
Amazon Athena 초간단 사용기
지난 2016년 11월 28일부터 12월 2일에 걸쳐 개최된 글로벌 컨퍼런스 AWS re:Invent 2016에서는 20여개가 넘는 신규 기능 및 서비스가 발표되었습니다. 크게 나눠 보았을때 기존 서비스에 추가된 기능(새로운 EC2 타입 등)을 제외한다면 가장 많은 주목을 받은 부분은 딥러닝에 기반한 인공 지능 서비스(Amazon Rekognition, Polly, Lex 등)들과 데이터에 기반한 분석 서비스였습니다.
이 중 기존에 인프라나 비즈니스 운영을 관리하시는 분들이 가장 많이 관심을 가진 서비스가 바로 Amazon Athena 발표입니다. Athena는 Amazon S3 스토리지에 저장된 다양한 포맷의 기초 데이터, 예를 들어 csv, tsv, txt, CRC, Parquet 등에 대해 바로 표준 SQL 문을 사용해 데이터를 검색 및 분석할 수 있는 서비스입니다.
Amazon Athena의 기반 기술 및 장점
Amazon Athena는 페타바이트 규모의 데이터에 대해 표준 SQL 문에 기반한 질의를 수행할 수 있습니다. S3 를 스토리지로 사용하기 때문에 99.999999999%에 달하는 S3의 내구성이 그대로 데이터에 적용됩니다. 또한 데이터 소스에 대응하는 테이블 메타 정보만 생성하면 바로 쿼리를 수행할 수 있으며, 쿼리 수행 속도 또한 매우 빠릅니다.
가격 또한 매우 큰 이점으로 작용합니다. 매번 쿼리를 수행할 때 스캔하는 데이터의 양에 따라 과금되며, 미리 서버를 준비할 필요가 없어 고정 비용이 발생하지 않습니다. 비용은 S3에서 스캔하는 데이터 1TB당 5 달러입니다.
또한, Athena는 여러 가용영역에 걸친 컴퓨팅 자원을 준비해 두고 여러분의 쿼리를 처리합니다. 아래와 같이 크게 두 가지의 오픈소스 기술이 Athena에 적용되어 있습니다.

[그림 1] Athena의 적용 기반 기술
Presto는 인 메모리 분석 쿼리 엔진으로 ANSI-SQL이 호환됩니다. 또한 Hive는 DDL 관련 기능을 처리하는 것을 담당합니다. 복잡한 데이터 타입, 여러 포맷, 데이터 파티셔닝, 테이블 생성 등과 관련된 부분을 담당합니다.
Athena가 유용한 부분을 살펴보기 위해서는 다른 서비스, 예를 들어 유사한 AWS의 다른 빅 데이터 분석 서비스인 EMR, Redshift 와 어떤 차이점이 있는지 살펴보는 것이 좋겠습니다.
| Athena | EMR | Redshift |
| SQL 지원의 쿼리 서비스 S3에 데이터 존재 바로 실행 서버리스 쿼리 수행에 따른 과금 |
단순 SQL 만이 아니라, 여러 배치 잡을 수행 가능 (딥 러닝 트레이닝, 파일 변환/복사 등) 다양한 플랫폼을 사용해서 워크로드에 따라서 다양하게 구성 할 수 있음 데이터가 반드시 S3 에 있을 필요는 없음. 서버 클러스터 존재 클러스터 시간당 과금 |
여러 데이터 소스에 대해 구조화된 데이터를 집적. 전형적인 D/W 워크로드에 적합. 서버 클러스터 존재 시간당 과금 |
Athena를 적용할 수 있는 대표적인 분야는 각종 로그 분석입니다. 과거 대량 로그 분석에는 EMR 혹은 Redshift를 사용해야 했는데, EMR은 다양한 프레임워크 선택에서, Redshift는 비용에서 상대적으로 사용자가 부담을 가질 수 있었습니다. 이제는 Athena를 통해 손쉽고 저렴하게 분석을 할 수 있습니다.
물론 로그 분석 이외에도 ETL 적용이 부담스럽거나 어려운 워크로드, 기존에 Hive, Spark를 사용했던 워크로드들도 Athena가 대체할 수 있는 대상입니다.
Athena 바로 사용해 보기
서울 리전에 여러분의 데이터가 존재한다고 합시다. 현재 Athena는 2개 리전(버지니아, 오레곤)에서 사용할 수 있습니다. 따라서 서울 리전의 버킷을 버지니아 리전으로 리전간 복제(CRR, Cross Region Replication)합니다. 이것은 버킷의 프로퍼티에서 지정할 수 있습니다. CRR을 하기 위해서는 먼저 버킷의 버저닝을 활성해야 합니다. 활성 버튼을 누르고 나면 그림 2와 같이 설정을 할 수 있습니다.

