Benchmarking API Management Solutions from NGINX, Kong, and Amazon: Do They Deliver APIs in Real Time?
Speed – it’s key in today’s digital landscape, where consumers can easily switch to a competitor if your app’s performance is too slow. App speed is ultimately driven by responsive, healthy, and adaptable APIs, and one of the critical factors in API responsiveness is the latency introduced by your API gateway. But not all API gateways perform at the same level.
That point was brought home to us last fall when an NGINX customer – a major player in the consumer credit industry – told us about the increasing importance of “real‑time” API performance as more and more apps and other components need to communicate to provide the digital experience users expect. We were highly gratified to learn that NGINX Plus was the only API gateway that achieved the super‑fast API latencies (as low as 10ms) the customer needed. Many other customers, such as Capital One, have also shared with us how they cut latency and improved throughput with NGINX Open Source or NGINX Plus as their API gateway.
We decided to look deeper into the API ecosystem and try to figure out what makes an API “real‑time”. Based on a number of factors, we determined that a real‑time API must process API calls end-to-end in less than 30ms at every percentile through the 99th (meaning that on average only 1 call in 100 takes longer than 30ms).
Comparing API Management Solutions
Our own testing consistently shows that it’s easy to achieve real‑time API performance with our API management solution, which combines NGINX Plus as the API gateway for processing API calls and the NGINX Controller API Management Module for managing both NGINX Plus instances and your APIs as you define, publish, manage, and monitor them across their full lifecycle.
But we understand that you might not want to take our word for it. So we commissioned GigaOm, an independent technical research and analysis firm, for objective and transparent benchmarking of our API management solution and other popular solutions on the market: two solutions that like NGINX can be deployed on premises or in the cloud, Apigee and Kong Enterprise, and two fully managed cloud offerings, Amazon API Gateway and Kong Cloud.
In this blog we summarize the results of GigaOm’s testing (spoiler: NGINX Plus delivered APIs in real time in every tested condition, and the other solutions didn’t). For all the details on the solutions, the testing methodology, and the results, download the free GigaOm report.
Note: The Apigee end user license agreement (EULA) prohibits publication of testing results without Google’s express permission, so unfortunately neither the report nor this blog includes information about Apigee.
Benchmark Overview
GigaOm used the Vegeta HTTP load‑testing tool to generate requests (API calls), and measured how much latency – the amount of time it took to return the response to an API call – the API gateway introduced at various numbers of requests per second (RPS), which it calls “attack rates”. It ran test runs with attack rates starting at 1,000 RPS and scaling up through 5,000, 10,000, 20,000, and so on until Vegeta reported error status codes. Each test run lasted 60 seconds and was repeated 3 times. As shown in the graphs below, GigaOm captured the latencies at the 50th, 90th, 95th, 99th, 99.9th, and 99.99th percentiles and also recorded the longest latency observed during the test run (Max in the graphs).
Results: NGINX vs. Enterprise
GigaOm conducted two benchmarks comparing NGINX Plus (as deployed using NGINX Controller) and Kong Node (as deployed using Kong Enterprise). In the first benchmark, there was a single worker node (one instance of NGINX Plus or Kong Node). In the second, there were three worker nodes load balanced by NGINX Open Source in Round‑Robin mode. (GigaOm stresses that using NGINX Open Source as the load balancer didn’t create an advantage for NGINX Plus, and even Kong recommends it as the load balancer to use for clustered Kong Node instances.)
As shown in the following graphs, the difference in latency between NGINX and Kong is negligible up to the 99th percentile, at which point Kong’s latency starts to grow exponentially. At the 99.99th percentile Kong’s latency is triple or double NGINX’s in the two benchmarks respectively.
The 99th percentile is a decent minimum value for defining an API as real‑time, but GigaOm notes that in real‑world deployments it’s “extremely important” to maintain low latency at higher percentiles like the 99.9th and 99.99th. The report explains:
Latency results tend to be multi‑modal over time, with the tops of the spikes representing “hiccups” in response times.
