Load Balancing Applications with NGINX Plus in a CoreOS Cluster
CoreOS is a Linux OS that is designed to run applications across a cluster of machines. There can be multiple running copies of a web application (each in a separate Docker or rkt container), distributed across a cluster. For such a deployment the configuration of the load balancer needs to change frequently in reaction to changes in the cluster, including:
- A change in the number of running containers, when (for example) you scale the application up or down
- A change in the IP addresses of the containers, when (for example) one of the machines goes down due to failure or some other reason, and the affected containers get started on another machine
NGINX Plus provides an HTTP on-the-fly reconfiguration API, which lets you update the configuration of the load balancer dynamically instead of editing and reloading its configuration files.
In this blog post we show how to use NGINX Plus to load balance an application running in a CoreOS cluster. We assume that you’re familiar with Docker, CoreOS, and the tools it comes with, fleet and etcd.
NGINX Plus requires a subscription. If you don’t have one, you can sign up for a free 30-day trial.
Overview
Here is an outline of what we’ll do:
-
Create template unit files for a simple backend application. The distributed init tool for CoreOS, fleet, uses these files to start up and configure instances (which it calls units) of a service (application). Our backend application consists of two services:
- The backend service, which is multiple instances of an NGINX web server serving static pages
- The service-discovery service for the backend service; it registers all the backend units in etcd
-
Create template unit files and other elements required for load balancing our application.
- The load-balancer service, a single instance of NGINX Plus, which distributes requests among the instances of the backend service
- The service-discovery service for NGINX Plus; it updates NGINX Plus configuration when backend units are added to or removed from etcd
- An NGINX Plus configuration file
- A Docker image of NGINX Plus
- Create a cluster of four virtual machines (VMs) running CoreOS.
- Use fleet to launch the four services listed in Steps 1 and 2.
- Scale the backend application and see how the load-balanced NGINX Plus upstream group gets reconfigured.
- Bring one of the VMs down to see how NGINX Plus active health checks work.
To make it easier for you to get the cluster and services up and running, we’ve put all the required templates and configuration files in our coreos-demo repository on GitHub.
As we’ll detail later, we’re using Vagrant to create our CoreOS cluster. The advantage of Vagrant is that a single vagrant up command creates and starts up all VMs, and distributes the templates and other files to them. You can deploy your cluster in an environment other than Vagrant, but in that case you have to make sure that the files get distributed as necessary. For details, see Setting Up the Cluster.
Note: We tested the solution described in the blog post against CoreOS alpha version 949.0.0, Vagrant 1.7.4, and VirtualBox 5.0.10, all running on a OS X El Capitan machine.
About Dynamic Reconfiguration of NGINX and NGINX Plus
In addition to the on-the-fly reconfiguration API we’re using in this blog, NGINX Plus supports
DNS-based dynamic reconfiguration. You can configure NGINX Plus to periodically re-resolve DNS names for load-balanced backend servers. We chose not to use this option for this example, because it requires extra steps: setting up a DNS server and registering the backends within it.
The open source NGINX software doesn’t support these two dynamic reconfiguration options. To reconfigure NGINX, you modify and reload its configuration files. You can automate the process with tools such as confd. For an example, see How To Use Confd and Etcd to Dynamically Reconfigure Services in CoreOS at DigitalOcean.
Template Unit Files for the Services
In the following sections, we analyze the template unit files for our four services, explaining the meaning of the various instructions (options, in fleet’s terminology). The template files must reside on at least one of the VMs in the CoreOS cluster (the one where we issue fleetctl commands, as described in Starting the Services).
Template for the Backend Service
The backend service consists of multiple instances of the NGINX web server. We’re using the nginxdemos/hello Docker image, which returns a simple web page with the IP address and port of the web server, and the hostname of the container.
The template unit file for the backend service, [email protected], has the following contents. We’ll use this file to start multiple units of the service.
When fleet starts a backend unit based on this template, the ExecStart option launches a container with the nginxdemos/hello image on one of the VMs; port 8080 on the VM is mapped to port 80 on the container. The Conflicts option tells fleet not to schedule more than one unit of the backend service on the same VM.
