Amazon Aurora – PostgreSQL을 통한 장애 복원 기능 활용하기
기존 데이터센터나 비 클라우드 기반 아키텍처에서 데이터베이스에 대한 복제, 장애 조치, 복원력, 재해 복구 및 백업 등은 일부 또는 전부를 달성하기는 상당히 어려울 수 있습니다. 또한, 이를 위해서는 상당한 엔지니어링 작업일 필요할 때가 있습니다. 이와 관련된 구현 및 인프라 비용이 높기 때문에 일부 기업은 어쩔 수 없이 가장 중요한 애플리케이션만 안전하게 보호하도록 애플리케이션을 계층화합니다.
Amazon Aurora for PostgreSQL를 사용하면 이러한 우려를 상당히 완화할 수 있습니다. AWS에서는 Oracle, MySQL, PostgreSQL 및 Aurora를 비롯하여(이에 국한되지는 않음) 다양한 관계형 데이터베이스 엔진을 제공합니다. PostgreSQL의 경우 AWS에서는 Amazon EC2 인스턴스 기반 PostgreSQL, Amazon RDS for PostgreSQL 및 Amazon Aurora with PostgreSQL Compatibility를 비롯하여 다양한 배포판을 지원합니다. 적합한 PostrgreSQL을 선택하기 위한 많은 지표 중 중요한 몇 가지는 다음과 같습니다.
- 고가용성(HA)
- 성능
- 관리 용이성
Amazon Aurora PostgreSQL이 이러한 기준에 어떻게 부합하는지 살펴보겠습니다.
- 고가용성: HA는 Aurora PostgreSQL의 아키텍처에 내장되어 있으며 3개의 가용 영역에 걸쳐 6개의 데이터 복사본이 유지 관리됩니다. 즉, 가용 영역별로 2개의 복사본이 있으므로 전체 가용 영역에 장애가 발생하더라도 최소한의 가동 중단으로 가용성을 높일 수 있습니다. 또한, 데이터베이스는 Amazon S3에 지속해서 백업되므로 백업에서 S3의 뛰어난 내구성(99.999999999%)을 활용할 수 있습니다. 또한, Aurora PostgreSQL은 특정 시점으로 복구를 지원합니다.
- 성능: Amazon Aurora PostgreSQL은 Amazon EC2 기반 PostgreSQL과 비교하여 최대 3배 뛰어난 성능을 제공합니다. 벤치마크 테스트에 대한 자세한 내용은 Amazon Aurora PostgreSQL 호환 에디션 벤치마킹 안내서를 참조하십시오. 또한, Performance Insights를 사용하면 데이터베이스 분석 및 문제 해결을 좀 더 쉽게 수행할 수 있습니다.
- 관리 용이성: Amazon Aurora PostgreSQL은 프로비저닝, 패치 적용, 백업, 복구, 장애 탐지, 수리 등과 같은 일상적인 데이터베이스 작업을 처리하여 관리를 간소화합니다. Aurora 스토리지는 자동으로 규모가 조정되어 플릿 전체에서 I/O를 확장하고 재조정하여 일관된 성능을 제공합니다.
이 글에서는 Amazon Aurora 클러스터와 엔드포인트에 대한 개요를 제공하고, 클러스터와 엔드포인트가 어떻게 구성 변경을 최소화하면서 읽기에 대한 장애 조치와 로드 밸런싱을 수행하는 데 도움이 되는지 설명합니다. Aurora 클러스터에서 장애 조치가 어떻게 작동하는지 보여주는 예제를 살펴보고, 장애 조치를 투명하게 만드는 방법을 설명합니다. 이 게시물에서는 Amazon Aurora PostgreSQL을 주로 다루지만, 대부분의 개념을 Amazon Aurora MySQL에도 적용할 수 있습니다.
