현대자동차, Amazon SageMaker 기반 자율 주행 기계 학습 모델의 학습 시간 단축 사례
현대자동차는 세계에서 가장 큰 자동차 제조업체 중 하나이며, 최근에 자율 주행차를 직접 개발하기 위해 다양한 인적 및 물적 자원을 많이 투자하고 있습니다.
자율 주행에서 자주 사용되는 알고리즘 중 하나로, 이미지의 모든 픽셀에 클래스를 할당하는 작업인 의미 분할(semantic segmentation)이라는 것이 있습니다. 여기서 클래스는 도로, 사람, 자동차, 건물, 풀과 나무, 하늘 등이 될 수 있습니다. 현대자동차 개발팀은 개발 과정에서 정기적으로 정확도를 테스트하고, 그 결과 특정 상황에서의 예측 성능을 수정하기 위해 학습 이미지를 추가로 수집합니다. 하지만, 개발 일정을 맞추려면 학습에 필요한 시간을 남기면서 새로운 데이터를 준비할 시간이 부족한 경우가 많았습니다.
Amazon ML Solutions Lab 팀은 현대 자동차와 함께 확장성 높은 AWS 클라우드를 사용하여 모델 학습을 더 빠르게 해서 이 문제를 해결했습니다. 이 글에서는 기계 학습(ML) 관리 서비스인 Amazon SageMaker에 새롭게 포함된 데이터 병렬 처리를 위한 SageMaker 라이브러리를 사용한 사례를 공유합니다.
솔루션 개요
Amazon SageMaker는 분산 컴퓨팅 인프라를 관리하고, 모델 학습 작업을 모니터링 및 디버깅하는 “높은 부담의 작업”을 줄여 고객 문제를 해결하는 완전 관리형 기계 학습 플랫폼입니다. SageMaker 데이터 병렬 처리 라이브러리와 Amazon SageMaker 디버거 를 사용하여 현대자동차의 기술적 과제를 해결하고 비용 효율적으로 비즈니스 목표를 달성할 수 있었습니다.
SageMaker는 데이터 병렬 처리 및 모델 병렬 처리를 위한 분산 학습 라이브러리를 제공합니다. 이 경우, 학습중인 모델은 단일 GPU의 메모리에 맞더라도 학습 데이터의 양이 클 경우 학습 시간이 너무 오래 걸립니다. 이런 경우, 데이터 병렬 분산 학습을 사용하면 학습 작업의 전체 시간을 줄일 수 있습니다. SageMaker 데이터 병렬 처리는 학습 데이터를 여러 GPU 인스턴스로 분산하고 할당 된 데이터 세트를 사용하여 각 GPU에서 동일한 모델을 학습합니다. SageMaker 데이터 병렬 처리 라이브러리는 더 많은 GPU를 사용하면서 거의 선형에 가까운 확장성을 제공하는 고속 AWS 네트워크 인프라를 활용하도록 설계되었습니다.
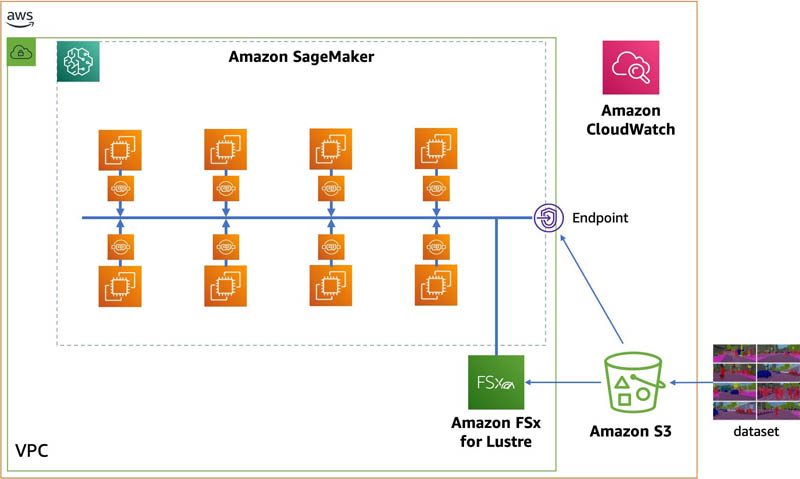
이번에 사용한 모델 학습 아키텍처에서는 Amazon SageMaker를 사용하고, 일시 데이터 저장을 위해 Amazon FSx for Lustre, 영구적인 데이터 저장에 Amazon S3서비스를 활용합니다. PyTorch 기반의 모델 학습을 데이터 병렬 처리 라이브러리을 활용하여 단 몇 줄의 학습 코드만으로 8개의 GPU 인스턴스 또는 총 64개의 GPU를 사용하여 최대 93%의 확장 효율성을 달성했습니다. 다음 다이어그램은 분산 학습을 위해 배포된 AWS 아키텍처를 보여줍니다.

