amazon web service
Amazon Location Service 미리보기 – 사용자 애플리케이션에 지도 및 위치 인식 기능 추가
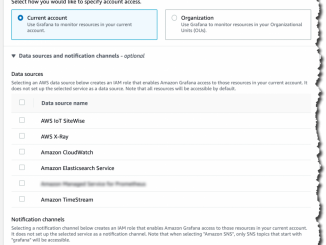
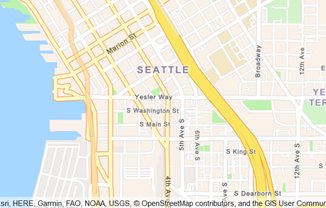
Amazon Location Service 미리보기 – 사용자 애플리케이션에 지도 및 위치 인식 기능 추가 맵, 위치 인식 및 기타 위치 기반 기능을 사용자의 웹 및 모바일 애플리케이션에 보다 쉽고 비용 효율적으로 추가하고자 합니다. 지금까지 이 작업은 다소 복잡하고 비용이 많이 들었을 뿐 아니라, 단일 공급자의 비즈니스 및 프로그래밍 모델에 연결되었습니다. Amazon Location Service 소개 오늘 Amazon Location을 미리 보기 형식으로 사용할 수 있으며 지금 바로 사용 가능합니다. 일반적인 대안책에 비해 상당히 저렴한 Amazon Location Service를 사용하면 경제적인 종량 과금제 방식으로 여러 공급자의 맵 및 위치 기반 서비스에 액세스할 수 있습니다. Amazon Location Service를 사용하면 사용자의 위치를 파악하는 애플리케이션을 구축하고 그에 따라 대응할 수 있습니다. 맵 표시, 주소 검증, 지오코딩(주소를 특정 위치로 전환) 수행, 패키지 및 디바이스 이동 추적 등의 작업을 수행할 수 있습니다. 추적된 항목이 지오펜싱된 영역에 들어가거나 나갈 때 지오펜스를 쉽게 설정하고 알림을 받을 수 있습니다. 전체 제어를 유지하면서 맵에 [ more… ]