AWS Step Functions Distributed Map — 대규모 병렬 데이터 처리를 위한 서버리스 기능 출시
AWS Step Functions용 분산 맵 출시를 발표하게 되어 매우 기쁩니다. 이 흐름은 반정형 데이터의 온디맨드 처리와 같은 대규모 병렬 워크로드 오케스트레이션에 대한 지원을 확장합니다.
Step Function의 맵 상태는 데이터 세트의 여러 항목에 대해 동일한 처리 단계를 실행합니다. 기존 맵 상태는 한 번에 40개의 병렬 반복으로 제한됩니다. 이러한 제한으로 인해 수천 개 항목(또는 그 이상)을 병렬로 처리하도록 데이터 처리 워크로드를 확장하기가 어렵습니다. 오늘날 이전에는 더 높은 수준의 병렬 처리를 달성하려면 기존 맵 상태 구성 요소에 복잡한 해결 방법을 구현해야 했습니다.
새로운 분산 맵 상태를 사용하면 Step Functions를 작성하여 서버리스 애플리케이션 내에서 대규모 병렬 워크로드를 조정할 수 있습니다. 이제 Amazon Simple Storage Service(S3)에 저장된 로그, 이미지 또는 .csv 파일과 같은 수백만 개의 객체를 반복할 수 있습니다. 새로운 분산 맵 상태는 최대 1만 개의 병렬 워크플로를 실행하여 데이터를 처리할 수 있습니다.
Step Functions에서 지원하는 모든 서비스 API를 작성하여 데이터를 처리할 수 있지만, 일반적으로 Lambda 함수를 호출하여 선호하는 프로그래밍 언어로 작성된 코드로 데이터를 처리합니다.
Step Functions 분산 맵은 최대 1만 개의 병렬 실행을 동시에 지원하며, 이는 다른 많은 AWS 서비스에서 지원하는 동시성보다 훨씬 많은 수치입니다. 분산 맵의 최대 동시성 기능을 사용하여 다운스트림 서비스의 동시성을 초과하지 않도록 할 수 있습니다. 다른 서비스를 이용할 때는 두 가지 요소를 고려해야 합니다. 먼저, 서비스에서 계정에 대해 지원하는 최대 동시성입니다. 둘째, 최대 동시성을 얼마나 빨리 달성할 수 있는지를 결정하는 버스트 및 증가율입니다.
Lambda를 예로 들어 보겠습니다. 함수의 동시성은 주어진 시간에 요청을 처리하는 인스턴스 수입니다. Lambda의 기본 최대 동시성 할당량은 AWS 리전당 1,000개입니다. 언제든지 상향을 요청할 수 있습니다. 초기 트래픽 버스트의 경우 한 리전에서 함수의 누적 동시성은 500~3000의 초기 레벨에 도달할 수 있으며, 이는 리전에 따라 다릅니다. 버스트 동시성 할당량은 리전의 모든 함수에 적용됩니다.
분산 맵을 사용하는 경우 다운스트림 서비스의 할당량을 확인해야 합니다. 개발 중에는 분산 맵의 최대 동시성을 제한하고 그에 따라 서비스 할당량 상향을 계획합니다.
새 분산 맵을 기존 맵 상태 흐름과 비교하기 위해 이 테이블을 만들었습니다.
| 기존 맵 상태 흐름 | 새 분산 맵 흐름 | |
| 하위 워크플로 |
|
|
| 병렬 분기 | 맵 반복은 병렬로 실행되며 한 번에 최대 40개 정도의 유효 동시 실행이 가능합니다. | 한 번에 최대 1만 개의 실행을 동시에 실행하여 수백만 개의 항목을 여러 하위 실행에 전달할 수 있습니다. |
| 입력 소스 | JSON 배열만 입력으로 받아들입니다. | 입력을 Amazon S3 객체 목록, JSON 배열 또는 파일, csv 파일 또는 Amazon S3 인벤토리로 받아들입니다. |
| 페이로드 | 256KB | 각 반복은 파일에 대한 참조(Amazon S3) 또는 파일의 단일 레코드(상태 입력)를 받습니다. 실제 파일 처리 기능은 Lambda 스토리지 및 메모리에 의해 제한됩니다. |
| 실행 기록 | 2만 5천 개의 이벤트 | 맵 상태의 각 반복은 각각 최대 2만 5천 개의 이벤트가 있는 하위 실행입니다(익스프레스 모드에서는 실행 기록에 제한이 없음). |
분산 맵 내의 하위 워크플로는 표준 워크플로와 지연 시간이 짧고 기간이 짧은 익스프레스 워크플로우 모두에서 작동합니다.