[Unit]
Description=Backend Service
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker kill backend
ExecStartPre=-/usr/bin/docker rm backend
ExecStartPre=/usr/bin/docker pull nginxdemos/hello
ExecStart=/usr/bin/docker run --name backend -p 8080:80 nginxdemos/hello
ExecStop=/usr/bin/docker stop backend
[X-Fleet]
Conflicts=backend@*.service
Template for the Backend Service’s Service‑Discovery Service
The service‑discovery service registers units of the backend service in etcd. Its template unit file, backend‑[email protected], has the contents that appear below.
Every unit of the backend service has a corresponding unit of the service‑discovery service running on the same VM; this setup is referred to as the sidekick model. The service‑discovery unit records the IP address of the VM it’s running on in an etcd key.
The purpose of the options in the template unit file is as follows:
- The
EnvironmentFileoption imports the CoreOS environment variables from the /etc/environment file into the unit file. In our case we use theCOREOS_PRIVATE_IPV4variable to capture the VM’s private IP address. -
The
ExecStartoption specifies that the unit launches an inline shell script as it starts. In the script, thewhilecommand sets up an infinite loop. Every 100 seconds theetcdctltool sets a key in etcd, consisting of the private IP address of the CoreOS VM and port 8080, which is mapped to port 80 on the backend container running on the same VM. The key itself contains all the information we need, so we can set a random value for the key (the stringlazy-unicornin our case). Setting a key in etcd effectively registers a backend unit.The
--ttlargument sets a time-to-live (TTL) value of 120 seconds, after which the key expires. Since we set the key every 100 seconds, it expires only in abnormal circumstances, for example if the VM goes down. - The
MachineOfoption tells fleet to schedule the service‑discovery unit on the node that hosts the backend service unit with the same instance name (value of the%iunit variable). - The
BindsTooption (at the top of the file) links the two units such that the service‑discovery unit stops when the backend unit stops. - The
ExecStopoption specifies that when the units stop theetcdctlcommand is run to remove the key from etcd.
[Unit]
Description=Backend Discovery Service
BindsTo=backend@%i.service
After=backend@%i.service
[Service]
EnvironmentFile=/etc/environment
ExecStart=/bin/sh -c "while true; do etcdctl set /services/backend/${COREOS_PRIVATE_IPV4}:8080 lazy-unicorn --ttl 120; sleep 100; done"
ExecStop=/usr/bin/etcdctl rm /services/backend/${COREOS_PRIVATE_IPV4}:8080
[X-Fleet]
MachineOf=backend@%i.service
Template for the Load-Balancer Service
The unit template file that we’ll use to start a load-balancer service unit, [email protected], has the following contents.
When we start a unit based on this file, an NGINX Plus container starts up on one of the VMs, with ports 80 and 8081 on the VM mapped to the same ports on the container. The Conflicts options tell fleet not to schedule the unit on a VM where either another load-balancer unit or a backend unit is already running.
[Unit]
Description=Load Balancer Service
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker kill loadbalancer
ExecStartPre=-/usr/bin/docker rm loadbalancer
ExecStart=/usr/bin/docker run --name loadbalancer -p 80:80 -p 8081:8081 nginxplus-coreos
ExecStop=/usr/bin/docker stop loadbalancer
[X-Fleat]
Conflicts=loadbalancer@*.service
Conflicts=backend@*.service
Template for the Load-Balancer Service’s Service‑Discovery Service
To automate the addition and removal of backend servers in the upstream group being load balanced by NGINX Plus, we create a service‑discovery service for the load-balancer service. It does the following:
- At startup, gets the IP address and port number from etcd for every container running a unit of the backend service, and uses the NGINX Plus on-the-fly reconfiguration API to add the backend units to the upstream group.
- Invokes the
etcdctlexec‑watchcommand, which in turn runs an inline script every time there is a monitored change in etcd. The changes we are monitoring are the addition, deletion, or expiration of a backend key in the /services/backend etcd directory. The script uses the on-the-fly reconfiguration API to add or remove the backend corresponding to the key from the NGINX Plus upstream group.
