출처 : http://meetup.toast.com/posts/55
본 내용은 NHN엔터테인먼트의 정성환 님께서 작성하신 내용입니다.
연재
리눅스 서버의 TCP 네트워크 성능을 결정짓는 커널 파라미터 이야기 – 1편
리눅스 서버의 TCP 네트워크 성능을 결정짓는 커널 파라미터 이야기 – 2편
목차 – 3편
5. TIME_WAIT socket
5.1 TIME_WAIT 상태의 소켓이 무엇일까요?
5.2 TIME_WAIT socket buckets
5.3 TIME_WAIT socket reuse (TW_REUSE)
5.4 TCP timestamp
5.5 TIME_WAIT socket recycling (TW_RECYCLE)
5.6 Socket linger option
6. 결론
7. 맺으며
8. FAQ
5. TIME_WAIT socket
앞서 말씀드린 대로, TIME_WAIT 상태의 소켓은 가용한 local port 수를 경감시켜 동시에 가질 수 있는 클라이언트 소켓 수를 제약합니다.
본 장에서는 이러한 TIME_WAIT 상태의 소켓에 대해 이야기하도록 하겠습니다.
5.1 TIME_WAIT 상태의 소켓이 무엇일까요?
그렇다면, 정확히 TIME_WAIT 상태의 소켓은 언제 발생할까요?
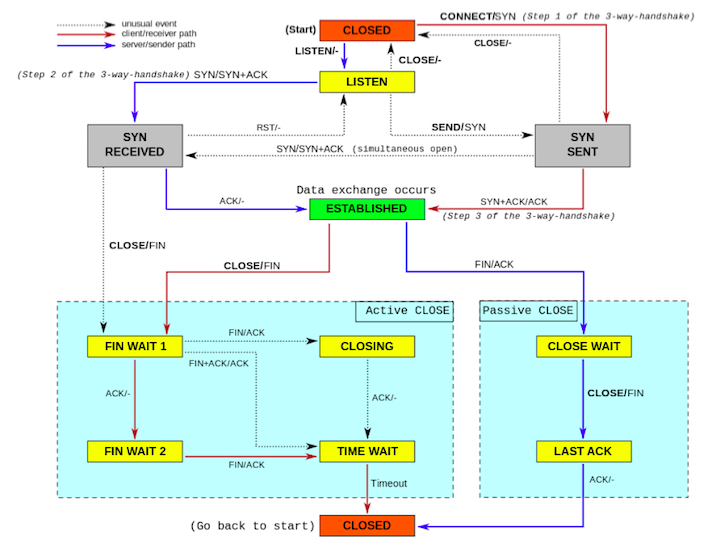
먼저, TCP 소켓 상태 전이도를 살펴봅시다. 아래 그림은 위키피디아에서 찾아 볼 수 있는 TCP 소캣 상태 전이도입니다.
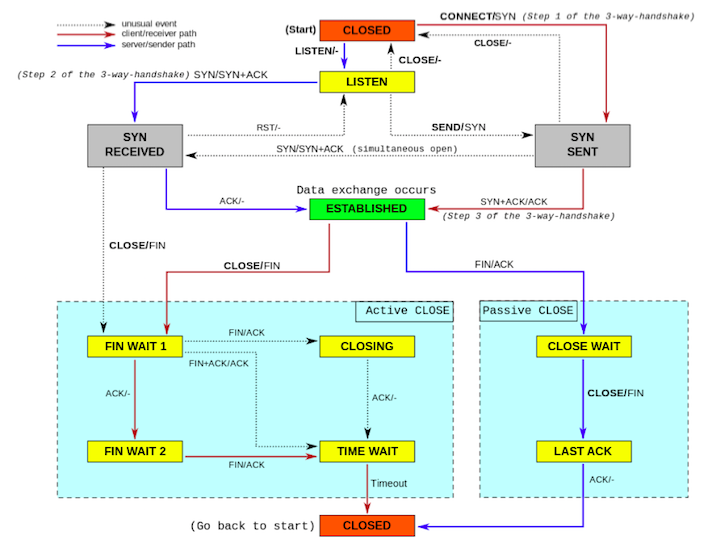
위 그림에서 알 수 있듯이, active closing 하는 소켓의 마지막 종착지가 TIME_WAIT 상태입니다.
바꾸어 말하면, 클라이언트 소켓이든 서버 소켓이든 close() 시스템 콜을 먼저 호출한 쪽(active closing)이 최종적으로 가게됩니다.
