Amazon CloudFront 실시간 로그 기능을 통한 대시 보드 생성하기
Amazon CloudFront 는 글로벌 엣지 로케이션 네트워크를 사용하여 짧은 지연 시간과 빠른 전송 속도로 정적 및 동적 웹 콘텐츠를 안전하게 전송하는 콘텐츠 전송 네트워크 (CDN) 서비스입니다. 오늘 부터 CloudFront에서 실시간 로그를 제공하는 새로운 기능을 발표했습니다. CloudFront 실시간 로그에는 수신하는 모든 요청에 대한 자세한 정보를 포함할 수 있기 때문에 운영 시 생기는 문제에 대해 신속하게 대응할 수 있습니다.
실시간 로그를 사용하여 수집 된 정보와 제공되는 위치를 사용자 지정할 수 있으며, Amazon Kinesis Data Streams을 통합하거나, 일반 HTTP 엔드 포인트를 통해 실시간 로그를 Amazon Kinesis Data Firehose를 통해 Amazon S3 , Amazon Redshift , Amazon Elasticsearch Service (Amazon ES) 및 Datadog, New Relic 및 Splunk와 같은 서비스 공급자에 제공할 수 있습니다. 이를 통해 실시간 대시 보드를 생성하고, 알람를 설정하고, 이상 현상에 대해 조사하거나 운영 장애에 신속하게 대응할 수 있습니다. 추적 할 수 있는 공통 데이터 포인트에는 서로 다른 리전에서 발생하는 요청 수와 지연 시간이 증가한 고유 한 뷰어 수가 포함됩니다.
이 글에서는 CloudFront 실시간 로그 기능을 활용하여, Amazon Elasticsearch Service (ES)를 통해 운영 대시 보드를 생성하는 방법을 알아 봅니다 .
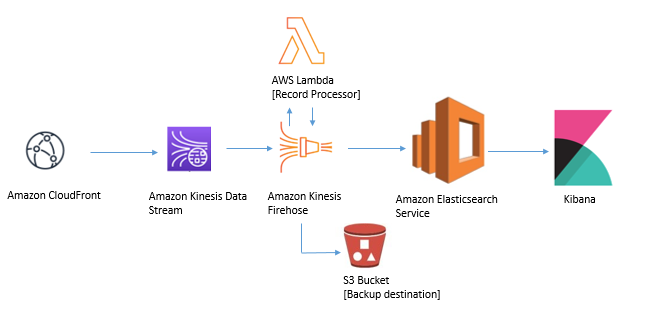
본 아키텍처는 Kinesis Data Stream과 Kinesis Data Firehose를 통해 로그를 받아, Kinesis Firehose 내에서 Lambda 함수를 사용하여 로그를 처리하고, 로그 형식을 업데이트하는 방법을 보여줍니다. 또한 Kinesis Firehose가 Elasticsearch에 데이터를 전송할 수 없는 경우에 대한 백업 방법으로 S3 버킷을 구성하는 방법도 살펴봅니다. 권한이있는 사용자는 Kibana 인터페이스에 로그인하여 실시간 로그에서 대시 보드를 통해 실시간 운영 상 문제를 해결할 수 있습니다.
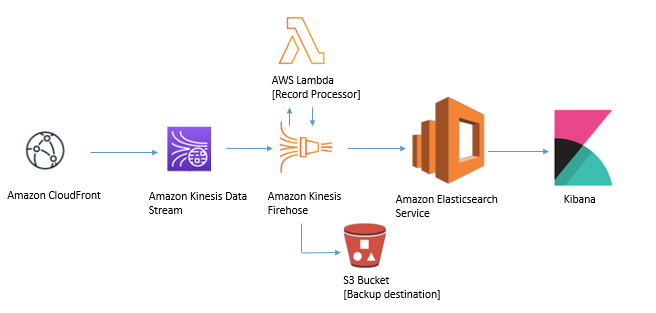
다음 단계에 따라이 로그 파이프 라인을 설정할 수 있습니다.
단계 1: Kinesis 데이터 스트림 만들기
1) 우선 Amazon Kinesis 콘솔로 이동하여 데이터 스트림을 선택하고, 데이터 스트림 생성합니다.

2) 다음 페이지에서 스트림의 이름을 cloudfront-real-time-log-data-stream으로 지정 하고, 샤드 수를 200으로 합니다. 계정 당 최대 500 개까지 프로비저닝 할 수 있습니다.

