AWS Step Functions 동적 병렬 처리 지원 기능 출시
마이크로서비스를 통해 애플리케이션을 더 쉽게 확장하고 더 빠르게 개발할 수 있지만, 분산 애플리케이션 구성 요소를 조정하는 작업은 꽤 벅찰 수 있습니다. AWS Step Functions는 각 단계가 이전 단계의 출력을 입력으로 수신하는 여러 단계로 구성된 워크플로를 설계 및 실행하여 조정 작업을 보다 쉽게 도와주는 완전관리형 서비스입니다. 예를 들어, Novartis Institutes for Biomedical Research는 Step Functions를 사용하여 클러스터 전문가에 의존하지 않고도 이미지 분석을 실행하도록 지원합니다.
Step Functions는 사람의 활동과 타사 서비스의 통합을 단순화하는 콜백 패턴 및 모듈형 재사용 가능한 워크플로를 함께 어셈블하는 중첩 워크플로와 같은 매우 흥미로운 기능을 최근에 추가했습니다. 오늘은 하나의 워크플로에서 동적 병렬 처리에 대한 지원을 추가해 보고자 합니다!
동적 병렬 처리 작동 방식
상태 머신은 JSON 기반 구조 언어인, Amazon States 언어를 사용하여 정의됩니다. Parallel 상태는 상태 머신에 정의된 고정된 수의 브랜치를 병렬로 실행하는 데 사용할 수 있습니다. 이제 Step Functions는 동적 병렬 처리를 위해 새로운 Map 상태 유형을 지원합니다.
Map 상태를 구성하려면 전체 하위 워크플로에 해당하는 Iterator를 정의합니다. Step Functions 실행 시 Map 상태로 설정되고 Input 상태로 JSON 배열에서 반복됩니다. 각 항목에 대해 Map 상태는 하나의 하위 워크플로를 실행합니다(잠재적으로는 병렬 실행). 모든 하위 워크플로 실행을 마치면 Map 상태는 Iterator에서 처리하는 각 항목의 출력을 포함하는 배열을 반환합니다.
MaxConcurrency 필드를 추가하여 동시에 실행하는 하위 워크플로 Map 수의 상한을 구성할 수 있습니다. 기본값은 0입니다. 이 경우 병렬 처리에 제한을 두지 않으며, 가능하면 동시에 반복이 호출됩니다. MaxConcurrency 값이 1이면 Iterator는 Input 상태에 표시되는 순서대로, 요소를 한 번에 하나씩 호출하며, 이전 반복이 실행을 마칠 때까지 반복을 시작하지 않습니다.
새 Map 상태를 사용하는 한 가지 방법은, 워크플로에서 팬아웃 또는 분산-수집 메시징 패턴을 활용하는 것입니다.
- 팬아웃은 여러 대상에 메시지를 전송할 때 적용되는 방법으로, 주문 처리 또는 배치 데이터 처리와 같은 워크플로에 유용합니다. 예를 들어, Amazon SQS에서 메시지 배열을 검색할 수 있으며, Map은 별도의 AWS Lambda 함수에 각 메시지를 전송합니다.
- 분산-수집은 여러 대상에 단일 메시지를 브로드캐스트(분산)한 후, 다음 단계를 위해 응답을 다시 집계(수집)합니다. 이 방법은 파일 처리 및 테스트 자동화에 유용합니다. 예를 들어, 10개의 500MB 미디어 파일을 병렬로 코드 변환한 후, 결합하여 5GB 파일을 생성합니다.
Parallel 및 Task 상태와 마찬가지로, Map은 서비스 및 사용자 지정 예외를 처리하기 위해 Retry 및 Catch 필드를 지원합니다. 또한 예외를 처리하기 위해 Iterator 내의 상태에 Retry 및 Catch를 적용할 수도 있습니다. Fail 상태로 전이되거나 처리하지 못한 오류로 인해 Iterator 실행에 실패하면 전체 Map 상태가 실패한 것으로 간주하고 해당되는 모든 반복이 중지됩니다. 오류가 Map 상태 자체에서 처리되지 못하면 Step Functions는 오류를 표시하며 워크플로 실행을 중지합니다.
