AWS Lambda 신규 기능 – Layers 기반 라이브러리 관리 및 Runtime API를 통한 모든 언어 지원
AWS Lambda가 2014년 출시되었던 당시의 흥분이 기억납니다! 4년이 지난 지금, 고객은 다양한 사용 사례에 Lambda 함수를 사용하고 있습니다. 예를 들어, iRobot은 AWS Lambda를 사용하여 Roomba 로봇 진공 청소기를 위한 컴퓨팅 서비스를 제공하고, Fannie Mae는 수백만 건의 모기지를 위한 몬테카를로 시뮬레이션을 실행하고, Bustle은 디지털 콘텐츠에 대한 수십억 건의 요청을 서비스합니다.
오늘, AWS는 서버리스 개발을 더욱 쉽게 만들어줄 두 가지의 새로운 기능을 소개합니다.
- Lambda Layers는 여러 함수가 공유하는 코드 및 데이터를 중앙에서 관리하는 방식입니다.
- Lambda Runtime API는 함수 개발을 위해 모든 프로그래밍 언어 또는 언어 버전을 사용할 수 있는 간단한 인터페이스입니다.
이 두 기능은 함께 사용할 수 있습니다. 런타임을 레이어 형태로 공유하면 개발자가 이를 가져와 선호하는 프로그래밍 언어로 Lambda 함수를 제작하는 데 사용할 수 있습니다.
작동 방식을 자세히 살펴보겠습니다.
Lambda Layers
서버리스 애플리케이션을 구축할 때에는 코드를 여러 Lambda 함수가 공유하는 경우가 자주 있습니다. 이는 비즈니스 로직의 구현을 간소화하기 위해 추가하는 사용자 정의 코드이거나, 하나 이상의 함수가 사용하는 코드이거나, 표준 라이브러리일 수 있습니다.
이전에는 이 공유 코드와 해당 코드를 사용하는 함수를 함께 패키징하여 배포해야 했습니다. 이제는 공통 구성 요소를 ZIP 파일에 담아 하나의 Lambda 레이어로 업로드할 수 있습니다. 고객은 함수 코드를 변경할 필요가 없으며 레이어 안의 라이브러리를 정상적인 방식으로 참조할 수 있습니다.
Layers에는 버전을 지정하여 업데이트를 관리할 수 있습니다. 각 버전은 변경할 수 없습니다. 버전을 삭제하거나 사용 권한을 회수한 경우, 이를 이전해 사용했던 함수는 계속 작동하지만 새 함수를 만들 수는 없습니다.
함수는 구성을 통해 최대 5개의 레이어를 참조할 수 있으며 이 중 하나는 선택적으로 런타임이 될 수 있습니다. 함수를 호출하면 제공한 순서로 레이어가 /opt에 설치됩니다. 레이어는 모두 동일한 경로를 통해 추출되므로 각 레이어는 이전 레이어를 재지정할 가능성이 있기 때문에 순서가 중요합니다. 이 접근방식은 환경을 사용자 정의하는 데 사용할 수 있습니다. 예를 들어, 첫 번째 레이어를 런타임으로 설정하고 두 번째 레이어로 필요한 특정 라이브러리 버전을 추가할 수 있습니다.
압축되지 않은 함수 및 레이어의 전체 크기는 일반적인 비압축 배포 패키지 크기 제한에 따라 달라집니다.
Layers는 AWS 계정 내에서 사용하거나, 여러 계정이 공유하거나, 광범위한 개발자 커뮤니티와 공개적으로 공유할 수 있습니다.
레이어를 사용하는 것에는 다양한 장점이 있습니다. 예를 들어, Lambda Layers를 사용하여 다음을 수행할 수 있습니다.
- 종속성과 사용자 정의 비즈니스 로직 사이에서 우려 요소를 강제로 분리합니다.
- 함수 코드를 더 작고 제작 목적에 더 집중하도록 만듭니다.
- 패키징 및 업로드해야 할 코드가 더 적고 종속성을 재활용할 수 있으므로 배포 시간이 단축됩니다.
고객 피드백을 기반으로 Lambda Layers를 사용하는 방법의 예를 제공하기 위해 AWS는 Pythong용으로 자주 사용되는 두 가지의 과학 라이브러리인 NumPy와 SciPy를 포함하는 퍼블릭 레이어를 발표했습니다. 이 사전 제작 방식의 최적화된 레이어는 데이터 프로세싱 및 기계 학습 애플리케이션을 매우 신속하게 시작하는 데 도움이 될 수 있습니다.
