Amazon Aurora 기능 업데이트 – 병렬 미리 읽기, 고속 인덱싱 , NUMA 인식 등
Amazon Aurora는 현재 가장 빠르게 성장하고 있는 AWS 서비스입니다. 클라우드에 최적화된 관계형 데이터베이스 엔진으로서 Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS는 높은 성능 향상과 최대 64TB까지 원활하게 스토리지 확장 및 견고성과 가용성 향상을 실현하였습니다.
Aurora을 MySQL 호환 엔진으로 디자인함으로써 고객은 기존 애플리케이션을 마이그레이션하거나 새로운 응용 프로그램 구축할 때 더욱 간단하게 접근하실 수 있습니다.오늘 추가로 세 가지 성능을 개선하는 새로운 기능을 Aurora에 추가했습니다. 각각의 기능은 AWS를 많이 이용하는 고객의 일반적인 워크로드에서 Aurora 성능을 최대로 개선하도록 설계되었습니다.
- 병렬 미리 읽기(Parallel Read Ahead) – 구간 선택, 전체 테이블 스캔, 테이블 변경, 인덱스 생성을 최대 5배 빠르게 성능 개선
- 빠른 인덱싱(Faster Index Build) – 인덱스 생성 시간을 약 75% 단축
- NUMA 인식 스케줄링(NUMA-Aware Scheduling) – 두 개 이상의 CPU가 탑재 된 데이터베이스 인스턴스를 사용하는 경우, 쿼리 캐시에서 및 버퍼 캐시에서 읽기 성능 향상 및 전체 처리량이 최대 10 % 향상
한 가지씩 자세히 살펴보겠습니다.
병렬 미리 읽기
MySQL에서 사용되는 InnoDB 스토리지 엔진은 테이블 행이나 인덱스 키(index key)를 이용하는 스토리지(디스크 페이지)를 관리합니다. 이는 테이블의 순차 스캔 속도와 새로 생성 된 테이블에 효과적입니다. 그러나, 테이블 행이 업데이트 혹은 생성 및 삭제되면, 데이터가 파편화됨으로써 물리적으로 더 이상 순차적이지 않고, 스캔 성능이 크게 저하됩니다. InnoDB의 선형 미리 읽기(Linear Read Ahead) 기능은 페이지가 실제로 사용할 때까지 메모리에서 64 페이지까지 정리하여 데이터 파편화에 대처하고 있습니다. 그러나, 일반적으로 엔터프라이즈 규모의 워크로드에서는 이 기능이 성능 향상을 제공하지 않는다고 알려져있습니다.
이번 기능 업데이트에서는 Aurora가 많은 상황에서 현명하게 이러한 상황을 처리할 수 있는 기능을 제공합니다. Aurora의 테이블을 스캔 할 때, 논리적으로 판단하고 병렬로 페이지를 미리 추가합니다. 이러한 미리 추가(pre-fetch)기능은 Aurora의 복제 스토리지 (3개 가용 영역에 각각 2 개씩 복사)에서 우위를 발휘하여, 데이터베이스 캐시중인 페이지가 스캔 작업과 관련 있는지를 판단하는 데 도움이 됩니다.
결과적으로, 구간 검색, 전체 테이블 검색, ALTER TABLE 그리고 index 생성을 이전 버전에 비해 최대 5 배 빠르게 할 수 있습니다.
Aurora 1.7로 업그레이드하면 바로 성능 향상을 경험하실 수 있습니다.
빠른 인덱싱
특정 테이블에 기본(Primary) 및 보조(Secondary) 인덱스를 만들 때, 스토리지 엔진은 새로운 키를 포함해서 트리 구조를 만듭니다. 이 작업은 통해 많은 하향식 트리 검색 및 키의 증가에 대응하기 위해 트리 재구축을 통해 페이지 분할을 하게됩니다.
Aurora는 상향식(bottom-up) 트리 구조를 만듭니다. 리프(leaves)를 먼저 만들고 필요한 만큼 부모 페이지를 추가합니다. 이를 통해 스토리지 이동을 줄이고, 각 페이지가 일단 모두 메워지도록 하여 페이지를 분할 할 필요가 없습니다.
이를 통해 테이블 스키마에 따라 다르지만, 인덱스 추가 또는 테이블 재구성이 최대 4배 빨라집니다. 예를 들어, Aurora 팀이 다음과 같은 스키마에서 테이블을 만들고 1억 행을 추가하여 5GB의 사이즈 테이블을 제작했습니다.
create table test01 (id int not null auto_increment primary key, i int, j int, k int);
그리고 4개의 index를 추가했습니다.
alter table test01 add index (i), add index (j), add index (k), add index comp_idx(i, j, k);
db.r3.large 인스턴스에서 쿼리 실행 시간이 67분에서 25분으로 줄었고, db.r3.8xlarge에서는 29분에서 11.5분으로 단축되었습니다.
