AWS Glue를 활용한 서버리스 스트리밍 ETL 기능 출시
데이터를 분석할 때, 가장 먼저 취하는 방법은 일괄(Batch) 처리 모델입니다. 일정 기간 동안 데이터를 수집한 다음, 분석 도구에 넣는 것입니다. 신속히 대응하려면 스트리밍(Streaming) 모델을 사용할 수 있습니다. 이 모델에서는 데이터가 도착하는 대로 처리하거나, 한 번에 레코드 하나씩 처리하거나, 10개, 100개, 1,000개 단위의 마이크로 배치로 레코드를 처리합니다.
연속적인 입력 파이프라인을 관리하고 즉석에서 데이터를 처리하는 작업은 상당히 복잡한데, 그 이유는 관리와 패치, 확장이 필요하고 전반적으로 돌봐야 하는 상시 가동 시스템이기 때문입니다. 오늘부터 Apache Spark에 기반하여 확장하여 스트리밍 플랫폼(예: Amazon Kinesis Data Streams, Apache Kafka(완전관리형 Amazon MSK 포함))에서 데이터를 연속적으로 실행하고 사용함으로써 이 작업이 더욱 간편해지고 비용이 절감할 수 있게 됩니다.
AWS Glue가 Amazon S3의 데이터 레이크, Amazon Redshift의 데이터 웨어하우스 또는 다른 데이터 스토어에 입력하는 데 필요한 인프라를 프로비저닝, 관리 및 확장할 수 있습니다. 예를 들어 DynamoDB 테이블에 스트리밍 데이터를 저장하여 빠르게 조회하거나, Elasticsearch에 저장하여 특정 패턴을 찾을 수 있습니다. 일반적으로 이 절차를 추출, 변환, 로드(ETL)라고 합니다.
Glue 작업에서 스트리밍 데이터를 처리할 때는 Spark Structured Streaming의 모든 기능을 활용하여 집계, 파티션 나누기, 서식 지정, 다른 데이터 세트와의 결합 등 데이터 변환을 구현하고 간편한 분석을 위해 데이터를 보강 또는 정리할 수 있습니다. 예를 들어 외부 시스템에 액세스하여 실시간으로 허위 정보를 찾아내거나 기계 학습 알고리즘을 적용하여 데이터를 분류하거나 이상 값 또는 상태를 탐지할 수 있습니다.
AWS Glue 스트리밍 데이터 처리
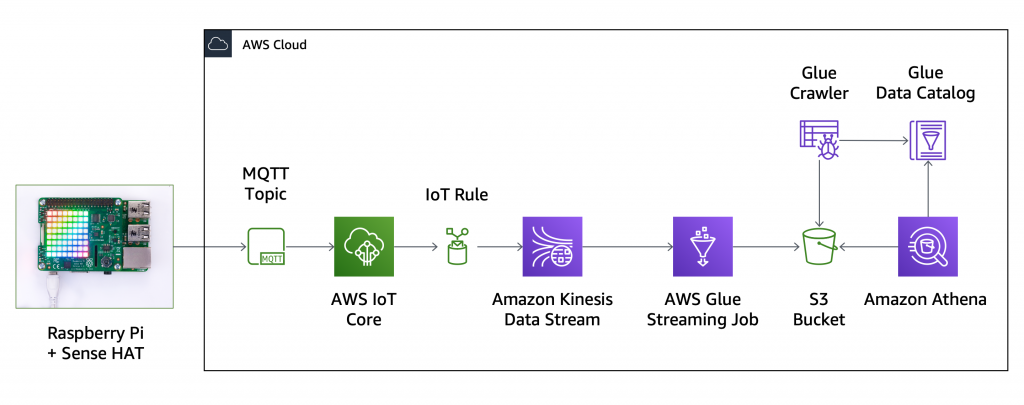
이 새 기능을 사용해보기 위해 IoT 센서에서 데이터를 수집하고 S3 데이터 레이크에 모든 데이터 포인트를 저장하겠습니다. 저는 Sense HAT을 사용하는 Raspberry Pi로 온도, 습도, 기압, 공간에서의 위치를 실시간으로 수집하고 있습니다(내장 자이로스코프, 가속도계, 자기계 사용). 현재 제가 구축하고 있는 솔루션의 설계도입니다.