이 새로운 기능은 S3와 함께 작동하도록 최적화되어 있습니다. 분산 맵 구성에서 내 데이터가 저장되는 버킷과 접두사를 직접 구성할 수 있습니다. 분산 맵은 1억 개 항목 이후 읽기를 중단하고 최대 10GB의 JSON 또는 csv 파일을 지원합니다.
대용량 파일을 처리할 때는 다운스트림 서비스 기능을 고려해 보세요. 다시 Lambda를 예로 들어 보겠습니다. 각 입력(예: S3에 있는 파일)은 임시 스토리지 및 메모리 측면에서 Lambda 함수 실행 환경에 맞아야 합니다. Python용 Lambda Powertools에는 대용량 파일을 더 쉽게 처리할 수 있도록 메모리 공간 사용을 최소화하면서 S3 객체를 가져오고, 변환하고, 처리하는 새로운 스트리밍 기능이 도입되었습니다. 이를 통해 Lambda 함수는 실행 환경 크기보다 큰 파일을 처리할 수 있습니다. 이 새로운 기능에 대해 자세히 알아보려면 Lambda Powertools 설명서를 확인하세요.
실제 작동 모습 살펴보기
이 데모에서는 S3에 저장된 1,000개의 개 이미지를 처리하는 워크플로를 만들 것입니다. 이미지는 이미 S3에 저장되어 있습니다.
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/
2022-11-08 15:03:36 27034 n02085620_10074.jpg
2022-11-08 15:03:36 34458 n02085620_10131.jpg
2022-11-08 15:03:36 12883 n02085620_10621.jpg
2022-11-08 15:03:36 34910 n02085620_1073.jpg
...
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/ | wc -l
1000워크플로와 S3 버킷은 동일한 리전에 있어야 합니다.
시작하려면 AWS Management Console의 Step Functions 페이지로 이동하여 상태 머신 생성을 선택합니다. 다음 페이지에서는 시각적 편집기를 사용하여 워크플로를 디자인하기로 합니다. 분산 맵은 표준 워크플로와 함께 작동하며 기본 선택 항목을 그대로 유지합니다. 다음을 선택하여 시각적 편집기로 들어갑니다.
 시각적 편집기의 왼쪽 창에서 맵 구성 요소를 검색하여 선택한 다음 워크플로 영역으로 드래그합니다. 오른쪽에 구성 요소를 구성합니다. 처리 모드로 배포를 선택하고 항목 소스로 Amazon S3를 선택합니다.
시각적 편집기의 왼쪽 창에서 맵 구성 요소를 검색하여 선택한 다음 워크플로 영역으로 드래그합니다. 오른쪽에 구성 요소를 구성합니다. 처리 모드로 배포를 선택하고 항목 소스로 Amazon S3를 선택합니다.
분산 맵은 기본적으로 S3와 통합됩니다. 버킷 이름(awsnewsblog-distributed-map)과 이미지가 저장된 접두사(images)를 입력합니다.
 런타임 설정 섹션에서 하위 워크플로우 유형에 대해 익스프레스를 선택합니다. 또한 동시성 제한을 제한하기로 결정할 수도 있습니다. 이는 특정 계정 또는 리전에 대한 다운스트림 서비스(이 데모에서는 Lambda)의 동시성 할당량 내에서 운영되도록 하는 데 도움이 됩니다.
런타임 설정 섹션에서 하위 워크플로우 유형에 대해 익스프레스를 선택합니다. 또한 동시성 제한을 제한하기로 결정할 수도 있습니다. 이는 특정 계정 또는 리전에 대한 다운스트림 서비스(이 데모에서는 Lambda)의 동시성 할당량 내에서 운영되도록 하는 데 도움이 됩니다.
기본적으로 하위 워크플로의 출력은 최대 256KB의 상태 출력으로 집계됩니다. 더 큰 출력을 처리하기 위해 맵 상태 결과를 Amazon S3로 내보내기를 선택할 수 있습니다.