Amazon Aurora 클러스터 소개
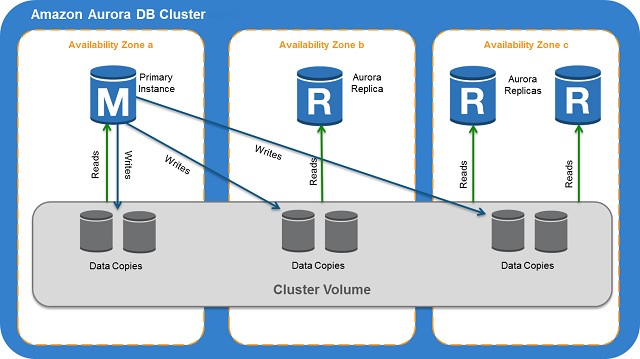
Amazon EC2 기반 PostgreSQL 또는 Amazon RDS for PostgreSQL과는 달리 Aurora PostgreSQL DB 인스턴스를 생성할 때는 실제로 데이터베이스 클러스터를 생성하게 됩니다. Aurora PostgreSQL에서 DB 클러스터는 1개의 읽기/쓰기 인스턴스, 최대 15개의 읽기 인스턴스, 그리고 여러 가용 영역으로 확장되는 데이터 스토리지(클러스터 볼륨)의 모음입니다. 각 가용 영역은 2개의 DB 클러스터 데이터 복사본을 유지 관리합니다.
Amazon Aurora 읽기 전용 복제본은 소스 인스턴스와 동일한 기본 스토리지를 공유하므로 비용이 절감되고 데이터를 복제본 노드에 복사할 필요가 없습니다. Amazon RDS for PostgreSQL 읽기 전용 복제본은 물리적 복사본입니다. 비동기식 복제 방법을 사용하여 소스 데이터베이스 인스턴스가 변경될 때마다 읽기 전용 복제본을 업데이트합니다. 또한, RDS for PostgreSQL의 경우 데이터베이스 소스 인스턴스당 읽기 전용 복제본이 5개로 제한되지만, Aurora 클러스터는 1개의 기본(마스터 또는 읽기/쓰기) 인스턴스와 최대 15개의 읽기 전용 복제본을 지원합니다.
다음 다이어그램은 1개의 마스터 및 3개의 읽기 전용 복제본으로 구성된 Aurora PostgreSQL 아키텍처를 보여줍니다.
Aurora 아키텍처에 대한 자세한 내용은 AWS 데이터베이스 블로그 게시물 Introducing the Aurora Storage Engine을 참조하십시오.
엔드포인트
Aurora PostgreSQL 인스턴스로 연결은 엔드포인트를 사용해 이루어집니다. 엔드포인트는 호스트 주소와 포트(콜론으로 분리)가 포함된 URL입니다. 사용자가 Aurora PostgreSQL 인스턴스를 생성하면, AWS에서 클러스터 수준과 인스턴스 수준에서 엔드포인트를 생성합니다. 클러스터 수준에서는 읽기/쓰기 작업을 위한 엔드포인트(클러스터 엔드포인트라고 함) 1개와 읽기 전용 작업을 위한 엔드포인트(리더(reader) 엔드포인트라고 함) 1개로 총 2개의 엔드포인트가 생성됩니다. 장애 조치는 클러스터 엔드포인트를 통해 이루어지는 반면에 여러 읽기 전용 복제본 전체에서 읽기 전용 연결을 위한 로드 밸런싱은 리더 엔드포인트를 통해 이루어집니다. 또한, 클러스터에 읽기 전용 복제본이 없는 경우 리더 엔드포인트가 기본 인스턴스로 연결을 제공합니다.
인스턴스 수준에서는 인스턴스당 1개의 엔드포인트가 생성됩니다. 인스턴스 엔드포인트의 경우 기존 연결과 마찬가지로 인스턴스에 직접 연결하게 됩니다. 정당한 이유가 없다면 클러스터 엔드포인트 없이 인스턴스 엔드포인트만 사용하는 것은 권장되지 않습니다. 인스턴스 엔드포인트와 함께 클러스터 엔드포인트를 사용하여 읽기 쿼리의 수동 로드 밸런싱을 수행할 수 있습니다.