These hiccups matter. If the median response time or latency is less than 30 milliseconds, but there are hiccups of 1 second or greater latencies, th[ere] is actually a cumulative effect on subsequent user experience. For example, if you visit a fast food drive through where the median wait time for food is 1 minute, you would probably think that was a good customer experience. However, what if the customer in front of you has a problem with their order and it takes 10 minutes to resolve? Your wait time would actually be 11 minutes. Because your request came in line after the hiccup, the delayed 99.99th percentile’s delay can become your delay too.
The negative effect of unusually large latencies at high percentiles becomes even more significant in distributed applications where a single client request might actually spawn multiple downstream API calls. For example, suppose that 1 client request creates 10 API calls to a subsystem with a 1% probability of responding slowly. It can be shown mathematically that as a result there is almost a 10% probability the 1 client request will be affected by a slow response. For details on the math, see Who moved my 99th percentile latency?
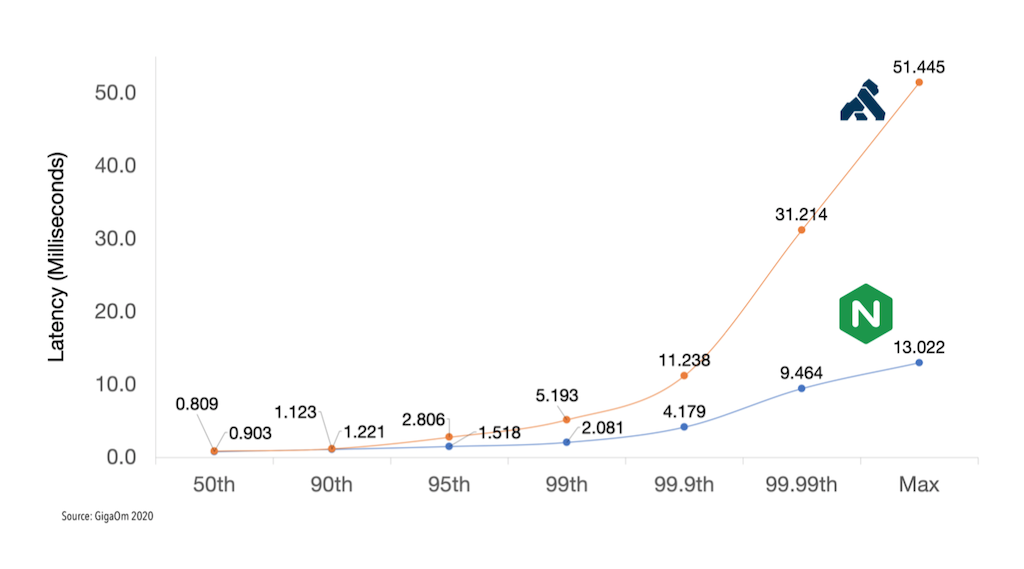
Figure 1 depicts the results for the 30,000 RPS attack rate with a single worker node. At the 99.99th percentile Kong’s latency is more than 3 times NGINX’s, and exceeds the 30ms threshold for real‑time APIs. In contrast, NGINX Plus achieves real‑time latency at every percentile – even its highest recorded (Max) latency of 13ms is less than half the real‑time threshold.