마지막으로 각 파일에 대해 수행할 작업을 정의합니다. 이 데모에서는 S3 버킷의 각 파일에 대해 Lambda 함수를 호출하려고 합니다. 함수가 이미 있습니다. 왼쪽 창에서 Lambda 호출 작업을 검색하여 선택합니다. 분산 맵 구성 요소로 드래그합니다. 그런 다음 오른쪽 구성 패널을 사용하여 호출할 실제 Lambda 함수를 선택합니다. 이 예에서는 AWSNewsBlogDistributedMap을 선택합니다.
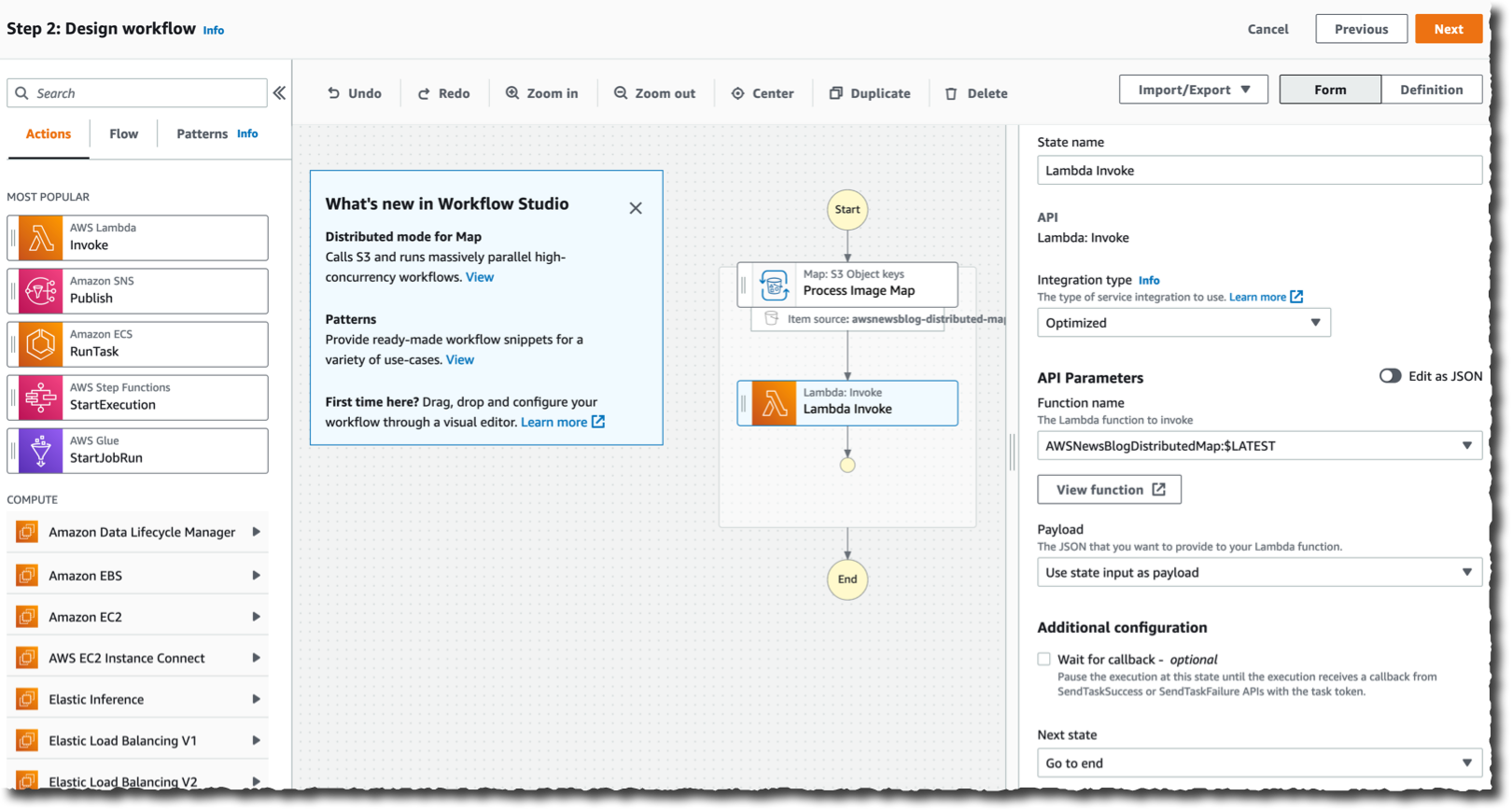
작업을 마치면 다음을 선택합니다. 생성된 코드 검토 페이지(여기서는 표시되지 않음)에서 다시 다음을 선택합니다.