그 뿐 아니라, Datadog, Epsagon, IOpipe, NodeSource, Thundra, Protego, PureSec, Twistlock, Serverless 및 Stackery와 같은 파트너사로부터 애플리케이션 모니터링, 보안 및 관리용 레이어를 찾을 수 있습니다.
Lambda Layers 사용
이제 Lambda 콘솔에서 자체 레이어를 관리할 수 있습니다.
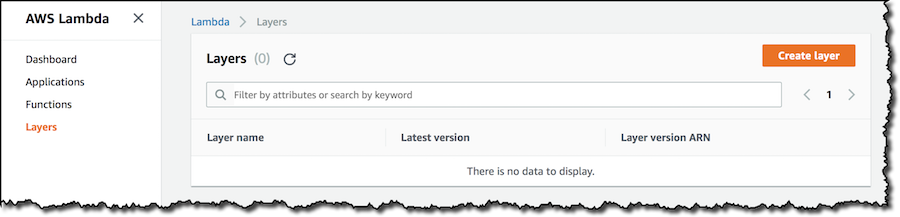
새 레이어를 지금 생성하지 않고 함수에 있는 기존 레이어를 사용하겠습니다. 새로운 Python 함수를 생성하겠습니다. 함수 구성을 보면 참조 레이어가 없는 것을 알 수 있습니다. 레이어를 추가하도록 선택합니다.
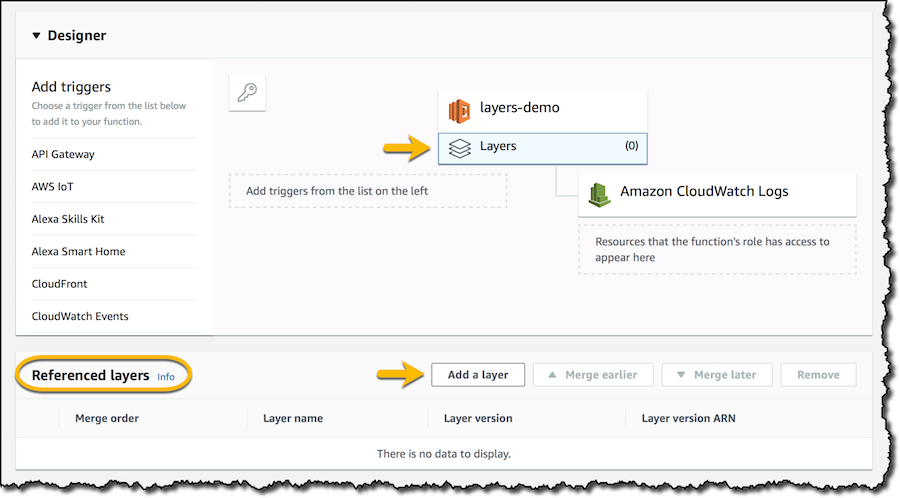
함수의 런타임과 호환되는 레이어의 목록에서 NumPy 및 SciPy가 포함된 최신 버전을 선택합니다.
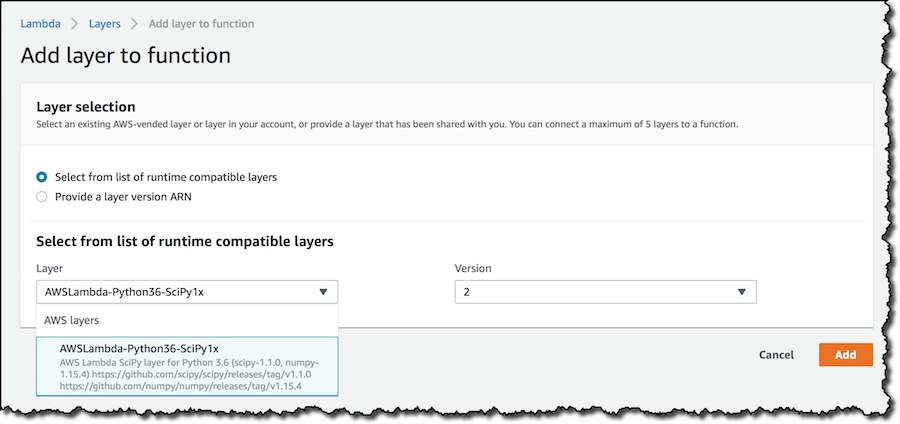
레이어를 추가한 후 [저장]을 클릭하여 함수 구성을 업데이트합니다. 둘 이상의 레이어를 사용하는 경우 여기에서 레이어가 함수 코드와 병합되는 순서를 조정할 수 있습니다.

