MySQL에서 다운타임 거의 없이 DynamoDB로 마이그레이션하기
많은 고객들이 MySQL 과 같은 관계형 데이터베이스에서 Amazon DynamoDB으로 마이그레이션 하고자 합니다. 왜냐하면, 완전 관리형, 고성능, 높은 확장성과 유연성을 갖춘 NoSQL 데이터베이스 서비스이기 때문입니다. DynamoDB의 경우, 트래픽 및 비즈니스 요구 사항에 따라 용량을 유연하게 증가 및 감소시킬 수 있기 때문에 서비스에 필요한 총 비용을 기존의 서버 기반의 RDBMS보다 더 쉽게 최적화 하는 것이 가능합니다.
하지만, 마이그레이션 작업은 통상적으로 다음과 같은 두 가지 이슈가 있을 수 있습니다:
- 고객서비스가 반드시 24/7/365 가용 해야 할 경우 다운타임으로 인한 서비스 중단을 어떻게 최소화할 것인가?
- RDBMS와 DynamoDB의 서로 다른 Key Design을 어떻게 반영할 것인가?
이 글에서는 다운타임을 최소화하면서 MySQL의 주요 DB 디자인을 NoSQL에 적합한 형태로 변환한 후, MySQL의 기존 데이터를 DynamoDB로 원활하게 마이그레이션하는 두 가지 방법을 소개합니다.
마이그레이션을 위한 AWS 서비스 빌딩 블록
이 글에서 포함된 예제 코드들은 다음 AWS 서비스을 사용합니다:
- AWS 데이터 마이그레이션 서비스(AWS DMS) 는 가장 범용적으로 사용되는 상용 및 오픈소스 데이터베이스 사이의 데이터 마이그레이션을 가능하게 해줍니다. AWS DMS는 서로 다른 데이터베이스 플랫폼 간의 동종 및 이종 데이터 마이그레이션을 지원합니다.
- Amazon EMR은 방대한 양의 데이터를 신속하게 처리할 수 있도록 하는 관리형 Hadoop 프레임워크입니다. Hive 및 다른 비지니스 소프트웨어를 포함하는 이미 설정된 소프트웨어 스택들로 구성된 EMR 클러스터를 손쉽게 구축할 수 있습니다.
- Amazon Kinesis는 실시간 트랜잭션, 로그 데이터, 클릭 스트림과 같은 방대한 양의 실시간 데이터를 최대 7일까지 지속적으로 저장하고 유지할 수 있습니다.
- AWS Lambda는 서버를 준비하거나 운영하지 않고, 원하는 코드를 클라우드 상에서 직접 실행할 수 있도록 해 줍니다. AWS Lambda에서 실행되는 코드는 Amazon Kinesis Stream과 같은 다른 AWS 서비스들에 의해 자동으로 호출되도록 설정할 수 있습니다.
마이그레이션 방안
이 글에서는 다음 두가지 데이터 마이그레이션 옵션을 설명합니다.
- AWS DMS 사용: AWS DMS는 DynamoDB 테이블을 타겟으로 마이그레이션을 지원합니다. 객체 매핑을 사용하여 마이그레이션 과정 중에 원본 데이터를 DynamoDB에서 요구하는 데이터 구조에 적합하게 재구성하는 것이 가능합니다.
- Amazon EMR, Kinesis 및 AWS Lambda 커스텀 스크립트 사용: 보다 복잡한 변환 과정 및 유연성이 요구될 때는 EMR, Kinesis, Lambda를 이용한 마이그레이션을 고려할 수 있습니다. MySQL 레코드를 더 적은 DynamoDB 항목으로 그룹화하고, 속성 이름을 동적으로 결정하고, 마이그레이션 중에 프로그래밍 방식으로 비즈니스 로직을 추가하고, 더 많은 데이터 유형을 지원하거나 하나의 큰 테이블에 대해 병렬 제어를 추가하려면 세분화된 사용자 제어가 필요합니다.
데이터 초기 적재 및 벌크 입력을 완료한 후에 가장 최근의 실시간 데이터를 CDC(Change Data Capture)로 처리하고 나면 최종적으로 애플리케이션이 DynamoDB를 바라보도록 설정을 변경하게 됩니다.