 3) 데이터 스트림 생성을 선택합니다.
3) 데이터 스트림 생성을 선택합니다.
4) 데이터 스트림을 프로비저닝 한 후, 데이터 보존 기간 필요에 따라 이를 늘리도록 선택할 수 있습니다 . 기본값은 24 시간이며 168 시간으로 늘릴 수 있습니다.
단계 2: CloudFront 배포에서 실시간 로그 활성화
먼저 CloudFront 배포 지점을 생성해야합니다. CloudFront 배포를 빠르게 생성하기 위해 CloudFormation 템플릿를 사용하셔도 됩니다. 배포에 대한 실시간 로그를 활성화하려면 실시간 로그 구성을 생성해야합니다. 배포를 만들거나 업데이트하는 동안 또는 배포를 직접 진행하여 로그 구성을 만들 수 있습니다.
CloudFront 콘솔에서 Telemety 아래 Logs 항목을 선택합니다. 기본 설정과 기본 샘플링 속도 인 100을 유지합니다. 샘플링 속도를 사용하면 로그 레코드의 백분율을받을 수 있습니다. 예를 들어 트래픽 볼륨이 높고 모든 로그 데이터를 처리하고 싶지 않을 수 있습니다. 이 경우 높은 수준의 추세 분석을 위해 전체 로그의 백분율을 샘플링하도록 선택할 수 있습니다.
실시간 로그 활성화를 계속하려면 로그를 생성 할 배포 및 캐시 동작을 선택하십시오. 구성의 일부로 cloudfront-real-time-log-data-stream 이전 단계에서 생성한 Kinesis 데이터 스트림도 지정합니다.

전체 구성을 생성하는 동안이 실시간 로그 구성을 배포의 캐시 동작에 연결할 수 있습니다. 기존 배포에서 캐시 동작 설정을 편집 또는 생성하거나 새 배포를 생성 할 때 실시간 로그 구성을 첨부 할 수 있습니다.
아래 화면에서 캐시 동작을 편집하려고 할 때, 실시간 로그 구성을 첨부 할 수있는 옵션이 있습니다. 새 구성 만들기 버튼은 위에 표시된 실시간 로그 구성 섹션으로 리디렉션됩니다.


단계 3: Kinesis Firehose에서 로그 처리용 Lambda 함수 생성하기
AWS Lambda 콘솔로 이동하여 간단하게 람다 함수를 만들 수 있습니다. 새로 함수 만들기를 눌러 기본 정보 섹션에서 cf-real-time-logs-transformer 를 함수 이름으로 사용하고, 런타임으로 Python 3.8을 선택합니다. 권한 섹션에서 기본 람다 권한을 가진 새로운 역할 만들기 를 선택한 후 함수를 만듭니다.

이제 Lambda 함수를 생성했으면, 함수에 대한 구성 탭을 엽니다.

함수의 코드는 아래를 복사해서 넣습니다.
import base64
import json
print('Loading function')
def lambda_handler(event, context):
output = []
# Based on the fields chosen during the creation of the
# Real-time log configuration.
# The order is important and please adjust the function if you have removed
# certain default fields from the configuration.
realtimelog_fields_dict = {
"timestamp" : "float",
"c-ip" : "str",
"time-to-first-byte" : "float",
"sc-status" : "int",
"sc-bytes" : "int",
"cs-method" : "str",
"cs-protocol" : "str",
"cs-host" : "str",
"cs-uri-stem" : "str",
"cs-bytes" : "int",
"x-edge-location" : "str",
"x-edge-request-id" : "str",
"x-host-header" : "str",
"time-taken" : "float",
"cs-protocol-version" : "str",
"c-ip-version" : "str",
"cs-user-agent" : "str",
"cs-referer" : "str",
"cs-cookie" : "str",
"cs-uri-query" : "str",
"x-edge-response-result-type" : "str",
"x-forwarded-for" : "str",
"ssl-protocol" : "str",
"ssl-cipher" : "str",
"x-edge-result-type" : "str",
"fle-encrypted-fields": "str",
"fle-status" : "str",
"sc-content-type" : "str",
"sc-content-len" : "int",
"sc-range-start" : "int",
"sc-range-end" : "int",
"c-port" : "int",
"x-edge-detailed-result-type" : "str",
"c-country" : "str",
"cs-accept-encoding" : "str",
"cs-accept" : "str",
"cache-behavior-path-pattern" : "str",
"cs-headers" : "str",
"cs-header-names" : "str",
"cs-headers-count" : "int"
}
for record in event['records']:
# Extracting the record data in bytes and base64 decoding it
payload_in_bytes = base64.b64decode(record['data'])
# Converting the bytes payload to string
payload = "".join(map(chr, payload_in_bytes))
# dictionary where all the field and record value pairing will end up
payload_dict = {}
# counter to iterate over the record fields
counter = 0
# generate list from the tab-delimited log entry
payload_list = payload.strip().split('t')
# perform the field, value pairing and any necessary type casting.
# possible types are: int, float and str (default)
for field, field_type in realtimelog_fields_dict.items():
#overwrite field_type if absent or '-'
if(payload_list[counter].strip() == '-'):
field_type = "str"
if(field_type == "int"):
payload_dict[field] = int(payload_list[counter].strip())
elif(field_type == "float"):
payload_dict[field] = float(payload_list[counter].strip())
else:
payload_dict[field] = payload_list[counter].strip()
counter = counter + 1
# JSON version of the dictionary type
payload_json = json.dumps(payload_dict)
# Preparing JSON payload to push back to Firehose
payload_json_ascii = payload_json.encode('ascii')
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(payload_json_ascii).decode("utf-8")
}
output.append(output_record)
print('Successfully processed {} records.'.format(len(event['records'])))
return {'records': output}기본 설정내 제한 시간 에서 편집 버튼을 클릭하여 값을 기본값 인 3 초에서 1 분으로 바꿉니다.