다음 다이어그램은 엔드포인트 작동 방식을 보여줍니다.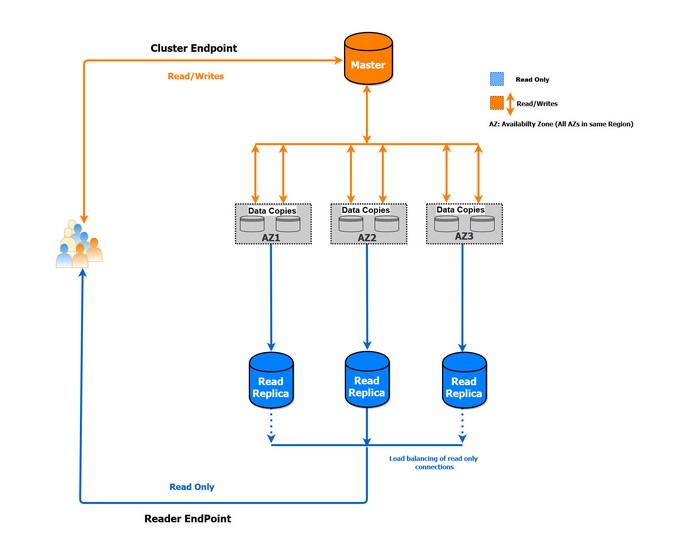
참고: DB 클러스터의 이름이 바뀌면 클러스터 엔드포인트와 리더 엔드포인트가 변경됩니다.
Amazon RDS 콘솔의 탐색 창에서 Clusters를 선택하면 해당 클러스터 엔드포인트와 리더 엔드포인트를 찾을 수 있습니다.

장애 조치 작동 방식
DB 클러스터의 기본 인스턴스에 장애가 발생하면 자동으로 Aurora가 다음과 같은 순서로 장애 조치합니다.
- Aurora 읽기 전용 복제본을 사용할 수 있는 경우, 기존 읽기 전용 복제본을 새로운 기본 인스턴스로 승격합니다.
- 읽기 전용 복제본을 사용할 수 없는 경우, 새로운 기본 인스턴스를 생성합니다.
Aurora 읽기 전용 복제본이 여러 개인 경우, 승격 기준은 읽기 전용 복제본에 정의된 우선순위를 따릅니다. 우선순위 번호는 0에서 15까지 다양하면 언제든지 수정할 수 있습니다. Amazon Aurora PostgreSQL은 가장 우선순위가 높은 Aurora 복제본을 새로운 기본 인스턴스로 승격합니다. 우선순위가 같은 읽기 전용 복제본이 있다면 Aurora PostgreSQL이 임의 방식으로 또는 크기가 가장 큰 복제본을 승격합니다.
애플리케이션이 클러스터 엔드포인트를 사용하여 연결하고 연결 재시도 로직을 구현하는 경우, 해당 애플리케이션은 최소한의 서비스 가동 중단을 경험할 수 있습니다. AWS는 장애 조치 도중 새로 생성된/승격된 DB 인스턴스를 가리키도록 클러스터 엔드포인트를 수정합니다. Well-Architected 애플리케이션은 자동으로 재연결합니다. 장애 조치 도중 가동 중단 시간은 정상적인 읽기 전용 복제본의 존재 여부에 따라 달라집니다. 읽기 전용 복제본이 구성되어 있지 않거나 기존 읽기 전용 복제본이 비정상인 경우, 새로운 인스턴스를 생성하기 위해 가동 중단 시간이 증가할 수 있습니다.