단일 GPU를 사용하여 모델을 학습하는 것과는 다르게, 다중 또는 분산 GPU 학습에서는 단일 GPU에서 관찰되지 않은 성능 문제가 나타날 수 있습니다. 따라서, 고가의 GPU 리소스를 최대한 활용하고 원하는 모델 성능을 달성하려면 학습 지표와 함께 리소스 사용률을 모니터링하는 것이 중요합니다.
Amazon SageMaker 디버거 및 프로파일링 기능을 통해 딥 러닝 과학자 및 엔지니어는 학습 작업이 실행되는 동안에 시스템 관련 또는 모델 관련 성능 문제를 모니터링, 추적 및 분석 할 수 있습니다. 디버깅 출력을 활성화하기 위해서 학습 코드를 변경할 필요가 없습니다. 실시간 모니터링 및 시각화는 Amazon SageMaker Studio 에서 제공하며, 커스텀 시각화 또는 분석을 위한 API 호출을 통해 수집된 디버깅 및 프로파일링 데이터를 액세스 할 수 있습니다. 진행 중인 학습이 진행되고 있는 중에 SageMaker 프로파일러를 켜거나 끄고, 또는 프로파일링 구성을 변경하여 디버거의 프레임워크 수준 프로파일링 기능으로 인한 부하를 최소화 하는 것도 가능합니다.
SageMaker 데이터 병렬 처리 라이브러리를 사용한 분산 모델학습
Amazon SageMaker 데이터 병렬 처리 라이브러리를 사용하려면, SageMaker의 DistributedDataParallel 클래스로 모델을 래핑(wrapping)하는 간단한 코드 변경만 필요합니다. 아래 코드 예제는 PyTorch 학습 스크립트의 모델을 어떻게 적용하는지 보여줍니다. API 사용법은 PyTorch의 DistributedDataParallel와 거의 유사합니다.
여러분이 만약 PyTorch 또는 TensorFlow 분산 학습 방식에 익숙하다면, 분산 학습을 위해 클러스터를 설정하는 방법과 클러스터의 각 인스턴스에서 학습 프로세스를 시작하는 방법이 궁금하실 것입니다. Amazon SageMaker에서 해야 할 일은, 인스턴스 개수와 인스턴스 유형을 지정하고 SageMaker가 사용할 분산 학습 전략을 알려주는 것입니다. SageMaker는 이 정보를 바탕으로 필요한 구성을 자동으로 처리하며, 이 방법은 PyTorch와 TensorFlow 모두에 적용됩니다. 다음 예제 코드를 참조하십시오.
이제 학습 스크립트를 업데이트 했으므로, Amazon S3 버킷에 있는 데이터 세트를 액세스하는 방법을 결정해야 합니다. 가장 일반적인 방법은 학습 작업이 시작될 때 SageMaker가 S3 버킷에서 학습 인스턴스에 연결된 스토리지 또는 내부 NVMe SSD 스토리지로 데이터 세트를 복사하도록 하는 것입니다. 이러한 방법은 매번 학습마다 학습 인스턴스의 스토리지에 다시 복사해야 합니다(이 방법을 SageMaker 파일 모드라고 합니다).
여기서 사용한 데이터 세트는 총 300GB이고 파일 수가 많았습니다. 모델 학습을 시작하기 전에 학습 인스턴스로 데이터 복사를 완료하는 데 약 1시간이 걸립니다. 실제 학습 스크립트는 이 단계가 완료된 후에만 실행됩니다. 며칠, 몇 주 또는 그 이상이 걸리는 대규모 학습에서는 이런 데이터 복사 시간을 무시할 수 있을 것입니다. 하지만, 반복적인 학습 수행이 필요한 개발 및 테스트 단계에서는 이 시간을 줄이는 것이 중요합니다.
데이터 복사로 인해 학습 시작 속도가 느려지는 것을 피하기 위해 다음 조치 중 하나를 취할 수 있습니다.
- 데이터 세트의 크기 줄이기
- 데이터를 복사하는 대신 스트리밍하는 SageMaker 파이프 모드 사용
- Amazon S3에서 데이터를 복사하는 대신 Amazon FSx for Lustre를 사용하기
저희는 반복되는 실험을 위해 FSx for Lustre 파일 시스템을 선택했습니다. S3 버킷에 있는 데이터를 사용하여 FSx for Lustre 파일 시스템을 생성하고, 이 파일시스템을 학습 인스턴스에 연결했습니다. FSx for Lustre 파일 시스템은 (모델 학습 인스턴스에 연결된 스토리지와 달리) SageMaker 모델 학습 작업 후에도 삭제되지 않기 때문에 초기화 지연 없이 여러번 실험을 실행할 수 있습니다.
코드 변환을 완료하고 학습 코드가 문제 없이 실행되고 있는지 확인한 후, 최적의 I/O 성능을 위해 내부 NVMe SSD 스토리지를 사용할 수 있도록 파일 모드로 전환합니다. 이 작업은 SageMaker의 구성을 변경해서 쉽게 할 수 있고, 학습 스크립트에 대한 코드 변경은 필요하지 않습니다. 아래 코드를 참조하세요.