이제 함수는 만들어졌습니다.
단계 4: Elasticsearch 생성 및 백업 S3 버킷 생성하기
Elasticsearch Service 콘솔에서 클릭 새 도메인 생성 하고, 아래 화면처럼 (1 단계 : 배포 유형 선택)의 배포 유형을 개발 및 테스트, 버전은 기존 버전 그대로 둡니다.

다음 화면 (2 단계 : 도메인 구성)의 도메인 구성 섹션에서 cf-realtime-log-es-domain 을 Elasticsearch 도메인 이름으로 사용 합니다. 인스턴스 유형 및 노드 수에 에서 데이터 노드 섹션 등은 기본 설정도 그대로 둡니다 .

다음 화면에서 (3 단계 : 접근 및 ID 구성)의 네트워크 구성 에서 외부 접속을 선택합니다. (테스트용이므로 외부 접근을 허락하는 것이고, 필요에 따라 VPC를 선택하시기 바랍니다.) 
Fine-grained access control – Power by Open Distro for Elasticsearch 섹션에서 Enable fine-grained access control을 선택하고, 마스터 사용자 생성을 눌러 마스터 사용자 이름, 마스터 암호 및 마스터 암호 확인 입력 필드를 합니다. (중요: Kibana 대시 보드에 접속하는 데 필요하므로 이 정보를 꼭 기록해 두세요.)

액세스 정책 세션에서 션에서 선택합니다 도메인 액세스 정책에서 오픈 액세스 허용을 선택합니다.

같은 화면의 다른 설정 (3 단계 : 액세스 및 ID 구성)을 기본값으로두고 클릭 다음을 합니다. 다음 화면 (4 단계 : 검토)에서 설정을 다시 하고 확인을 선택하여 마무리합니다 .
Elasticsearch 리소스를 만드는데 약 10 분이 걸립니다. 도메인이 Active 상태가 되면 Kinesis Firehose 리소스 프로비저닝을 진행합니다.

Kinesis Firehose가 Elasticsearch 클러스터로 전송하지 못할 수 있는 레코드의 백업 대상으로 작동하려면 Kinesis Data Stream 및 Elasticsearch 클러스터와 동일한 리전에 S3 버킷을 생성하세요.
단계 4: Kinesis Data Firehose를 통해 분석 파이프 라인 설정
Kinesis 콘솔 대시 보드 에서 전송 스트림 생성을 선택합니다 .

다음 화면에서 (1 단계 : 이름 및 소스)의 새 전송 스트림 섹션에서 cloudfront-real-time-log-data-kinesis-firehose-consumer를 전송 스트림 이름으로 사용합니다.

소스 선택 섹션에서 Kinesis 데이터 스트림 Kinesis 데이터 스트림으로 라디오 버튼을 선택하고, cloudfront-real-time- log-data-stream 을 선택 합니다.

다음 화면 (2 단계 : 레코드 처리)의 AWS Lambda로 소스 레코드 변환 섹션에서 데이터 변환 활성화를 선택하고, 만들어둔 cf-real-time-logs-transformer 이름의 Lambda 함수 선택합니다.

다음 화면에서 (3 단계 : 대상 선택)에서 Amazon Elasticsearch을 선택합니다.

Amazon Elasticsearch Service 대상 섹션에서 cf-realtime-log-es-domain을 도메인으로 선택하고, 인덱스에 realtime이라고 입력합니다.

S3 백업 섹션에서 실패한 레코드만을 선택하고 단계4에서 생성 한 백업 S3 버킷을 선택합니다.

