amazon web service
Amazon CloudWatch 계정간 관찰 가능성 기능 출시
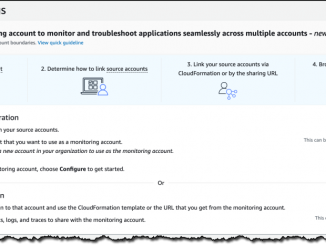
Amazon CloudWatch 계정간 관찰 가능성 기능 출시 여러 AWS 계정을 사용하여 애플리케이션을 배포하는 것은 팀 간의 보안 및 청구 경계를 설정하고 운영 이벤트의 영향을 줄이는 좋은 방법입니다. 다중 계정 전략을 채택할 때는 여러 계정에 분산되어 있는 원격 분석 데이터를 분석해야 합니다. 애플리케이션의 모든 구성 요소를 중앙 집중식 보기에서 모니터링할 수 있는 유연성을 제공하기 위해 오늘 Amazon CloudWatch 계정간 관찰 가능성을 도입했습니다. Amazon CloudWatch 계정간 관찰 가능성은 CloudWatch에 저장된 지표, 로그 및 추적과 같은 교차 계정 원격 측정 데이터를 검색, 분석 및 상호 연관시키는 새로운 기능입니다. 이제 중앙 모니터링 AWS 계정을 설정하고 다른 계정을 소스로 연결할 수 있습니다. 그런 다음 애플리케이션 전반의 로그를 검색, 감사 및 분석하여 몇 초 만에 운영 문제를 심층 분석할 수 있습니다. 한 곳에서 여러 계정의 지표를 검색 및 시각화하고 다른 계정에 속한 지표를 평가하는 경보를 생성할 수 있습니다. 먼저 애플리케이션의 총 교차 계정 보기로 시작하여 오류가 [ more… ]