그림2. CRR 설정
버킷 내 데이터의 양에 따라 다르지만 설정 시점으로부터 최대 24시간 안에 대상 버지니아의 버킷으로 모든 데이터의 복제가 완료됩니다. 이렇게 복제가 완료된 후 Athena에서 데이터베이스와 테이블을 생성하면 됩니다.
예를 들어 로우 데이터가 csv파일이라고 합시다. 여러 파일이 버킷의 특정 폴더에 존재한다면, 데이터 소스를 다음과 같이 지정하면 해당 폴더 안의 파일 전체를 지정하게 됩니다.
S3:<버킷이름>< 폴더이름>
그림 3은 테이블을 새롭게 생성하는 화면입니다. 데이터베이스 이름은 새롭게 생성할 수도 있고 기존의 데이터베이스 이름을 사용할 수도 있습니다.

그림 3. 테이블의 생성
이렇게 테이블을 생성하고 나면, 각 칼럼들을 지정하게 됩니다. 그림 4는 소스 타입을 지정하는 부분입니다.
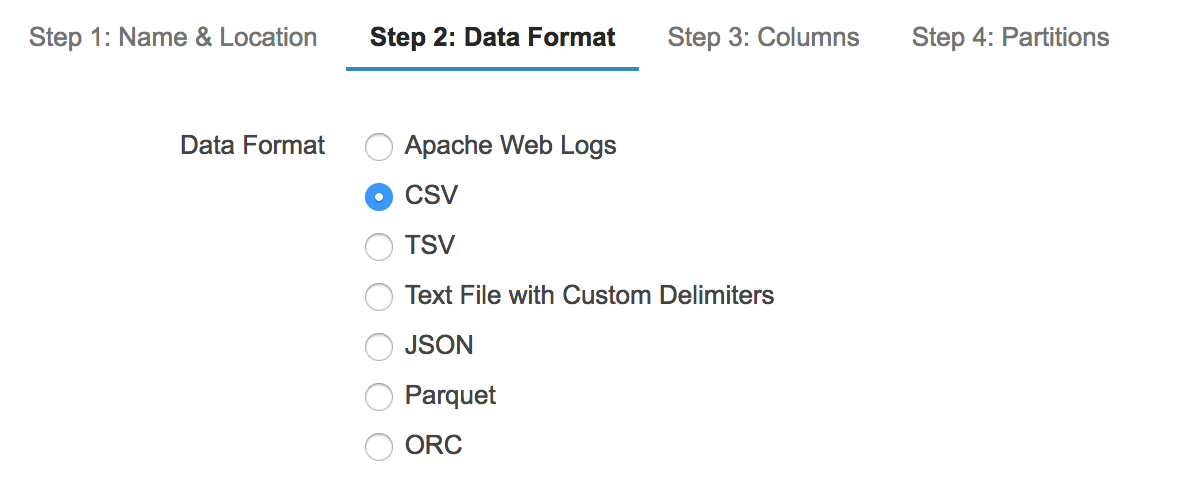
그림 4. 소스 타입 지정
그림 5.는 칼럼을 지정하는 과정입니다. 여기까지만 하면 기본적으로 쿼리를 수행할 수 있습니다.

