Building in 10k: Svelte JavaScript Enhancements
Editor’s note: This is the fifth in a series of posts from the team that built the 10k Apart contest site, exploring the process of building for interoperability, accessibility, and progressive enhancement in less than 10kB.
In the previous post in this series, I discussed my approach to CSS for the 10k Apart site. Now it’s time to add the icing to our user experience cake with JavaScript.
What happens when JavaScript doesn’t?
First off, let me start by assuring you: I love JavaScript. Love it. Seriously. I write it every day and have for well the better part of two decades now. In all of my years working with JavaScript, however, I’ve been reminded of one thing over and over: there’s no guarantee my users will get my JavaScript or, if they do, there’s no guarantee it will run. In other words, I learned that I can’t depend on it.
Doug Crockford once (in)famously quipped “The Web is the most hostile software engineering environment imaginable” and he’s right. The Web is awesome, but unlike most traditional programming environments, we (as the programers) have absolutely no control over the execution of our code. None. We could write the most heavily-tested, lint-ed, robust JavaScript framework on the planet and a spotty network connection, a browser plugin, a firewall, or an error in some piece of 3rd party code could bring it to its knees in a millisecond. True story.
Talk like this is probably why I don’t get invited to present at as many JavaScript conferences as I used to, but it’s the harsh reality of development for the Web. There are no guarantees. Any dependencies we take on in the process of building our browser-based interfaces may not be met and we need to be prepared for that eventuality. Heck, jQuery is one of the most ubiquitous JavaScript libraries out there, with an amazing CDN infrastructure backing it, but a simple misdiagnosis of cdn.jquery.com as malware broke the Web for several hours for many of Sky Broadband’s subscribers back in 2014.
This is why the philosophy of progressive enhancement is so important. It keeps us focused on the core experience and frames everything else in terms of enhancing that experience. Markup? Enhancement. HTML5 form fields? Enhancement. Visual design? Enhancement. Responsive layouts? Enhancement. Print styles? Enhancement. Rich interactions? Enhancement, enhancement, enhancement.
Progressive enhancement isn’t concerned with the technologies we use, just the way we use them. It doesn’t say not to use JavaScript, it simply cautions us not to rely on it. Same with CSS. Same with HTML. Heck, same with the network for that matter. Nothing is guaranteed. We start with a core experience that works for everyone and then improve that experience using the tools we have at our disposal: HTML, CSS, JavaScript, SVG, images, video, and so on. We use these tools to build up the experience in layers, making it better and better with each successive layer while simultaneously realizing that not everyone will be able to use each layer. Ben Hoh frames this as keeping “the design open to possibilities of sexiness in opportune contexts.” I wish I’d come up with that.
All of this is to say that the 10k Apart site will run just fine without any front-end JavaScript. You can move from page to page. You can enter the contest. You can send us a message. You can view the gallery. You can do anything you would possibly want to do on the site without ever executing a single line of the JavaScript code I’ve so lovingly written for you. And I’m okay with that.
Where do you draw the line with support?
When it comes to browsers, I’m a big fan of thinking in terms of support vs. optimization. I do everything I can think of to support any browser that’s out there, but I optimize for the more modern and popular browsers. Taking a progressive enhancement approach means I can deliver better experiences in browsers that are more capable without sacrificing good experiences in older browsers in the process. Furthermore, when it comes to JavaScript, by having each script test for its own dependencies, I can deliver enhancements in an à la carte fashion. Each browser gets the enhancements it can implement, and browsers that can’t handle the enhancement don’t encounter errors.
I do draw one line in the sand and it’s mainly for my own sanity: I no longer send JavaScript to IE8 or below. It was a good browser for its time and actually supports more modern JavaScript APIs than you’d think (which I will discuss shortly), but I already cut it off from layout enhancements. Using support for media queries as a prerequisite for layout, I leave IE8 and below with a linear mobile-style layout. It saves me a lot of testing time if I don’t have to fire it up to test all of the JavaScript functionality in it, and lets me spend more time making the experience even better in modern browsers.