이 접근방법에서 변경데이터를 캡처하는 방법에 대한 상세한 내용은 AWS 데이터베이스 블로그 포스팅의 Streaming Changes in a Database with Amazon Kinesis에서 다루고 있습니다. 이 블로그 포스팅에서 사용한 모든 코드 및 테스트 코드는 big-data-blog GitHub 저장소를 통해 얻을 수 있습니다.
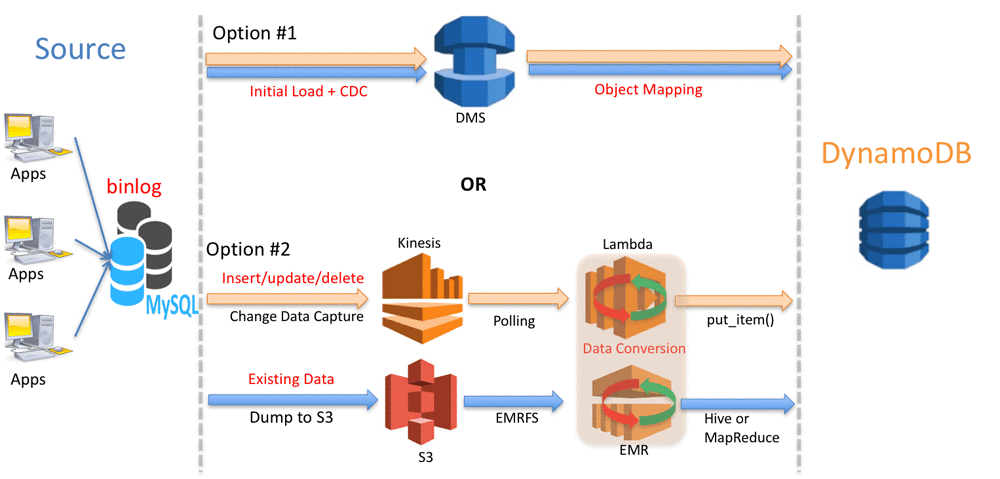
마이그레이션 솔루션 아키텍쳐
두 접근 방법의 전반적인 아키텍처는 다음과 같습니다.

방안 1: AWS DMS 사용
이 절에서는 DMS를 이용하여 어떻게 MySQL 데이터베이스에 접속하고, 원본 데이터를 읽고, 데이터를 대상 DynamoDB 데이터베이스에 적재하기 위해 데이터를 정형화하는지에 대해 설명합니다.
1. 복제 인스턴스 생성 및 원본 및 대상 엔드포인트 설정하기
AWS Database Migration Service Best Practices를 참고하여 마이그레이션을 수행하기에 충분한 저장소와 처리능력을 갖춘 복제 인스턴스를 생성합니다. 예를 들어, 마이그레이션 대상 테이블이 많거나 동시에 여러 복제 작업을 수행할 계획이라면 더 큰 크기의 인스턴스들을 사용하는 것을 고려하여야 합니다. 데이터 복제 서비스는 상당한 양의 메모리와 CPU 리소스를 사용합니다.
MySQL 사용자 정보를 사용하여 MySQL에 접속하고 SUPER, REPLICATION CLIENT 권한으로 데이터를 추출합니다. MySQL 설정에서 Binary log를 활성화하고 CDC를 위해 binlog_format 파라미터를 ROW로 설정합니다. DMS를 사용하는 방법에 대한 더 상세한 정보는 AWS Database Migration Service 사용자 가이드의 Getting Started 문서를 참조합니다.
DMS에서 DynamoDB 데이터베이스를 대상으로 설정하기 전에, DMS가 사용할 IAM Role을 생성하고 DynamoDB 대상 테이블에 접근할 권한을 부여해야 합니다. 원본 및 대상 데이터베이스에 접근할 엔드포인트들도 다음 스크린샷과 같이 설정합니다.

다음 스크린샷은 source-mysql의 상세 정보 화면입니다.

객체 매핑 규칙 설정 및 작업 생성하기
다음 예제에서는, MySQL 테이블이 복합 프라이머리 키( customer id + ordered + productid )를 가지고 있다고 가정합니다. 이와 같은 경우, 객체 매핑 규칙을 사용하여 DynamoDB에서 요구하는 데이터 구조에 적합하게 키를 재구성할 수 있습니다.