The template unit file for the load-balancer service’s service‑discovery service, [email protected], has the contents that appear below. The purpose of the options is as follows:
- As with the service‑discovery service for the backend service, the
MachineOfoption tells fleet to schedule this unit on the node that hosts the load-balancer service unit with the same instance name (value of the%ivariable), and theBindsTooption links the two units such that the service‑discovery unit stops when the load‑balancer unit stops. - The
ExecStartPreoption executes its inline script right before theExecStartoption is invoked. This script gets the keys of all backend units from etcd. Then it runs acurlcommand for each backend unit, invoking the on-the-fly reconfiguration API to add the unit to the NGINX Plus upstream group. This way NGINX Plus is configured immediately at startup. -
The
ExecStartoption runs theetcdctlexec‑watchcommand, which invokes an inline script every time there is a change in the /services/backend directory of etcd. The change notification is passed to the script in the$ETCD_WATCH_ACTIONenvironment variable and the key is passed in the$ETCD_WATCH_KEYvariable. The action performed depends on the value of$ETCD_WATCH_ACTION:- The value
setindicates that the key was just set in etcd, so we add the backend unit corresponding to the passed-in key to the upstream group. Before adding it, we check if it is already listed in the group, because the API lets you add the same server multiple times, essentially increasing its weight in the load-balancing algorithm. (You can list a server multiple times in an upstream group in the configuration file for this reason as well, but the better way to increase a server’s weight – either in the API call or the configuration file – is to include theweightparameter on itsserverdirective.) - The value
deleteorexpiresignals the removal of the backend unit from the upstream group. To identify the unit to remove, we have to include its ID as an argument in the API call. To obtain it, we first make an API call that lists all the units and their IDs, and extract the ID of the relevant unit from the response.
- The value
[Unit]
Description=Load Balancer Discovery Service
BindsTo=loadbalancer@%i.service
After=loadbalancer@%i.service
[Service]
EnvironmentFile=/etc/environment
ExecStartPre=/bin/bash -c 'NGINX_ENDPOINT=127.0.0.1:8081;
SERVERS=$(etcdctl ls /services/backend --recursive | awk -F/ '''{print $NF}''');
for s in $SERVERS;
do
curl "$NGINX_ENDPOINT/upstream_conf?upstream=backend&add=&server=$s";
done'
ExecStart=/usr/bin/etcdctl exec-watch --recursive /services/backend -- /bin/bash -c 'NGINX_ENDPOINT=127.0.0.1:8081;
SERVER=$(echo $ETCD_WATCH_KEY | awk -F/ '''{print $NF}''');
function get_server_id () {
ID=$(curl -s "$NGINX_ENDPOINT/upstream_conf?upstream=backend" | awk -v server="$SERVER;" '''$2==server { print $4 }''');
echo $ID;
};
if [ $ETCD_WATCH_ACTION == '''set''' ];
then
echo "Adding $SERVER server";
ID=$(get_server_id);
if [ -z $ID ];
then
curl -s "$NGINX_ENDPOINT/upstream_conf?upstream=backend&add=&server=$SERVER";
fi
elif [ $ETCD_WATCH_ACTION == '''delete''' ] || [ $ETCD_WATCH_ACTION == '''expire''' ];
then
echo "Removing $SERVER server";
ID=$(get_server_id);
echo "Server has $ID";
curl -s "$NGINX_ENDPOINT/upstream_conf?upstream=backend&remove=&$ID";
fi'
ExecStop=
[X-Fleet]
MachineOf=loadbalancer@%i.service
The NGINX Plus Configuration File and Docker Image
Before we start the load-balancer service, we need to add the NGINX Plus configuration file to the Docker image of NGINX Plus that we’re building.
NGINX Plus Configuration File
The NGINX Plus configuration file, backend.conf, has the contents that appear below. We’ll place it in the /etc/nginx/conf.d folder in our NGINX Plus Docker image. By default, NGINX Plus reads in all configuration files from that folder.
The upstream directive defines a group of backend servers to be load balanced by NGINX Plus, called backend. We don’t declare any servers for now – we’ll use the on-the-fly reconfiguration API to add them.
Next we declare two virtual servers:
-
The first virtual server listens on port 80 for HTTP requests from clients.