이후 TIME_WAIT 상태에서는 RFC793에 정의대로라면 2MSL(Maximum Segment Lifetime), 즉 2분 동안 대기하게 됩니다.
그런데, 실제로 대부분의 OS에서는 최적화를 위해 1분 정도를 TIME_WAIT 상태에서 대기하도록 구현되어 있습니다.
리눅스도 이 시간을 1분으로 규정하고 있고, 변경이 불가능합니다. (커널 코드에 상수로 정해져 있습니다.)
일부 구글에서 찾아볼 수 있는 문서에는 ’net.ipv4.fin_timeout’을 수정하면, TIME_WAIT에서 대기하는 시간을 수정 가능하다고 말하고 있는데요.
’net.ipv4.fin_timeout’은 FIN_WAIT_2 상태에 머무를 수 있는 최대 시간을 설정합니다.
(RFC에서는 TIME_WAIT 상태 외에는 별도 timeout을 정의하고 있지 않지만, 대부분의 시스템에서는 최적화를 위해 별도 timeout 시간을 둡니다.)
실제 세계에서 FIN_WAIT_2에 머무르는 소켓은 매우 드물고, 어차피 자연스레 TIME_WAIT 상태로 전이되기에 이 설정값은 기본으로 두어도 큰 문제가 없습니다.
한가지 강조하고 싶은 것은, TIME_WAIT 상태는 ’잘못된’ 상태가 아니라는 것 입니다.
소켓의 지극히 정상적인 생명 주기 중 한 상태이며, 소켓의 gracefully shutdown을 보장하는 불가결한 요소입니다.
그리고 느슨히 결합된 네트워크 특성상 소켓은 되도록 gracefully shutdown 되어야 데이터의 유실 등의 문제가 없습니다.
먼저, 웹 서버를 예로 들어 TIME_WAIT 상태의 소켓을 확인해 보도록 하겠습니다.
HTTP keepalive 옵션을 사용하지 않는 웹서버가 있다고 합시다.
이 서버에 가서 다음과 같은 명령어를 사용하면 현재 TIME_WAIT 상태의 소켓을 확인할 수 있습니다.
$ netstat -n -t | grep 'TIME_WAIT'
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp6 0 0 10.77.57.106:10080 10.77.94.26:37901 TIME_WAIT
tcp6 0 0 10.77.57.106:10080 10.77.94.26:37900 TIME_WAIT
tcp6 0 0 10.77.57.106:10080 10.77.94.26:37905 TIME_WAIT
tcp6 0 0 10.77.57.106:10080 10.77.56.86:41811 TIME_WAIT
tcp6 0 0 10.77.57.106:10080 10.77.56.82:48168 TIME_WAIT
위 예제는 서버 포트 10080을 사용하는 웹서버에서 발생한 TIME_WAIT 상태의 소켓들입니다.
HTTP 1.1에서는 스펙상 누가 먼저 소켓을 끊을지 정의하고 있지 않습니다.
하지만 일반적인 구현에서 keepalive 설정을 사용하지 않는다면, 서버에서 클라이언트로 데이터를 전송 후 즉시 close() 시스템 콜을 불러 연결을 끊습니다.
그래서 위 경우처럼 서버에 TIME_WAIT 상태의 소켓이 남게 되는 것 입니다.
그렇다면, 이 경우(서버 소켓에서 TIME_WAIT이 발생하는 경우) TIME_WAIT 소켓이 많아지는 것이 문제가 될까요?
결론부터 말하자면, 아주 크게는 문제 되지 않는다는 것 입니다.
5.2 TIME_WAIT socket buckets
먼저, 어떤 시스템이 가질 수 있는 TIME_WAIT 상태 소켓 개수 제한을 확인해 봅시다.
’net.ipv4.tcp_max_tw_buckets’ 커널 파라미터에 이 값이 설정되어 있습니다.
다음과 같은 명령어로 이 설정값을 확인할 수 있습니다.
$ sysctl net.ipv4.tcp_max_tw_buckets
net.ipv4.tcp_max_tw_buckets = 65536
이 시스템에서 TIME_WAIT 상태의 소켓은 동시에 65,536개 존재할 수 있습니다.
그렇다면, 만약 TIME_WAIT 상태의 소켓 개수가 이보다 많아지면 어떻게 될까요? 서버 애플리케이션에 문제가 발생할까요?