If you’re wondering how I accomplish that, it’s a bit of black magic from the Microsoft vaults: Conditional Comments. If you’re familiar with Conditional Comments, you probably remember them looking a little like this:
.gist table { margin-bottom: 0; }
They were a proprietary technology Microsoft used for directing specific code to their browser or particular versions of their browser. It had its uses for sure, but as IE advanced, they became less and less necessary with each subsequent release. In IE10 they were abandoned all together.
So why I am bringing them up? Well, there is a special type of Conditional Comment called downlevel-revealed that turns the tables on older IE versions:
.gist table { margin-bottom: 0; }
Looks really weird, right? It is. But it’s also magic. Let me break this down a little bit for you so you can see what’s happening:
<!--[if gt IE 8]>— This kicks off a Conditional Comment focused on IE9 or better; IE8 and lower will ignore the contents of this conditional comment entirely.<!-->— Browsers that don’t understand Conditional Comments see this as some gibberish followed by the close of a comment (-->). The<!bit keeps IE9 (which does understand Conditional Comments) from displaying-->as text.<!--— This kicks off a new comment for browsers that don’t support Conditional Comments.<![endif]-->— This is the way Conditional Comments are normally closed.
It feels a little weird I know, but this is a fool proof way to deliver only a subset of your markup to particular browsers. In the case of the 10k Apart site, I use it to hide all of the script references that come after at the end of the body.
If you like this approach as much as I do, just be sure you’re still using feature detection to avoid throwing errors in older browsers that aren’t IE. This approach only handles the “Old IE” issue for you.
What library did I chose and why?
If there’s one thing the last decade or so of JavaScript development has taught us, it’s that no one writes JavaScript anymore. We write jQuery, Prototype, Dojo, Zepto, or another of the countless JavaScript libraries out there that have APIs we like better or offer a richer set of plugins that do what we need done. I mean why reinvent the wheel?
As great as many of these libraries are, there’s something to be said for vanilla JavaScript. First off, it’s faster than library code. Consider this simple comparison of how many times you can run document.getElementById() and its library equivalents in a second:
| Library | Code | Operations/second |
| Native JS | document.getElementById('test-table') |
12,137,211 |
| Dojo | dojo.byId('test-table') |
5,443,343 |
| Prototype | $('test-table') |
2,940,734 |
| Ext JS | delete Ext.elCache['test-table']; Ext.get('test-table'); |
997,562 |
| jQuery | jQuery('#test-table') |
350,557 |
| YUI | YAHOO.util.Dom.get('test-table') |
326,534 |
| MooTools | document.id('test-table') |
78,802 |
This table and many more can be found on the awesome (and often hilarious) vanilla-js.com.
It’s worth noting that not all of these lookups are one-for-one aliases for document.getElementById(), but even creating a simple alias creates overhead. Abstraction, while often useful, comes at a cost. Typically that cost is performance or memory usage.
Many of the things we picked up JavaScript libraries to help us with in the mid-to-late 2000s are no longer necessary. I remember having a conversation with John Resig, creator of jQuery, years ago in which remarked that JavaScript libraries would be completely unnecessary if browsers had a standard event model and easier DOM traversal. He wasn’t wrong. Half the jQuery code I see out there seems to involve finding an element using a CSS selector and then making it do something when hovered or clicked.
.gist table { margin-bottom: 0; }
We got solid, interoperable support for DOM traversal using CSS selectors all the way back in 2009 when it landed in IE8:
.gist table { margin-bottom: 0; }
And the W3C event model was (finally) implemented in IE9 in 2011, meaning we no longer needed to bloat our code with two methods of event assignment.
There are also a ton of other awesome, interoperable, native APIs you may not be aware of:
dataset– Reads and writes custom data attributes and has been widely available since 2013.classList– Adds, removes, toggles, and searches class values and has been widely available since 2012.JSON– Natively parses & creates JSON and has been widely available since 2009.Web Storage– Stores key/value pairs for the duration of the session or longer and has been widely available since 2009.
Heck, even basic ajax support hasn’t required library code since 2007. All of this is to say that if you’ve been using a library to smooth things over in the JavaScript world, you may not actually need it anymore.