- The
status_zonedirective enables collection of live activity monitoring data by the NGINX Plus Status module. - The
proxy_passdirective tells NGINX Plus to distribute all incoming requests (represented by the / location) among the servers in the backend upstream group. -
For health checks we create the named location @healthcheck. The
internaldirective means that regular incoming requests don’t hit this location. The separatelocationblock enables us to handle health checks differently from the regular traffic captured by the / location, even though both health checks and regular traffic are sent to the same upstream group.Specifically, we want to detect the failure of an upstream server very quickly, so we set
proxy_connect_timeoutandproxy_read_timeoutto allow only 1 second each for establishing the connection to the server and for the server to respond to a request, respectively. (The default value for both directives, 60 seconds, applies to the / location.) We also set 1 second as the interval between health checks. We use the default health check, which succeeds if the status code in the server’s response to a request for / is2xxor3xx.
- The
-
The second virtual server listens on port 8081 for administrative traffic.
- The
upstream_confdirective in the /upstream_conf location enables us to use the on-the-fly reconfiguration API on the VM. - The
statusdirective in the /status location makes live activity monitoring data available there. The built-in NGINX Plus dashboard is accessible at /status.html.
- The
upstream backend {
zone backend 64k;
}
server {
listen 80;
status_zone backend;
location / {
proxy_pass http://backend;
}
location @healthcheck {
internal;
proxy_pass http://backend;
proxy_connect_timeout 1s;
proxy_read_timeout 1s;
health_check interval=1s;
}
}
server {
listen 8081;
root /usr/share/nginx/html;
location /upstream_conf {
upstream_conf;
}
location /status {
status;
}
location = /status.html {
}
}
Dockerfile for Building the Docker Image
We’ll create a Docker image of NGINX Plus from the following Dockerfile.
FROM ubuntu:14.04
MAINTAINER NGINX Docker Maintainers "[email protected]"
# Set the debconf frontend to Noninteractive
RUN echo 'debconf debconf/frontend select Noninteractive' | debconf-set-selections
RUN apt-get update && apt-get install -y -q wget apt-transport-https
# Download certificate and key from the customer portal (https://cs.nginx.com)
# and copy to the build context
ADD nginx-repo.crt /etc/ssl/nginx/
ADD nginx-repo.key /etc/ssl/nginx/
# Get other files required for installation
RUN wget -q -O /etc/ssl/nginx/CA.crt https://cs.nginx.com/static/files/CA.crt
RUN wget -q -O - http://nginx.org/keys/nginx_signing.key | apt-key add -
RUN wget -q -O /etc/apt/apt.conf.d/90nginx https://cs.nginx.com/static/files/90nginx
RUN printf "deb https://plus-pkgs.nginx.com/ubuntu `lsb_release -cs` nginx-plusn" >/etc/apt/sources.list.d/nginx-plus.list
# Install NGINX Plus
RUN apt-get update && apt-get install -y nginx-plus
# forward request logs to Docker log collector
RUN ln -sf /dev/stdout /var/log/nginx/access.log
RUN ln -sf /dev/stderr /var/log/nginx/error.log
# copy the config files
RUN rm /etc/nginx/conf.d/*
COPY backend.conf /etc/nginx/conf.d/
EXPOSE 80 8081
CMD ["nginx", "-g", "daemon off;"]
Creating the NGINX Plus Docker Image
For complete details on how to build the NGINX Plus Docker image and run NGINX and NGINX Plus in containers, see the Deploying NGINX and NGINX Plus with Docker blog post.
In brief, the steps for creating the Docker image are:
- Place the Dockerfile, the NGINX Plus configuration file (backend.conf), and the certificate and private key for your subscription (nginx-repo.crt and nginx-repo.key) in a directory on the local machine.
-
Run the following command in that directory to build the image, naming it nginxplus-coreos:
$ docker build –t nginxplus-coreos .
The image needs to be available on all our CoreOS VMs. There are a couple ways to make that happen. We can set up a private Docker registry, or for the purpose of a quick test we can use Docker commands to load the image onto the VMs. Run the save command to save the newly built image to a file, use scp to transfer the file to all VMs, and run the load command on each VM to load the image.
Setting Up the Cluster
With the template unit files and the NGINX Plus Docker image in hand, we can set up our cluster of four VMs running CoreOS, and start our services.
We are using Vagrant to create the cluster, and recommend you do the same. The coreos-demo for this blog post includes complete instructions for setting up a cluster, along with complete code and configuration examples.
The advantage of Vagrant is that a single vagrant up command creates and starts up all VMs, and distributes the templates and other files to them as necessary. You can deploy your cluster in an environment other than Vagrant, but in that case you have to make sure that the files get distributed as necessary.