먼저 AWS IoT Core로 디바이스를 등록하고 다음의 Python 코드를 실행하여 1초에 한 번씩 센서 데이터를 포함한 JSON 메시지를 streaming-data MQTT 주제로 전송합니다. 이 설정에서는 디바이스를 한 개만 사용하지만, 디바이스가 늘어나면 디바이스당 하나의 하위 주제를 사용할 것입니다(예: streaming-data/{client_id}).
import time
import datetime
import json
from sense_hat import SenseHat
from awscrt import io, mqtt, auth, http
from awsiot import mqtt_connection_builder
sense = SenseHat()
topic = "streaming-data"
client_id = "raspberrypi"
# Callback when connection is accidentally lost.
def on_connection_interrupted(connection, error, **kwargs):
print("Connection interrupted. error: {}".format(error))
# Callback when an interrupted connection is re-established.
def on_connection_resumed(connection, return_code, session_present, **kwargs):
print("Connection resumed. return_code: {} session_present: {}".format(
return_code, session_present))
if return_code == mqtt.ConnectReturnCode.ACCEPTED and not session_present:
print("Session did not persist. Resubscribing to existing topics...")
resubscribe_future, _ = connection.resubscribe_existing_topics()
# Cannot synchronously wait for resubscribe result because we're on the connection's event-loop thread,
# evaluate result with a callback instead.
resubscribe_future.add_done_callback(on_resubscribe_complete)
def on_resubscribe_complete(resubscribe_future):
resubscribe_results = resubscribe_future.result()
print("Resubscribe results: {}".format(resubscribe_results))
for topic, qos in resubscribe_results['topics']:
if qos is None:
sys.exit("Server rejected resubscribe to topic: {}".format(topic))
# Callback when the subscribed topic receives a message
def on_message_received(topic, payload, **kwargs):
print("Received message from topic '{}': {}".format(topic, payload))
def collect_and_send_data():
publish_count = 0
while(True):
humidity = sense.get_humidity()
print("Humidity: %s %%rH" % humidity)
temp = sense.get_temperature()
print("Temperature: %s C" % temp)
pressure = sense.get_pressure()
print("Pressure: %s Millibars" % pressure)
orientation = sense.get_orientation_degrees()
print("p: {pitch}, r: {roll}, y: {yaw}".format(**orientation))
timestamp = datetime.datetime.fromtimestamp(
time.time()).strftime('%Y-%m-%d %H:%M:%S')
message = {
"client_id": client_id,
"timestamp": timestamp,
"humidity": humidity,
"temperature": temp,
"pressure": pressure,
"pitch": orientation['pitch'],
"roll": orientation['roll'],
"yaw": orientation['yaw'],
"count": publish_count
}
print("Publishing message to topic '{}': {}".format(topic, message))
mqtt_connection.publish(
topic=topic,
payload=json.dumps(message),
qos=mqtt.QoS.AT_LEAST_ONCE)
time.sleep(1)
publish_count += 1
if __name__ == '__main__':
# Spin up resources
event_loop_group = io.EventLoopGroup(1)
host_resolver = io.DefaultHostResolver(event_loop_group)
client_bootstrap = io.ClientBootstrap(event_loop_group, host_resolver)
mqtt_connection = mqtt_connection_builder.mtls_from_path(
endpoint="a1b2c3d4e5f6g7-ats.iot.us-east-1.amazonaws.com",
cert_filepath="rapberrypi.cert.pem",
pri_key_filepath="rapberrypi.private.key",
client_bootstrap=client_bootstrap,
ca_filepath="root-CA.crt",
on_connection_interrupted=on_connection_interrupted,
on_connection_resumed=on_connection_resumed,
client_id=client_id,
clean_session=False,
keep_alive_secs=6)
connect_future = mqtt_connection.connect()
# Future.result() waits until a result is available
connect_future.result()
print("Connected!")
# Subscribe
print("Subscribing to topic '{}'...".format(topic))
subscribe_future, packet_id = mqtt_connection.subscribe(
topic=topic,
qos=mqtt.QoS.AT_LEAST_ONCE,
callback=on_message_received)
subscribe_result = subscribe_future.result()
print("Subscribed with {}".format(str(subscribe_result['qos'])))
collect_and_send_data()
다음은 디바이스에서 전송한 JSON 메시지의 예시입니다.