With all of this mind, we opted not to grant libraries like jQuery a free pass in this year’s competition. And I built all of the JavaScript enhancements for the site without a lick of library code.
How do I organize my JavaScript?
While there isn’t a ton of JavaScript driving the 10k Apart site, I thought it was important to keep my code organized. For the last few years, I’ve been using task runners (Gulp, Grunt, etc.) to merge & minify my JavaScript code. I’ll talk about that process a bit more in the next post, but I thought I’d take a few minutes to talk about my current approach to organizing my JavaScript code. If that’s not interesting to you, feel free to skip this section.
I like to keep my general purpose JavaScript file (main.js) as small as possible. That way folks who don’t hit every page on my sites don’t have to download code they’re unlikely to need. My general rule of thumb is that certain functionality is used in more than one page, I’ll drop it in the main JS file. If it’s shared across multiple pages, but is also incredibly task-specific and requires a decent amount of code to work, I’ll break it out into a separate file. If it is completely page-specific, I’ll either embed it in the page directly or break it out into its own file as well.
I organize my JavaScript source code into subdirectories, one for each file I eventually want my task runner to build. Within each of those directories I keep maintain discrete functions or behaviors in individual files. In the case of the main.js file, its source is in the main directory. That directory contains the following files:
_.js– This file holds any preamble code necessary, like my ‘use strict’ declaration._getActiveMQ.js– A utility for returning the current media query._watchResize.js– Another utility method for observing resize events.eu-cookie-law.js– Behaviors related to legally-mandated cookie notifications.ga.js– Lazy loader for Google Analytics.lazy-images.js– Lazy loader for images (I’ll discuss this shortly).link-all.js– Spreads the link love to container elements.storage-test.js– Checks for the availability of and permission to uselocalStorageandsessionStorage.svg-test.js– Checks to see if the browser supports SVG.Ω.js– Holds any code that needs to be at the end of the file.
Some of those names—like the ones that begin with underscores and the mysterious Ω—may seem a little odd, but they’re important because task runners concatenate files in alphabetical order. Putting an underscore in front of the file name (or as the file name) ensures that file get picked up first or at least early in the build. The Greek omega (Ω) will alphabetize after any of my Latin alphabet filenames, so I can rest assured it will always be added to the end of the final file.
In total, the 10k Apart project has ten JavaScript files:
enter.js– Code related to the entry form.form-saver.js– Saves what you type in forms until you submit them. I’ll discuss this script below.gallery.js– Code related to the gallery.hero.js– Code related to the homepage hero.home.js– Code related to the homepage.html5shiv.js– This is the one bit of 3rd party code (apart from Google Analytics) that we’re using. It ensures styles applied to HTLM5 elements make it to non-HTML5 browsers. It gets sandboxed in a Conditional Comment.main.js– Code that gets used on all pages.project.js– Code specific to project pages.serviceworker.js– You guessed it: Our Service Worker, which I will discuss below.update.js– Code specific to a page we will use for winners to update their profile with mailing addresses and such. I’ll also be talking a little bit about this one later on.
On any given page, only one or two of these files will get loaded via script elements. Others may be lazy loaded as needed by the main JavaScript file or the page-specific JavaScript.
So that’s a quick and dirty overview of how I’ve organized the JavaScript source files. I’ll talk more about the build process, concatenation, minification, and more in the final post in this series. As with most things in life, this approach may work for you and your projects or it may not. It happened to work well for this one.
Images are huge, how do you justify including them?
As I mentioned way back in the first post in this series, I think the images we use on the site—predominantly judge photos and project screenshots—are nice to have, but are by no means necessary. As such, I consider them an enhancement and chose not to include img or even picture elements in the page source. Doing so would cause the images to be downloaded by everyone. Instead, I’ve opted to lazy load these images via JavaScript once the page loads. If the JavaScript never runs for a user, they won’t get the images and I’m okay with that. I chose to go image-less by default because I wanted to ensure that the baseline experience was as fast as it could possibly be.
