NumPy와 C++ Extensions의 성능 비교
파이썬은 놀라운 생산성을 발휘하는 언어입니다. 하지만 성능 문제는 늘 발목을 잡게 합니다. 이 문제를 극복하는 방법으로 일반적으로 C Extension을 작성하는 방법이 권장되며, 여기서는 표준 편차를 구하는 함수를 작성하여 순수 파이썬의 성능과 NumPy, 각종 C++ Extensions의 성능을 비교해 보도록 합니다.
Python
표준 편차를 구하는 파이썬 코드는 아래와 같이 작성할 수 있습니다.
def mean(lst):
return sum(lst) / len(lst)
def standard_deviation(lst):
m = mean(lst)
variance = sum([(value - m) ** 2 for value in lst])
return math.sqrt(variance / len(lst))
NumPy
NumPy로는 매우 간단하게 한 줄로 처리 가능합니다.
np.std(lst)
NumPy를 사용하면 코드가 간단해지고, 일반적으로 NumPy는 C로 최적화한 매우 효율적인 라이브러리로 알려져 있으나 NumPy는 싱글 코어와 대형 배열에 최적화된 라이브러리라는 한계가 존재합니다. 실제로 배열의 크기가 100개 이내인 경우 NumPy는 순수 파이썬 구현 보다도 오히려 낮은 성능을 보입니다.
C++ Extension
여기서는 C++로 Extension을 작성하여 성능을 최적화 해보도록 합니다. C++로 표준 편차를 구하는 코드는 아래와 같이 작성했습니다.
double standardDeviation(std::vector<double> v) {
double sum = std::accumulate(v.begin(), v.end(), 0.0);
double mean = sum / v.size();
double squareSum = std::inner_product(v.begin(), v.end(), v.begin(), 0.0);
return sqrt(squareSum / v.size() - mean * mean);
}
C++을 파이썬과 연동 하려면 계산 코드 외에도 wrapper 함수를 작성해야 합니다.
static PyObject *std_standard_dev(PyObject * self, PyObject * args) {
PyObject * input;
PyArg_ParseTuple(args, "O", &input);
int size = PyList_Size(input);
std::vector<double> list;
list.resize(size);
for (int i = 0; i < size; i++) {
list[i] = PyFloat_AS_DOUBLE(PyList_GET_ITEM(input, i));
}
return PyFloat_FromDouble(standardDeviation(list));
}
이 wrapper 함수는 파이썬 리스트를 받아와 값을 하나씩 끄집어 낸 다음 std::vector에 담아 C++ 함수에 전달하는 역할을 합니다. wrapper에는 이외에도 여러가지 처리를 위한 boilerplate 코드가 들어갑니다. 매우 번거로운 작업이고 저 역시도 wrapper 코드를 작성하며 사소한 실수로 무수한 컴파일 오류를 맞이 해야만 했습니다.
번거로운 작업입니다.
Cython
Cython은 CPython과 이름이 비슷하여 혼동될 수 있으나 전혀 다릅니다. 원래의 목적은 Pyrex 기반의 파이썬 코드를 작성하면 이를 C로 변환해 성능을 최적화 해주는 컴파일러입니다. 그러나 외부 C 라이브러리를 랩핑 하는데도 매우 유용합니다. 아울러 C 뿐만 아니라 C++도 네이티브로 지원합니다. 여기서는 C++ 함수를 랩핑하는 용도로 사용했으며, 아래와 같이 코드를 작성했습니다.
cdef extern from "std.h":
double standardDeviation(vector[double])
def standard_dev(lst):
# This pre-conversion has some performance improvements.
cdef vector[double] v = lst
return standardDeviation(v)
헤더를 읽어 함수를 정의한 다음 파이썬 스타일의 함수에서 C++ 함수의 리턴값을 전달합니다. C++과 파이썬이 오묘한 형태로 결합되어 있습니다. 이 부분은 장점이자 단점이 될 수 있는데 기존 파이썬의 함수를 그대로 사용할 수 있는 장점이 있는 반면 기존 파이썬 함수의 낮은 성능 또한 그대로 반영됩니다. 상식적으로 파이썬 코드가 단순히 C 코드로 변환되었다고 성능이 개선되진 않습니다. (물론 약간의 효과는 있습니다.) cdef를 이용해 변수를 C/C++ 네이티브로 선언하고 주요 계산 알고리즘은 외부 C/C++ 함수로 따로 작성해서 랩핑해야 진정한 성능 개선 효과를 기대할 수 있습니다.