TIME_WAIT 상태의 소켓은 위 설정된 값 보다 많아질 수 없습니다.
이미 이 설정값 만큼의 TIME_WAIT 상태의 소켓이 있다면, TIME_WAIT 상태로 전이되어야 할 소켓은 더이상 대기하지 않고 파괴(destroy)되어 버립니다.
즉, gracefully shutdown하지 않고 과격하게 닫혀버리는 것이지요. 그리고 서버 애플리케이션은 이를 알지 못합니다.
일반적으로 이런 경우, 소켓은 파괴되고 ’/var/log/messages’와 같은 곳에 다음과 같은 로그 메시지가 남을 것입니다.
TCP: time wait bucket table overflow
이렇게 파괴된 소켓은 TCP의 gracefully shutdown 원칙에 벗어나지만, 서버 성능이나 수용량에 큰 영향을 주지 않습니다.
그러나, 소켓이 gracefully shutdown 되지 않으므로 서버에서 클라이언트로 아직 내보내지지 않는 데이터도 즉시 사라지게 됩니다. 이 경우, 클라이언트에서는 불완전한 데이터를 수신하게 될 수 있습니다.
따라서, 되도록 소켓은 gracefully shutdown 되어야 하며, 요청량이 많은 서버의 경우 이 값을 적당히 높여두는 것이 좋습니다.
역시 메모리양이 주요 trade-off 요인이기에, 상대적으로 메모리 양이 충분한 서버라면 적당히 높여도 문제 되지 않습니다.
다음과 같은 명령어로 적당량 증가 시킵니다.
$ sysctl -w net.ipv4.tcp_max_tw_buckets="1800000"
또 한가지 의문을 가져볼 수 있는데, 어떤 특정 foreign address와 foreign port를 가지는 소켓이 TIME_WAIT 상태에 있다고 할 때 똑같은 주소와 포트로 클라이언트에서 연결 요청이 오면 어떻게 될까요?
RFC 1122에서는 같은 주소와 주소를 사용하는 TIME_WAIT 상태의 소켓이 있더라도, SYN을 받으면 이 소켓을 재사용하도록 되어 있습니다. 때문에, 특별한 다른 설정이 없어도 문제 될 것이 없습니다.
정리하자면, 서버 소켓만 있는 서버에서는 TIME_WAIT 소켓이 많아지더라도 성능 및 수용량 측면에서는 문제가 없습니다.
이러한 유형의 서버인 경우, TIME_WAIT 소켓 수에 크게 민감할 필요가 없습니다.
다만, TCP 소켓은 되도록 gracefully shutdown 되어야 하므로 ’net.ipv4.tcp_max_tw_buckets’ 커널 파라미터를 적당히 상향할 수 있겠습니다.
5.3 TIME_WAIT socket reuse (TW_REUSE)
그런데, 대규모 서비스에서는 웹서버라고 할지라도 다른 서버에 질의하는 경우가 있습니다. 이 경우, 서버는 또 다른 서버의 클라이언트가 되는 것이지요.
이럴때는 TIME_WAIT 상태의 소켓 개수가 성능에 영향을 미칠 수 있습니다.
어떤 서버가 다른 서버로 질의하는데, 별도의 connection pool을 두지 않고 HTTP RESTful API로 질의한다고 가정합시다.
그리고 이때 HTTP keepalive를 사용하지 않는다고 가정합시다.
가정한다고 했지만, 굉장히 일반적으로 사용되는 형태일 것 입니다. 일반적으로 TCP keepalive의 경우 L4 스위치에 의해 무용지물이 되기에 대개는 사용하지 않기 때문입니다.
이 때 TIME_WAIT 상태의 소켓 수가 local port를 선점하여 생성할 수 있는 클라이언트 소켓 개수를 제한시키며, 이는 다시 말해 다른 서버에 동시 질의할 수 있는 연결 수를 줄입니다. 최악의 경우 다른 서버로 1분내 질의 수가 가질 수 있는 ephemeral port 수보다 많으면, HTTP 연결 시점에 요청은 실패할 것입니다.
그럼 이러한 경우 어떻게 해야 할까요? 그리고 이미 필요 없는 소켓을 닫았을 뿐인데, 이 때문에 새로운 소켓을 만들지 못하는 것이 합당할까요?
이를 해소하기 위한 방법으로는 크게 네가지 정도가 있을 것 입니다.
