
Redis의 SCAN은 어떻게 동작하는가?


Redis의 기능 중에 쓰면 안되지만, 그 단맛에 끌려 어쩔 수 없이 치게 되는 명령이 KEYS입니다. KEYS를 쓰는 순간, Redis는 이 명령을 처리하기 위해서 멈춰버립니다. 특히 트래픽이 많은 서버는 이 KEYS 명령 하나 때문에 많은 장애를 내게 됩니다.
그런데 어느 순간(!) Redis에 SCAN이라는 명령이 생겼습니다. KEYS의 단점을 없애면서도, 느리지 않은 SCAN, 어떻게 그것이 가능할까요? 이 글에서는 단순한 SCAN의 사용법을 넘어, 소스 코드를 통해 동작 원리까지 알아보겠습니다.
SCAN/SSCAN/ZSCAN/HSCAN 명령
대부분의 Redis 명령처럼 SCAN도 네가지 변형이 있습니다. SCAN은 전체 key 목록에서, SSCAN은 set 안에서, ZSCAN은 sorted set 안에서, HSCAN은 hash 안에서 키를 가져오는 명령입니다:
SCAN cursor [MATCH pattern] [COUNT count]SSCAN key cursor [MATCH pattern] [COUNT count]ZSCAN key cursor [MATCH pattern] [COUNT count]HSCAN key cursor [MATCH pattern] [COUNT count]
cursor 값을 0으로 지정한 SCAN/SSCAN/ZSCAN/HSCAN 명령으로 순회가 시작되고, 이어지는 순회에 사용할 cursor 값과, 지정한 패턴(pattern)과 일치하는 키를 최대 지정한 갯수(count)만큼 반환합니다. 반환된 cursor 값이 0이면 순회가 종료됩니다. 이 과정을 전체 순회(full iteration)이라고 합니다. 다음은 CLI에서 SCAN 명령을 사용하여 전체 순회를 하는 예입니다:
redis 127.0.0.1:6379> scan 0 <-- cursor 값 0으로 순회 시작.
1) "17" <-- 이어지는 scan 명령에 사용할 cursor 값
2) 1) "key:12"
2) "key:8"
3) "key:4"
4) "key:14"
5) "key:16"
6) "key:17"
7) "key:15"
8) "key:10"
9) "key:3"
10) "key:7"
11) "key:1"
redis 127.0.0.1:6379> scan 17 <-- 앞의 scan 명령의 응답으로 반환된 cursor 값
1) "0" <-- 반환된 cursor 값이 0이면 순회 종료(전체 순회).
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"
6) "key:13"
7) "key:6"
8) "key:9"
9) "key:11"
앞의 scan 명령의 결과에 따라 이어지는 scan 명령에 사용할 cursor 값이 바뀌고 이 값에 따라 순회 종료 여부를 판단해야 하므로 CLI보다는 스크립트에서 더욱 유용합니다. 다음은 Redis에서 모든 키 목록을 가져오는 파이썬 코드입니다:
import redis
r = redis.StrictRedis('localhost', port=6379)
init = 0 # cursor 값 0으로 스캔 시작
while(True):
ret = r.scan(init)
print init
init = ret[0] # 이어지는 scan 명령에 사용할 cursor 값
print ret[1]
if (init == '0'): # 반환된 cursor 값이 0이면 스캔 종료
break
위 예제의 결과는 KEYS 명령과 기본적으로 동일하지만, 항상 그렇지는 않습니다 항상 그렇지는 않다뇨?! 뭐가 다른거죠? 왜 다른거죠? 그래서… Redis의 소스를 뒤져보았습니다.
