amazon web service
AWS 주간 소식 모음 – 2019년 8월 12일
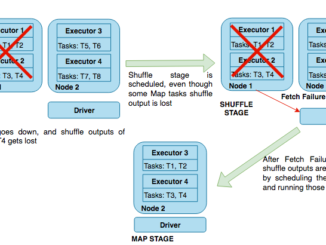
AWS 주간 소식 모음 – 2019년 8월 12일 안녕하세요! 여러분~ 매주 월요일 마다 지난 주에 업데이트된 국내 AWS관련 콘텐츠를 정리해 드립니다. AWS 클라우드에 대한 새로운 소식을 확인하시는데 많은 도움 되시길 바랍니다. 혹시 빠지거나 추가할 내용이 있으시면, 저에게 메일 주시면 추가 공유해 드리겠습니다. AWS코리아 블로그 Amplify CLI에서 로컬 모의 동작 및 테스트 기능 사용해 보기 (2019-08-11) Amazon Aurora Multi-Master를 통한 고가용성 MySQL 애플리케이션 만들기 (2019-08-11) AWS Lake Formation – 데이터레이크 구축 및 관리 서비스 정식 출시 (2019-08-10) Amazon EMR 클러스터 탄력성에 따른 Spark 노드 손실 문제 해결 방법 (2019-08-08) Parquet 형식의 EMRFS S3 최적화 커미터를 통한 Apache Spark 쓰기 성능 개선하기 (2019-08-08) AWS Toolkit for IntelliJ를 통해 손쉽게 서버리스 앱 배포해 보기 (2019-08-08) Amplify Framework 업데이트 – 인공 지능 서비스 기능 추가 (2019-08-06) AWS 추천 콘텐츠 궁금한 이야기 Y – 그들이 AWS 위에서 데이터 파이프라인을 운영하는 법 (2019-08) (2019-08-09) AWS Deepracer [ more… ]