여기에서는 대상 DynamoDB 테이블은 customer id와 order id 컬럼의 조합을 hash key로 설정하고 product id 컬럼을 sort key로 설정합니다. 하지만, 실제 마이그레이션 상황에서는 데이터 적재 및 접근 패턴에 따라 파티션 키를 결정해야 합니다. 보통 카디널리티가 높은 속성을 파티션키로 사용하게 됩니다. DynamoDB에서 올바른 파티션 키를 결정하는 방법에 대한 상세한 내용은 Choosing the Right DynamoDB Partition Key 블로그를 참조하십시오.
여기서 rule-action을 map-record-to-record로 설정하였고 해당 컬럼을 제외 대상 컬럼(exclude-columns) 속성 리스트에 포함시키지 않았기 때문에, DMS 서비스는 원본 데이터의 quantity 컬럼을 대상 DynamoDB 테이블에 자동으로 생성합니다. map-record-to-record 및 map-record-to-document 설정에 대한 상세 내용은 AWS Database Migration Service에서 Amazon DynamoDB 데이터베이스를 대상으로 사용 문서를 참조하십시오.

마이그레이션은 작업 생성시 Start task on create 옵션을 해제하지 않을 경우, 작업이 생성되는 즉시 시작됩니다. 마이그레이션 작업이 백그라운드에서 수행되는 동안 어떤 일이 발생하는지 확인하기 위하여 enabling logging을 선택하는 것을 추천합니다.
다음 스크린샷은 작업 생성 페이지를 보여줍니다.

콘솔에서 마이그레이션 개별 데이터베이스 테이블과 마이그레이션에 필요한 변환을 포함한 스키마를 지정할 수 있습니다. Guided 탭의 Where 항목에서 스키마, 테이블을 설정하고 Action 항목에서 포함/불포함 여부를 설정합니다. Filter 항목에서 테이블 내의 컬럼명 및 적용할 조건을 설정합니다.
테이블 매핑 정보는 JSON 형태로 생성할 수도 있습니다. JSON 탭에서 Enable JSON editing 체크박스를 선택하십시오.
다음은 원본데이터가 대상 테이블의 어디에 위치할지 결정하는 객체 매핑 규칙에 대한 예제입니다. 아래 예제를 복사하여 사용할 경우, 아래 속성들을 실제 사용하는 값으로 변경해야 합니다. 보다 많은 예제들은 AWS Database Migration Service에서 Amazon DynamoDB 데이터베이스를 대상으로 사용 문서를 참조하십시오.
- schema-name
- table-name
- target-table-name
- mapping-parameters
- attribute-mappings
마이그레이션 작업 시작하기
만약 target-table-name 속성에 정의된 대상 테이블이 DynamoDB에 존재하지 않을 경우, DMS는 데이터 변환 참조와 추가 주제를 포함하는 AWS Database Migration Service 참조 문서에서 설명하는 원본 데이터 형식 및 대상 데이터 형식에 대한 데이터형 변환 규칙에 따라 테이블을 생성합니다. 마이그레이션 작업의 진행상황을 모니터링하는 많은 지표들이 제공됩니다. 보다 상세한 모니터링 관련 정보는 AWS Database Migration Service 작업 모니터링 문서에서 확인하실 수 있습니다.

다음 스크린샷은 CloudWatch Logs에 기록된 이벤트들과 오류 샘플입니다.

마이그레이션에 사용한 DMS 복제 인스턴스들은 모든 마이그레이션 작업이 완료된 후에는 삭제되어야 합니다. 보유기간이 경과한 Cloudwatch log들은 자동으로 삭제됩니다.
방안 2: EMR, Amazon Kinesis, Lambda 사용
이 절에서는 보다 정교한 제어와 유연성을 제공하기 위하여 EMR과 Amazon Kinesis, Lamdba를 사용하는 다른 방안에 대해 다룹니다. 만약 작업환경에 MySQL replica가 포함된다면, replica로부터 데이터를 마이그레이션하는 것을 추천합니다.
키 디자인 변경하기
데이터베이스를 RDBMS에서 NoSQL로 변경하기로 결정했다면, 성능 및 비용 효율성을 위해서 데이터 키를 NoSQL에 더 적합하도록 설계할 필요가 있습니다.