원래 Cython은 파이썬의 리스트를 C++ std::vector로 자동으로 컨버전 하지만 여기서는 조금이나마 성능을 개선하고자 상단에 컨버전을 직접 정의했습니다. 컨버전을 직접 구현할때는 14줄이 필요했으나 여기서는 단 한 줄로 가능했습니다.
pybind11
pybind11는 “Seamless operability between C++11 and Python”라는 모토로 최근에 등장한 C++ 전용 헤더 라이브러리 입니다. ctypes를 사용할 수 있는 C의 잇점이 있다면 pybind11은 C++에서만 사용이 가능합니다. 파이썬 연동을 마치 C++ 코드의 연장선 처럼 부드럽게seamless 할 수 있습니다. cmake도 잘 지원하여 빌드나 IDE 연동도 편리합니다. 앞서 Cython이 파이썬 중심의 라이브러리 였다면 pybind11는 C++ 중심의 라이브러리라 할 수 있습니다.
랩핑 코드 또한 파이썬으로 작성했던 Cython과 달리 아래와 같이 C++로 작성합니다.
PYBIND11_MODULE(stdpy, m) {
m.def("standard_dev", &standardDeviation);
}
Cython과 마찬가지로 오토 컨버전을 지원하며 헤더를 include 하면 나머지는 자동으로 처리됩니다.
#include <pybind11/stl.h>
C++에 최적화 되어 있으므로 성능이 매우 좋을 것 같지만 아쉽게도 Cython 보다 못한 성능을 보여줍니다. 특히 오토 컨버전은 편리하지만 별도로 제어할 수 없으며, 이로 인한 성능 저하가 뚜렷합니다.
실험 결과
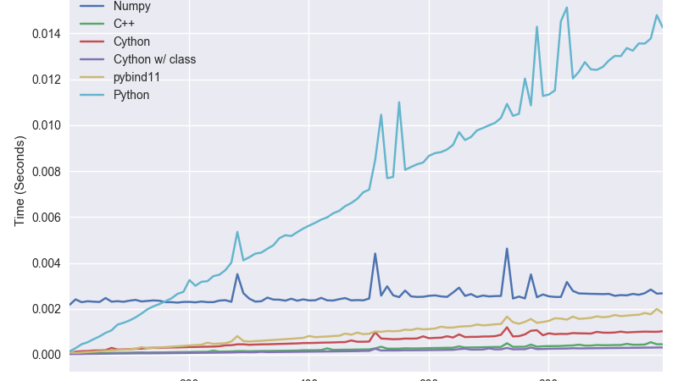
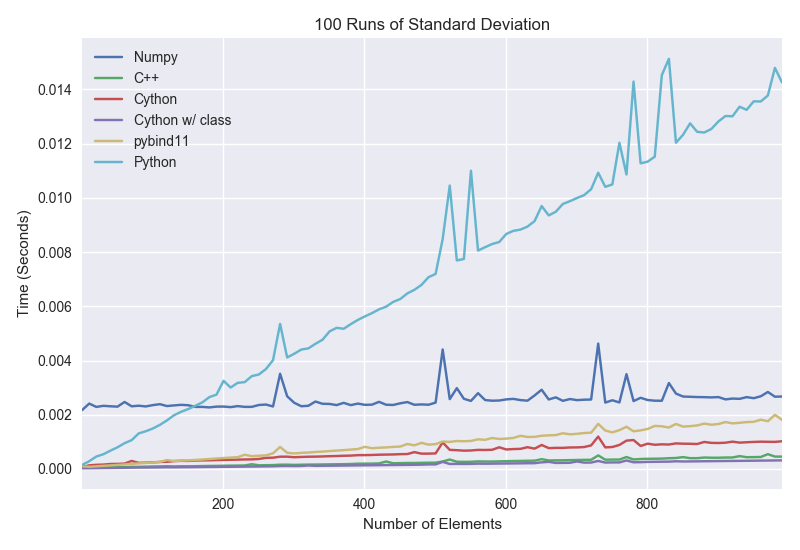
최대 1만개까지 배열의 표준 편차를 구하는 성능 테스트 결과는 아래와 같습니다.

순수 파이썬 구현의 성능은 따로 언급할 필요가 없을듯 하며, 앞서 잠깐 언급했지만 기대를 모았던 NumPy의 성능이 그다지 높지 않습니다. 이는 대형 배열에 최적화 되어 있기 때문이며 이후에 이어지는 대형 배열의 성능 테스트에선 좋은 성능을 확인할 수 있습니다.
C++ 구현은 직접 구현하든 Cython, pybind11을 사용하든 어느쪽이든 좋은 성능을 보여줍니다. 그러나 일반적으로 직접 wrapper를 작성하는 쪽이 가장 성능이 좋으며 오토 컨버전을 지원하는 Cython과 pybind11는 그 만큼의 성능 저하가 있습니다. 특히 pybind11 쪽의 성능 저하가 뚜렷합니다.