So how do the images end up on the page? I use data attributes to provide the path to the image I want to load as well as a few other details about how I want to load it. Here’s an example:
.gist table { margin-bottom: 0; }
This is Rachel Andrew’s listing in the judges section. The data-img attribute acts as declarative instruction for the JavaScript to lazy load an image into this list item. As there were a few different ways I wanted to configure the lazy loader, I opted to include the specific instructions right there in the value of the attribute, separated by vertical pipes (|):
- The path to the default image –
/i/j/r.jpg - The alt text I want to use or nothing if I want an empty alt, as I do in this case (having an
alt="Rachel Andrew"seems redundant) - Whether or not it should prepend the lazy loaded image to the element with this data attribute (the list item in this case)
The API for the lazy loader also lets me define an optional descendent selector as the home for the lazy loaded image, but I didn’t need that for this instance.
Over in the JavaScript, I look for the data-img attribute and create a skeleton picture element. I then loop through the elements I found that have that attribute and clone the picture element and insert it (as instructed) into each of the elements. I opted to create and clone a single picture element (and its child nodes) rather than creating a new set of elements each time I need an image because it is less expensive in terms of CPU and RAM usage.
Each picture contains a source element and an img. In the case of Rachel’s image, that ends up looking like this:
.gist table { margin-bottom: 0; }
Every JPG and PNG on the site has a WebP equivalent that is (in the majority of cases) significantly smaller. But since WebP is not universally supported, I chose to offer either the WebP or the original source image. Each WebP source gets a type attribute equal to the WebP MIME type so the browser can decide whether to use that option or move on to the JPG or PNG option. The img with the default src provides the original image value and acts as a fallback for browsers that don’t support picture.
Once the image has been lazy loaded, the element gets updated to indicate it shouldn’t be touched again:
.gist table { margin-bottom: 0; }
If you’re interested in dissecting the code, you can see I’ve put the full source of the lazy loading script in a Gist. It also includes the option to indicate an image has an SVG version available too. I thought I might use that, but I didn’t end up needing it in the end.
What about that hero image on the homepage?
The homepage hero was a bit of a different beast. First off, it’s an SVG. It’s also right around 10k in size. That may seem tiny from a hero image perspective—especially given that it’s interactive—but it would blow the page load budget if we had it in there by default. The hero would take up a significant amount of room on smaller screens, which could make for a less-than-optimal reading experience.
For all of these reasons, I opted to lazy-load the hero image using JavaScript, but I also added the additional constraint of only loading it in the two largest responsive layouts, when it can sit comfortably to the right of the contest introduction. To accomplish this, I used two of the utility methods introduced above: watchResize() and getActiveMQ().
The watchResize() method is a custom event observer that looks for changes in browser size and then executes the callback you provide to it. The problem with tracking window.onresize is that that particular event fires repeatedly while the browser window is resizing. Running JavaScript code repeatedly during that process would negatively affect the performance of the page. Obviously we don’t want that, so watchResize() throttles the callback execution and only fires when there is a pause in resizing for more than 50ms. In most cases that means it executes the code once per resize or device rotation. It also executes the callback once during initialization to ensure the code is run when the page loads too.
The getActiveMQ() method uses some clever CSS-to-JavaScript communication to indicate the name of the current media query being applied. It does this by generating a hidden div into the body and then reporting that element’s font-family property. Within the CSS, I use Sass to capture each of the breakpoints I defined and spit out a corresponding CSS rule:
.gist table { margin-bottom: 0; }
What this results in is a series of media query-wrapped rules:
.gist table { margin-bottom: 0; }
and so on. Taken all together, the code for loading the hero SVG is triggered like this:
.gist table { margin-bottom: 0; }
This means that every time the browser is resized (or when it initially loads), I check to see if the hero has already been loaded. If it is loaded, the script just quietly exits. If it isn’t however, I can get the current media query and see if it’s the “larger” or “full” one. If it is, I’ll go ahead and lazy load the hero image.
I won’t get into all of the code for lazy loading the SVG, but I do want to talk about a few of the other optimizations I have in place for this functionality. The first is that I use the SVG test (mentioned above) to determine whether to lazy load the SVG image or a raster image alternative. That ensures folks that can’t handle SVG have the opportunity to potentially see Sarah Drasner’s amazing illustration.
