Amazon SageMaker Notebook에서 (Amazon EMR기반) Apache Spark와의 연동 환경 구축 방법
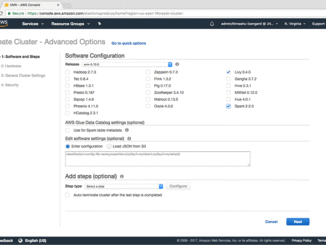
Amazon SageMaker Notebook에서 (Amazon EMR기반) Apache Spark와의 연동 환경 구축 방법 지난 AWS re:Invent 2017에서 처음 소개된 Amazon SageMaker는 데이터 과학과 머신 러닝 워크플로우를 위한 완전 관리형 서비스를 제공하고 있습니다. 특히 모델을 만드는데 사용되는 Jupyter notebook 인터페이스는 SageMaker에서 대단히 중요한 구성 요소 중 하나입니다. 한편Amazon Elastic MapReduce (Amazon EMR) 상에서 동작하는 Apache Spark 클러스터에 notebook 인스턴스를 연결시켜서 SageMaker의 성능을 훨씬 더 향상시킬 수 있습니다. 참고로 EMR은 대량의 데이터를 처리하기 위한 관리형 프레임워크입니다. 따라서 이와 같은 조합을 통해 대용량 데이터에 대한 모델 구축이 가능해집니다. Apache Spark는 빅 데이터를 빠른 속도로 처리할 수 있게 해주는 오픈소스 기반의 클러스터 컴퓨팅 프레임워크로, MLlib이라는 머신 러닝 작업을 위한 라이브러리도 제공하고 있습니다. 여기서는 SageMaker notebook과 Spark EMR 클러스터 간의 연동을 손쉽게 하기 위해, Livy라는 툴을 사용하는 방법을 설명하겠습니다. 참고로 Livy는 Spark 클라이언트를 사용하지 않고도 어디서든 Spark 클러스터와 상호 연동할 수 있게 해주는 오픈소스 REST 인터페이스입니다. 이 [ more… ]