Redis의 스캔 구현
모든 스캔 명령(SCAN/SSCAN/ZSCAN/HSCAN)은 scanGenericCommand라는 공통 함수를 이용해서 처리가 됩니다:
void scanGenericCommand(redisClient *c, robj *o, unsigned long cursor) {
......
ht = NULL;
if (o == NULL) {
ht = c->db->dict;
} else if (o->type == REDIS_SET && o->encoding == REDIS_ENCODING_HT) {
ht = o->ptr;
} else if (o->type == REDIS_HASH && o->encoding == REDIS_ENCODING_HT) {
ht = o->ptr;
count *= 2; /* We return key / value for this type. */
} else if (o->type == REDIS_ZSET && o->encoding == REDIS_ENCODING_SKIPLIST) {
zset *zs = o->ptr;
ht = zs->dict;
count *= 2; /* We return key / value for this type. */
}
if (ht) {
void *privdata[2];
/* We pass two pointers to the callback: the list to which it will
* add new elements, and the object containing the dictionary so that
* it is possible to fetch more data in a type-dependent way. */
privdata[0] = keys;
privdata[1] = o;
do {
cursor = dictScan(ht, cursor, scanCallback, privdata);
} while (cursor && listLength(keys) < count);
} else if (o->type == REDIS_SET) {
int pos = 0;
int64_t ll;
while(intsetGet(o->ptr,pos++,&ll))
listAddNodeTail(keys,createStringObjectFromLongLong(ll));
cursor = 0;
} else if (o->type == REDIS_HASH || o->type == REDIS_ZSET) {
unsigned char *p = ziplistIndex(o->ptr,0);
unsigned char *vstr;
unsigned int vlen;
long long vll;
while(p) {
ziplistGet(p,&vstr,&vlen,&vll);
listAddNodeTail(keys,
(vstr != NULL) ? createStringObject((char*)vstr,vlen) :
createStringObjectFromLongLong(vll));
p = ziplistNext(o->ptr,p);
}
cursor = 0;
} else {
redisPanic("Not handled encoding in SCAN.");
}
......
위의 코드에서 핵심적인 부분은, 찾아야 하는 key들을 keys라는 리스트에 추가하고, 이 리스트를 돌면서 패턴에 맞는 것들을 삭제한 결과를 돌려줍니다. 당연히 Redis는 다양한 자료구조를 지원하고 있고, 속도를 위해서 같은 자료구조라도 구현 방식이 여러가지입니다. 그러나 이것 전부라면 이 글을 쓰지 않았겠죠. 삽질을 계속하기 위해, 먼저 “Redis가 어떻게 데이터를 저장하는지”부터 다시 한번 살펴 보겠습니다.
Redis의 자료구조
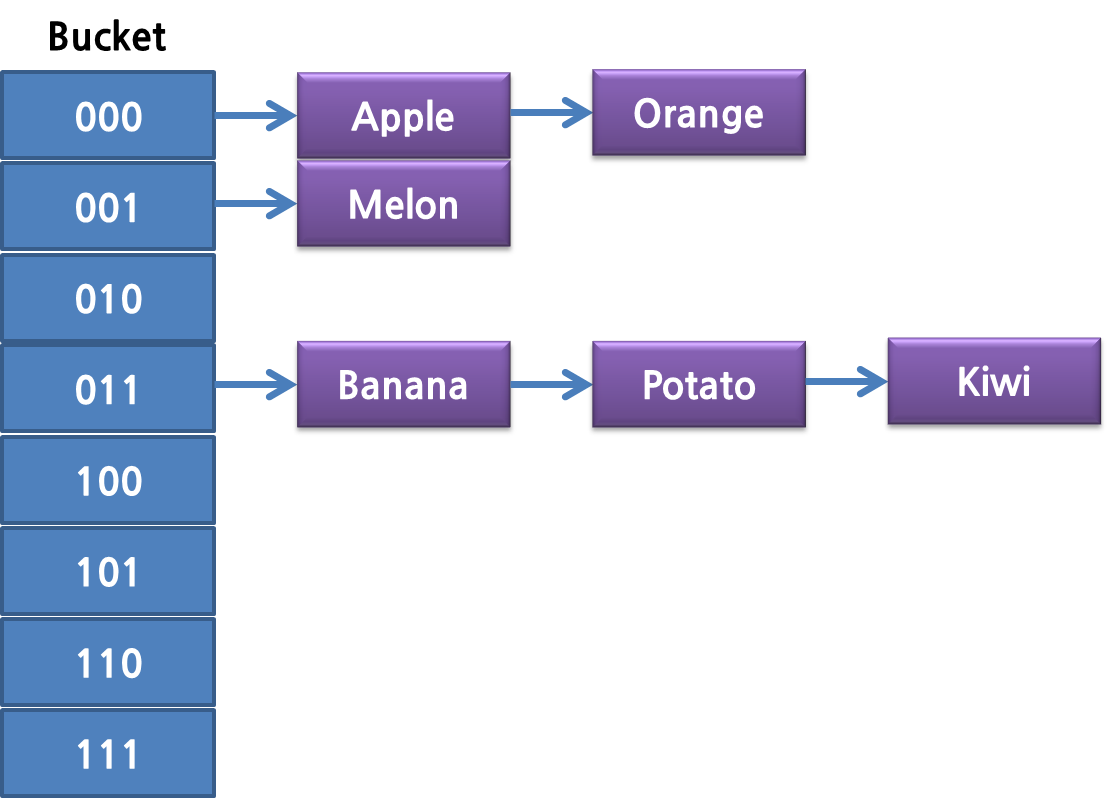