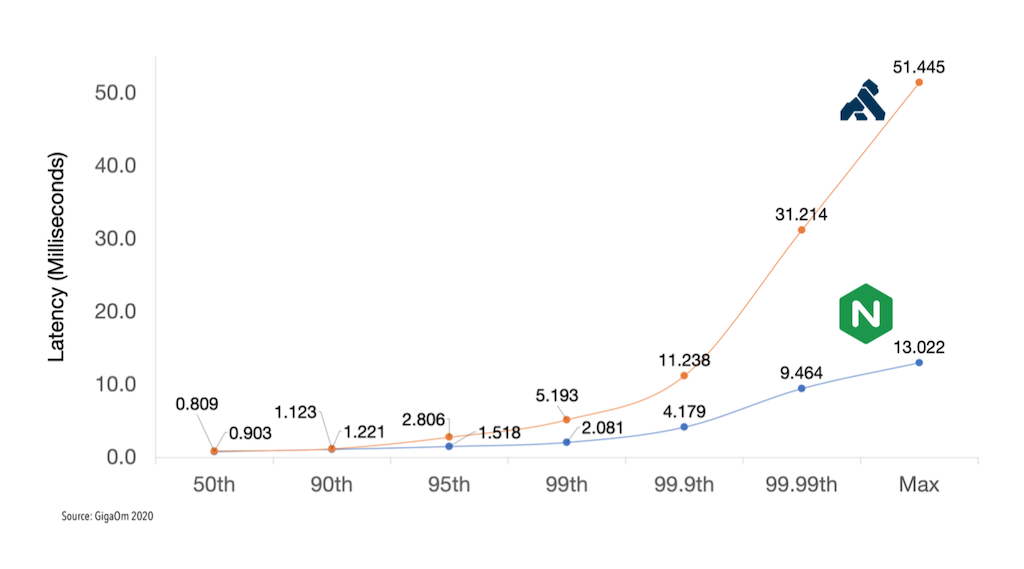
Figure 2 shows very similar results for the benchmark with three worker nodes, also at the 30,000 RPS attack rate. Interestingly, Kong outperforms NGINX at the 99th and 99.9th percentiles, but once again suffers a huge latency spike at the 99.99th percentile, this time hitting a latency that’s about double NGINX’s. As in the first benchmark, NGINX stays below the 30ms real‑time threshold at all percentiles.
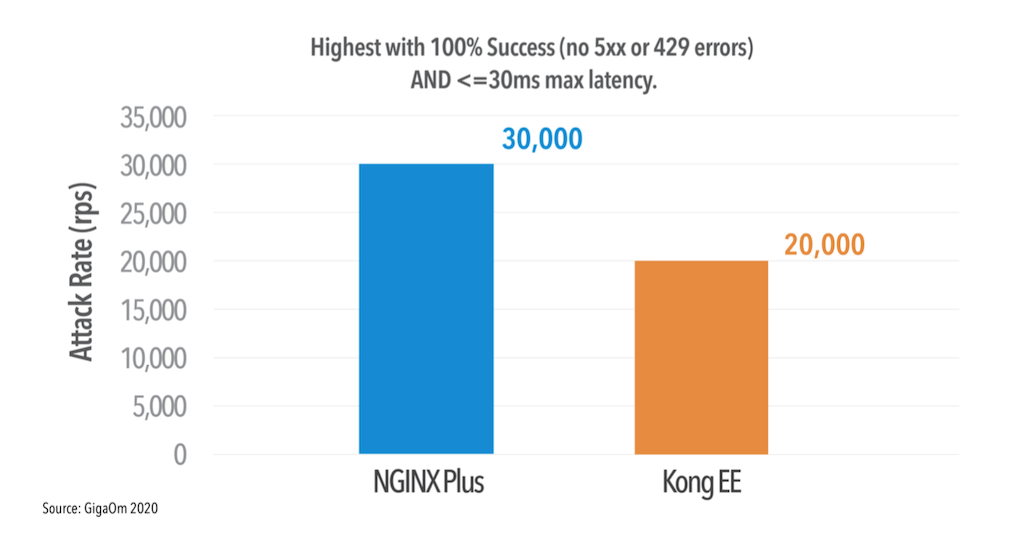
Another way to gauge an API gateway’s performance is to determine the maximum RPS it can process with 100% success (no 5xx or 429 [Too Many Requests] errors) and latency below 30ms at all percentiles, for both the single‑node and three‑node configurations. Figure 3 shows how by this measure, NGINX sustains 50% higher RPS than Kong: 30,000 versus 20,000.