Another optimization I put in place is local caching of the hero’s embed code. Once JavaScript determines the appropriate markup to inject into the homepage, it looks to see if localStorage is available. If it is and the user has granted us permission to use it, the script will store the markup in localStorage and then retrieve it the next time the page is loaded, rather than making a network request for the SVG. It’s a minor tweak but speeds up subsequent page loads considerably.
Can I improve the speed of the gallery?
The gallery is probably one of the more computationally-expensive sections of the contest site, both in terms of back-end processing and front-end construction. Not only does it have to request the entries from the database and assemble the page, but if client-side JavaScript is available, there are all the images to lazy load as well. In order to reduce some of that overhead, I decided to cache the pages gallery entries in sessionStorage. I chose sessionStorage over localStorage in this instance as I knew the content would likely get updated with a decent amount of frequency and only wanted to persist the gallery pages for the duration of the session. That would make it far easier to move back and forth in the gallery without making repeated round trips to the server.
If JavaScript isn’t available, the gallery is just a series of static pages, served up by Node. The pagination works just as you’d expect. However, if JavaScript is available, those pagination links get hijacked and become Ajax requests that update only the main content of the page (the gallery and the pagination links). When the content is loaded via Ajax, the images are lazy loaded. And finally, if the browser has sessionStorage and we have permission to use it, the rendered contents of the gallery page (including the lazy-loaded picture markup) gets added to sessionStorage.
The next time a request comes in for that page, be it via a click on the pagination buttons or the back and forward buttons, the sessionStorage cache is consulted. If a match is found, the contents are loaded from the cache instead of making the Ajax request again. It’s not a terribly complex setup, but it’s quite effective at speeding things up for folks whose browsers don’t yet support Service Worker (I’ll get to that I promise).
The one piece of this I think is worth discussing is how the events are handled. Often, when we are assigning event handlers to elements, we assign them directly to the elements in question. It works well in most scenarios, but when you are dynamically adding and removing elements from the DOM, this approach forces you to continually add new event handlers whenever you add new elements to the page. It’s not terribly efficient and requires keeping track of page updates. Thankfully, there’s a better way: event delegation.
If you’re a jQuery user, you may have used event delegation before. It often looks like this:
.gist table { margin-bottom: 0; }
What’s happening here is that you are looking for the click event to fire on .child, but you are actually attaching the event handler to .parent. This is really useful when .parent contains multiple .child elements that can be added or removed at any time. When attached to the parent, the event handler persists. This works because of the way the W3C event model was designed: Events move down and up the DOM tree in the capture and bubble phases, respectively. That means the click on .child fires on .parent as well.
jQuery makes this pretty easy to do, but it’s always been a little more complicated in vanilla JavaScript. Here’s a simplified version of how I did it:
.gist table { margin-bottom: 0; }
In this code I’m identifying the main element and setting an event handler on it named paginate. The paginate function then verifies whether or not the event’s target element was one of the pagination links (using matches()) and, if it is, goes on to handle the click.
Using this approach, I can replace the contents of main over and over, and the pagination links (which are contained within the main element) will still use Ajax to load new content (or load content from the sessionStorage cache if it exists).
Can I speed up address entry?
Though it will only benefit four users of the site, I opted to enhance address entry in the form we will use to update the contest winners’ profiles with mailing information. I thought it offered a nice opportunity to explore ways I could speed up data entry. My idea was to enable users to enter a street address and postal code, at which point I could predictively present options for their country and town.
Here are the form fields involved:
.gist table { margin-bottom: 0; }
As I mentioned in my post on the markup for the site, autocomplete’s new token capability can definitely speed things up by enabling browsers to pre-fill this form with a user’s information. It provides the quickest path to completion. To expedite things, I’ve used the following tokens with the “shipping” modifier:
- street-address,
- postal-code,
- country-name, and
- address-level2.