{
"client_id": "raspberrypi",
"timestamp": "2020-04-16 11:33:23",
"humidity": 39.35261535644531,
"temperature": 30.10732078552246,
"pressure": 1020.447509765625,
"pitch": 4.044007304723748,
"roll": 7.533848064912158,
"yaw": 77.01560798660883,
"count": 104
}Kinesis 콘솔에서 my-data-stream 데이터 스트림을 생성합니다(제 워크로드는 샤드 1개로도 충분합니다). AWS IoT 콘솔로 돌아와 IoT 규칙을 만든 다음, MQTT 주제의 모든 데이터를 이 Kinesis 데이터 스트림으로 보냅니다.
이제 모든 센서 데이터가 Kinesis로 전송되었으므로 새 Glue 통합을 사용하여 데이터가 도착하는 즉시 처리할 수 있습니다. Glue 콘솔에서 Glue Data Catalog에 수동으로 테이블을 추가합니다. Kinesis를 소스 유형으로 선택하고 스트림 이름과 Kinesis Data Streams 서비스의 엔드포인트를 입력합니다. Kafka 스트림의 경우, 테이블을 생성하기 전에 Glue 연결을 생성해야 한다는 것을 잊지 마십시오.

JSON을 데이터 형식으로 선택하고 스트리밍 데이터의 스키마를 정의합니다. 여기에서 열을 지정하지 않으면 스트림을 처리할 때 무시됩니다.