Map 상태 사용
주문을 처리하는 워크플로에서 Map 상태를 사용하여 주문의 항목을 병렬로 처리하는 워크플로를 만들어보겠습니다. 이 워크플로의 일부로 실행되는 태스크는 모두 Lambda 함수지만, Step Functions에서는 다른 AWS 서비스 통합을 사용할 수 있으며, EC2 인스턴스, 컨테이너 또는 온프레미스 인프라에서 코드를 실행할 수 있습니다.
다음은 몇 개 책과 책을 읽는 동안 마실 커피에 대해 JSON 문서로 표현된 샘플 주문입니다. 주문에는 detail 섹션이 있고, 여기에는 주문의 일부인 items 목록이 있습니다.
{
"orderId": "12345678",
"orderDate": "20190820101213",
"detail": {
"customerId": "1234",
"deliveryAddress": "123, Seattle, WA",
"deliverySpeed": "1-day",
"paymentMethod": "aCreditCard",
"items": [
{
"productName": "Agile Software Development",
"category": "book",
"price": 60.0,
"quantity": 1
},
{
"productName": "Domain-Driven Design",
"category": "book",
"price": 32.0,
"quantity": 1
},
{
"productName": "The Mythical Man Month",
"category": "book",
"price": 18.0,
"quantity": 1
},
{
"productName": "The Art of Computer Programming",
"category": "book",
"price": 180.0,
"quantity": 1
},
{
"productName": "Ground Coffee, Dark Roast",
"category": "grocery",
"price": 8.0,
"quantity": 6
}
]
}
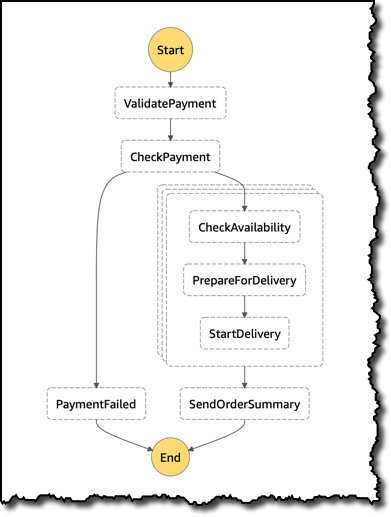
}이 주문을 처리하기 위해 서로 다른 태스크를 실행하는 방법을 정의하는 상태 머신을 사용합니다. Step Functions 콘솔에서는 지금 만드는 워크플로를 시각적으로 표현합니다.
- 먼저 결제를 검증하고 확인합니다.
- 그런 다음, 주문의 항목을 처리하고(잠재적으로 병렬 처리), 항목의 가용성을 확인하며, 배송을 준비하고, 배송 프로세스를 시작합니다.
- 마지막으로 주문에 대한 요약 정보를 고객에게 전송합니다.
- 결제 확인에 실패하면 고객에게 알림을 보내는 등 인터셉트 프로세스를 수행합니다.
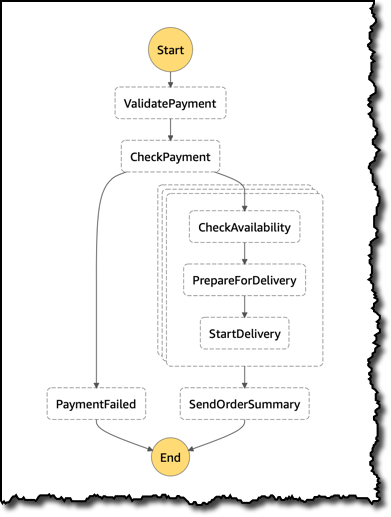
다음은 JSON 문서로 표현된 동일한 상태 머신 정의입니다. ProcessAllItems 상태는 Map을 사용하여 주문의 항목을 병렬로 처리합니다. 이 경우 MaxConcurrency 필드를 사용하여 동시성을 3으로 제한합니다. Iterator 내에 임의의 복잡도를 지닌 하위 워크플로를 삽입할 수 있습니다. 이 경우 항목의 CheckAvailability, PrepareForDelivery 및 StartDelivery를 위한 세 가지 단계를 사용합니다. 이러한 각 단계에서 오류에 대해 Retry 및 Catch 작업을 수행하여 가령 외부 서비스와 통합 시 하위 워크플로 실행의 안정성을 높일 수 있습니다.