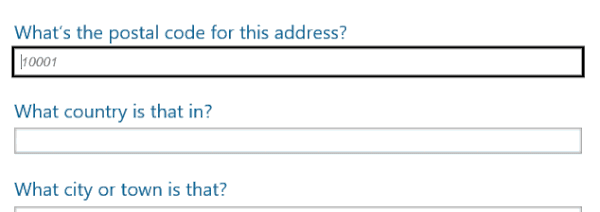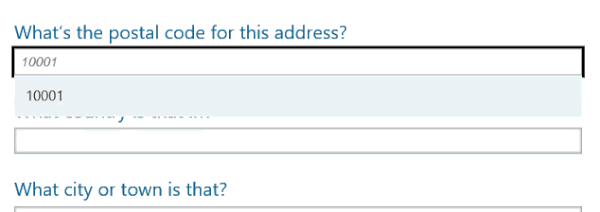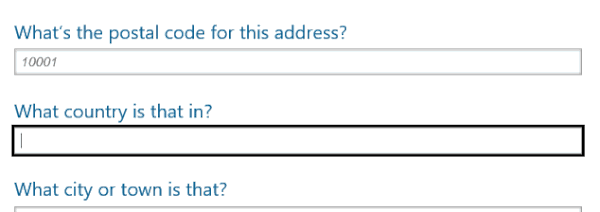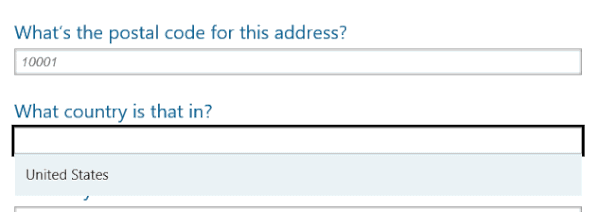
All of those are pretty self-explanatory, with the possible exception of “address-level2”, which indicates the town or city. Here’s the briefest of demos covering the auto-complete experience:

Animation showing Microsoft Edge auto-completing the postal code and country fields.
The next enhancement came directly via JavaScript. I knew we could do geo-coding lookups against postal codes to get back potential locales they describe, so I organized the form so that you entered the street address first, followed by the postal code. Then I use Ajax to retrieve a list of potential locations matching that postal code from GeoNames. The country options are piped into a datalist that I connect to the country field to enable native predictive typing. Then, when a user chooses the appropriate country, I automatically populate the city information.
From a markup standpoint, the datalist bit is connected like this:
.gist table { margin-bottom: 0; }
You’ll notice the datalist has an id that is referenced by the field’s list attribute. I added event listeners to the postal code field (running on “keyup”) and to the country field (on “change”) to trigger the lookup and auto-population. Here’s the end result:

Microsoft Edge interacting with the Ajax-driven auto-complete.
What I really like about this pattern is that it degrades quite well (to a bunch of text fields) and if none of the options are accurate, users can still manually enter the correct value because they are all free response fields. Look ma: No long select lists!
Can I ease folks’ form fail frustrations?
When it comes to forms, HTML5 gave us a lot of awesome affordances and reduced our reliance on JavaScript by enabling native in-browser validation. Still, forms are an area where we can add a lot of value via scripting. You’ve seen one example of that, but I wanted to do more.
One of my biggest frustrations with forms is when I’ve spent a long time filling in the form fields and the browser crashes or my network connection goes down and I lose everything that I just typed. I’ve run into this issue countless times, annoying me to the point that I began using extensions like Lazarus to guard my form entries. But not everyone has a form-saving extension, nor should they have to. We can provide similar functionality quite easily.
I created a JavaScript object called formSaver that is initialized with a single argument: a selector pointing to the form you want to enable this feature on. I opted not to run it for every form in order to make it more portable to other projects. A search form, for instance, would not be a good candidate for this functionality. The contact and entry forms, however, are excellent candidates for this functionality.
The formSaver tracks keyup events in any non-disabled fields (in addition to change and blur events) and saves the contents of each field in the user’s localStorage as a JSON string assigned to the page. I chose localStorage over sessionStorage on the off chance the browser crashes (which would result in sessionStorage being cleared). When the formSaver is initialized, it checks localStorage for saved form values and will automatically re-populate the form.