다음 화면 (4 단계 : 설정 구성)에서 모든 설정을 기본값으로 두고 진행합니다. (참고 : 권한 섹션에서 Firehose가 다른 서비스와 상호 작용하는 동안 담당하는 IAM 역할을 생성한다는 것을 알 수 있습니다.이 역할의 예제 ARN은 다음과 같습니다. arn:aws:iam::xxxx:role/service-role/KinesisFirehoseServiceRole-cloudfront-re-us-west-2-xxxx)
다음 화면 (5 단계 : 검토)에서 설정을 다시 확인하고 완료합니다.
단계 6: Elasticsearch에서 Kinesis Data Firehose 서비스 설정하기
Elasticsearch 도메인에 대한 세분화 된 접근 제어를 구성하는 동안, 이전에 설정한 마스터 사용자 이름과 암호를 사용하여 Kibana 대시 보드에 접속한 뒤, Kinesis Data Firehose를 허용하고 Elasticsearch 도메인 인덱스를 생성하고 데이터를 쓰기 위한 서비스 역할 등 필요한 구성 변경을 수행해야 합니다.
ES 콘솔에서 설정된 Kibana URL로 이동합니다. Elasticsearch 도메인에 대한 Kibana 필드 옆에있는 URL을 선택하면 됩니다.
Amazon Elasticsearch Service 엔드 포인트를 생성 할 때 설정 한 마스터 사용자 이름과 암호를 입력합니다.

보안에서 역할을 선택합니다.

+아이콘을 선택하여, 새 역할을 추가합니다. (예 : firehose-role). 클러스터 권한 탭에서 클러스터 전체 권한 으로 cluster_composite_ops및 cluster_monitor액션 그룹을 추가합니다.


색인 권한 탭에서 추가를 눌러, Index Patterns를 선택하고 realtime*을 입력하세요. 액션 그룹 권한에는 crud, create_index, manage을 선택합니다.

다음 단계에서는 Kinesis Data Firehose가 사용하는 IAM 역할을 방금 생성 한 역할에 매핑합니다. 백엔드 역할의 경우, Kinesis Data Firehose가 Amazon ES 및 S3에 쓰기 위해 사용하는 역할의 IAM ARN을 입력합니다 arn:aws:iam::<aws_account_id>:role/service-role/<KinesisFirehoseServiceRole>. (이는 5 단계에서 Kinesis Data Firehose 리소스 생성 중에 생성 된 IAM 서비스 역할에 대한 동일한 ARN입니다. 예 :( arn:aws:iam::xxxx:role/service-role/KinesisFirehoseServiceRole-cloudfront-re-us-west-2-xxx)

단계 7: Amazon ES에서 실시간 대시 보드 구축
Amazon ES를 사용하여 데이터의 추세를 관찰하고 그래프를 대시 보드로 결합 할 수 있습니다. 예를 들어 서로 다른 리전의 실시간 요청 수를 확인할 수 있습니다.
이를 위해 Kibana 대시 보드의 시각화 섹션으로 이동하여 새 시각화를 만듭니다. 생성하려는 시각화 유형을 지정하여, 리전별 데이터 지도를 만들 수 있습니다.

요청이 가장 많은 지연 시간을 보는 리전을 확인하려는 경우, 막대 그래프로 시각화를 만들고 추적하려는 값 범위를 설정할 수 있습니다.

시각화를 통해 실시간 이벤트에 대한 관련 정보를 집계하는 대시 보드로 결합 할 수 있습니다.

이전에 만든 기존 시각화를 대시 보드에 추가합니다.

다음 샘플 대시 보드에서 국가 별 요청, 요청 당 높은 대기 시간을 경험하는 국가, 지정된 대기 시간 범위 내의 국가 당 시청자 수와 같은 다양한 차원에 시각화 정보를 볼 수 있습니다.

마무리
이 글에서는 Amazon CloudFront 및 Amazon ES를 사용하여 실시간 로그 스트리밍 및 대시 보드 솔루션을 설정했습니다. 실시간 CloudFront 로그 데이터를 수신하는 기능을 통해 웹 애플리케이션에 대한 요청을 빠르게 분석 할 수 있습니다.
또한, Amazon ES를 CloudFront 로그의 대상으로 사용하는 방법에 대한 예를 다루고 시각화를 구축하는 방법을 살펴 보았습니다. Kibana에서 실시간 운영 대시 보드를 생성하여 자세한 로그 데이터를 검토 할 수 있습니다. CloudFront 실시간 로그에 대해서는 CloudFront 개발자 안내서를 살펴 보세요.
– Mohammad Shafiullah, Senior Cloud Support Engineer
– Samrat Karak, Senior Product Manager
이 글은 AWS Networking & Content Delivery 블로그의 Creating realtime dashboards using Amazon CloudFront logs 한국어 번역입니다.

Leave a Reply