Aurora 클러스터 장애 조치 예제
Amazon Aurora 클러스터의 장애 조치 예제를 살펴보겠습니다. 다음 표에는 1개의 마스터 인스턴스와 2개의 읽기 전용 복제본으로 구성된 클러스터의 세부 정보가 나와 있습니다.
| 클러스터 이름 | pgcluster |
| 마스터 인스턴스 | myinstance-us-east-2a |
| 읽기 전용 복제본 | myinstance-us-east-2b (Priority 0) |
| 읽기 전용 복제본 | myinstance-us-east-2c (Priority 1) |
| 클러스터 엔드포인트 | pgcluster.cluster-xxxxxxxxxx.us-east-2.rds.amazonaws.com |
| 리더 엔드포인트 | pgcluster.cluster-ro-xxxxxxxxxx.us-east-2.rds.amazonaws.com |
이 다이어그램은 pgcluster라는이름의 Aurora PostgreSQL 클러스터를 보여줍니다. 클러스터 엔드포인트 pgcluster.cluster-xxxxxxxxxx.us-east-2.rds.amazonaws.com이 현재 myinstance-us-east-2a는인스턴스를 가리키고 있습니다.
아래 코드는 클러스터 엔드포인트를 사용하여 포트 5432에서 데이터베이스 pgdb에 연결하는 것을 보여줍니다. 이 그림의 일부로 이 예제에서는 failover라는 이름의 테이블을 생성하고 행 하나를 테이블에 삽입합니다.
다음 코드는 실패한 트랜잭션과 더불어 리더 엔드포인트를 사용하여 읽기 전용 복제본 인스턴스에 연결하는 작업을 보여줍니다. 리더 엔드포인트를 통해 읽기 전용 복제본에서 failover 테이블에 액세스하여 동기화를 확인합니다.
예상한 대로 읽기 전용 복제본이 쓰기 가능한 트랜잭션을 지원하지 않아서 오류가 발생했습니다.
수동 장애 조치
다음 스크린샷은 Amazon RDS 콘솔에 있는 현재 기본 인스턴스 myinstance-us-east-2a를 보여줍니다.
수동 장애 조치를 수행하려면 콘솔에서 기본 인스턴스 이름을 선택하고 Instance actions 메뉴에서 Failover를 선택합니다.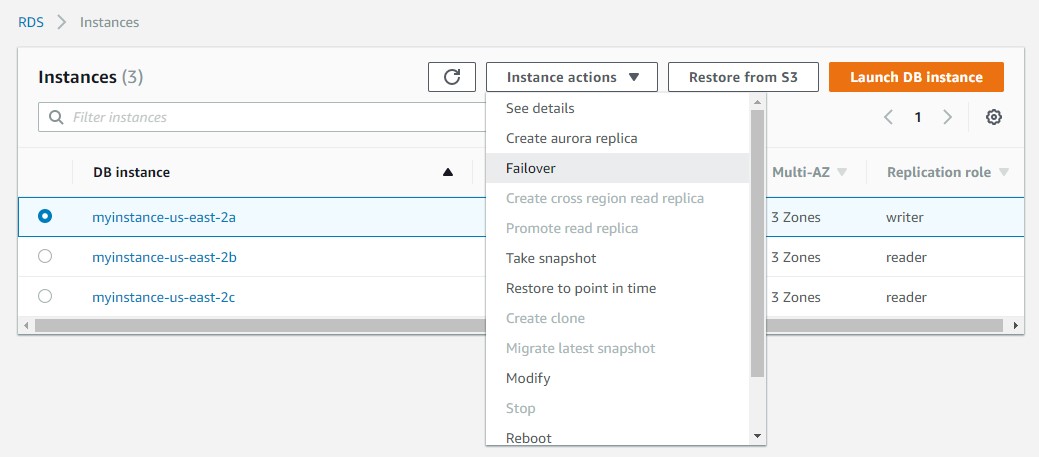
그런 다음 Failover 창에서 이를 확인합니다.
수동 장애 조치가 완료되면 myinstance-us-east-2b 인스턴스가 새로운 기본 인스턴스로 승격되고 myinstance-us-east-2a 인스턴스 역할이 읽기 전용 복제본으로 변경됩니다. 또한, 클러스터 엔드포인트가 이제 myinstance-us-east-2b를가리킵니다. 반면에 myinstance-us-east-2a는 리더 엔드포인트를 통해 사용할 수 있습니다.