Redis의 가장 기초적인 자료구조는 KV 즉 Key/Value 형태를 저장하는 것입니다.(String 타입이라고도 합니다.) 이를 위해 Redis는 Bucket을 활용한 Chained Linked List 구조를 사용합니다. 최초에는 4개의 Bucket에서 사용하며, 같은 Bucket에 들어가는 Key는 링크드 리스트 형태로 저장하는 거죠. 즉 다음 그림과 같습니다.

이 Chained Linked List에는 약점이 있습니다. 한 Bucket 안에 데이터가 많아지면 결국 탐색 속도가 느려집니다. 이를 위해서 Redis는 특정 사이즈가 넘을 때 마다 Bucket을 두 배로 확장하고, Key들을 rehash하게 됩니다. 먼저 이 때 Key의 Hash로 사용하는 해시함수는 다음과 같습니다. MurmurHash2를 사용합니다.
/* MurmurHash2, by Austin Appleby
* Note - This code makes a few assumptions about how your machine behaves -
* 1. We can read a 4-byte value from any address without crashing
* 2. sizeof(int) == 4
*
* And it has a few limitations -
*
* 1. It will not work incrementally.
* 2. It will not produce the same results on little-endian and big-endian
* machines.
*/
unsigned int dictGenHashFunction(const void *key, int len) {
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len;
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}
그리고 hash 값이 들어가야 할 hash table 내의 index를 결정하는 방법은 다음과 같습니다.
/* Returns the index of a free slot that can be populated with
* a hash entry for the given 'key'.
* If the key already exists, -1 is returned.
*
* Note that if we are in the process of rehashing the hash table, the
* index is always returned in the context of the second (new) hash table. */
static int _dictKeyIndex(dict *d, const void *key)
{
......
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
......
}
return idx;
}
table에는 Key를 찾기위해 비트 연산을 하기 위한 sizemask가 들어가 있습니다. 초기에는 table의 bucket이 4개 이므로 sizemask는
이진수로 11 즉 3의 값이 셋팅됩니다. 즉 해시된 결과 & 11의 연산결과로 들어가야 하는 Bucket이 결정되게 됩니다.
여기서 Key가 많아지면 Redis는 Table의 사이즈를 2배로 늘리게 됩니다. 그러면 당연히 sizemask도 커지게 됩니다. Table size가 8이면 sizemask는 7이 됩니다.
먼저 간단하게 말하자면, SCAN의 원리는 이 Bucket을 한 턴에 하나씩 순회하는 것입니다. 그래서 아래 그림과 같이 처음에는 Bucket Index 0를 읽고 데이터를 던져주는 것입니다.

t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
Redis의 Re-hashing
이번에는 Redis SCAN의 동작을 더 분석하기 위해서 Redis Hash Table의 Rehashing과, 그 상황에서 SCAN이 어떻게 동작하는지 알아보도록 하겠습니다. 앞에서도 간단하게 언급했지만 Redis Hash Table은 보통 Dynamic Bucket에 충돌은 list로 처리하는 방식입니다.