모델 학습 성능 분석 및 조정
Amazon SageMaker 디버거를 사용하기 위해 학습 코드를 변경할 필요가 없습니다. 디버거는 에스티메이터(Estimator)를 정의 할 때 구성되거나, 학습 작업이 실행되는 동안 SageMaker Studio 또는 Debugger API를 통해 활성화/비활성화됩니다. 학습 작업 성능을 전체적으로 파악하기 위해 SageMaker 에스티메이터를 통해 CPU 사용률, GPU 사용률, GPU 메모리 사용률 및 I/O 대기에 대한 디버거 시스템 프로파일링을 500 밀리 초 간격으로 활성화했습니다. ProfilerConfig를 에스티메이터에 설정하는 방법은 다음과 같습니다.
저희는 비정상적인 패턴을 찾기 위해 SageMaker 디버거가 수집한 데이터를 Studio의 디버거 시각화 기능을 사용하여 시스템 리소스 사용률을 모니터링했습니다. 단일 GPU 학습보다 다중 GPU 학습에서 각 단계에 소요되는 시간이 길었는데, 다중 GPU 모델 학습에서 CPU는 항상 100% 사용되었지만 GPU는 충분히 활용되지 않는 것을 알게 되었습니다. 이 패턴은 학습이 진행되는 동안 SageMaker Studio의 CPU 및 GPU 사용률 히트 맵을 통해 빠르게 식별되었습니다. Python 및 딥 러닝 프레임 워크 수준 프로파일링 출력을 제공하는 디버거의 프레임 워크 프로파일링 기능을 사용하여 근본 원인 분석을 수행 할 수 있습니다.
Amazon ML Solutions Lab과 현대자동차 개발팀은 디버거 데이터 및 학습 코드를 심층 분석하여 사용자 지정 데이터 로더에서 근본 원인을 찾았습니다. 이 문제는 단일 GPU 학습에서는 성능 오버 헤드를 유발하지 않았습니다. CPU 부족 문제가 해결됨에 따라 시스템 리소스 사용률이 정상으로 돌아 왔고 훈련 성능도 향상되었습니다. 이러한 노력으로 동일한 양의 GPU 리소스를 사용하여 다중 GPU 학습 속도를 두 배로 향상 시켰습니다.
다음 그림은 CPU 및 GPU 사용률 그래프와 히트 맵을 보여줍니다. 왼쪽은 문제가 있는 학습에서, 오른쪽은 수정된 학습에서 얻은 것입니다.

마무리
이 글에서는 Amazon SageMaker 데이터 병렬 처리 라이브러리를 사용하여, 자율 주행 모델의 학습 속도를 높이는 방법을 자세히 설명했습니다. 또한, Amazon SageMaker 디버거를 사용해 병목 현상을 식별하고 학습 성능을 최적화하는 실제 기술을 공유했습니다. 그 결과, 단 5배 더 많은 인스턴스로 10배 빠른 학습 속도를 달성할 수 있었습니다.
현대자동차의 최진욱 책임 연구원은 “우리는 컴퓨터 비전 모델을 사용하여 장면 분할을 수행하는데, 이는 장면 이해에 중요합니다. 예전에는 한번 모델을 학습시키는 데 57분이 걸려서, 작업 속도가 빠르지 않았습니다. Amazon SageMaker의 데이터 병렬 처리 라이브러리를 사용하고 Amazon ML Solutions Lab의 도움을 받아 5개의 ml.p3.16xlarge 인스턴스에서 최적화된 모델 코드로 6분 만에 학습을 마칠 수 있었습니다. 학습 시간이 10배 단축되었기 때문에, 한 번의 개발주기에서 데이터를 준비하는데 더 많은 시간을 할애 할 수 있습니다. “라고 이야기해 주셨습니다.
Amazon SageMaker의 관련 기능에 대해 자세히 알아 보려면 다음을 확인하십시오.
Amazon ML Solutions Lab 정보
Amazon ML Solutions Lab 은 AWS의 ML 전문가를 고객과 연결하여, 가치있는 ML 서비스 기회를 식별하고 구현하는 데 도움을 드리고 있습니다. AWS 고객 여러분의 사업에 ML을 더 빠르게 적용하기 위해 도움이 필요하다면 문의해 주세요.
– 김무현, 데이터사이언티스트, Amazon Machine Learning Solutions Lab
– 강지양, 딥러닝 아키텍트, Amazon Machine Learning Solutions Lab
– 최영준, 솔루션즈 아키텍트, AWS
– Aditya Bindal, 시니어 제품 관리자, AWS
– Nathalie Rauschmayr, 응용 과학자, AWS
– 김종모, 연구원, 현대자동차
이 글은 AWS Machine Learning 블로그 Hyundai reduces ML model training time for autonomous driving models using Amazon SageMaker의 한국어 번역입니다.
Source: 현대자동차, Amazon SageMaker 기반 자율 주행 기계 학습 모델의 학습 시간 단축 사례

Leave a Reply