방안 #2에서는 방안 #1과 비슷하게 MySQL 데이터베이스 원본이 복합 프라이머리 키 (customerid + orderid + productid)를 가지고 있다고 가정합니다. 하지만, 여기서는 MySQL 레코드들을 customerid(hash key)와 orderid(sort key)를 사용하여 더 적은 DynamoDB 아이템들로 그룹화합니다. 이를 위하여, MySQL의 복합키 중 마지막 컬럼 (productid)을 복합키에서 제거하는 대신 DynamoDB의 속성 이름으로 하고, Quantity 컬럼을 해당 속성의 값으로 변환합니다.
이런 변환법을 통해 전체 아이템의 수를 줄일 수 있으며, 같은 양의 정보를 더 적은 RCU(Read Capacity Unit)을 사용하여 조회할 수 있어 비용을 절감하면서 더 나은 성능을 얻을 수 있습니다. RCU/WCU(Read Capacity Unit/Write Capacity Unit)를 어떻게 계산하는지에 대한 더 상세한 정보는 프로비저닝된 처리량 문서를 확인하시기 바랍니다.
단계별 마이그레이션
방안 #2는 다음 두 단계의 마이그레이션이 동시에 진행됩니다.:
- 일괄 처리: MySQL 데이터 export, export파일의 S3 업로드, S3 데이터 DynamoDB에 import
- 실시간 처리: MySQL의 변경 데이터 캡처, insert/update/delete 트랜잭션을 Kinesis Stream에 송신, DynamoDB에 데이터를 입력하기 위한 Lambda 함수 호출.
데이터의 일관성과 무결성을 유지하기 위해 데이터를 캡처하고 Amazon Kinesis Stream에 밀어넣는 작업은 일괄 처리 프로세스 전에 시작되어야 하고, EMR에서 처리되는 일괄처리 프로세스가 종료되기 전까지 Lambda 함수는 실행되지 않고 캡처된 데이터가 스트림에 유지되어야 합니다. 다음 순서와 같이 진행됩니다.:
- Amazon Kinesis Stream에 대해 데이터 실시간 처리를 시작합니다.
- 실시간 처리 프로세스가 시작되자마자, 일괄 처리 프로세스를 시작합니다.
- 일괄 처리 프로세스가 완료되면 Amazon Kinesis Stream으로 부터 데이터를 추출하여 DynamoDB에 put_item 함수를 실행하는 Lambda 함수를 호출합니다.
- 애플리케이션의 엔드포인트를 MySQL에서 DynamoDB를 바라보도록 설정을 변경합니다.
단계 1: 변경데이터캡처및 Amazon Kinesis Streams에밀어넣기
먼저, MySQL으로부터 트렌젝션 데이터를 캡처할 Amazon Kinesis Stream을 생성합니다. Data retention period 값을 일괄 처리 프로세스의 예상 처리시간에 맞춰 설정합니다. 데이터 무결성을 위해서는 데이터 보관 기간을 일괄 처리 프로세스가 실행되는 기간 동안 발생하는 모든 트랜잭션을 보관하기 충분할 정도로 길게 설정해야 하지만, 보관 기간을 반드시 최대값으로 설정할 필요는 없습니다. 마이그레이션 대상 데이터의 양에 따라 설정합니다.
MySQL 설정에서, BinLogStreamReader 모듈이 트랜잭션 데이터를 캡처할수 있도록 binlog_format 설정값을 ROW로 설정합니다. Binlog를 활성화하려면 log_bin 매개변수도 설정되어야 합니다. 더 상세한 내용은 AWS 데이터베이스 블로그의 Streaming Changes in a Database with Amazon Kinesis 포스트를 참조하시기 바랍니다.
다음 예제 코드는 트랜잭션 데이터를 캡처하여 Amazon Kinesis Stream으로 밀어넣는 Python 예제 코드입니다.