Obviously I don’t want this information to persist beyond successful form submission because that wouldn’t be terribly helpful. In my first pass on the script, I purged the saved form values when the form was submitted, but then I remembered how many times I ran into networking issues that caused my form submissions to fail. With that in mind, I moved the purge code to the confirmation pages. That way I’m assured it isn’t cleared before the form has been successfully submitted.
How can I help users avoid errors in forms?
Helping users avoid errors is yet another way to reduce the friction inherent in filling out forms. There are numerous ways to do this: Noting required fields, providing hints as to the type of information we’re requesting, and enabling client-side validation are just a few of the ways we can do that. Some of these can be accomplished through markup alone. Others require a little intervention.
In the entry form, the project description field has both a minimum and a maximum character count. There’s no way to account for that purely in markup. I added a message informing users of the requirements for the field, but counting characters is not all that easy. I’ve been wiring for years and rarely have a sense of how many characters I’ve written; I doubt I’m the only one with this issue. We’re validating on the server side of course, but I’d hate to make folks have to test by trial an error.
In order to provide a little assistance, I decided to get JavaScript involved. My plan was to provide both visual, textual, and audible feedback to users as they type in the description of their project. The first step was to provide the baseline experience for everyone, regardless of JavaScript availability.
.gist table { margin-bottom: 0; }
Then I added some declarative instruction for the JavaScript via a data attribute—data-count—which I set to the acceptable character range, 10–500:
.gist table { margin-bottom: 0; }
Next I jumped over to the JavaScript and wrote some code to tweak the ARIA description so a screen reader would read out any changes:
.gist table { margin-bottom: 0; }
The aria-live attribute indicates that screen readers pay attention to changes to the content within the element. The aria-atomic attribute controls whether only the changed content should be read out (indicated by a value of “false”) or if the entire contents should be read out (indicated by a value of “true”). My plan was to update the contents of this strong element via JavaScript at three key milestones related to filling in the field:
- Less than 10 characters — The user needs to write more;
- Between 10 and 500 characters — The user’s description is an acceptable length; and
- Over 500 characters — The user needs to do some editing.
The next step involved adding an event handler to the textarea to track key presses. When the user types in the field, the handler checks the length of the field against the upper and lower bound defined in the data-count attribute. When a user hits one of these milestones, the message in the strong is updated to provide them with feedback on their progress.
In addition to the visible change of text and the audible cues for screen reader users, I decided to trigger some style changes to visually reinforce the current state. I did this by doing some class swapping, setting “count–under”, “count–over”, and “count–good” as appropriate. These class values would trigger color changes for the field itself and the message below it. To provide another subtle visual cue, I also applied the color-fade technique to the field using CSS animations when I updated the class:
.gist table { margin-bottom: 0; }
Taken all together, it’s a simple and effective, offering multiple ways for users see where they’re at in relation to the lower and upper character limits for the field.
What else can I do to improve performance?
I’ve been somewhat mystified by Service Worker ever since I saw Jake Archibald give a brief presentation on it at Responsive Day Out. It’s a very ambitious spec and has the potential to change the way we manage many of our interactions with the server and our users.
One of the key ways we can use Service Worker today is to gain fine-grained control over the caching of our pages and assets. I’ve written a Service Worker from scratch before for my own site, but after taking a stroll through the incredibly well-organized and well-documented Service Worker Lyza Danger Gardner created for Smashing Magazine, I decided I would write a new one, using hers as a template.
Following Lyza’s lead, I only really ran into one gotcha involving image caching: cross-domain requests made to a server that does not implement CORS will return an “opaque” response from fetch(). If you are only looking for the response to have an ok property that’s true, you’re not going to get that with an opaque response. According to Jake, Chrome does support caching of opaque responses, so with a minor tweak to the conditional that governed caching I was able to get the project screenshots to cache as well:
.gist table { margin-bottom: 0; }
Using the Service Worker, the vast majority of the site’s pages and assets are cached, making subsequent page loads even faster. One tricky thing about Service Worker is that when you create one it will persist. Your Service Worker will compare itself against its döppelganger on the server regularly though. If it notices so much as a byte difference between itself and the file on the server, it will begin the update process. That process looks like this:
- Service Worker notices a difference between itself and the file on the server and flags the server file as new.