레이어를 함수에 사용하려면 NumPy와 SciPy에서 필요한 기능을 가져오기만 하면 됩니다.
import numpy as np
from scipy.spatial import ConvexHull
def lambda_handler(event, context):
print("nUsing NumPyn")
print("random matrix_a =")
matrix_a = np.random.randint(10, size=(4, 4))
print(matrix_a)
print("random matrix_b =")
matrix_b = np.random.randint(10, size=(4, 4))
print(matrix_b)
print("matrix_a * matrix_b = ")
print(matrix_a.dot(matrix_b)
print("nUsing SciPyn")
num_points = 10
print(num_points, "random points:")
points = np.random.rand(num_points, 2)
for i, point in enumerate(points):
print(i, '->', point)
hull = ConvexHull(points)
print("The smallest convex set containing all",
num_points, "points has", len(hull.simplices),
"sides,nconnecting points:")
for simplex in hull.simplices:
print(simplex[0], '<->', simplex[1])함수를 실행하고 로그를 확인하면 흥미로운 결과를 볼 수 잇습니다.
우선, NumPy를 사용하여 매트릭스 곱셈을 수행합니다(매트릭스와 벡터는 종종 신경망의 입력, 출력 및 가중치를 나타내는 데 사용됨).
random matrix_1 = [[8 4 3 8] [1 7 3 0] [2 5 9 3] [6 6 8 9]] random matrix_2 = [[2 4 7 7] [7 0 0 6] [5 0 1 0] [4 9 8 6]] matrix_1 * matrix_2 = [[ 91 104 123 128] [ 66 4 10 49] [ 96 35 47 62] [130 105 122 132]]
그런 다음, SciPy의 고급 공간 알고리즘을 사용하여 직접 구축하기에 어려울 수 있는 컴퓨팅(평면 상의 점 목록을 포함하는 가장 작은 “컨벡스 세트” 찾기)을 구현합니다. 예를 들어, 여러 지리적 위치(건물, 고객 위치 또는 기기에 해당하는 위치)로부터 이벤트를 수신하는 Lambda 함수에 사용하여 비슷한 이벤트를 효과적인 방식으로 서로 “그룹화”할 수 있습니다.
10 random points: 0 -> [0.07854072 0.91912467] 1 -> [0.11845307 0.20851106] 2 -> [0.3774705 0.62954561] 3 -> [0.09845837 0.74598477] 4 -> [0.32892855 0.4151341 ] 5 -> [0.00170082 0.44584693] 6 -> [0.34196204 0.3541194 ] 7 -> [0.84802508 0.98776034] 8 -> [0.7234202 0.81249389] 9 -> [0.52648981 0.8835746 ] The smallest convex set containing all 10 points has 6 sides, connecting points: 1 <-> 5 0 <-> 5 0 <-> 7 6 <-> 1 8 <-> 7 8 <-> 6
이 예를 제작할 때에는 종속성을 설치하거나 패키징할 필요가 없었습니다. 또한 함수 코드를 신속하게 반복할 수 있었으며, 큰 라이브러리나 모듈을 포함하지 않아도 되므로 배포 속도가 매우 빨랐습니다.
