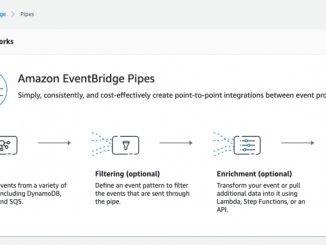
Amazon EventBridge Pipes – 이벤트 생산자와 소비자 간의 종단간 통합 기능 출시
Amazon EventBridge Pipes – 이벤트 생산자와 소비자 간의 종단간 통합 기능 출시 최신 이벤트 기반 애플리케이션을 구성하기 위해 여러 클라우드 서비스를 빌딩 블록으로 사용하는 것이 점점 더 보편화되고 있습니다. 목적별 서비스를 사용하여 특정 태스크를 수행하면 개발자가 사용 사례에 가장 적합한 기능을 확보할 수 있습니다. 그러나 서로 다른 기술을 사용하여 통신하는 경우 서비스 간 통신이 어려울 수 있습니다. 즉, 각 서비스의 미세한 차이와 서비스를 서로 통합하는 방법을 익혀야 합니다. 일반적으로 서비스 간 통신을 연결하고 갭을 메우려면 통합 코드(또는 ‘글루’ 코드)를 만들어야 합니다. 글루 코드를 작성하면 속도가 느려지고 버그가 발생할 위험이 증가합니다. 즉, 고객을 위한 더 나은 환경을 구축하는 대신 획일적인 코드를 작성하는 데 시간을 할애해야 합니다. Amazon EventBridge Pipes 소개 오늘 Amazon EventBridge의 새로운 기능인 Amazon EventBridge Pipes를 발표하게 되어 기쁩니다. Amazon EventBridge Pipes는 이벤트 생산자와 소비자 간에 포인트 투 포인트 통합을 생성할 수 있는 간단하고 일관되며 비용 효율적인 방법을 제공하여 [ more… ]