상태 머신 설정 지정 페이지에서 상태 머신의 이름과 실행할 IAM 권한을 입력합니다. 그런 다음 상태 머신 생성을 선택합니다.
 이제 실행을 시작할 준비가 되었습니다. 상태 머신 페이지에서 새 워크플로를 선택하고 실행 시작을 선택합니다. 워크플로에 전달할 JSON 문서를 선택적으로 입력할 수 있습니다. 이 데모에서는 워크플로가 입력 데이터를 처리하지 않습니다. 그대로 두고 실행 시작을 선택합니다.
이제 실행을 시작할 준비가 되었습니다. 상태 머신 페이지에서 새 워크플로를 선택하고 실행 시작을 선택합니다. 워크플로에 전달할 JSON 문서를 선택적으로 입력할 수 있습니다. 이 데모에서는 워크플로가 입력 데이터를 처리하지 않습니다. 그대로 두고 실행 시작을 선택합니다.
 |
 |
워크플로를 실행하는 동안 진행 상황을 모니터링할 수 있습니다. 반복 횟수와 성공적으로 처리되었거나 오류가 발생한 항목 수를 관찰합니다.
 특정 실행 하나를 드릴 다운하여 세부 정보를 확인할 수 있습니다.
특정 실행 하나를 드릴 다운하여 세부 정보를 확인할 수 있습니다.
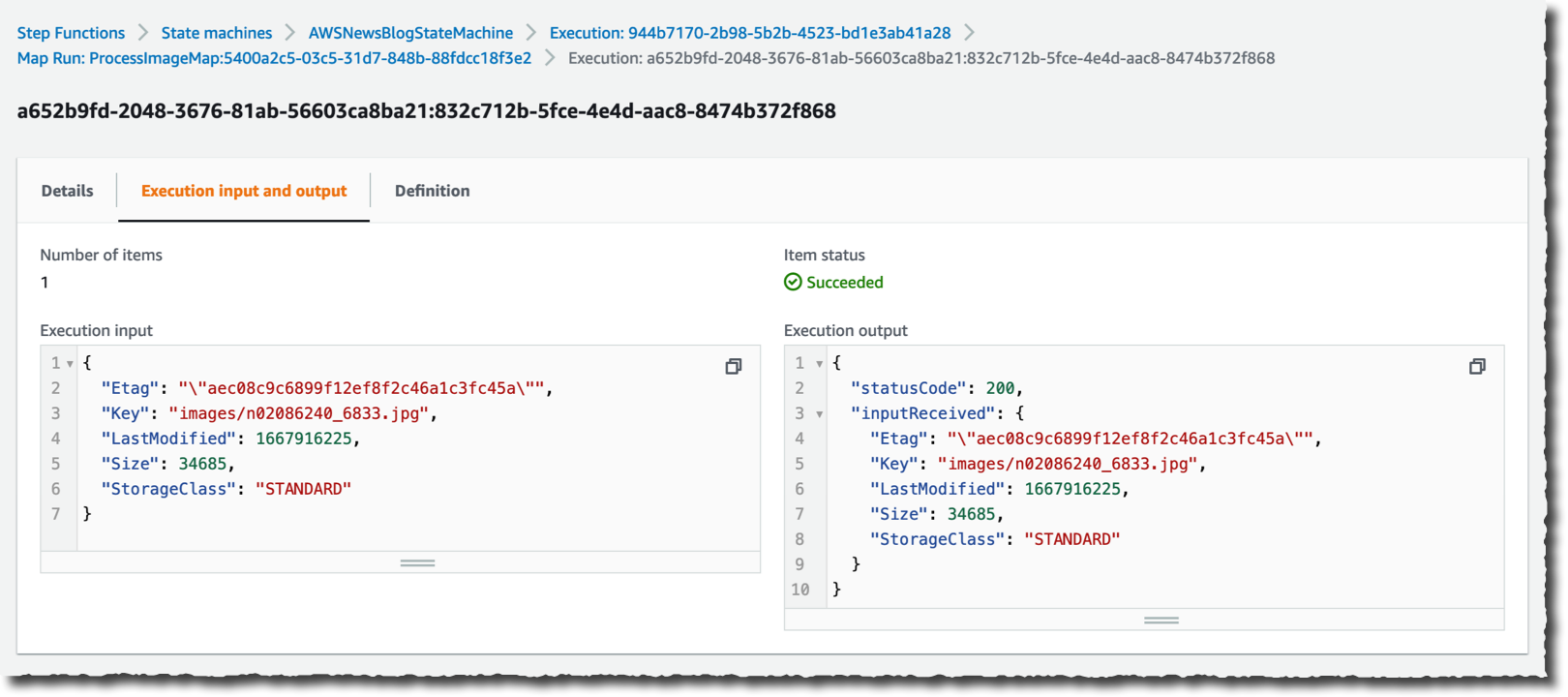
클릭 몇 번만으로 매우 많은 양의 데이터를 처리할 수 있는 대규모 병렬 워크플로를 만들었습니다.
사용해야 하는 AWS 서비스
AWS에서 자주 발생하는 것처럼 이 새로운 기능과 AWS Glue, Amazon EMR 또는 Amazon S3 배치 작업과 같은 기존 서비스 간에 중복되는 부분이 있을 수 있습니다. 사용 사례를 구분해 보겠습니다.
제 멘탈 모델에서는 데이터 과학자와 데이터 엔지니어가 AWS Glue와 EMR을 사용하여 대량의 데이터를 처리합니다. 반면 애플리케이션 개발자는 Step Functions를 사용하여 서버리스 데이터 처리를 애플리케이션에 추가할 것입니다. Step Functions는 0부터 빠르게 확장할 수 있으므로 고객이 결과를 기다리는 대화형 워크로드에 적합합니다. 