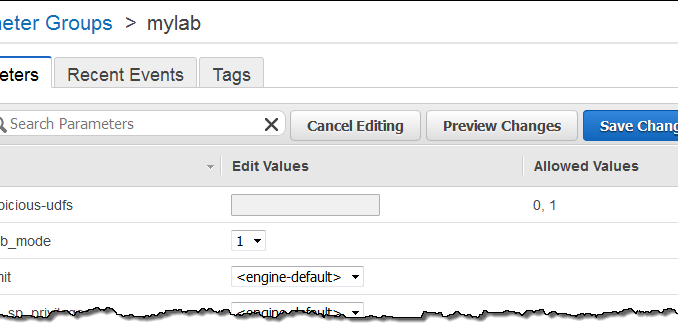
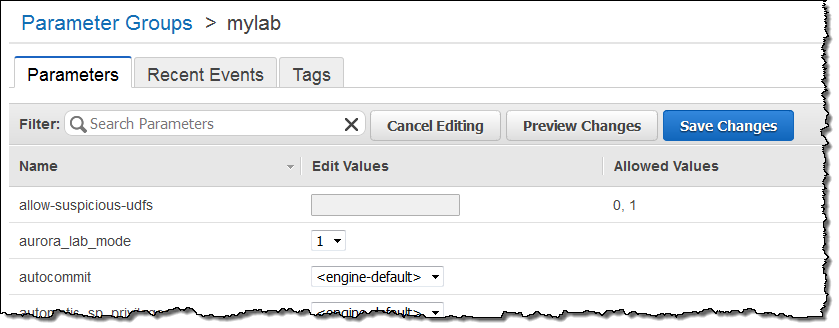
본 신규 기능은 우선 정식 서비스 환경이 아닌 테스트를 먼저 하시길 권장합니다. Aurora 1.7으로 업그레이드 하신 후, DB 인스턴스 파라미터 그룹에서 aurora_lab_mode를 1로 설정합니다. (더 자세한 사항은 DB Cluster and DB Instance Parameters 를 참고하시기 바랍니다.)
본 기능에 대한 질문 및 피드백은 Amazon RDS Forum을 통해 보내주시면 감사하겠습니다.
NUMA 기반 스케줄링
가장 큰 데이터베이스 인스턴스( db.r3.8xlarge )는 2개의 CPU를 탑재하고 있고, 불균일 기억 장치 접근(Non-Uniform Memory Access, NUMA)라는 기능을 가지고 있습니다. 본 유형의 시스템은 메인 메모리 파티션을 각 CPU에서 직접 효율적으로 사용할 수 있습니다. 나머지 메모리는 조금 비효율적 CPU 간의 접근 경로를 통해 사용합니다.
Aurora는이 고르지 못한 접근 시간을 활용하기 위해 스케줄링 스레드의 작업을 효율적으로 처리 할 수 있게 되었습니다. 스케줄링 스레드는 다른 CPU에 연결되어 있는 비효율적인 메모리 접근을 고려할 필요가 없습니다. 결과적으로, 쿼리 캐시와 버퍼 캐시를 많이 사용하는 같은 CPU 바운드 작업에서 최대 10%까지 성능을 향상하였습니다. 동일한 데이터베이스 인스턴스에 수백 또는 수천개의 동시 연결이 되어 있을 때, 현저하게 성능이 높아집니다. 예를 들어, Sysbench oltp.lua 벤치 마크에서 570,000 reads/second에서 625,000 reads/second로 향상되었습니다. 이 테스트에서는 db.r3.8xlarge DB 인스턴스에서 다음 매개 변수를 이용하여 테스트릴 진행했습니다.
oltp_table_count = 25oltp_table_size = 10000num-threads = 1500
Aurora 1.7로 업그레이드하면 바로 성능 향상을 경험하실 수 있습니다.
Aurora 1.7 업그레이드하기
DB 인스턴스를 새로 만드는 경우, Aurora 1.7로 자동으로 시작합니다. 이미 실행중인 DB 인스턴스에서 바로 업데이트하거나 다음 번에 업데이트를 선택하여 설치가 가능합니다.
아래 쿼리를 통해 Aurora 1.7이 적용되어 있는지 확인할 수 있습니다.
mysql> show global variables like "aurora_version";
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| aurora_version | 1.7 |
+----------------+-------+
— Jeff;
이 글은 Amazon Aurora Update – Parallel Read Ahead, Faster Indexing, NUMA Awareness의 한국어 번역입니다.
Source: Amazon Aurora 기능 업데이트 – 병렬 미리 읽기, 고속 인덱싱 , NUMA 인식 등


Leave a Reply