SciPy의 출력을 시각화하려면 간단히 그림용 라이브러리인 matplotlib를 가져오는 추가 레이어를 생성합니다. 이전 함수 끝에 몇 줄의 코드를 추가하면 이제 “컨벡스 세트”가 모든 점을 어떻게 커버하는지를 보여주는 이미지를 Amazon Simple Storage Service(S3)에 업로드할 수 있습니다.
plt.plot(points[:,0], points[:,1], 'o')
for simplex in hull.simplices:
plt.plot(points[simplex, 0], points[simplex, 1], 'k-')
img_data = io.BytesIO()
plt.savefig(img_data, format='png')
img_data.seek(0)
s3 = boto3.resource('s3')
bucket = s3.Bucket(S3_BUCKET_NAME)
bucket.put_object(Body=img_data, ContentType='image/png', Key=S3_KEY)
plt.close()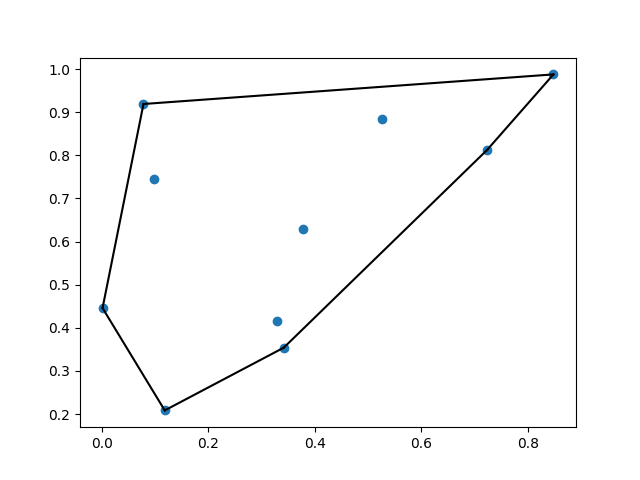
Lambda Runtime API
이제 함수를 생성하거나 업데이트할 때 사용자 정의 런타임을 선택할 수 있습니다.

이 옵션을 선택하면 함수는 자체 코드 또는 레이어에 bootstrap이라는 이름의 실행 파일을 포함해야 합니다. 이 파일은 코드(어떤 프로그래밍 언어도 사용 가능) 및 Lambda 환경 사이의 통신을 책임집니다.
런타임 부트스트랩은 간단한 HTTP 기반 인터페이스를 사용하여 신규 호출을 위한 이벤트 페이로드를 가져오고 함수에 응답을 반환합니다. 인터페이스 엔드포인트 및 함수 처리자의 정보는 환경 변수 형태로 공유됩니다.
코드 실행을 위해서는 Lambda 실행 환경을 실행할 수 있는 모든 도구를 사용할 수 있습니다. 예를 들어, 원하는 프로그래밍 언어에 대한 해석기를 사용할 수 있습니다.
자체 런타임을 관리하거나 게시하고자 하는 경우에는 Runtime API의 작동 방식만 알면 됩니다. 개발자는 다른 사람과 레이어 형태로 공유되는 런타임을 신속하게 사용할 수 있습니다.
다음과 같은 오픈 소스 런타임도 곧 출시될 예정입니다.
- C++
- Rust
AWS에서는 더 많은 오픈 소스 런타임을 제공하기 위해 파트너사와의 협력하고 있습니다.
- Erlang (Alert Logic)
- Elixir (Alert Logic)
- Cobol (Blu Age)
- N|Solid (NodeSource)
- PHP (Stackery)
런타임 API는 AWS가 Lambda에서 새 언어를 통해 지원하는 방식의 미래를 제시합니다. 예를 들어, 이 방식은 AWS가 Ruby 언어를 지원하는 데 사용되었습니다.
지금 이용 가능
런타임과 레이어는 Lambda를 지원하는 모든 리전에서 콘솔 또는 AWS 명령줄 인터페이스(CLI)를 통해 사용할 수 있습니다. 또한 AWS Serverless Application Model(SAM) 및 SAM CLI를 사용하여 이러한 새 기능을 테스트, 배포 및 관리할 수 있습니다.
런타임과 레이어를 사용할 때에는 별도의 요금이 부과되지 않습니다. 레이어의 스토리지는 AWS Lambda의 리전별 기능 스토리지 제한의 계산에 포함됩니다.
Runtime API 및 Lambda Layers에 대한 자세한 내용을 보려면, 책임 개발자 옹호자인 Chris Munns가 호스팅하는 12월 11일자 AWS 웹 세비나를 놓치지 마십시오.
정말 멋지고 새로운 기능들입니다. 다음 프로젝트를 제작하기 전에 의견을 저희에게 알려주시기 바랍니다.
– Danilo Poccia;
Source: AWS Lambda 신규 기능 – Layers 기반 라이브러리 관리 및 Runtime API를 통한 모든 언어 지원


Leave a Reply