Using NGINX Plus for Backend Upgrades with Zero Downtime, Part 2 – Individual Servers

This is the second of three articles in our series about using NGINX Plus to upgrade backend servers with zero downtime. In the first article, we describe the two NGINX Plus features you can use for backend upgrades with zero downtime – the on-the-fly reconfiguration API and application health checks – and discuss the advantages of each method.
In this second article, we explore use cases around upgrading the software or hardware on an individual server, which is one of the most common reasons to take servers offline. We could just take the server offline with no preparation, but that kills all the current client connections, making for a bad user experience. What we want is to stop sending any new requests or connections to the server, while letting it finish off any outstanding work. Then we can safely take it offline without impacting clients. NGINX Plus provides a few methods for achieving this outcome.
For use cases around upgrading the version of an application on a group of upstream servers, see the third article, Using NGINX Plus for Backend Upgrades with Zero Downtime, Part 3 – Application Version.
Base Configuration for the Use Cases
For the API examples we will be making the API calls from the NGINX Plus instance, so they will be sent to localhost.
The base configuration for the use cases starts with two servers in a single upstream configuration block called demoapp. In the first server configuration block, we configure a virtual server listening on port 80 that load balances all requests to the demoapp upstream group.
We’re configuring an application health check, which is a best practice for reducing the impact of backend server errors on the user experience and for improving monitoring. Here we configure the health check to succeed if the server returns the file healthcheck.html with an HTTP 2xx or 3xx response code (the default success criterion for health checks).
Though it’s not strictly necessary for basic health checks, we’re putting the health_check directive in its own location block. This is a good practice as it allows us to configure different settings, such as timeouts and headers, for health checks versus regular traffic. For a use case where a separate location for the health_check directive is required, see Doing a Dark Launch.
# In the HTTP context
upstream demoapp {
zone demoapp 64k;
server 172.16.210.81:80;
server 172.16.210.82:80;
}
server {
listen 80;
status_zone demoapp;
location / {
proxy_pass http://demoapp;
}
location @healthcheck {
internal;
proxy_pass http://demoapp;
health_check uri=/healthcheck.html;
}
}
We also configure a second virtual server that listens on port 8080 for requests to locations corresponding to the dynamic reconfiguration API (/upstream_conf), the NGINX Plus status dashboard (/status.html), and the NGINX Plus status API (/status). Note that these location names are the conventional ones, but you can choose different names if you wish.
It is a best practice to secure all traffic to the reconfiguration and status APIs and the dashboard, which we do here by granting access only to users on internal IP addresses in the range 192.168.100.0 to 192.168.100.255. For stronger security, use client certificates, HTTP Basic authentication, or the Auth Request module to integrate with external authorization systems like LDAP.
# In the HTTP context
server {
listen 8080;
allow 192.168.100.0/24;
deny all;
location = / {
return 301 /status.html;
}
location /upstream_conf {
upstream_conf;
}
location = /status.html {
root /usr/share/nginx/html;
}
location /status {
status;
}
}
With this configuration in place, the base command for the API commands in this article is
http://localhost:8080/upstream_conf?upstream=demoappUsing the API to Upgrade an Individual Server
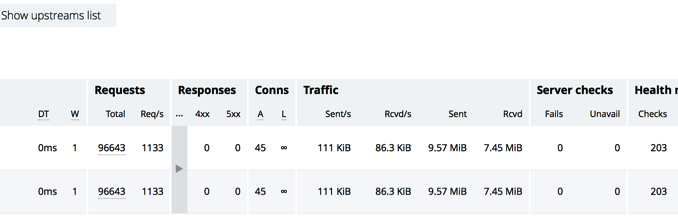
To verify that the two servers in the demoapp upstream group (configured in the previous section) are active, we look at the Upstreams tab on the NGINX Plus live activity monitoring dashboard. The numbers in the Requests and Conns columns confirm that the servers are processing traffic:
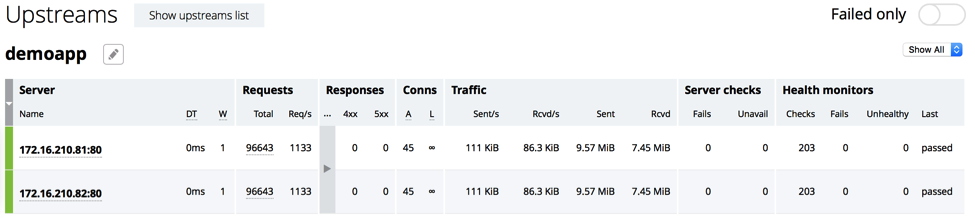
Now we take server 172.16.210.82 offline for maintence. To see the ID number assigned to it, we send the base API command. The response tells us the server has id=1:
http://localhost:8080/upstream_conf?upstream=demoapp
server 172.16.210.81:80; # id=0
server 172.16.211.82:80; # id=1To mark the server as down, we append this string to the base command:
...&id=1&down=Now the dashboard shows that the active connection count (Conns > A) for 172.16.210.82 is zero, so it is safe to take it offline for maintenance.