다음 스크린샷은 RDS 콘솔에서 읽기 전용 복제본이 새로운 기본 인스턴스가 되는 것을 보여줍니다.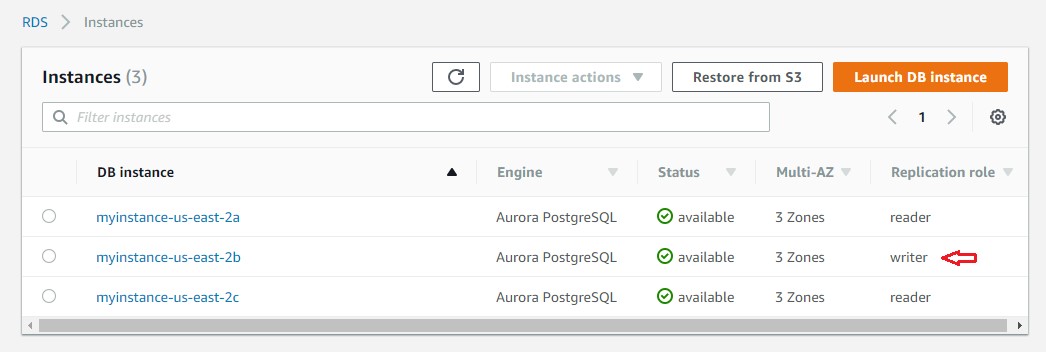
인스턴스 재연결
이제 같은 클러스터 엔드포인트를 사용하여 재연결할 수 있습니다.
앞의 코드에서 볼 수 있듯이 엔드포인트를 변경하지 않고 연결이 성공적으로 완료되었습니다. 애플리케이션 연결 재시도 로직을 추가하면 장애 조치를 투명하게 만들 수 있습니다.
클러스터 엔드포인트와 더불어 애플리케이션 수준에서 공격적인 TCP keep-alive 설정 및 JDBC 연결 설정 또는 PGConn 클래스를 구성하면 장애 조치를 훨씬 빠르게 처리할 수 있습니다. 자세한 내용은 Amazon Aurora PostgreSQL 모범 사례를 참조하십시오.
마무리
어느 조직이든 가동 시간 SLA(서비스 수준 계약)를 달성하려면 자동 복구 처리가 매우 중요합니다. 혁신적인 장애 조치 아키텍처를 갖춘 Aurora PostgreSQL은 가용성과 안정성을 향상할 뿐만 아니라 읽기 확장성을 통해 향상된 성능을 제공합니다.
애플리케이션이 장애 조치에 응답하는 방법은 많습니다. 하지만 클러스터 엔드포인트와 리더 엔드포인트를 사용하면 구성 변경을 최소화하면서 읽기에 대한 로드 밸런싱 및 장애 조치를 구현할 수 있습니다. 또한, TCP keep-alive 및 JDBC 모범 사례와 함께 클러스터 엔드포인트를 사용하면 빠른 장애 조치와 높은 가용성을 달성할 수 있습니다. 인스턴스 엔드포인트를 기본 엔드포인트로 사용하는 것은 권장하지 않습니다. 하지만 읽기를 위한 수동 로드 밸런싱을 지원하는 데 사용할 수 있습니다. 그뿐만 아니라 애플리케이션에 자동 재시도 기능을 추가하면 장애 조치를 투명하게 만들 수 있습니다.
작성자 소개
 Shan Nawaz는 Amazon Web Services의 빅 데이터 컨설턴트이비니다. Shan은 고객과 협력하여 데이터베이스 및 빅 데이터 프로젝트에 대한 기술적 지원과 지침을 제공하며, AWS 사용 시 고객 솔루션의 가치를 높일 수 있도록 지원합니다.
Shan Nawaz는 Amazon Web Services의 빅 데이터 컨설턴트이비니다. Shan은 고객과 협력하여 데이터베이스 및 빅 데이터 프로젝트에 대한 기술적 지원과 지침을 제공하며, AWS 사용 시 고객 솔루션의 가치를 높일 수 있도록 지원합니다.
이 글은 AWS Database Blog의 Failover with Amazon Aurora PostgreSQL의 한국어 번역입니다.


Leave a Reply