 모든 데이터를 수집하고 변환(태그 지정 및 인덱싱), 구조화 및 분석을 위해 준비하려면 몇 [ more… ]