처음에는 4개의 Bucket으로 진행하면 Hash 값에 bitmask를 씌워서 Hash Table 내의 index를 결정합니다. 그런데, 이대로 계속 데이터가 증가하면, 당연히 충돌이 많고, List가 길어지므로, 탐색 시간이 오래걸리게 되어서 문제가 발생합니다. Redis는 이를 해결하기 위해서 hash table의 사이즈를 2배로 늘리는 정책을 취합니다.
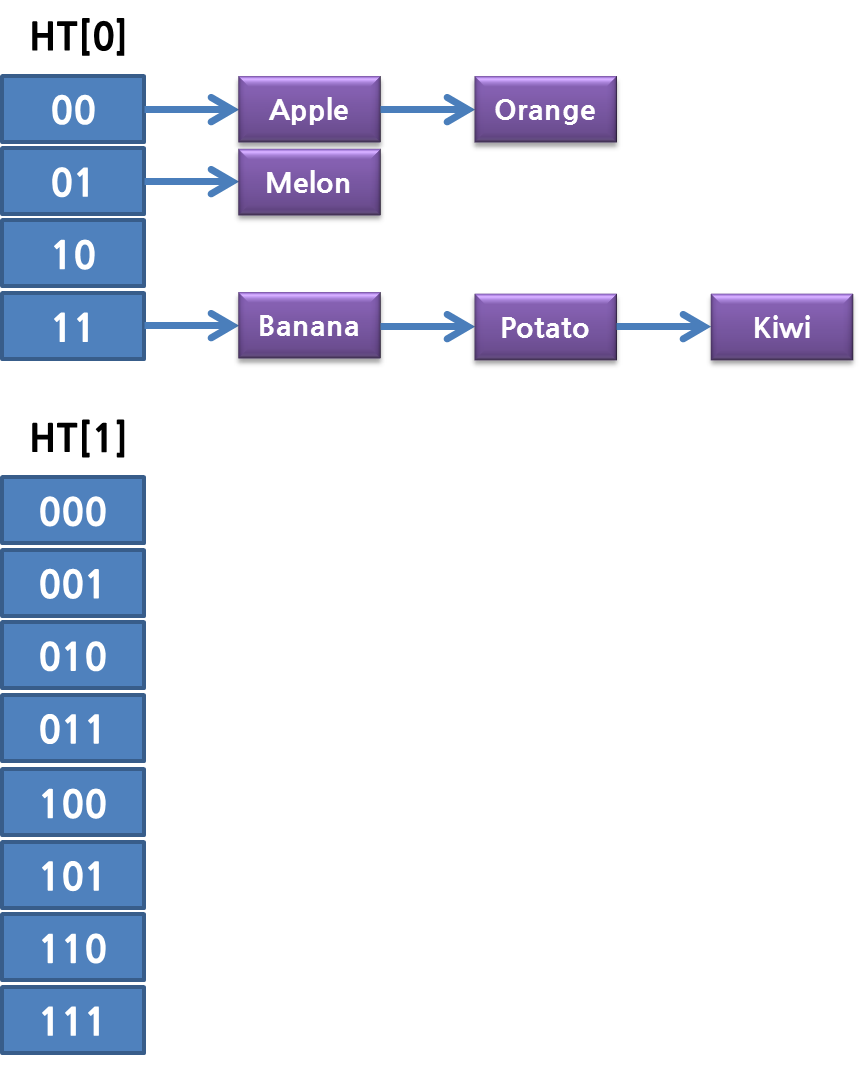
2배로 테이블이 늘어나면서, bitmask는 하나 더 사용하도록 됩니다. 이렇게 테이블이 확장되면 Rehash를 하게 됩니다. 그래야만 검색시에 제대로 찾을 수 있기 때문입니다. 먼저 Table을 확장할 때 사용하는 것이 _dictExpandIfNeeded 합수입니다. dictIsRehashing는 이미 Rehash 중인지를 알려주는 함수이므로, Rehashing 중이면 이미 테이블이 확장된 상태이므로 그냥 DICT_OK를 리턴합니다.