다음 코드는 위 Python 스크립트에 의해 생성된 JSON 데이터 예제입니다. 각 트랜잭션은 JSON 데이터에 다음과 같은 type 속성으로 기록됩니다:
- WriteRowsEvent = INSERT
- UpdateRowsEvent = UPDATE
- DeleteRowsEvent = DELETE
단계 2. MySQL에서 DynamoDB로 데이터 덤프하기
DMS를 사용하는 가장 손쉬운 방법 중 하나는, 최근 추가된 Amazon S3를 마이그레이션 대상으로 사용하는 것입니다. S3를 대상으로 할 경우, full load 및 CDC 데이터가 CSV 형식으로 저장됩니다. 그러나, CDC의 경우에는 UPDATE 및 DELETE 문의 지원되지 않아 마이그레이션에 적합하지 않습니다. 보다 상세한 내용은 AWS Database Migration Service에서 Amazon S3를 대상으로 사용 문서를 참조하십시오.
Amazon S3로 데이터를 업로드하는 다른 방법은 스크립트에서 INTO OUTFILE SQL 절과 aws s3 sync CLI 명령어를 병렬로 사용하는 것입니다. 병렬 처리 수준은 서버 용량 및 로컬 네트워크 대역폭에 따라 달라집니다. pt-archiver( Percona Toolkit 에 포함된 도구입니다. 상세 내용은 appendix를 참조하십시오. )와 같은 3rd party 도구도 유용하게 사용할 수 있습니다.
여기에서 다루는 사용사례의 경우 aws s3 sync 명령어를 추천합니다. 이 명령어는 내부적으로 S3 multipart 업로드기능을 사용하여 동작하고 패턴 매칭을 통해 특정파일을 포함하거나 제외시킬 수 있습니다. 또한, sync 명령어는 로컬 버전과 S3 버전 간에 파일 크기와 수정시간을 비교하여 서로 다른 경우에만 동기화를 수행하기 때문에 동기화 프로세스가 처리 도중에 중단되더라도 동일한 파일을 다시 업로드할 필요가 없습니다. 더 상세한 내용은 AWS CLI 명령어 참조문서의 sync command를 참고하시기 바랍니다.
모든 데이터가 S3로 업로드된 후, 데이터를 DynamoDB에 밀어넣기 위해서는 다음과 같은 두가지 방법이 있습니다.:
- 외부 테이블을 이용하여 Hive사용
- MapReduce 코드 작성
외부 테이블을 이용하여 Hive 사용
S3의 데이터에 대해서 Hive 외부테이블을 생성하고 org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler 속성을 사용하여 생성한 DynamoDB 테이블을 대상으로 하는 다른 외부 테이블에 S3와 연결된 외부 테이블의 내용을 밀어넣습니다. 더 나은 생산성과 확장성을 위해 Hive용 UDF 모음인 Brickhouse를 사용하는 것을 고려해 볼 수 있습니다.
다음 샘플 코드는 DynamoDB용 Hive 테이블이 ARRAY<STRING> 타입의 products 컬럼으로 생성되었다고 가정합니다. Productid 및 quantity 컬럼은 customerid와 orderid별로 그룹화되어 Brickhouse에서 제공하는 CollectUDAF 컬럼을 사용하여 products 컬럼에 삽입됩니다.
불행히도 DynamoDBStorageHandler클래스는 MAP, LIST, BOOLEAN 및 NULL 데이터형을 지원하지 않기 때문에 ARRAY<STRING> 데이터형을 선택하였습니다. Hive의 ARRAY<STRING> 형식의 products 컬럼은 DynamoDB의 StringSet데이터형 속성으로 변환됩니다. 샘플코드는 Brickhouse가 어떤 식으로 동작하는지, 어떻게 원하는 복수의 레코드들을 골라 DynamoDB의 하나의 StringSet 데이터형 속성으로 병합할 수 있는지 보여줍니다.
Hadoop Streaming으로 Python MarReduce 코드 작성하기
맵퍼 작업은 S3의 입력데이터로부터 각 레코드를 읽고 입력 키-값 쌍을 중간 키-값 쌍으로 매핑합니다. S3의 원본 데이터를 탭 문자(“t)로 구분된 키 부분과 값 부분의 두 부분으로 나눕니다. 맵퍼 데이터는 중간 키(customerid 및 orderid) 값으로 정렬되어 reducer로 전송됩니다. reducer단계에서 각 레코드들이 DynamoDB에 저장합니다.
일반적으로 reduce 작업은 매핑( 키 / 값 목록의 쌍 ) 프로세스가 생성한 결과값을 수신한 뒤 각 키에 대해 값의 목록에 대한 작업을 수행합니다.