그림 5. 칼럼 지정
이렇게 만들고 나면 바로 쿼리를 수행할 수 있습니다. 수행의 한 예제가 그림 6입니다.
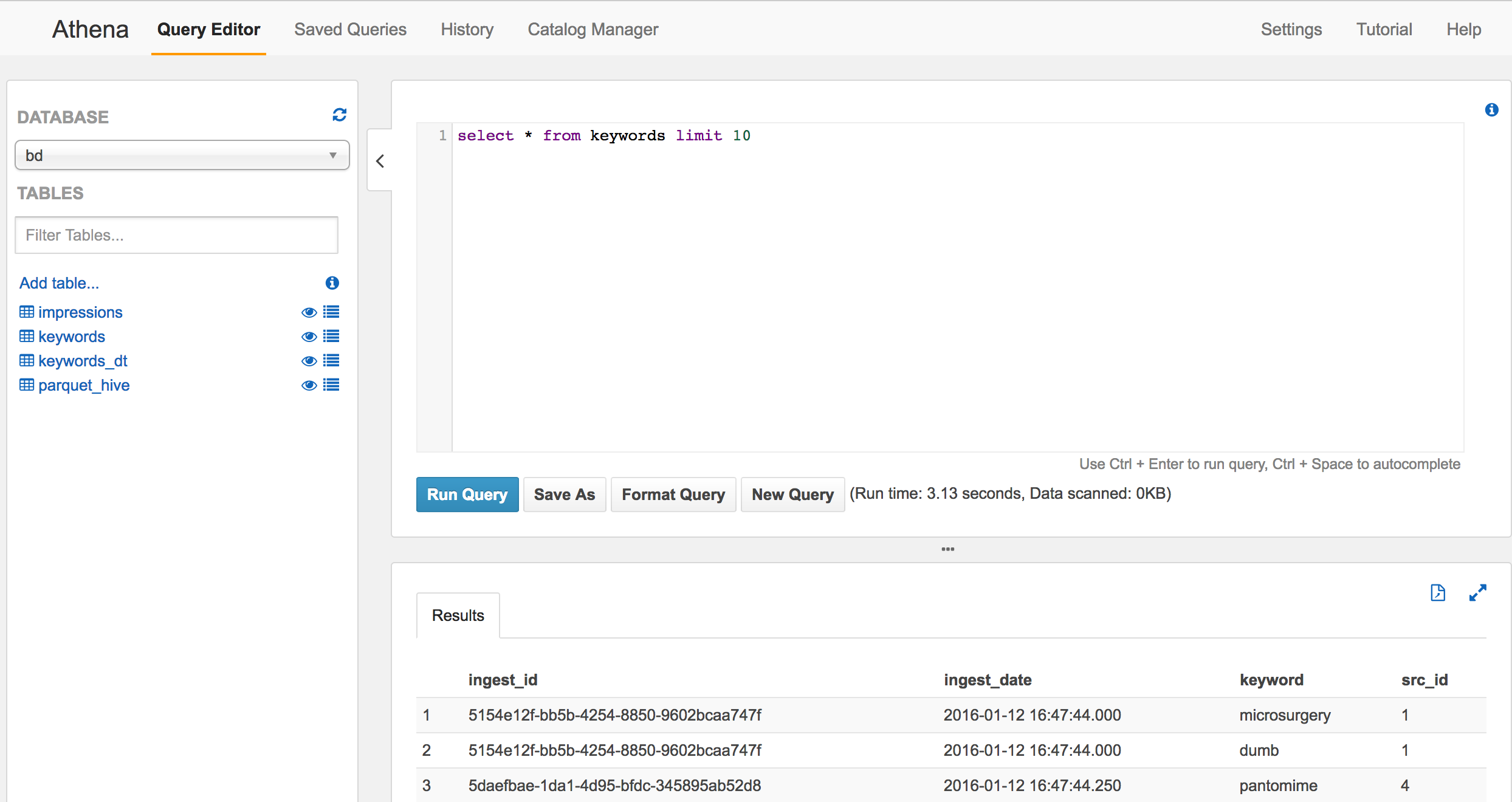
그림 6. 기본 쿼리의 수행
지금까지 Athena의 특성과 다른 서비스와의 비교를 살펴보았습니다. 이제 여러분의 S3 에 존재하는 데이터를 대상으로 바로 쿼리를 사용할 수 있으므로, 보다 손쉽게 데이터 분석과 관리가 가능합니다. 다음 포스팅에서는 Athena 활용에 도움이 되도록 보다 고급 예제, 파티셔닝, CRC, Parquet으로의 전환, 최적화 방법 등에 대해 살펴보도록 하겠습니다.
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁으로, 이번 포스팅은 박선용 솔루션즈 아키텍트께서 작성해주셨습니다.

Source: Amazon Athena 초간단 사용기


Leave a Reply