먼저 hash table에서 hash table의 사용 정도가 dict_force_resize_ratio 값 보다 높으면 2배로 확장하게 됩니다.
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
실제로 _dictExpandIfNeeded는 _dictKeyIndex 함수에서 호출하게 됩니다. 이렇게 테이블이 확장되면 Rehash를 해야 합니다. Rehash라는 것은 테이블의 Bucket 크기가 커졌고 bitmask가 달라졌으니… mask 0011이 전부 3번째 index였다면 이중에서 111은 7번째로, 011은 3번째로 옮기는 것입니다. 여기서 Redis의 특징이 하나 있습니다. 한꺼번에 모든 테이블을 Rehashing 해야 하면 당연히 시간이 많이 걸립니다. O(n)의 시간이 필요합니다. 그래서 Redis는 rehash flag와 rehashidx라는 변수를 이용해서, hash table에서 하나씩 Rehash하게 됩니다. 즉, 확장된 크기가 8이라면 이전 크기 총 4번의 Rehash 스텝을 통해서 Rehashing이 일어나게 됩니다. (이로 인해서 뒤에서 설명하는 특별한 현상이 생깁니다.)
그리고 현재 rehashing 중인것을 체크하는 함수가 dictIsRehashing 함수입니다. rehashidx가 -1이 아니면 Rehashing 중인 상태입니다.
#define dictIsRehashing(d) ((d)->rehashidx != -1)
그리고 위의 _dictExpandIfNeeded에서 호출하는 실제 hash table의 크기를 증가시키는 dictExpand 함수에서 rehashidx를 0으로 설정합니다.