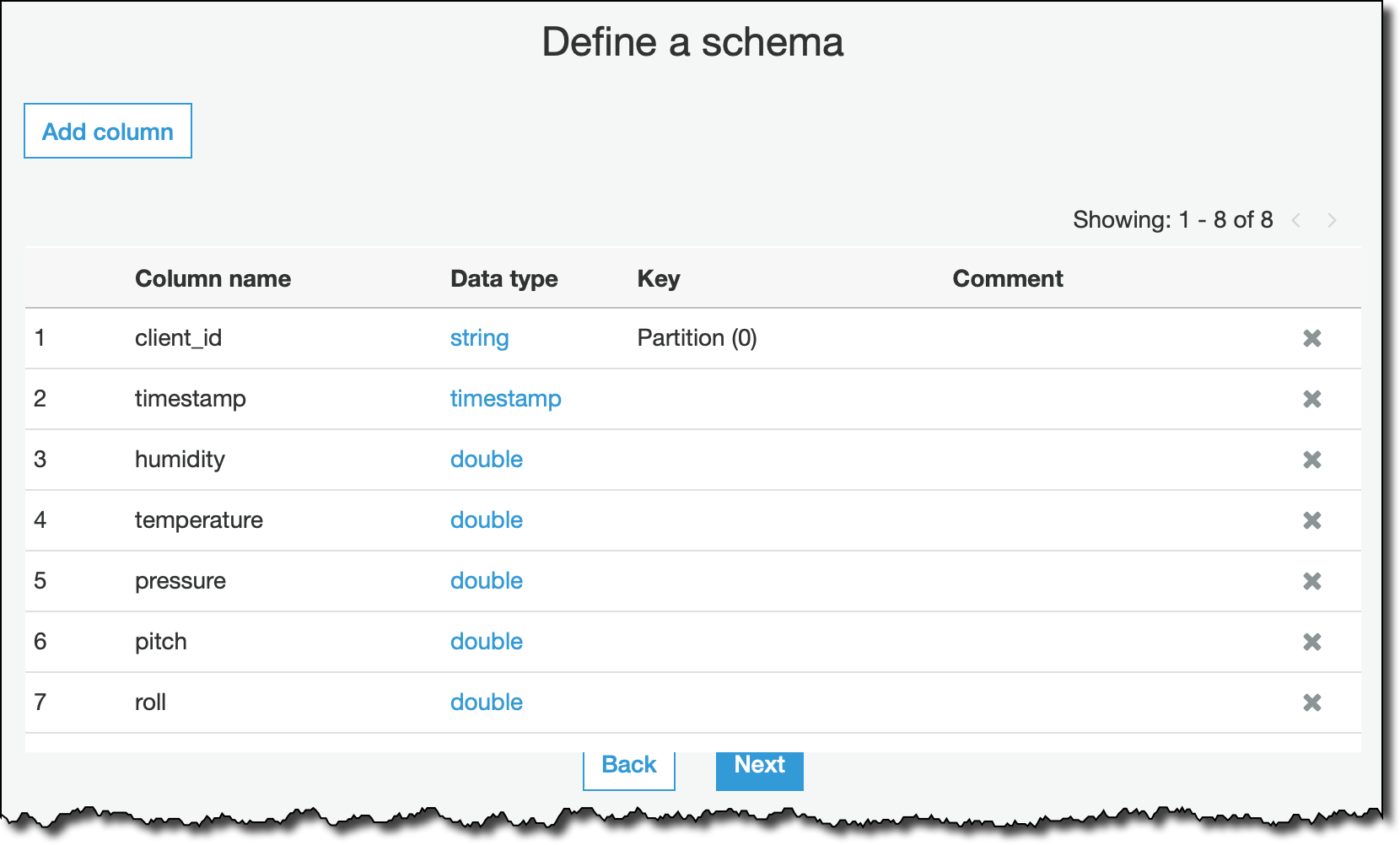
그 후에는 최종 요약 단계를 확인하고 my_streaming_data 테이블을 생성합니다. 현재는 스트리밍 ETL 작업에 스키마 추론을 추가하는 작업을 진행 중입니다. 그러면 전체 스키마를 먼저 지정할 필요가 없습니다. 향후 업데이트를 기다려주십시오.
스트리밍 데이터를 처리하기 위해 Glue 작업을 생성합니다. IAM 역할의 경우, AWSGlueServiceRole과 AmazonKinesisReadOnlyAccess 관리형 정책을 연결하는 새 역할을 생성합니다. 사용 사례와 AWS 계정의 설정에 따라 더욱 세밀한 액세스 관리를 제공하는 역할을 사용해야 할 수도 있습니다.
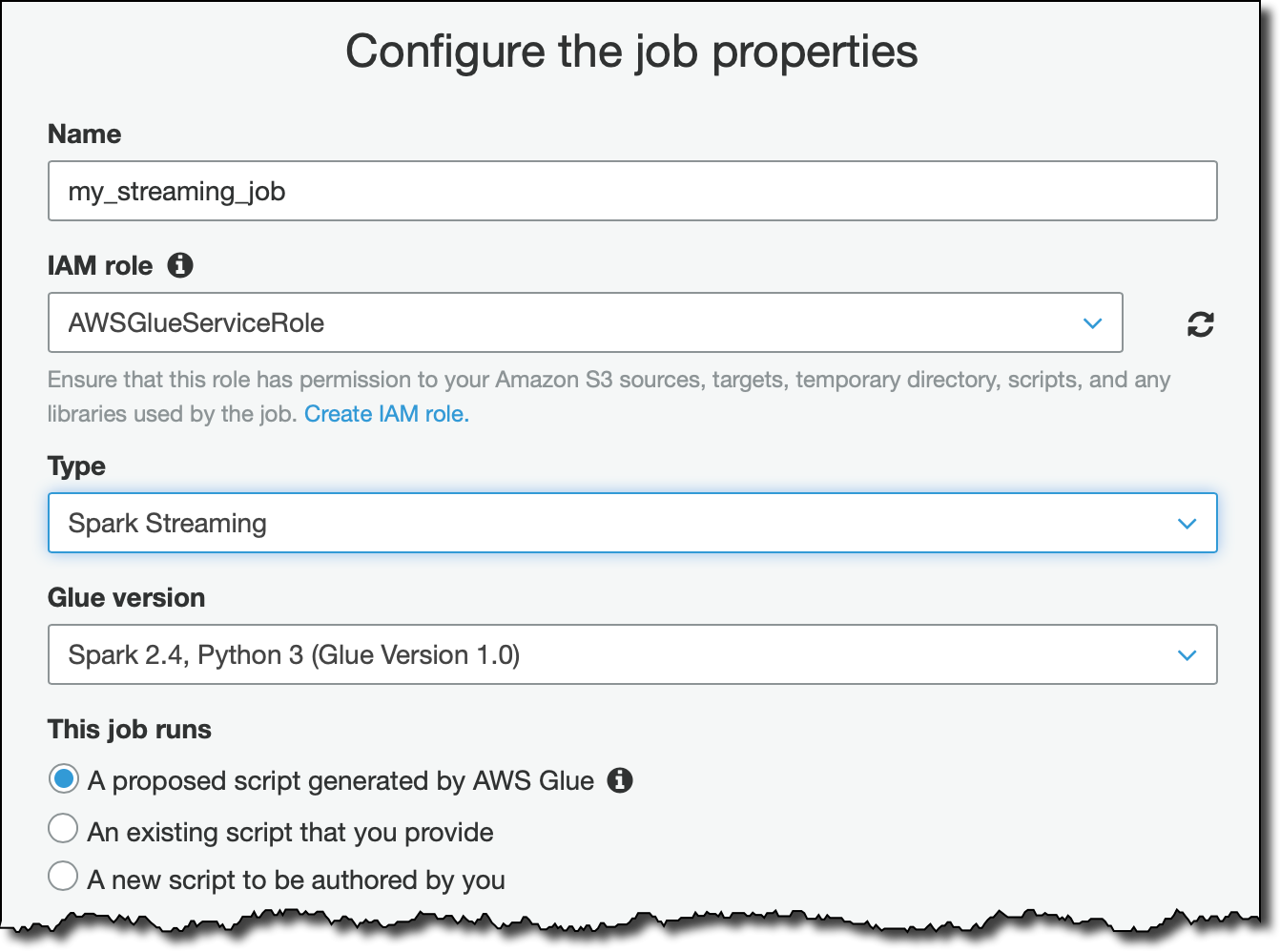
데이터 소스에는 방금 생성한 테이블을 선택하고 Kinesis 스트림에서 데이터를 수신하도록 했습니다.

Glue에서 생성된 스크립트를 얻기 위해 변경 스키마 변환 유형을 선택합니다. 대상으로는 Apache Parquet와 같은 효율적인 형식을 사용하여 Glue Data Catalog에서 새 테이블을 생성합니다. 이 작업으로 생성된 Parquet 파일은 이름이 aws-glue-(마지막 하이픈까지 포함)로 시작되는 S3 버킷에 저장됩니다. AWSGlueServiceRole 정책에 지정된 리소스 이름 지정 규칙을 따르면 해당 리소스에 액세스하는 데 필요한 권한이 이 작업에 부여됩니다.