Results: NGINX vs. Kong Cloud and Amazon API Gateway
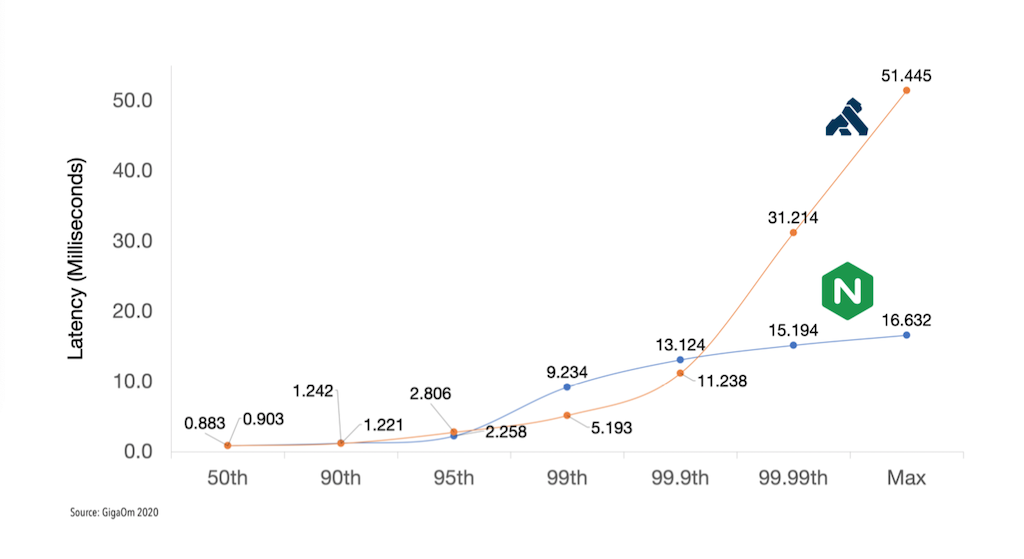
In the third set of benchmarks, GigaOm compared NGINX Plus to Kong Cloud and Amazon API Gateway. GigaOm stresses that a direct comparison is highly problematic because Kong Cloud and Amazon API Gateway are fully managed SaaS offerings, while NGINX Controller is a PaaS offering and not currently available as SaaS. In particular, neither SaaS offering reveals the instance type, compute power, memory, or networking capabilities it uses. GigaOm therefore had to make a best guess at the comparable settings to make for NGINX Plus.
Even setting aside comparison with NGINX Plus, it’s immediately clear that the SaaS offerings cannot deliver APIs in real time at any of the tested percentiles, even at the second‑lowest attack rate (5,000 RPS) shown in Figure 4. At the 50th percentile, the SaaS offerings’ latency is already more than 7 times the 30ms threshold; at the 99.99th percentile, it exceeds that threshold by more than 8000%. The obvious implication is that there are no conditions under which Kong Cloud or Amazon API Gateway achieves 100% success with latency under 30ms.

Validating NGINX as the Only Real‑Time API Solution
In summary, NGINX is the only solution tested by GigaOm that met the standards of real‑time API processing, achieving less than 30ms of latency at every percentile. Kong Enterprise attains real‑time performance at the 99th percentile, but latency spikes signficantly at higher percentiles, making it ill‑suited for production environments that require even a moderate volume of real‑time API processing. Neither of the tested SaaS solutions can be categorized as real‑time.
The GigaOm report validates both our previous benchmarks and what we hear from our customers. NGINX Plus is the fastest API gateway in the market and the only API solution capable of sustaining a latency of less than 30ms at all percentiles. And if you pair it with NGINX Controller, you gain access to a uniquely architected API management solution where because of careful decoupling there is no impact whatsoever on the performance of the API gateway data plane (NGINX Plus) from the API management control plane (NGINX Controller).
Here we’ve summarized the high‑level results from the GigaOm report. For complete details, download the complete report for free. You can also test your own API performance with our rtapi latency measurement tool. Check it out and get in touch with us to discuss how we can help you make your APIs real time.
The post Benchmarking API Management Solutions from NGINX, Kong, and Amazon: Do They Deliver APIs in Real Time? appeared first on NGINX.


Leave a Reply