Amazon EMR 클러스터 탄력성에 따른 Spark 노드 손실 문제 해결 방법
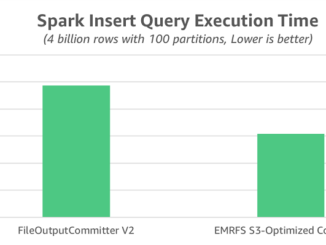
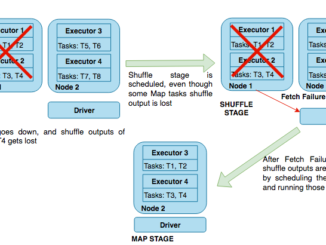
Amazon EMR 클러스터 탄력성에 따른 Spark 노드 손실 문제 해결 방법 AWS 고객은 Amazon EMR의 클러스터 탄력성을 활용하여 작업량에 따라 사용 인스턴스 수를 조정해서 비용을 절감할 수 있습니다. 특히, EC2 스팟 인스턴스를 사용하면, 빠르게 끝나는 작업에 대해서 80-90%의 저렴한 비용으로 작업을 할 수 있습니다. 또한, Amazon EMR의 오토 스케일링 기능을 통해 고객은 클러스터 사용이나 기타 작업 관련 지표에 따라 클러스터를 동적으로 확장 및 축소 할 수 있습니다. 다만, 이 기능을 통해 리소스를 효율적으로 사용할 수 있지만 작업 실행 중에 EC2 인스턴스가 중단될 수도 있습니다. 그 결과 계산 및 데이터가 손실될 수 있으며 이는 작업의 안정성을 저해하거나 재컴퓨팅을 통해 중복 작업을 초래할 수 있습니다. 이에 대한 해결 방법으로 실행 중인 작업에 영향을 미치지 않고 노드를 정상적으로 중단하기 위해 Amazon EMR은 Apache Hadoop의 폐기 메커니즘을 사용할 수 있습니다. Amazon EMR 팀은 이 메커니즘을 개발하여 오픈 소스로 공헌하기도 했습니다. 이 메커니즘은 대부분의 하둡 [ more… ]