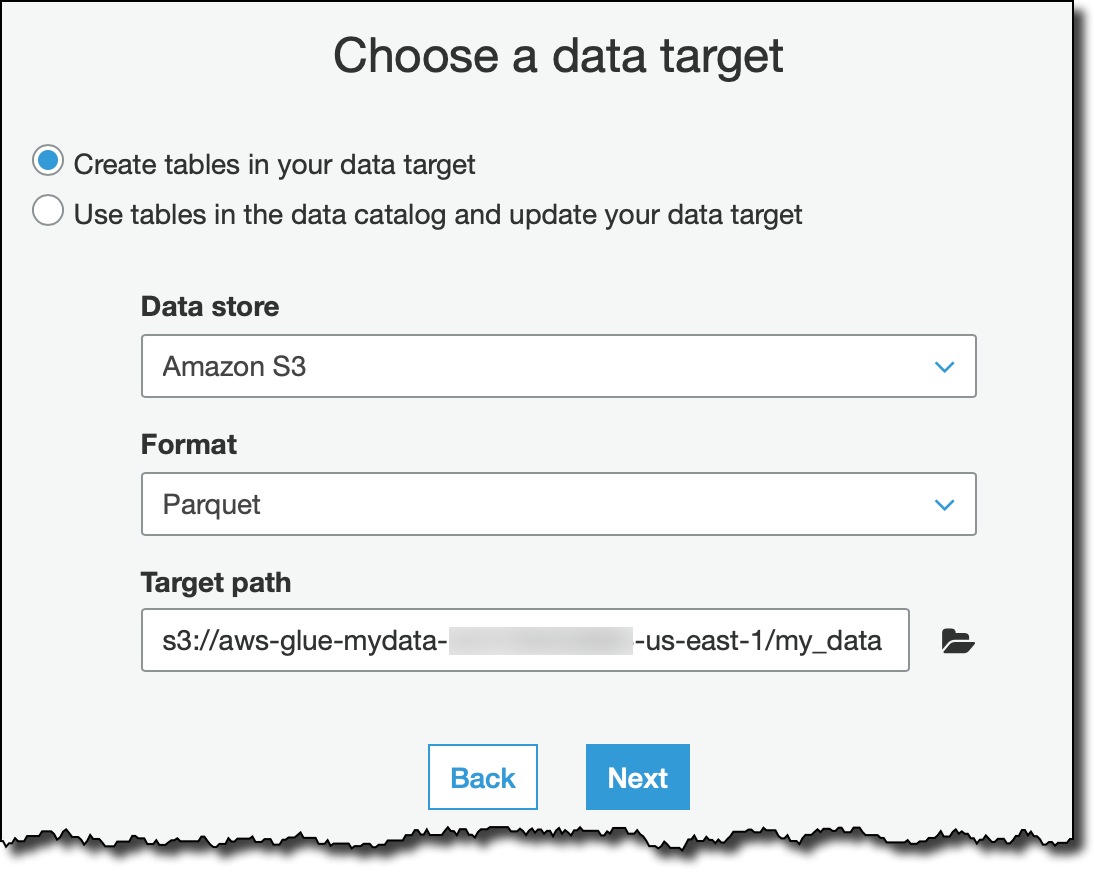
출력에 소스 스트림의 모든 열을 유지하는 기본 매핑을 그대로 사용합니다. 이렇게 하면 코드를 한 줄도 작성하지 않고도 제안된 스크립트를 사용하여 모든 레코드를 입력할 수 있습니다.

제안된 스크립트를 빠르게 검토하고 저장합니다. 각 레코드는 DynamicFrame으로 처리되고, 아무 Glue PySpark Transforms나 Spark Structured Streaming에서 지원되는 변환을 적용할 수 있습니다. 이 구성으로 기본 설정하면 ApplyMapping만 사용됩니다.

작업을 시작하고 몇 분이 지나면 작업 결과가 포함된 Parquet 파일이 출력된 S3 버킷에 나타날 것입니다. 파일은 입력 날짜(연도, 월, 일, 시간)로 파티션이 나뉩니다.
S3 버킷 내용을 기반으로 한 테이블로 Glue Data Catalog를 채우기 위해 크롤러를 추가하고 실행합니다. 크롤러 구성에서 Glue가 사용한 checkpoint 폴더를 제외하여 처리된 데이터를 추적합니다. 그러면 1분 이내로 새 테이블이 추가됩니다.
Amazon Athena 콘솔에서 데이터베이스와 테이블을 새로 고침하고 이번 연도부터 입력 데이터가 포함된 output_my_data 미리 보기를 선택합니다. 이렇게 하면 테이블에 처음 10개의 레코드가 표시되고, 설정이 작동하고 있다는 것을 확인할 수 있습니다!