(1) 애플리케이션에서 connection pool을 사용
성능과 유연성면에서 가장 추천하는 방법이지만, 애플리케이션을 고쳐야 합니다.
(2) TW_REUSE 옵션을 사용
사용할 수 있는 local port 수가 모자라면, 현재 TIME_WAIT 상태의 소켓 중 프로토콜상 사용해도 무방해 보이는 소켓을 재사용합니다.
(3) TW_RECYCLE 옵션을 사용
TIME_WAIT 상태에 머무르는 시간을 변경하여 TIME_WAIT 상태의 소켓 수를 줄입니다. 1분 대신 RTO(Retransmission Timeout) 시간만큼으> 로 TIME_WAIT 상태에 머무르는 시간이 경감되는데, 리눅스에서는 200ms까지 이 시간이 줄 수 있습니다. (최소 RTO가 200ms)
(4) Socket linger 옵션을 굉장히 짧은 시간을 매개변수로 주어 사용
FIN 대신 RST를 보내게 유도하며, 이 때 소켓을 파괴하여 소켓이 TIME_WAIT 상태에 머무르지 않게 합니다.
TW_RECYCLE, socket linger 옵션은 TW_REUSE 보다는 상대적으로 과격한 방법이며 되도록 권장하지 않습니다. 관련된 내용은 이후 별도의 절에서 서술하겠습니다.
TW_REUSE를 사용하려면 ’net.ipv4.tcp_tw_reuse’ 커널 파라미터를 설정해야 합니다.
그런데, 위에서 소개한 대로 TW_REUSE는 특정 상황에서만 TIME_WAIT 상태의 소켓을 재사용하게 되는데요. 이 판단 로직에서는 TCP timestamp라는 확장 옵션을 사용합니다. 때문에, TW_REUSE 옵션을 활성화 하려면 먼저 TCP timestamp 옵션도 활성화 되어야 합니다.
TCP timestamp가 사용되면 TIME_WAIT 상태의 소켓에 통신이 이루어진 마지막 시간(timestamp)를 기록할 수 있습니다.
TW_REUSE 옵션을 활성화 한 상태에서 클라이언트 소켓 생성시, TIME_WAIT 상태의 소켓 중 현재 timestamp 보다 확실히 작은 값의 timestamp를 가지는 소켓은 재사용(reuse) 할 수 있습니다.
일반적으로 리눅스에서 timestamp의 단위는 초 이므로, TIME_WAIT 상태로 전이된지 1초 이후의 소켓들은 재사용 할 수 있게 됩니다.
다음과 같은 명령어로 TW_REUSE 옵션을 활성화 할 수 있습니다.
$ sysctl -w ipv4.tcp_timestamps="1"
$ sysctl -w net.ipv4.tcp_tw_reuse="1"
한가지 유의할 점은, TW_REUSE 옵션은 통신을 하는 양측 모두 TCP timestamp 옵션이 설정되어 있어야 활성화된다는 것 입니다.
한쪽에 TCP timestamp 옵션이 활성화 되지 않은 경우, TIME_WAIT 상태의 소켓을 재사용 할 수 없습니다.
5.4 TCP timestamp
TCP에서는 sequence number로 패킷의 순서(ordering)을 판별합니다. 이 값은 32비트 unsigned int 형으로 0에서 약 40억까지의 표현범위를 가지고
그런데, 매우 빠른 네트워크 환경이 있다고 가정해 봅시다. 그리고 불행히도 receiver는 이 네트워크보다는 조금 느린 처리 속도를 가지고 있다고 가정해 봅시다.
이런 상황에서 sequence number는 중첩(wrapping) 될 수 있습니다.
예를 들자면, 어느 순간 receiver는 어느 sender로부터 100이라는 sequence number를 가진 패킷을 받았다고 합시다.
이후 receiver는 100 이상의 sequence number를 가지는 패킷들을 기대합니다.
이후 receiver는 순식간에 40억개 이상의 패킷이 수신 되었다고 합시다. 그런데 아직 receiver는 이 패킷들을 까보지 않았습니다.
NIC, 즉 네트워크 어댑터에 의해 수신되었으나 아직 커널의 TCP stack에서는 이 패킷을 열어보지 않은 상태입니다. (10G의 네트워크라면 불가능한 일이 아닙니다.)
이 때 마지막쯤 수신된 패킷의 sequence number는 unsigned int 형의 표현 범위 때문에 필시 overflow 되었을 것입니다.