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
위의 함수를 잘 살펴보면 dict 구조체 안의 ht[1] = n으로 할당하는 코드가 있습니다. 이 얘기는 hash table이 두 개라는 것입니다. 먼저 dict 구조체를 살펴보면 다음과 같습니다.
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
실제로, redis의 rehashing 중에는 Hash Table이 두개가 존재합니다. 이것은 앞에 설명했듯이… 한번에 rehash step이 끝나지 않고, 매번 하나의 bucket 별로 rehashing을 하기 때문입니다. 즉 hash table의 확장이 일어나면 다음과 같이 두 개의 hash table 이 생깁니다.
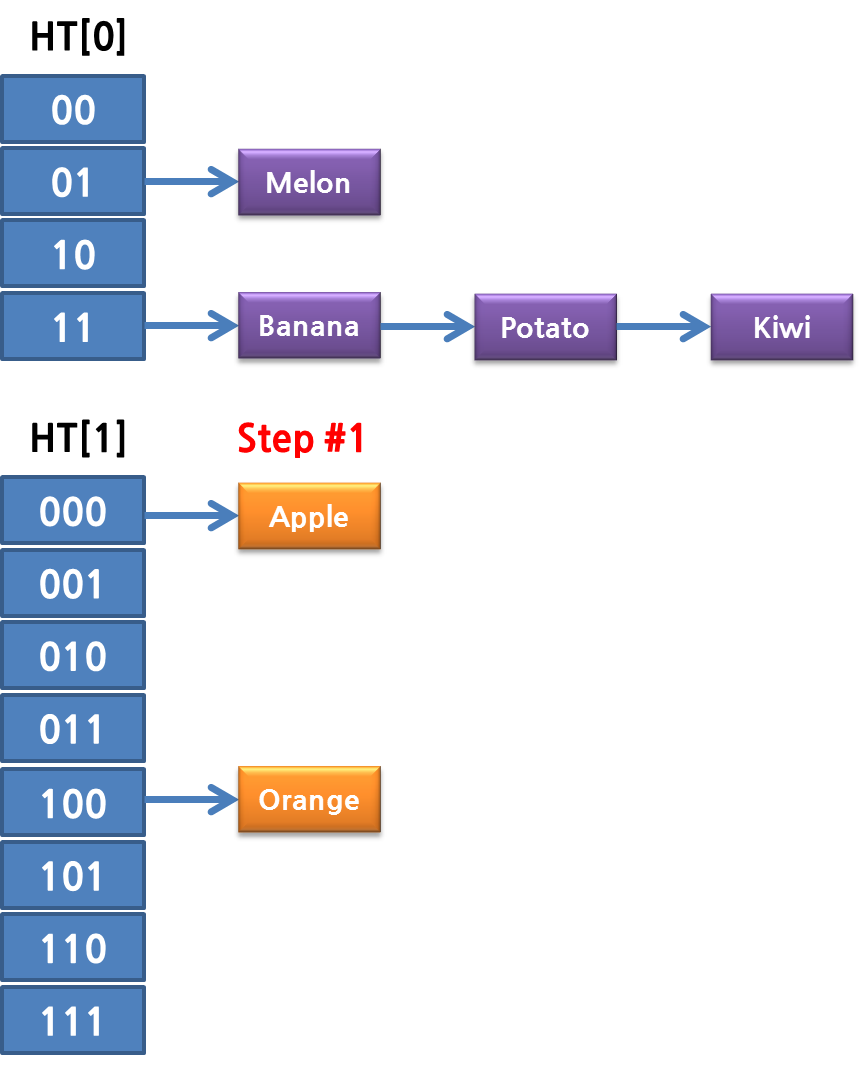
그리고 한 스텝이 자나갈 때 마다 하나의 Bucket 단위로 해싱이 됩니다. 즉 첫번째 rehash step에서는 다음과 같이 ht[0]에 있던 데이터들이 ht[1]으로 나뉘어서 들어가게 됩니다.
두 번째, 세 번째, 네 번째 rehash 스텝이 끝나면 완료되게 됩니다.
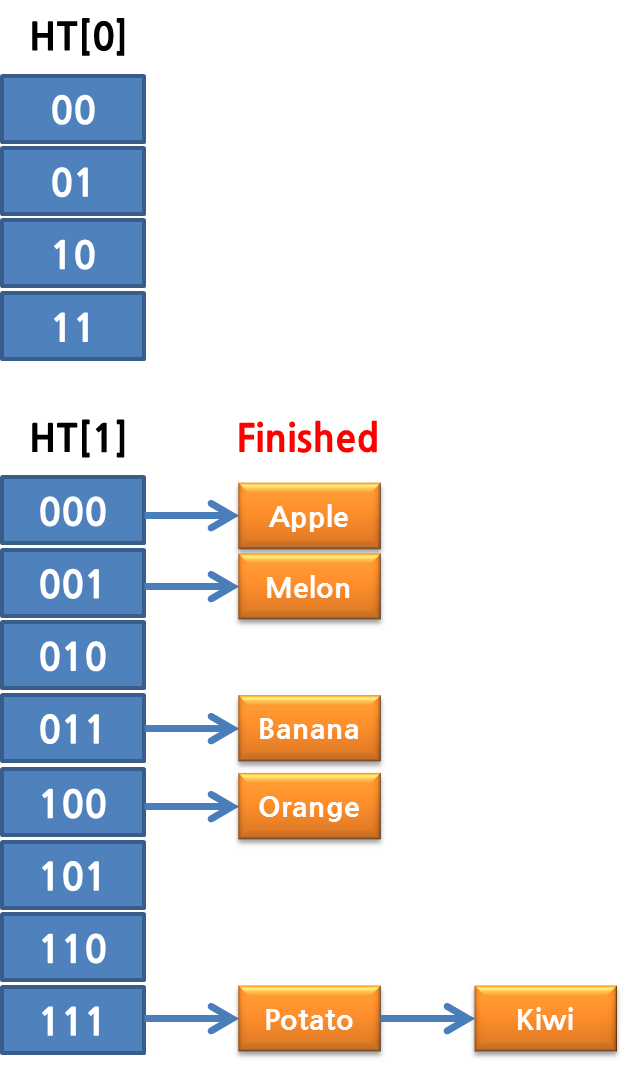
그럼 의문이 생깁니다. Rehashing 중에 추가 되는 데이터는? 또는 삭제나 업데이트는? 추가 되는 데이터는 이 때는 무조건 ht[1]으로 들어가게 됩니다.(또 해싱 안해도 되게…) 두 번째로, 검색이나 업데이트는?? 이 때는 ht[0], ht[1]을 모두 탐색하게 됩니다.(어쩔 수 없겠죠?)