마지막으로, 시스템 관리자와 IT 운영 팀은 수십억 개의 S3 객체에 대한 복사, 태그 지정 또는 권한 변경과 같은 단일 단계 IT 자동화 작업에 Amazon S3 배치 작업을 사용할 가능성이 높습니다.
요금 및 가용성
AWS Step Functions의 분산 맵은 미국 동부(오하이오, 버지니아 북부), 미국 서부(오레곤), 아시아 태평양(싱가포르, 시드니, 도쿄), 캐나다(중부) 및 유럽(프랑크푸르트, 아일랜드, 스톡홀름)의 AWS 리전에서 정식 버전으로 사용할 수 있습니다.
기존 인라인 맵 상태의 요금 모델은 변경되지 않습니다. 새로운 분산 맵 상태의 경우 반복당 하나의 상태 전환 요금을 청구합니다. 요금은 리전에 따라 다르며, 상태 전환 1,000회당 0.025 USD부터 시작합니다. 익스프레스 워크플로를 사용하여 데이터를 처리하는 경우 워크플로에 대한 요청 수와 실행 시간에 따라 요금도 청구됩니다. 다시 말하지만 요금은 리전마다 다르며 요청 1백만 개당 1.00 USD부터 시작하고 GB-시간당 0.06 USD(100ms로 비례 배분)부터 시작합니다.
동일한 반복 횟수에도 분산 맵과 표준 워크플로를 함께 사용하면 기존 인라인 맵에 비해 비용이 절감되는 것을 확인할 수 있습니다. 익스프레스 워크플로를 사용하는 경우 분산 맵으로 더 많은 가치를 얻으면서 비용은 동일하게 유지될 것으로 기대할 수 있습니다.
이 새로운 기능을 사용하여 여러분이 무엇을 구축할 것인지, 그리고 어떻게 혁신을 열 것인지 확인할 수 있게 되어 기쁩니다. 지금 바로 고도로 병렬화된 서버리스 데이터 처리 워크플로 구축을 시작하세요!
Source: AWS Step Functions Distributed Map — 대규모 병렬 데이터 처리를 위한 서버리스 기능 출시


Leave a Reply