AWS re:Invent 세션 미리 보기 – Under the Hood at Amazon Ads
제 동료들은 다가오는 AWS re:Invent 세션의 콘텐츠를 작성하고 검토하며 개선하는 데 몇 달을 보냈습니다. 특정 제품을 편애하고 싶지는 않지만, 최근 흥미로운 소식을 알려 드리고 싶습니다!
ADM301 세션(Under the Hood at Amazon Ads)은 11월 30일(화요일) 오후 2시에 진행됩니다. 이 세션에서는 Amazon Ads를 소개하고, 대규모 광고 시스템에서 나타나는 과제를 간략히 살펴본 후에 여러 AWS 서비스를 사용하여 이러한 과제를 어떻게 해결하는지 알려줍니다. 저는 이번 프레젠테이션의 최종 버전에 가까운 내용을 검토할 수 있었고, 이 게시물은 이번 검토를 통해 제가 확인한 내용에 기반합니다.
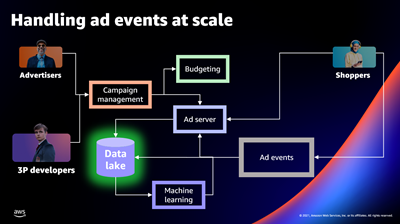
Amazon Ads는 인식을 구축하고, 배려 요소를 늘리며, 구매자 참여를 유도하고, 구매를 유도하는 네 가지 요소에 기반한 옴니채널 전략을 사용합니다. Amazon이 채택하고 있는 유명한 ‘고객에게서 시작되는 개발’ 모델을 통해 세 가지 차별적인 고객 유형을 식별하고 고객 요구 사항을 해결하는 시스템을 설계했습니다. 고객 유형은 다음과 같습니다.
- 캠페인을 운영하는 광고주
- Amazon Ads API를 사용하여 도구 및 서비스를 구축하는 서드 파티 파트너
- 구매 여정을 진행하는 소비자
광고주와 서드 파티 개발자는 캠페인 관리, 예산 책정, 광고 게재, 광고 이벤트를 위한 데이터 레이크, 광고 선택 및 관련성을 개선하기 위한 기계 학습을 포괄하는 UI와 프로그래밍 인터페이스 모두를 아우르는 경험을 원했습니다.
 성능, 스토리지, 가용성, 비용 및 효율성 관련 과제와 함께 스케일링은 매우 흥미로운 문제입니다. 120 ms의 대기 시간 예산 내에 초당 수억 건의 광고 요청(매일 수조 건의 광고)을 처리하는 것 외에도 광고 서버는 다음을 수행할 수 있어야 합니다.
성능, 스토리지, 가용성, 비용 및 효율성 관련 과제와 함께 스케일링은 매우 흥미로운 문제입니다. 120 ms의 대기 시간 예산 내에 초당 수억 건의 광고 요청(매일 수조 건의 광고)을 처리하는 것 외에도 광고 서버는 다음을 수행할 수 있어야 합니다.
- 수백 페타바이트 규모의 전체 스토리지를 사용하여 수백억 개의 캠페인 객체 추적
- 99.9999%가 넘는 가용성 제공
- Prime Day와 같은 사용량이 급증하는 이벤트 자동 처리
- 경제적으로 운영하고 광고주 예산을 거의 실시간으로 적용
- 수백 개의 기계 학습 모델에서 예측을 사용하여 관련성이 높은 광고 게재
이러한 규모의 워크로드를 처리하는 데 사용되는 한 가지 예로, 초당 5억 개의 요청을 처리할 수 있는 캐싱 시스템이 필요했습니다!
종종 그렇듯이 시스템은 현재 형식에 도달하기 전까지 여러 번의 반복을 거쳤으며 지금도 여전히 개발 중에 있습니다. 이 프레젠테이션에서는 이러한 각 반복의 아키텍처 스냅샷과 성능 지표를 통해 팀이 거쳐온 여정을 요약합니다.
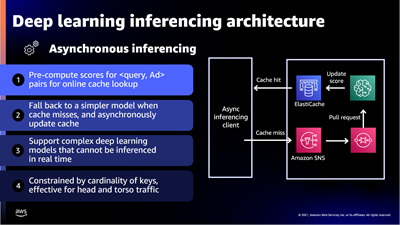 이 프레젠테이션의 마지막 부분에서는 기계 학습을 대규모로 적용할 수 있었던 몇 가지 방법에 대해 논의합니다. 예를 들어, Amazon Ads는 각 요청에 적합한 광고를 선택하기 위해 딥 러닝 모델을 사용하여 관련 광고를 예측하여 소비자에게 보여주고, 소비자가 클릭할지, 아니면 구매할지 여부를 예측하며, 광고를 할당하고 광고 가격을 책정합니다. 이를 위해 초당 10만 건이 넘는 트랜잭션에서 요청당 수천 개의 광고를 20 ms 이내에 평가할 수 있어야 했으며, 수백 개의 모든 모델에서 각각 다른 하드웨어 및 소프트웨어 최적화가 요구되었습니다.
이 프레젠테이션의 마지막 부분에서는 기계 학습을 대규모로 적용할 수 있었던 몇 가지 방법에 대해 논의합니다. 예를 들어, Amazon Ads는 각 요청에 적합한 광고를 선택하기 위해 딥 러닝 모델을 사용하여 관련 광고를 예측하여 소비자에게 보여주고, 소비자가 클릭할지, 아니면 구매할지 여부를 예측하며, 광고를 할당하고 광고 가격을 책정합니다. 이를 위해 초당 10만 건이 넘는 트랜잭션에서 요청당 수천 개의 광고를 20 ms 이내에 평가할 수 있어야 했으며, 수백 개의 모든 모델에서 각각 다른 하드웨어 및 소프트웨어 최적화가 요구되었습니다.
이러한 워크로드를 처리하기 위해 각 추론 모델 유형별로 하드웨어 및 소프트웨어를 최적화하여 Amazon Elastic Container Service(Amazon ECS) 및 AWS App Mesh에 마이크로서비스 추론 아키텍처를 구축했습니다. 대기 시간이 짧은 추론을 위해 Ads 팀은 CPU 기반 솔루션부터 시작한 다음, 복잡성과 모델 수가 증가하더라도 예측 시간을 줄이기 위해 GPU로 넘어갔습니다.
이 세션은 매우 흥미로운 내용들을 다루고 있으므로 버추얼 re:Invent의 일환으로 온라인에서 시청하거나 직접 참석해보시길 바랍니다.
– Jeff
Source: AWS re:Invent 세션 미리 보기 – Under the Hood at Amazon Ads


Leave a Reply