여기서는 reducer를 STDIN/STDOUT/Hadoop streaming을 기반으로 하여 Python으로 작성하였습니다. 문제는 이와 같은 경우 열거형 데이터 형식을 사용할 수 없다는 것입니다. 이와 같은 경우 reducer를 매퍼의 중간 키값 – 이 경우, customerid와 oerderid(cols[0],cols[1]) -으로 정렬된 데이터를 수신하고 모든 속성을 item_data dictionary의 특정 키로 저장합니다. Item_data dictionary의 속성들은 sys.stdin에서 새 중간 키가 들어올 대마다 DynamoDB에 입력되거나 플러싱됩니다.
MapReduce 작업을 실행하려면 EMR 마스터 노드에 접속하여 Hadoop 스트리밍 작업을 실행하십시오. hadoop-streaming.jar 파일 위치 및 파일 이름은 EMR 버전에 따라 다를 수 있습니다. reducer가 실행되는 동안 발생하는 exception 메시지들은 -output 옵션으로 지정한 디렉토리에 저장됩니다. 예외 또는 오류의 원인이되는 데이터를 식별하기 위해 해시 키 및 범위 키 값들도 기록됩니다.
위 스크립트와 자체 생성한 테스트 데이터를 사용하여 수행한 마이그레이션 테스트에서 데이터베이스 크기 및 데이터 마이그레이션을 완료하기까지 걸린 시간은 다음과 같습니다.
| Server | MySQL instance | m4.2xlarge |
| EMR cluster | master : 1 x m3.xlarge
core : 2 x m4.4xlarge |
|
| DynamoDB | 2000 write capacity unit | |
| Data | Number of records | 1,000,000,000 |
| Database file size (.ibc) | 100.6 GB | |
| CSV files size | 37 GB | |
| Performance (time) | Export to CSV | 6 min 10 sec |
| Upload to S3 (sync) | 3 min 30 sec | |
| Import to DynamoDB | depending on write capacity unit |
다음 스크린샷은 마이그레이션 작업 도중 write capacity 사용 결과를 보여줍니다.

성능 결과는 사용한 서버 용량과 네트워크 대역폭, 병렬 처리 수준, 변환 로직, 사용 프로그램 언어 및 기타 조건에 달라질 수 있습니다. 이 경우 프로비저닝된 write capacity unit이 모두 데이터 import를 위해 사용한 MapReduce 작업에 의해 소비되었으므로, EMR 클러스터의 크기 및 DynamoDB 테이블의 write capacity unit을 늘릴 수록 데이터 이전작업 완료에 걸리는 시간을 단축할 수 있습니다. Jave 기반 MapReduce 코드를 사용할 경우 MapReduce 프레임워크 사용 및 함수 작성시 보다 많은 유연성을 제공합니다.
단계 3: Amazon Lambda 함수를 사용하여 Amazon Kinesis로부터 데이터를 읽고 DynamoDB에 업데이트하기
AWS Lambda 콘솔에서 Create a Lambda function 및 kinesis-process-record-python blueprint를 선택합니다. 다음 버튼을 클릭하고 Configure triggers 페이지에서 생성한 Kinesis stream을 선택합니다.

생성한 Lambda 함수가 Amazon Kinesis 스트림을 읽고 데이터를 DynamoDB에 쓸 수 있도록 해당 권한을 가진 IAM role을 설정하여야 합니다.

Lambda 함수는 각 레코드의 type 속성을 확인하여 트랜잭션 유형을 식별합니다. 트랜잭션 유형에 따라 변환 및 업데이트 방법이 결정됩니다.
예를 들어 JSON 레코드가 함수에 전달되면 함수는 type 속성을 확인하고 DynamoDB 테이블에 들어온 레코드와 동일한 키를 가진 아이템이 이미 존재하는지 확인합니다. 만약 동일한 키를 가진 아이템이 이미 있다면 기존 아이템을 조회하여 dictionary 변수 (다음 코드에서는 item 변수)에 저장하고 DynamoDB 테이블에 저장하기 전에 dictionary 변수에 저장된 기존 아이템 정보에 새로 전달된 정보를 반영하여 저장합니다. 이렇게 해서 들어오는 레코드가 기존 항목을 덮어 쓰지 않도록 합니다.