편의상 TCP stack이 까봐야할 패킷의 sequence number가 101~4,294,967,296까지, 그리고 이후 overflow되어서 0~200 이라고 가정합시다.
receiver는 100 이상의 sequence number를 기대하고 있었는데, 이보다 작은 수인 0~100의 sequence number를 받은 상황이 됩니다.
즉 순서(ordering)에 위배되므로 이 패킷들은 새로 수신된 패킷임에도 불구하고 조용히 버려집니다. (silently dropped)
또, 이 경우 중복된 sequence number의 패킷도 존재하게 되는데요. 예컨대 sequence number가 101인 패킷이 두 개 존재합니다.
네트워크 상 패킷은 reordering될 수 있음을 감안한다면, 이 두 개의 패킷의 선후 관계를 확정 지을 수 있을까요?
당연히 확정할 수 없습니다. TCP stack의 구현에 따라 다르겠지만, 둘 중 어느 한 패킷은 버려질 것입니다.
이러한 문제, 즉 wrapped sequence number 문제를 해결하기 위해, RFC 1323에서는 PAWS(Protection against Wrapped Sequence Numbers)라는 방법을 제안합니다.
이는 reordering을 판별하는 요소에 sequence number 뿐만 아니라 timestamp 값을 사용하겠다는 것입니다.
PAWS가 구현된 TCP stack은 timestamp가 포함된 어느 패킷을 받았을 때 이 timestamp를 기록해두며 connection 별로 관리합니다.
이름에서 유추할 수 있듯이 timestamp는 단방향으로 증가되는 어느 값입니다. 일반적으로 timestamp는 밀리초(millisecond) 단위로 system clock에서 가져다 쓰는 경우가 많습니다.
여기서 한가지 생각해 볼만한 것이 있는데요. 그럼 sender와 receiver간 통신에서 이 timestamp 값이 동기화(synchronization)되어 있어야 할까요?
결론부터 이야기 하자면 그럴 필요가 없습니다. 사실 timestamp는 단방향으로 증가하는 어느 값이면 되며 system clock과 연동될 필요가 없습니다. 논리적으로는 sequence number의 high order로서 사용되기 때문입니다.
timestamp를 둔다면, 위와 같은 예제(단시간에 sequence number가 overflow되는 상황)에서 새로 수신한 패킷을 버리는 문제를 해결 할 수 있습니다.
sequence number가 중첩(wrap)되었더라도 timestamp는 더 높은 값이기에 새로 수신된 패킷이라고 인지할 수 있습니다.
(위에서 언급한대로 sequence number의 high order라 생각하면 쉽게 이해될 것 같습니다.)
리눅스에서 TCP timestamp를 사용하기 위해서는 ’net.ipv4.tcp_timestamps’라는 커널 파라미터를 1로 설정해야 합니다.
현재 설정값을 확인하려면 다음과 같은 명령어를 사용할 수 있습니다.
$ sysctl net.ipv4.tcp_timestamps
최신의 일반적인 리눅스 배포판에서는 기본값으로 활성화되어 있습니다.
참고로, 올바르게 동작하려면 sender/receiver 모두 활성화 상태이어야 합니다.
5.5 TIME_WAIT socket recycling (TW_RECYCLE)
TW_REUSE 옵션보다 과격한 방법은 TW_RECYCLE 옵션을 사용하는 것입니다.
TW_RECYCLE은 소켓이 TIME_WAIT 상태에 머무르는 시간을 RTO 만큼 재정의하게 되는데요.
RTO 시간은 RTT에 영향을 받으며, 일반적으로 1분 보다는 짧습니다.
다음과 같은 명령어로 TW_RECYCLE 옵션을 활성화 할 수 있습니다.
$ sysctl -w ipv4.tcp_timestamps="1"
$ sysctl -w net.ipv4.tcp_tw_reuse="1"
$ sysctl -w net.ipv4.tcp_tw_recycle="1"
TW_RECYCLE 옵션을 활성화하려면, 먼저 TCP timestamp와 TW_REUSE를 활성화시켜야 하는 것에 유의해야 합니다.
그런데, TW_RECYCLE은 크게 권장하지 않습니다.
클라이언트가 NAT 환경인 경우 일부 클라이언트로 부터의 SYN 패킷이 유실될 수 있기 때문입니다.
즉, TW_RECYCLE 사용시 일부 TCP 연결 요청은 실패하게 됩니다.