dictRehash 함수에서 이 rehash step을 처리하게 됩니다. dictRehash 함수의 파라매터 n은 이 스텝을 몇 번이나 할 것인가 이고, 실제로 수행할 hash table의 index는 함수 중에서 ht[0]의 table이 NULL인 부분을 스킵하면서 찾게 됩니다. 그리고 ht[0]의 used 값이 0이면 rehash가 모두 끝난것이므로 ht[1]을 ht[0]로 변경하고 rehashidx를 다시 -1로 셋팅하면서 종료하게 됩니다.
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table. */
int dictRehash(dict *d, int n) {
if (!dictIsRehashing(d)) return 0;
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
return 1;
}
이제 다시 SCAN으로 돌아오면… Rehashing 중의 dictScan 함수는 다음과 같습니다.
} else {
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
do {
/* Emit entries at cursor */
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment bits not covered by the smaller mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
실제로 이미 Rehashing이 된 bucket의 경우는 ht[0] 작은 hash table에는 이미 index의 값이 NULL이므로 실제로 돌지 않지만, 아직 rehash되지 않은 bucket의 경우는 ht[0] 와 ht[1]의 두 군데, 즉 총 세 군데에 데이터가 존재할 수 있습니다. 그래서 먼저 ht[0]의 bucket을 돌고 나서, ht[1]을 찾게 됩니다. 여기서 당연히 ht[1]에서는 두 군데를 검색해야 하므로 두 번 돌게 됩니다.
v = (((v | m0) + 1) & ~m0) | (v & m0);
즉 위의 식은 만약 v가 0이고 m0 = 3, m1 = 7이라고 하면 (((0 | 3) + 1) & ~3) | (0 & 3)이 됩니다. ~3은 Bitwise NOT 3이 되므로 -4이고, (4 & -4) | 0이므로, 결론은 4 & -4 입니다. 3은 00000011, bitwise NOT하면 11111100이므로, 00000100 & 11111100 해서 00000100, 즉 4가 됩니다. 처음에는 index 0, 두번째는 index 4가 되는 거죠. 그래서 첫 루프를 돌게 됩니다. 다시 4 & (m0 ^ m1) == 4 이므로…
이제 두 번째 루프에서 다시 (((4 | 3) + 1) & -4) | (4 & 3)이고 4 | 3 = 7, 4 & 3 = 0이고, 다시 한번 정리하면 ((7+1) & -4) | 0 이므로 결론은 8 & -4 = 4 가 되고, 00001000 & 111111100이 되므로 v 는 이번에는 00001000, 즉 8이 됩니다. 즉 한번 돌 때 마다, ht[0]의 size 만큼 증가하게 됩니다.(다들 한 방에 이해하실 텐데… 이걸 설명한다고 Orz) 그래서 그 다음번에는 8 & 4 가 되므로 루프가 끝나게 됩니다. 즉, 0, 4 이렇게 ht[1]에서 두 번 읽어야 하니, 두 번 읽는 코드를 만들어둔거죠.
Redis의 SCAN과 cursor
결국 Redis SCAN에서의 Cursor는 bucket 을 검색해야할 다음 index 값이라고 볼 수 있습니다. 그런데 실제로 실행시켜보면, 0, 1, 2 이렇게 증가하지 않습니다.
그 이유 중에 하나는 실제 Cursor 값이 다음 index의 reverse 값을 취하고 있기 때문입니다. 이걸 보기 전에 먼저 다시 한번 SCAN의 핵심 함수인 dictScan을 살펴보도록 하겠습니다.(맨 뒤만 보면 됩니다.)
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
} else {
......