When maintenance is complete, we can bring the server back online by appending this string to the base command:
...&id=1&up=Note that you can also use the editing interface on the dashboard’s Upstreams tab to change server state (mark a server as up, down, or drain) rather than sending commands to the API. For instructions, see our blog.
Using the API to Upgrade an Individual Server with Session Persistence Configured
When we enable session persistence, clients are directed to the same backend server for all requests during a session. NGINX Plus supports several session persistence methods with the sticky directive to the upstream block; here we use the sticky cookie method:
# In the HTTP context
upstream demoapp {
zone demoapp 64k;
server 172.16.210.81:80;
server 172.16.210.82:80;
sticky cookie srv_id expires=1h domain=.example.com path=/;
}Session persistence is required for any application that keeps state information for users (such as a shopping cart), but it complicates upgrades because now it is not enough just to wait until there are no active connections to our server before taking it offline. There might be clients that aren’t sending requests right now but haven’t ended their session with the server. For the best user experience, we want to keep the active sessions open – the amount of time depends on the application – but don’t want any new sessions to start.
Fortunately, the NGINX Plus drain state does exactly this. Session draining adds one more step to the process outlined in the previous section. Instead of immediately marking the server as down, we mark it as drain by appending the following string to the base command:
...&id=1&drain=In this case, before taking the server offline we don’t only want the number of active connections to be zero, but also for all sessions to end. That translates to the server being idle for some amount of time, which depends on the application. We can periodically check the dashboard or use the status API to determine that the server is idle, but we can also automate the process of marking a server drain and verifying it is idle before marking it down.
I’ve created the following Python program called server-drain-down.py as an example. It takes the upstream group name and the IP address and port of the server as input, and marks the specified server with drain. It then marks the server down after either it has been idle for 60 seconds, or 5 minutes have elapsed since session draining began (even if the server isn’t idle). The program uses the status API to get the timestamp of the last request sent to the server and the number of active connections. It uses the configuration API to mark the server with drain and then down.
#!/usr/bin/env python
################################################################################
# Copyright (C) 2016 NGINX, Inc.
#
# This program is provided for demonstration purposes only and is not covered
# by your NGINX Plus support agreement.
#
# It is a proof of concept for automating the process of taking a server offline
# when it is configured for session persistence.
#
# This program takes two command line-arguments:
# - upstream group name
# - server IP address and port
#
# It uses the NGINX Plus status API to get the server's ID and the
# upstream_conf API to set the state of the server to 'drain'. It then loops,
# waiting to mark the server down until either it has been idle for a
# configured period of time or a configured maximum time has elapsed (even if
# the server is not idle).
################################################################################
import requests
import json
import sys
import time
if len(sys.argv) != 3:
print "Error: Wrong number of arguments. Usage is:"
print " server-drain-down.py "
sys.exit(1)
upstream=sys.argv[1]
server=sys.argv[2]
# The URL for the NGINX Plus status API
statusURL = 'http://localhost:8080/status'
# The URL for the NGINX Plus reconfiguration API
confURL = 'http://localhost:8080/upstream_conf'