왜 이런 현상이 발생할까요?
TW_RECYCLE 사용시, TIME_WAIT 상태로 대기하는 시간이 극히 짧아져 TIME_WAIT에 남아 있는 소켓이 거의 없다고 해도 될 것 입니다. (물론 peer가 timestamp를 사용하지 않는다면 남아있습니다.) 그렇지만, 커널은 되도록 TIME_WAIT 상태의 소켓이 있는 것처럼 행동해야 하려 합니다. 소켓의 gracefully shutdown을 보장하기 위해서죠.
예를 들어, 어떤 소켓이 있고 active closing 되었다고 합시다. TIME_WAIT 상태에서 매우 짧은 시간 머무른 후 삭제될 것 입니다. 이윽고 같은 foreign address / port로 부터 연결 요청이 와서 새로운 연결이 맺어졌습니다.
이때 sequence number가 역전된 패킷이 도착했다고 합시다.
그런데, 이 패킷이 이전에 연결이 끊어진 소켓에 대한 패킷인지, 지금 연결이 맺어진 소켓에 대한 패킷인지 알 수 있을까요? 이런 경우에 어떻게 해야 할까요?
이러한 문제점을 해결하기 위해 TW_RECYCLE 옵션을 사용하면 TIME_WAIT 상태의 소켓이 있는 것처럼 몇가지 모사를 하게 됩니다. 이러한 로직을 간단히 서술하면 아래와 같습니다.
(1) TIME_WAIT 상태로 들어가면, 다른 구조체에 현재 소켓의 foreign address와 timestamp 값을 기록합니다.
(2) 해당 foreign address/port의 패킷이 오면, (1) 과정에서 알고 있는 timestamp와 대조하여 이보다 작은 timestamp라면 조용히 버려버립니다.
(3) 이 구조체에 저장된 값은 원래 TIME_WAIT 상태로 체류하는 시간 만큼(즉 1분) 유지됩니다.
즉, timestamp가 역전된 패킷은 버립니다.
그런데, 위에서 설명한대로 timestamp는 peer 별로 동기화되어 있지 않습니다. NAT를 사용하는 클라이언트들은 서버 입장에서는 모두 같은 주소를 사용하는 것처럼 보일 것입니다. 그런데, 보내는 패킷의 timestamp는 각 클라이언트 별로 다른 값을 가질 수 있습니다. 때문에 기존 소켓이 마지막으로 기록한 패킷의 timestamp 값이 새로이 소켓 연결을 요청하는 SYN 패킷에 포함된 timestamp 보다 클 수 있습니다. 그리고 이 경우, 위에서 서술한대로 조용히 버려지게 될 것 입니다.
특히, front-end 서버에서는 TW_RECYCLE 옵션을 (절대) 사용하면 안되는데, 이 서버는 주로 인터넷에서 수신되는 클라이언트의 요청을 받게될 것이기 때문입니다.
인터넷의 클라이언트들은 NAT 환경일 확률이 큽니다. 3G/LTE 등의 모바일 네트워크 환경은 일종의 거대한 NAT 환경이고요, 중국과 같이 IP가 모자라는 환경인 경우 NAT를 많이 사용 할 것 입니다. 이런 경우, 많은 수의 클라이언트에서 서버로 접속 못하는 장애가 발생할 수 있습니다.
5.6 Socket linger option
TIME_WAIT 상태의 소켓을 줄이는 또 하나의 ”극단적” 방법은, 극히 짧은 시간(극단적으로 0초)으로 linger 옵션을 활성화하는 것 입니다.
소켓당 설정할 수 있는 옵션인데, 기본 설정은 비활성화입니다.
원래 TCP 소켓은 close() 호출하는 거의 즉시 반환됩니다. 그리고 소켓을 닫기 위한 실제 동작(아직 소켓 버퍼에 남아 있는 데이터를 보낸다던가, FIN/ACK를 보낸다던가)은 커널에 의하여 진행 되죠. 이 소켓은 결국 TIME_WAIT 상태가 되어 주어진 시간(리눅스에서는 1분) 대기하게 됩니다.
linger 옵션은 close()의 반환을 즉각적으로 하지 않고, 즉 non-blocking으로 반환되지 않고 blocking manner로 처리하겠다는 것을 의미합니다. 애플리케이션은 close()시 linger 옵션 활성화시 주어진 매개변수 시간까지 block 됩니다. 이 시간 동안 커널은 소켓 버퍼에 남아 있는 데이터들을 내보내려 노력합니다. 그리고 주어진 시간안에 이러한 처리가 완료되면, 즉 정상 처리되면 일반적인 방법과 똑같이 커널은 FIN을 보내고 소켓도 결국 TIME_WAIT 상태가 되죠. 그러나 주어진 시간내 정상 처리되지 못하면, 커널은 FIN 대신 RST을 보내고 즉시 소켓은 파괴됩니다.