단계 4: 애플리케이션 엔드포인트를 MySQL에서 DynamoDB로 변경하기
애플리케이션이 MySQL 대신 DynamoDB를 데이터베이스로 사용하려면 애플리케이션 코드를 리팩토링해야 합니다. 애플리케이션의 데이터베이스 액세스에 대한 모든 경우를 여기에서 다루기는 어렵기 때문에, 여기서는 다음의 간단한 자바 코드로 데이터베이스 연결 및 쿼리 부분이 어떻게 바뀌어야 하는지 확인해 보겠습니다. 더 자세한 내용에 대해서는 DynamoDB 및 AWS SDK를 사용한 프로그래밍 문서를 참조하시기 바랍니다.
MySQL 쿼리 코드 예제
다음 샘플 코드는 MySQL 데이터베이스에 연결하고 데이터를 조회하는 일반적인 방법을 보여줍니다.
DynamoDB 쿼리 코드 예제
DynamoDB에서 데이터를 조회하려면 다음 단계를 따르면 됩니다:
- AmazonDynamoDBClient 및 ProfileCredentialProvider를 이용하여 DynamoDB 클래스의 인스턴스 생성
- DynamoDB 클래스 인스턴스의 getTable method를 사용하여 대상 Table 클래스 인스턴스 획득
- withHashKey및 withRangeKeyCondition method를 사용하여 QuerySpec 클래스 인스턴스 생성
- QuerySpec 클래스 인스턴스를 사용하여 Table 클래스 인스턴스의 query method를 실행. 결과값이 JSON 형식으로 반환되므로, 결과값에 대하여 특정 속성 값을 확인하기 위하여 getJSON method 사용
맺음말
이 글에서는 MySQL에서 DynamoDB로 데이터를 원활하게 마이그레이션하고 마이그레이션 중 중단 시간을 최소화하기 위한 두 가지 방안을 소개했습니다. 방안 #1에서는 DMS를 사용하였고, 방안 #2에서는 EMR, Amazon Kinesis 및 Lambda를 복합적으로 사용하였습니다. 또한 각 데이터베이스의 특성에 따라 키 디자인을 변환하여 읽기 및 쓰기 성능을 개선하고 비용을 절감하는 방법도 설명했습니다. 각 방안은 서로 장단점이 있으므로 비즈니스 요구 사항에 따라 어떤 접근방법을 취할지 고려할 필요가 있습니다.
여기에서 사용한 예제 코드들은 다양한 환경에서 완벽하고 효율적이며 신뢰할 수 있는 데이터 마이그레이션 용으로 재사용되기에 충분한 수준이 아닙니다. 데이터 마이그레이션을 시작하기 전에 참조용으로 사용하시고 실제 마이그레이션에서는 신뢰할 수 있는 마이그레이션을 수행할 수 있도록 모든 요소들을 충분히 고려하여 작성되어야 합니다.
이 글이 여러분의 데이터베이스 마이그레이션을 계획 및 구현하고 서비스 중단을 최소화하는데 도움이 되기를 바랍니다.
Appendix
Percona Toolkit 설치법:
# Install Percona Toolkit
$ wget https://www.percona.com/downloads/percona-toolkit/3.0.2/binary/redhat/6/x86_64/percona-toolkit-3.0.2-1.el6.x86_64.rpm
$ yum install perl-IO-Socket-SSL
$ yum install perl-TermReadKey
$ rpm -Uvh percona-toolkit-3.0.2-1.el6.x86_64.rpmPt-archiver 실행 예제:
# run pt-archiver
$ pt-archiver –source h=localhost,D=blog,t=purchase –file ‘/data/export/%Y-%m-%d-%D.%t’ –where “1=1” –limit 10000 –commit-each 이 글은 AWS 빅데이터 서비스의 기술 지원 엔지니어인 이용성님이 작성하신 글 Near Zero Downtime Migration from MySQL to DynamoDB을 AWS 솔루션즈 아키텍트인 김병수님이 번역해 주셨습니다.
이 글은 AWS 빅데이터 서비스의 기술 지원 엔지니어인 이용성님이 작성하신 글 Near Zero Downtime Migration from MySQL to DynamoDB을 AWS 솔루션즈 아키텍트인 김병수님이 번역해 주셨습니다.


Leave a Reply