- The browser will start up the new Service Worker which will, in turn, fire its
installevent. - The current Service Worker will enter a waiting state, but will still be in control.
- When all of the tabs open to your site are closed, the old Service Worker will hand over the reigns to the new one and head to a farm upstate.
- The new Service Worker will fire its
activateevent and do a little dance.
Since a byte difference is all that’s needed to kick off this process, most developers opt to include a VERSION constant that they can easily update when they need to refresh their Service Worker. They also use that to prefix their caches so they can be easily trashed and the new Service Worker can cache it all again.
I opted to manage version bumping by automatically updating my VERSION constant whenever I run my JavaScript build task. I did this by putting a little Mustache in the Service Worker file:
.gist table { margin-bottom: 0; }
Then, during the build process, I swap the BUILD_TIME variable for the actual build time, calculated as
.gist table { margin-bottom: 0; }
Doing this ensures I can refresh the cache when I roll out new HTML, CSS, or JavaScript tweaks.
Of course now that I had a Service Worker in play, I needed to revisit some of my own caching approaches using the Web Storage API. I was good with the lazy loaded hero SVG remaining cached in localStorage. The improved performance of pulling the markup directly from localStorage versus having to reconstruct it from a cached Ajax request made it worth keeping. Similarly, the form preservation code also made sense to keep since it didn’t tread into the Service Worker’s territory (and in fact it can’t because Service Workers run on their own thread with no access to the DOM).
Where things got complicated was my caching of the gallery pagination. As nice as that enhancement was, it was definitely doing the same job that the Service Worker could do, albeit with a different storage medium. I decided that a measured approach would be to test the browser for Service Worker support and simply bypass the sessionStorage caching if that was the case. The rest of the code could remain intact. The way I ended up handling that was using two method wrappers for getting and setting the items in sessionStorage. By default, they were bare-bones placeholders that didn’t do anything, but if the browser doesn’t have Service Worker support, they get redefined to handle the caching via sessionStorage:
.gist table { margin-bottom: 0; }
Taking this approach improves the performance of the gallery for everyone (provided, of course, they aren’t experiencing a JavaScript meltdown and are visiting the site in a browser made some time in the last seven years). It’s the best of both worlds too because it doesn’t penalize folks who use browsers that don’t support Service Worker yet.
What did we learn?
Oh my word this post was a beast. So much enhancement. So many codes. So much to think about. Since even I can’t remember everything I covered above, here’s a brief list of key takeaways:
- JavaScript is not guaranteed — While it won’t happen often, there are a ton of reasons your JavaScript may not run; make peace with that reality and plan for a fallback;
- Don’t be afraid to draw a line in the sand — Some older browsers are a pain to test and if you have a non-JavaScript experience, they can survive with that;
- You may not need a library — If you’re not doing anything truly crazy, you can probably accomplish what you need to do using standard JavaScript APIs;
- Get organized — As with my CSS approach, you don’t have to use the tools or approach I did for organizing my JavaScript, but it pays to have well-organized code;
- Default to good performance — Users on older, less-capable devices will thank you for reducing their downloads by avoiding big assets like inline images, but you can still provide those enhancements by lazy loading assets when it makes sense to do so;
- Look for easy performance wins — If you have a computationally-expensive DOM manipulation, consider caching the result in some way to speed up future page loads;
- Look for opportunities to reduce the friction in completing a task — For example, if you are confident you can predict what someone is going to type into a form, go for it, but make sure they can override your educated guess;
- Help users recover from browser and networking problems — Again, caching can be your friend;
- Get familiar with Service Worker — This powerful new spec gives you a lot of control over the speed of your site and helps you provide a decent offline experience, take advantage of that.
Where to next?
With the site pretty much coded, it was time to focus on squeezing the files into the tightest pants they could wear. I’ll discuss some of the build tools I used to do that for the HTML, CSS, and JavaScript and my colleagues Antón Molleda and David García will discuss some of their server-side strategies. Stay tuned!
― Aaron Gustafson, Web Standards Advocate


Leave a Reply