Cython w/ class
Cython w/ class는 Cython 구현에 type conversion을 없애기 위해 별도로 구현한 방식입니다. 사실 이 테스트는 NumPy에게 지나치게 유리한데, 왜냐면 파이썬 리스트를 np.array()로 컨버전 하는 것을 벤치마크 바깥에서 별도로 진행했기 때문입니다. 밀리 세컨드 단위로 수행되는 벤치마크에서 NumPy 컨버전은 매우 무거운 편이기도 하고(만약 따로 컨버전 하지 않으면 가장 나쁜 성능이 나옵니다.) 과학 계산에서 NumPy는 사실상 표준 라이브러리의 위치에 있기 때문에 이미 원본 데이터가 NumPy 타입임을 감안하여 어드밴티지를 부여했습니다.
그러나, NumPy를 제외한 다른 모든 구현은 type conversion이 포함되며 C++은 직접 컨버전 코드를 작성했고, 나머지는 오토 컨버전이 되도록 처리했습니다. 테스트는 각 100번씩 수행되므로 컨버전이 필요 없는 NumPy에 비해 다른 구현은 모두 100번씩 별도로 컨버전되는 오버헤드가 발생해 공정한 비교가 될 수 없습니다.
이를 개선하고자 C++ 클래스를 Cython으로 구현했고 미리 컨버전한 값을 private 변수로 갖고 있다가 벤치마크시 계산만 하는 방식으로 최적화 했습니다. 따라서 계산 코드가 다른 구현과 다릅니다.
cyc_rands = stdcyc.pystd(rands)
print('stdcyc: ', cyc_rands.standard_dev())
그 결과 가장 좋은 성능을 확보할 수 있었습니다.
5만개까지 대형 배열로 성능 테스트한 결과는 아래와 같습니다.

먼저 순수 파이썬으로 계산한 결과는 다른 것과 비교가 불가능 할 정도로 느려 아예 비교에서 제외했습니다. 여기서는 NumPy, C++, Cython, Cython w/ class, pybind11만 비교했는데 앞서 다소 실망스런 모습을 보였던 NumPy가 좋은 모습을 보여줍니다. 일정 갯수를 넘어서면서 부터 가장 좋은 성능을 보이며, 배열의 크기가 늘어나도 전체 계산 속도는 크게 증가하지 않습니다. 대형 배열에 최적화된 C 라이브러리의 진가가 드러나는 순간입니다. 컨버전을 배제한 Cython w/ class 조차도 NumPy에 비해 성능이 낮습니다.
참고로 벤치마크는 각 100번씩 수행해 결과를 측정했는데, 실제 프로덕션에서는 같은 계산을 반복하지 않기 때문에 각 1번만 수행하여 NumPy와 Cython w/ class의 비교를 10만개까지 측정해봤습니다.

약 3만개 정도 부터 근소한 차이로 NumPy의 성능이 앞서는 것을 확인할 수 있습니다.
Cython w/ threads
일반적으로 NumPy만 잘 사용해도 충분한 성능을 얻을 수 있습니다. 그러나 NumPy에는 결정적인 한계가 있는데 싱글 코어에 최적화 되어 있다는 점입니다. 애초에 GIL로 인해 멀티 쓰레드가 유명무실한 파이썬과 마찬가지로 NumPy 또한 싱글 코어에 최적화 되어 있다는 한계가 있으며, 멀티 코어를 제대로 활용하기 위해선 C/C++로 쓰레드 프로그래밍을 해야 합니다. 이 때문에 텐서플로를 포함한 대부분의 딥러닝 프레임워크 또한 C++에서 멀티 코어를 활용하며(이 글에선 언급하지 않았지만 SWIG로 파이썬과 연동하여) 계산을 수행하는 방식으로 구현되어 있습니다.
C++11에서 지원하는 std::thread를 이용해 sum, squaredSum을 멀티 쓰레드로 계산해 최적화 해보도록 합니다.
int start = i * round(v.size() / NUM_THREADS);
int end = (i == NUM_THREADS - 1) ? v.size() : (i + 1) * round(v.size() / NUM_THREADS);
ths.push_back(std::thread(&stddev::calc, this, &v, start, end, std::ref(sum), std::ref(squaredSum)));
각 쓰레드별로 분할하여 시작(start)과 끝(end)으로 지정할 인덱스를 계산하고 전체 배열이 포함된 매우 큰 std::vector를 포인터로 넘깁니다. 만약 포인터가 아닌 밸류로 넘긴다면 성능 저하가 심각해 질 것입니다. 계산 함수에서는 포인터의 밸류를 조회하여 start에서 end까지 값을 끄집어내 연산을 수행합니다.
for (int i = start; i < end; i++) {
double it = (*v).at(i);
th_sum += it;
th_squaredSum += it * it;
}
sum += th_sum;
squaredSum += th_squaredSum;
결과를 담을 변수는 C++ 레퍼런스로 넘겼으며, 가장 마지막에 전체 값을 한 번만 업데이트 합니다. 사실 처음 코딩할때는 실수로 레퍼런스 변수를 for loop 사이에 넣고 매 번 업데이트 했는데, 그렇게 할 경우 쓰레드를 4개만 생성해도 변수를 업데이트 하기 위한 atomic lock 경쟁이 생겨 심각한 성능 저하를 가져옵니다. 위 코드 처럼 loop 바깥에서 수행하여 성능을 개선했으며, 컴파일러가 따로 경고하지 않아 실수하기 쉽기 때문에 주의해야 합니다.