이제 데이터가 입력되고 있으므로 더욱 복잡한 쿼리를 실행할 수 있습니다. 예를 들어 디바이스 센서에서 수집한 최고 및 최저 온도와 Parquet 파일에 저장된 전체 레코드 수를 알 수 있습니다.
결과를 보면, 8,000개 이상의 레코드가 처리되었고 최고 온도는 섭씨 31도(약 화씨 88도)입니다. 사실, 이렇게 덥지는 않습니다. 온도는 디바이스에 매우 가까이 있는 센서에서 측정되고 디바이스가 사용 중에 뜨거워지면 온도도 상승합니다.

이 설정에서는 디바이스를 한 개만 사용하지만 여기서 구현된 솔루션은 데이터 소스 개수에 따라 손쉽게 확장할 수 있습니다.
지금 이용 가능
스트리밍 소스에 대한 지원은 Glue가 제공되는 모든 리전에서 사용할 수 있습니다(AWS 리전 표 참조). 자세한 내용은 설명서를 참조하십시오.
Glue로 서버리스 ETL 파이프라인을 관리하면 스트리밍 입력 프로세스를 간편하고 비용 효율적으로 설정하고 관리함으로써 구현 작업에 드는 노력이 절감되므로 분석의 비즈니스 결과에만 집중할 수 있습니다. 이 단계별 설명에서 보여드린 것과 같이 전체 입력 파이프라인을 코드 없이 설정할 수도 있고, 필요에 따라 제안된 스크립트를 사용자 지정할 수도 있습니다.
이 새로운 기능을 어디에 사용할지 알려주세요!
— Danilo


Leave a Reply