TIME_WAIT 상태의 소켓을 줄이는 극단적인 방법은, 이 linger 옵션에서의 block 될 수 있는 시간을 ’0’으로 설정하는 것 입니다. 그러면, close()시 커널은 한순간도 기다리지 않고 FIN 대신 RST를 보내며 소켓을 파괴할 것입니다. 때문에 TIME_WAIT 상태의 소켓도 남아있지 않는 것이죠.
그러나, linger 옵션은 결코 TIME_WAIT 상태의 소켓을 제거하기 위한 옵션이 아닙니다. 데이터를 peer에게 완전히 전달(delivery)하기 위해 애플리케이션에 보다 통제권을 주는 하나의 옵션일 뿐이죠. 일반적인 처리에서 소켓은 커널에 의해 gracefully shutdown하는 것이 올바릅니다.
이렇게까지 하는 저변에는 TIME_WAIT 상태의 소켓을 해악으로 보기 때문인 것 같습니다.
그러나 패킷의 reordering이나 유실이 있을 수 있는 네트워크의 특성상, 소켓은 되도록 gracefully shutdown 되어야 합니다.
이번장에서 반복해서 말씀드리는 건, TIME_WAIT 상태의 소켓은 크나큰 해악이 아니라는 것입니다. 소켓이 정상 종료되는 과정인 것이지요.
서버 소켓에서는 일반적으로 아무런 문제가 없으며, 클라이언트 소켓이라도 TW_REUSE 옵션으로 극복이 가능합니다.
TW_REUSE 옵션이 사용 불가능한 극히 예외적인 상황(예를 들어, timestamp를 사용하지 않는 다수의 서버와 통신)에서라도 TW_RECYCLE, linger 옵션 같은 극단적인 처치는 지양해야 할 것 입니다. 이러한 경우에 정말로 TIME_WAIT 상태의 소켓 개수가 성능의 병목점이라면, keepalive를 사용하거나, connection pool 등을 구현하는 등 애플리케이션 자체를 고쳐야 할 것 입니다.
6. 결론
생각보다 꽤 긴 글이 되었는데, 적당히 요약하자면 다음과 같습니다.
- TCP 대역폭을 증가시키려면 receive window size를 늘려야 한다.
$ sysctl -w net.ipv4.tcp_window_scaling="1" $ sysctl -w net.core.rmem_default="253952" $ sysctl -w net.core.wmem_default="253952" $ sysctl -w net.core.rmem_max="16777216" $ sysctl -w net.core.wmem_max="16777216" $ sysctl -w net.ipv4.tcp_rmem="253952 253952 16777216" $ sysctl -w net.ipv4.tcp_wmem="253952 253952 16777216" - 애플리케이션에서 알지 못하는 네트워크 패킷 유실을 방지하기 위해서는 in-bound queue 크기를 늘려야 한다.
$ sysctl -w net.core.netdev_max_backlog="30000" $ sysctl -w net.core.somaxconn="1024" $ sysctl -w net.ipv4.tcp_max_syn_backlog="1024" $ ulimit -SHn 65535 ` - TIME_WAIT 상태의 소켓은 일반적으로 서버 소켓의 경우 신경쓸 필요 없지만, 다른 서버로 다시 질의하는 경우(예를 들어 프록시 서버) 성능을 제약할 수 있으며 이 상황에서 TW_REUSE 옵션은 고려할 만 하다. (TW_RECYCLE 옵션은 NAT 환경에서 문제가 있고, socket linger 옵션은 데이터 유실이 있을 수 있으니 사용하지 말자.)
$ sysctl -w net.ipv4.tcp_max_tw_buckets="1800000" $ sysctl -w ipv4.tcp_timestamps="1" $ sysctl -w net.ipv4.tcp_tw_reuse="1"다시금 말하자면, 모든 워크로드를 만족하는 설정값은 있을 수 없습니다. 위 파라미터 값들은 본문에서 예시를 든 값을 그대로 옮겨온 것에 불과합니다.