{
"StartAt": "ValidatePayment",
"States": {
"ValidatePayment": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:validatePayment",
"Next": "CheckPayment"
},
"CheckPayment": {
"Type": "Choice",
"Choices": [
{
"Not": {
"Variable": "$.payment",
"StringEquals": "Ok"
},
"Next": "PaymentFailed"
}
],
"Default": "ProcessAllItems"
},
"PaymentFailed": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:paymentFailed",
"End": true
},
"ProcessAllItems": {
"Type": "Map",
"InputPath": "$.detail",
"ItemsPath": "$.items",
"MaxConcurrency": 3,
"Iterator": {
"StartAt": "CheckAvailability",
"States": {
"CheckAvailability": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:checkAvailability",
"Retry": [
{
"ErrorEquals": [
"TimeOut"
],
"IntervalSeconds": 1,
"BackoffRate": 2,
"MaxAttempts": 3
}
],
"Next": "PrepareForDelivery"
},
"PrepareForDelivery": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:prepareForDelivery",
"Next": "StartDelivery"
},
"StartDelivery": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:startDelivery",
"End": true
}
}
},
"ResultPath": "$.detail.processedItems",
"Next": "SendOrderSummary"
},
"SendOrderSummary": {
"Type": "Task",
"InputPath": "$.detail.processedItems",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:sendOrderSummary",
"ResultPath": "$.detail.summary",
"End": true
}
}
}이 워크플로에서 사용하는 Lambda 함수는 주문 JSON 문서의 전체 구조를 인식하지 않습니다. 다만, 처리하려는 Input 상태의 일부만 알고 있습니다. 이는 여러 워크플로에서 이러한 함수를 쉽게 재사용하기 위한 모범 사례입니다. 상태 머신 정의는 InputPath, ItemsPath, ResultPath 및 OutputPath 필드를 통해 JsonPath 구문을 사용하는 함수의 입력 및 출력에 사용되는 경로를 조작합니다.
InputPath는 Input 상태의 데이터를 필터링하는 데 사용됩니다. 예를 들어, 주문의detail만Iterator에 전달합니다.ItemsPath는Map상태에 특정하며, 입력에서 처리할 배열 필드를 찾은 위치를 식별하는 데 사용됩니다. 예를 들어, 주문의detail내items를 처리합니다.ResultPath는 태스크의 출력을 Input 상태에 추가할 수 있으며, 완전히 덮어쓰지 않습니다. 예를 들어, 주문의detail에summary를 추가합니다.- 여기에서는
OutputPath를 사용하지 않았지만, 원하지 않는 정보를 필터링하고 다음 상태에서 처리할 JSON의 일부만 전달하려는 경우에 유용합니다. 예를 들어, 주문의detail만 출력으로 전송합니다.
선택적으로 Parameters 필드는 각 반복에 대해 사용된 원시 입력을 사용자 지정하는 데 사용할 수 있습니다. 예를 들어, deliveryAddress는 각 item이 아니라, 주문의 detail에 있습니다. Iterator가 항목의 index를 포함하고 deliveryAddress에 액세스할 수 있도록 다음을 Map 상태에 추가합니다.
"Parameters": {
"index.$": "$$.Map.Item.Index",
"item.$": "$$.Map.Item.Value",
"deliveryAddress.$": "$.deliveryAddress"
}정식 출시
이 기능은 AWS Step Functions가 제공되는 모든 리전에서 사용 가능합니다. 동적 병렬 처리는 Step Functions에서 가장 많이 요청된 기능이었습니다. 이제 이 기능을 통해 새로운 사용 사례 구현이 가능해졌으며, 기존 사용 사례를 최적화하는 데에도 큰 도움이 될 것입니다. 이 기능을 어떻게 활용하는지에 대해 알려주십시오!
– Danilo Poccia, AWS Serverless 테크에반젤리스트


Leave a Reply