성능 최적화를 위해 포인터와 레퍼런스를 번갈아 사용해봤는데 이에 따른 성능 이슈는 없었습니다. 둘 중 선호하는 쪽을 사용하면 되며, 일반적으로 C++에서는 안전하고 편리한 레퍼런스를 사용하는 편이 권장됩니다.
성능 비교
기존에 NumPy와 근사할 정도로 성능이 좋았던 Cython w/ class와 쓰레드로 구현한 Cython w/ threads의 성능을 비교해보도록 합니다. 성능 향상을 극대화 하기 위해 대형 배열로 정했으며 2억개의 엘리먼트로 비교를 진행했습니다.
200,000,000 elements
--
generate rands: 28.931 seconds.
type conversion(stdcyc): 14.959 seconds.
stdcyc elapsed: 2.494 seconds.
랜덤을 생성하는데만 해도 약 30초가 걸리는 대형 배열이고, Cython w/ class로 2.49초 정도 소요됩니다.
200,000,000 elements
--
generate rands: 29.194 seconds.
type conversion(stdcyt): 14.139 seconds.
[C++] std::vector loading: 1600 ms
[C++] NUM_THREADS: 8
[C++] thread execution elapsed: 76 ms
stdcyt elapsed: 1.843 seconds.
Cython w/ threads로는 1.84초에 완료되어 25% 정도 성능 개선 효과가 있습니다. 맥북 프로에서 진행하여 맥북의 코어 갯수인 8개만큼 쓰레드를 돌렸으며, 쓰레드를 8개나 풀 가동 했음에도 불구하고 성능 개선 효과가 그리 크진 않습니다. 이유는 벡터 로딩에 1.6초나 걸렸기 때문이며, 이처럼 정작 연산이 아닌 엉뚱한 곳에 병목이 있을 수 있으므로 주의깊게 디버깅하는 것이 매우 중요합니다.
8개의 쓰레드가 데이터를 나눠 각 쓰레드별 최대 76ms 이내에 모든 연산을 완료 했습니다. 만약 쓰레드를 하나만 사용했다면 600ms가 걸렸을 텐데 이처럼 멀티 쓰레드 프로그래밍으로 524ms를 단축시킬 수 있었습니다.
참고로 두 테스트를 동시에 실행하면 대형 변수의 메모리 복사로 인해 서로간의 성능에 영향을 끼치므로 각각 따로 테스트하여 비교했습니다.
결론
앞서 성능 비교에서 벡터 로딩에만 1.6초가 걸리는걸 확인할 수 있었습니다. 또한 type conversion에만 14초가 걸렸습니다. 이 처럼 대형 배열에서 파이썬과 C/C++ 네이티브 타입(여기서는 C++의 std::vector)의 type conversion, 변수의 메모리 복사는 상당한 오버헤드를 발생시키며, 이를 최소화 하는 것이 무엇보다 중요합니다. 포인터나 레퍼런스를 잘 활용하여 줄일 수 있는 부분은 가능한 줄이는 편이 좋으며, 여기서도 처음부터 벡터를 포인터로 가져오면 시간을 획기적으로 줄일 수 있으나 NumPy와 비교를 위해 일부러 복사하는 방식을 택했습니다. 프로덕션에는 당연히 포인터를 사용해야 합니다.
아울러 직접 모든 wrapper를 작성하는 일은 많은 고난이 뒤따르기 때문에 성능을 약간 타협하여 Cython 또는 pybind11를 택하는 편이 최적의 선택입니다. 그 중에서도 Cython의 성능이 돋보이며, C++ 연동 방식은 pybind11가 좀 더 우아한 편이지만 오토 컨버전의 성능 이슈는 하루빨리 해결되어야 할 과제입니다.
참고
이 문서에서 사용한 표준 편차를 구하는 함수와 최초 C++ 구현은 Speeding up Python and NumPy: C++ing the Way를 참조했으며 이를 fork 하여 C++ wrapper를 개선하고 Cython, pybind11 바인딩을 추가했습니다. 전체 코드는 아래 깃헙에 올려 두었습니다.
likejazz/PythonCExtensions – GitHub
Source: NumPy와 C++ Extensions의 성능 비교


Leave a Reply