After we create the cluster, we choose one of the VMs, run ssh to connect to it, and in the new shell run the following command to check that all VMs are up:
$ fleetctl list-machines
MACHINE IP METADATA
1647c9ff... 172.17.8.101 -
23ed990b... 172.17.8.102 -
5004d92a... 172.17.8.103 -
9af60101... 172.17.8.104 - We’ll run commands on this VM for the rest of the blog post, except when we mention otherwise. When we run fleetctl start commands to start our services, we assume that template unit files are located in the current working directory.
Starting the Services
To start up the services, perform these steps on the VM you chose in Setting Up the Cluster:
-
Start three units of the backend service, allowing fleet to choose the VM on which to launch each container:
$ fleetctl start backend@1
Unit [email protected] inactive
Unit [email protected] launched on 1647c9ff.../172.17.8.101
$ fleetctl start backend@2
Unit [email protected] inactive
Unit [email protected] launched on 23ed990b.../172.17.8.102
$ fleetctl start backend@3
Unit [email protected] inactive
Unit [email protected] launched on 5004d92a.../172.17.8.103 -
Check that all units are running:
$ fleetctl list-units
UNIT MACHINE ACTIVE SUB
[email protected] 1647c9ff.../172.17.8.101 active running
[email protected] 23ed990b.../172.17.8.102 active running
[email protected] 5004d92a.../172.17.8.103 active running -
Start the service-discovery units for the backend application:
$ fleetctl start backend-discovery@1
Unit [email protected] inactive
Unit [email protected] launched on 1647c9ff.../172.17.8.101
$ fleetctl start backend-discovery@2
Unit [email protected] inactive
Unit [email protected] launched on 23ed990b.../172.17.8.102
$ fleetctl start backend-discovery@3
Unit [email protected] inactive
Unit [email protected] launched on 5004d92a.../172.17.8.103 -
Verify that each service-discovery unit has registered its corresponding backend unit in etcd:
$ etcdctl ls /services/backend
/services/backend/172.17.8.102:8080
/services/backend/172.17.8.103:8080
/services/backend/172.17.8.101:8080The output confirms that three keys were created in the /services/backend directory of etcd.
-
Start the load-balancer unit:
$ fleetctl start loadbalancer@1
Unit [email protected] inactive
Unit [email protected] launched on 9af60101.../172.17.8.104The load balancer starts on the fourth VM, with IP address 172.17.8.104, because the
Conflictsoption in the load-balancer template unit file tells fleet not to start it on a VM where a unit of the backend service is already running. -
Check that NGINX Plus is running on the fourth VM:
$ curl 172.17.8.104
<html>
<head><title>502 Bad Gateway</title></head>
<body bgcolor="white">
<center><h1>502 Bad Gateway</h1></center>
<hr><center>nginx/1.9.9</center>
</body>
</html>As expected, the response is
502BadGateway, which confirms that NGINX Plus is running but can’t return any content because we haven’t added any backend servers to the upstream group yet. -
Start the service-discovery service for the load-balancer service:
$ fleetctl start loadbalancer-discovery@1
Unit [email protected] inactive on 9af60101.../172.17.8.104
Unit [email protected] launched on 9af60101.../172.17.8.104The service-discovery service starts on the same VM as the load-balancer service, as specified by the
MachineOfoption in its template file.
As we described in Template for the Load-Balancer Service’s Service‑Discovery Service, this service‑discovery service automatically detects changes in the set of etcd keys, which correspond to backend units. It uses the NGINX Plus on-the-fly reconfiguration API to add the backend units to the upstream group being load balanced by NGINX Plus. In this case, it discovers and adds the three backend units we started in Step 1.