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits of the smaller table */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
return v;
}
한 이터레이션이 끝나고 나면 m0 의 bitwise NOT을 or 하고 reverse를 취한 다음 1을 더하고 다시 reverse를 취합니다. 일단 bucket이 4개만 있다고 가정하고, rehashing은 빼고 생각해보도록 합니다. 먼저 여기서 reverse는 비트를 쭈욱 세워놓고, 그걸 거꾸로 뒤집는 것입니다.
그래서 0의 rev(0) 은 그대로 0이고, rev(1)은 8000000000000000(16진수), rev(2)는 4000000000000000(16진수)가 됩니다.
처음에는 v(cursor)가 0입니다. scan이 끝나고 (0 |= ~3) = -4, 그 뒤에 rev(-4)는 3fffffffffffffff(16진수) 가 됩니다. 여기에 1을 더하면 4000000000000000 여기서 다시 rev(4000000000000000)가 되면 2가 나오게 됩니다.
/* Function to reverse bits. Algorithm from:
* http://graphics.stanford.edu/~seander/bithacks.html#ReverseParallel */
static unsigned long rev(unsigned long v) {
unsigned long s = 8 * sizeof(v); // bit size; must be power of 2
unsigned long mask = ~0;
while ((s >>= 1) > 0) {
mask ^= (mask << s);
v = ((v >> s) & mask) | ((v << s) & ~mask);
}
return v;
}
그런데 왜 reverse를 취하는 것일까요? 이것은 실제 적으로 1씩 증가하는 형태라면… cursor가 언제 끝나는지 알려주기가 애매해서 입니다. 즉 끝났다는 값을 다시 줘야 하는데, 그것보다는 0으로 시작해서 다시 0으로 끝날 수 있도록 reverse 형태를 취하는 것이죠.
결론
Redis의 SCAN명령은 싱글쓰레드 아키텍쳐에서 KEYS와 SMEMBERS 명령이 가진 문제점을 해결한 유용한 명령입니다. 그러나, 빛이 있는 곳에는 그림자가 있기 마련! SCAN 명령도 여러가지 문제점이 있습니다:
- 기본적으로 scan 의 경우 table 의 한 블럭을 가져오는 것이라서, 여기에 개수가 많으면 시간이 많이 걸릴 수도 있습니다.(다만, 리해싱 테이블이 bitmasking 크기만큼 커지므로, 한 블럭이 극단적으로 커질 가능성은 높지 않습니다.)
- set/sorted set/hash 의 내부 구조가 hash table 이나 skiplist 가 아닐 경우(ziplist 로 구현되어 있을 경우), 한 컬렉션의 모든 데이터를 가져오므로,
KEYS명령과 비슷한 문제가 그대로 발생할 수 있습니다. - 명령의 옵션으로 count 값을 지정할 수 있지만, 정확히 그 개수를 보장하지 않습니다.
- 순회가 시작(cursor 값을 0으로 지정한 scan 명령)된 이후에 추가된 항목은 전체 순회(full iteration; scan 명령의 반환된 cursor값이 0)가 끝날 때까지 반환되지 않습니다(cursor가 이미 지나갔으므로).
- hash table이 확장/축소/rehashing 될 때 다시 스캔하지 않기 때문 같은 항목이 여러 번 반환 될 수 있습니다. 반환된 키 값으로 다른 명령을 실행하려면 주의해야 합니다.
“Redis의 SCAN은 어떻게 동작할까”라는 단순한 호기심에서 출발해서 Redis의 코드를 여기저기 살펴보았습니다. 어떤가요? 별거 없죠? 부족한 글이지만 이 글을 통해서, 유명한 오픈소스라고 해서 기죽지 않고 소스 코드를 뒤져보고 직접 확인하는 재미를 발견하셨길 바랍니다.
이 글은 자칭 “혀로그래머” clark.kang의 블로그 Scan/SScan/ZScan/HScan 이야기…와 “Redis Scan은 어떻게 동작할까?” 시리즈 1부, 2부, 3부를 원저자의 동의를 받아 엮은 글입니다.
- 커버 이미지 출처: European Southern Observatory © The new PARLA laser in operation at ESO’s Paranal Observatory
Source: Redis의 SCAN은 어떻게 동작하는가?


Leave a Reply