# The time the server needs to be idle before being marked down, in seconds
maxIdleTime = 60
# The total elapsed time before marking the server down even if it isn't idle,
# in seconds
maxTime = 300
sleepInterval = 1
client = requests.Session() # Create a session for making HTTP requests
################################################################################
# Function sendRequest
#
# Send an HTTP request. Status 200 is expected for all requests.
################################################################################
def sendRequest(url):
try:
response = client.get(url) # Make an NGINX Plus status API call
if response.status_code == 200:
return response
else:
print ("Error: Response code %d") %(response.status_code)
sys.exit(1)
except requests.exceptions.ConnectionError:
print "Error: Unable to connect to " + url
sys.exit(1)
################################################################################
# Main
################################################################################
url = statusURL + '/upstreams/' + upstream + '/peers'
response = sendRequest(url)
nginxstats = json.loads(response.content) # Convert JSON to dict
id = ""
state = ""
serverFound = False
for stats in nginxstats:
if stats['server'] == server:
serverFound = True
id = stats['id']
state = stats['state']
# The last time a request was sent to this server, converted to seconds
lastSelected = stats['selected'] / 1000
break
if not serverFound:
print("Server %s not found in Upstream Group %s") %(server, upstream)
sys.exit(1)
if state == 'down':
print "The server is already marked as down"
sys.exit(0)
elif state == 'unhealthy' or state == 'unavailable':
# The server is not healthy so it won't be receiving requests and can be
# marked down
url = confURL + '?upstream=' + upstream + '&id=' + str(id) + '&down='
response = sendRequest(url)
print "The server was unhealthy or unavailable and has been marked down"
sys.exit(0)
if state == 'up':
print "Set server to drain"
url = confURL + '?upstream=' + upstream + '&id=' + str(id) + '&drain='
response = sendRequest(url)
startTime = int(time.time())
while True: # Loop forever
now = int(time.time())
totalTime = now - startTime
if totalTime >= maxTime:
print "Max time has expired. Mark server as down"
url = confURL + '?upstream=' + upstream + '&id=' + str(id) + '&down='
response = sendRequest(url)
break
idleTime = now - lastSelected
if idleTime >= maxIdleTime:
if nginxstats['active'] == 0:
print "Idle time has expired. Mark server as down"
url = confURL + '?upstream=' + upstream + '&id=' + str(id) + '&down='
response = sendRequest(url)
break
else:
print("Idle time has expired but there are still active "
"connections. %d max seconds") %(totalTime)
else:
print("Server idle for %d seconds. %d max seconds") %(idleTime, totalTime)
url = statusURL + '/upstreams/' + upstream + '/peers/' + str(id)
response = sendRequest(url)
nginxstats = json.loads(response.content)
lastSelected = nginxstats['selected'] / 1000
time.sleep(sleepInterval)
Whether we use the program or verify manually that the server is idle, after it is marked down we proceed as in the previous section: take the server offline, do the upgrade, and mark it as up to return it to service.
Using Health Checks to Upgrade an Individual Server
Recall that we set up a health check with the health_check directive in the first server block we configured in Base Configuration for the Use Cases. Now we use it to control server state. The health check succeeds if the server returns the file healthcheck.html with an HTTP 2xx or 3xx response code.
# In the first server block
location @healthcheck {
internal;
proxy_pass http://demoapp;
health_check uri=/healthcheck.html;
} When we want to take a server offline, we simply rename the file to fail‑healthcheck.html and health checks fail. NGINX Plus stops sending any new requests to the server, but allows existing requests to complete (equivalent to the down state set with the API). After making the health check fail, we use the dashboard or the status API to monitor the server as we did when using the API to mark the server down. We wait for connections to go to zero before taking the server offline to do the upgrade. When the server is ready to return to service, we rename the file back to healthcheck.html and health checks once again succeed.
As previously mentioned, with health checks we can make use of the slow-start feature if the server requires some warm-up time before it is ready to receive its full share of traffic. Here we modify the servers in the upstream group so that NGINX Plus ramps up traffic gradually during the 30 seconds after they come up:
# In the HTTP context
upstream demoapp {
zone demoapp 64K;
server 172.16.210.81:80 slow_start=30s;
server 172.16.210.82:80 slow_start=30s;
sticky cookie srv_id expires=1h domain=.example.com path=/;
}Conclusion
NGINX Plus provides operations and DevOps engineers with several options for managing software and hardware upgrades on individual servers while continuing to provide a good customer experience by avoiding downtime.
Check out the other two articles in this series:
- An overview of the upgrade methods
- Upgrading to a new version of an application by switching traffic to completely different servers or upstream groups
Try NGINX Plus out for yourself and see how it makes upgrades easier and more efficient – start a 30‑day free trial today or contact us for a live demo.
The post Using NGINX Plus for Backend Upgrades with Zero Downtime, Part 2 – Individual Servers appeared first on NGINX.
Source: Using NGINX Plus for Backend Upgrades with Zero Downtime, Part 2 – Individual Servers


Leave a Reply