We repeat Step 6 and fetch a web page from the VM where the load-balancer unit is running. This time the request is passed to one of the backend units and its webpage is returned:
$ curl 172.17.8.104
<!DOCTYPE html>
<html>
<head>
<title>Hello from NGINX!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Hello!</h1>
<h2>My hostname is abcf317089f2</h2>
<h2>My address is 10.1.99.2:80</h2>
</body>
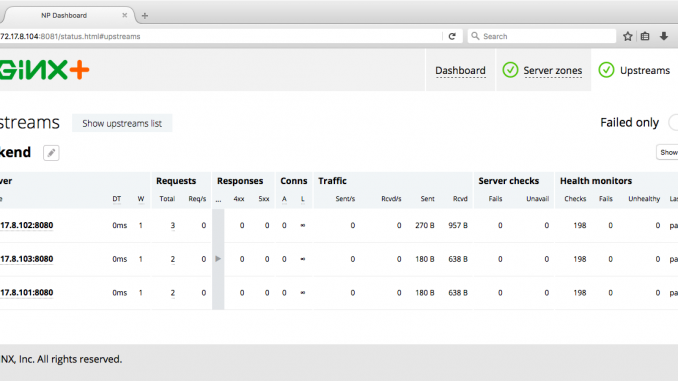
</html>Another way to confirm that NGINX Plus is load balancing three backend units is to open the live activity monitoring dashboard on the VM where the load-balancer unit is running; in our case the URL is http://172.17.8.104:8081/status.html. When we click on the Upstreams tab, we see three servers in the backend upstream group.
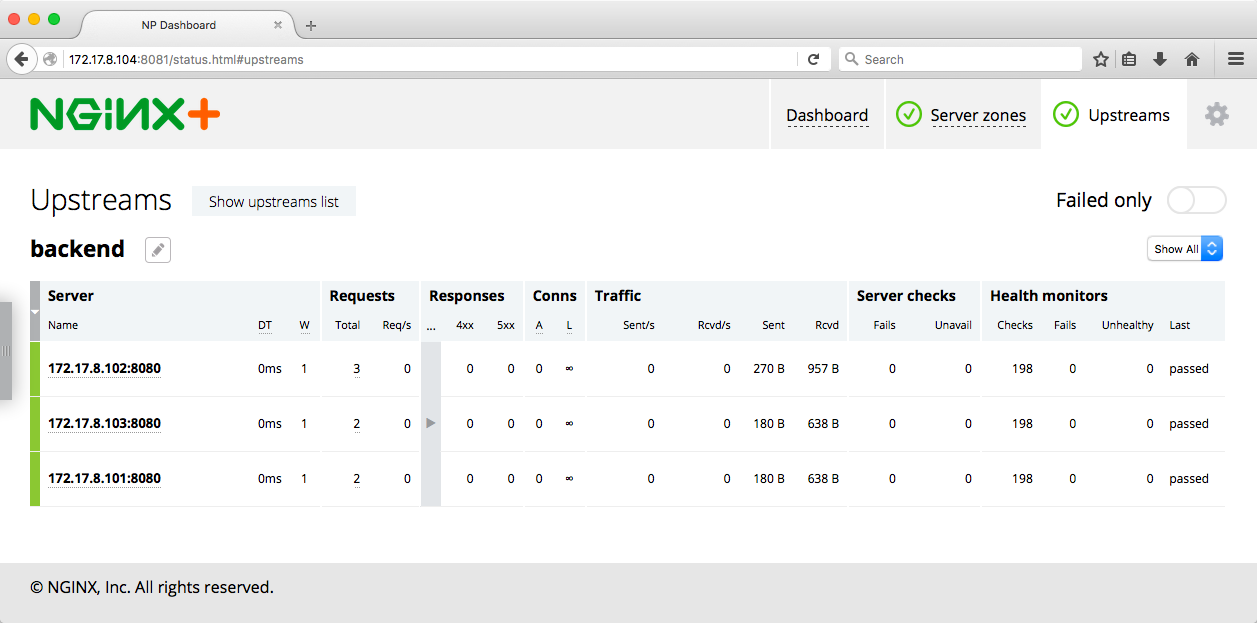
Scaling the Web Application
Now let’s see how quickly the load balancer gets reconfigured after we destroy or start a backend unit, effectively scaling our application up or down.
First we destroy one of the backend units:
$ fleetctl destroy backend@1
Destroyed [email protected]Returning to the dashboard, we now see only two servers in the backend upstream group.
To start the backend unit again, we run the fleetctl start backend@1 command, and again see three servers in the Upstreams tab on the dashboard.
Using Active Health Checks to Detect Outages
Let’s see how health checks quickly exclude a faulty server from the load-balanced group. We bring one of the VMs down, simulating an outage, and observe how the unit that was running on the failed VM gets rescheduled on a healthy one.