보다 정밀히 튜닝하기 위해서는 서버 애플리케이션 특성(워크로드)에 대해 보다 자세히 알아둘 필요가 있습니다.
7. 맺으며…
글을 쓰다보면, 단편적인 지식이 문장이 되고 다시 그 문장들이 모여 하나의 장이 되는 것을 경험하게 되는데요.
그 와중에 미처 들춰보지 못했던 지식의 치부들을 곧잘 발견하게 됩니다.
충분히 이해했다고 생각했던 부분이 사실은 전부 이해하지 못했으며, 옳다고 생각했던 부분이 사실은 그르다는 것을 발견하는 것이지요.
특히 TCP 소켓의 timewait과 관련된 부분은 굉장히 빈번한 오해를 사는 일이 많아서 한번쯤 정리하고 싶었는데요.
국내에도 저와 비슷한 생각을 가진 분들이 몇 있어, 올해(2015년)에 잘 작성된 글을 2건이나 찾을 수 있었습니다.
http://docs.likejazz.com/time-wait/
https://brunch.co.kr/@alden/3
충분히 이해했다고 생각했던 부분에서 발견된, 사실은 이해한 게 없었던 지식의 치부들은 위 글들을 참고하여 어느 정도 가려진 것 같습니다.
긴 글 읽어주셔서 고맙습니다!
8. FAQ
Q1) 언급하신데로 최근 서버의 경우 cubic 방식을 많이 사용하는데요. 이전에 많이 사용되던 reno 로 커널 컴파일 없이 변경해서 사용할 수 있나요? 만약 가능하다면 몇가지 알고리즘을 제공하는 지도 궁금합니다.
A1)
현재 즉시 사용 가능한 congestion control algorithm 목록은 다음과 같이 확인할 수 있습니다.
$ cat /proc/sys/net/ipv4/tcp_available_congestion_control
(OR) $ sysctl net.ipv4.tcp_available_congestion_control
제가 사용하는 ubuntu 14.04.2 LTS에서는 기본적으로 cubic, reno가 탑재되어 있는데요.
현재 congestion control algorithm을 변경하려면 다음과 같이 하면 됩니다.
$ echo "reno" > /proc/sys/net/ipv4/tcp_congestion_control
(OR) $ sysctl -w net.ipv4.tcp_congestion_control="reno"
tcp congestion control algorithm은 pluggable kernel module로 되어 있습니다.
위 목록 외 가용한 목록을 찾으려면 다음과 같은 명령어를 사용할 수 있습니다.
ls /lib/modules/`uname -r`/kernel/net/ipv4/
여기서 tcp_vegas.ko, tcp_westwood.ko와 같은 파일들이 TCP congestion control algorithm을 구현하는 커널 모듈인데요.
다음과 같이 별다른 조치 없이 이 목록에 있는 커널 모듈들을 사용할 수 있습니다.
echo "westwood" > /proc/sys/net/ipv4/tcp_congestion_control
(OR) $ sysctl -w net.ipv4.tcp_congestion_control="westwood"
그리고 ’sysctl net.ipv4.tcp_available_congestion_control’ 명령을 사용하면 위에서 추가된 알고리즘이 이 목록에도 추가되어 있음을 알 수 있습니다.
References
http://www.tldp.org/HOWTO/Linux+IPv6-HOWTO/proc-sys-net-ipv4..html
https://developers.google.com/speed/articles/tcp_initcwnd_paper.pdf
http://tools.ietf.org/html/draft-ietf-tcpm-initcwnd-00
http://www.cdnplanet.com/blog/tune-tcp-initcwnd-for-optimum-performance/
http://d2.naver.com/helloworld/47667
http://packetbomb.com/understanding-throughput-and-tcp-windows/
http://stackoverflow.com/questions/8893888/dropping-of-connections-with-tcp-tw-recycle
http://blogs.technet.com/b/thenetworker/archive/2008/04/20/of-tcp-sequence-numbers-and-paws.aspx
http://unix.stackexchange.com/questions/210367/changing-the-tcp-rto-value-in-linux
http://vincent.bernat.im/en/blog/2014-tcp-time-wait-state-linux.html
http://veithen.github.io/2014/01/01/how-tcp-backlog-works-in-linux.html
https://www.frozentux.net/ipsysctl-tutorial/chunkyhtml/tcpvariables.html


Leave a Reply