First let’s bring the number of running backend units down to two by destroying the third unit and its service‑discovery unit:
$ fleetctl destroy backend@3 && fleetctl destroy backend-discovery@3
Destroyed [email protected]
Destroyed [email protected]Now we bring down VM number 2 in our cluster, where the backend@2 unit is running. To do that we suspend the VM. The method for suspending a VM or machine depends on the environment in which you’re running your CoreOS cluster, but in our Vagrant environment we run the following command from the host VM:
$ vagrant suspend core-02
The dashboard shows that the backend server on VM number 2 is marked failed in red now, meaning that NGINX Plus has marked it unhealthy as a result of a failed health check and is not passing requests to it.
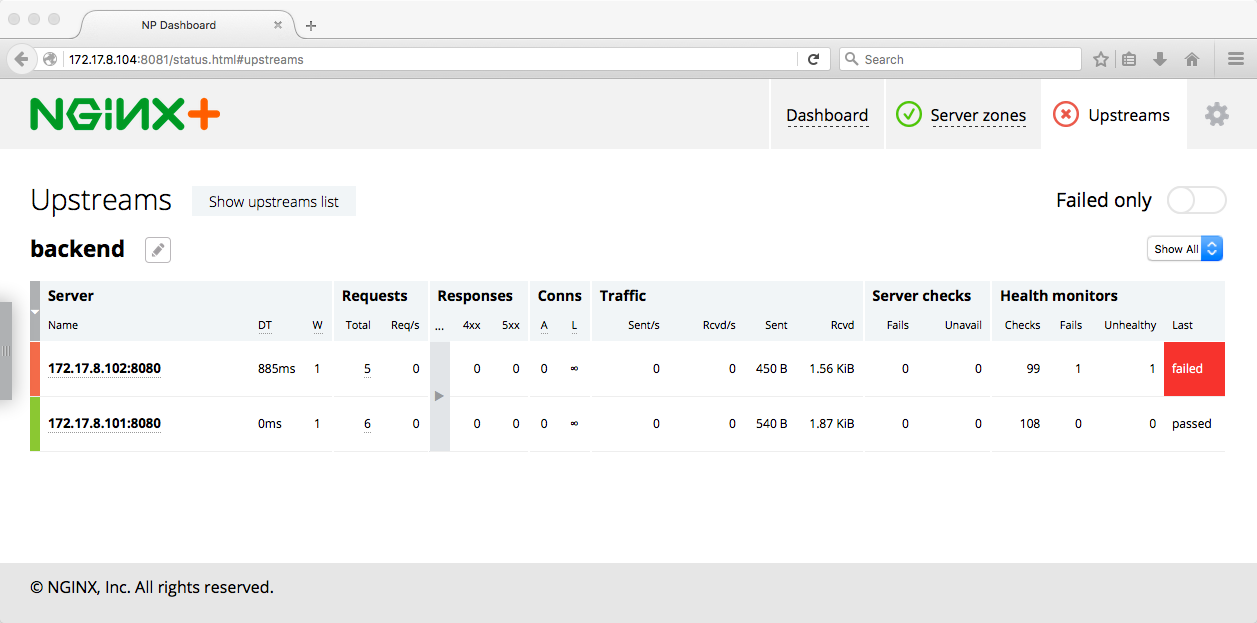
If we wait about 2 minutes (the TTL for etcd keys specified in the Template for the Backend Service’s Service‑Discovery Service), the key expires and the server is removed from the upstream group. Soon after we’ll see a newly launched backend unit when fleet reschedules the unit from the failed VM on a healthy VM.
Summary
The on-the-fly reconfiguration API lets you easily integrate NGINX Plus with any service discovery mechanism, minimizing the need to change and reload configuration files, and enabling NGINX Plus to react quickly to changes in the environment. With health checks you quickly detect a failed server and stop passing requests to it. Live activity monitoring provides you with complete information about the state of NGINX Plus.
Try out automated reconfiguration of NGINX Plus upstream groups using etcd in a CoreOS cluster for yourself:
- Download the coreos-demo from our GitHub repository
- Start a free 30-day trial of NGINX Plus today or contact us for a live demo
The post Load Balancing Applications with NGINX Plus in a CoreOS Cluster appeared first on NGINX.
Source: Load Balancing Applications with NGINX Plus in a CoreOS Cluster


Leave a Reply