Amazon Comprehend 기반 설공 상품평 분석을 통한 상품 트렌드 예측도 개선하기
이랜드 이노플은 이랜드 그룹 전체의 IT를 담당하는 회사이며, 2014년 빅데이터 사업부 설립 이래 빅데이터 분석 및 AI 서비스를 그룹사를 대상으로 제공해 오고 있습니다.
대외적으로는 2020년부터 스타트업 및 중소기업을 대상으로 빅데이터 트렌드 컨설팅을 통해 성공의 경험을 함께 나누고 있습니다. 그중에서도 저당류 푸드 스타트업인 ‘설탕없는 과자공장'(이하 ‘설공’)에 대한 컨설팅 사례를 공유하고자 합니다.
설공은 푸드 상품기획에 있어서 몇 가지 애로점을 가지고 있었습니다. 지금까지 대부분 상품 기획자의 직관 및 현장 경험에 의존하여 신상품을 출시해왔고, 직원들 간의 의견이 다른 경우 내부 조정에 어려움을 겪는 문제점을 가지고 있었습니다. 이랜드 이노플은 설공의 이러한 애로점을 해결하기 위해, Amazon Comprehend를 활용한 클라우드 기반 빅데이터 기반 트렌드 분석 및 상품기획 프로젝트 컨설팅을 진행하였습니다. Amazon Comprehend는 2019년 한국어를 지원하기 시작했으며, 2020년에 서울 리전에도 출시했기 때문에 한국 고객들도 바로 이용이 가능합니다.
Amazon Comprehend를 통한 상품평 감성 분석 구현
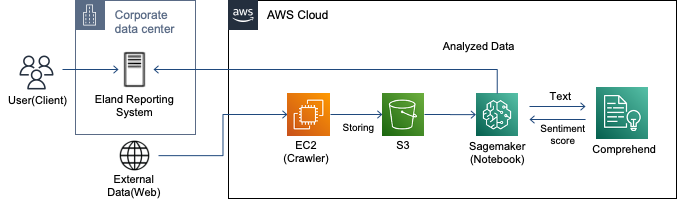
이랜드 이노플은 유통, 패션, 외식, 호텔 등 이랜드 그룹의 다양한 사업 영역에서 발생하는, 매일 백만 건 이상의 판매 데이터와 회원 1,300만 명의 고객 행동 이력 데이터를 AWS 상에 정제하여 적재하고 있으며, 이렇게 수집된 정보를 Amazon SageMaker 기반으로 분석하고 가공하여 비즈니스에 적용하고 있습니다. 이러한 경험을 활용하기 위하여 설공에 대한 컨설팅 과정에서도 기존의 분석 아키텍처를 활용했습니다.

이랜드 이노플의 클라우드 기반 데이터 분석 아키텍처
먼저 설공의 타겟 시장의 트렌드 분석 및 예측을 위한 기초 데이터 수집에 착수하였습니다. 건강한 먹거리에 관심이 높은 고객들의 선호도가 높은 온라인몰들을 선정하고, 동일 제품 카테고리 내에 약 700여 종에 제품에 대해 140만 건의 공개된 상품평 데이터를 수집하여, Amazon Simple Storage Service (Amazon S3)에 적재하였습니다.
수집된 상품평 데이터에 대한 통계치와 단어 횟수 계산(Word Count) 등의 기본 분석은 상대적으로 수월하게 진행되었습니다. 그러나, 일부 온라인몰들은 평점에 대한 정보를 제공하지 않았기 때문에 다른 방법으로 긍정/부정에 대한 고객들의 평가를 구분할 필요성을 확인하게 되었습니다.
긍/부정 또는 감성 분석을 위한 효과적인 방법을 찾던 중, 기존의 다른 알고리즘은 학습이 필요하나 학습을 위한 데이터 레이블링에 시간을 많이 들일 수 없는 상황임을 고려하여 이미 검증된 서비스를 이용하는 것이 생산성에 더 큰 도움이 되리라 판단하고 Amazon Comprehend를 활용하였습니다.
Amazon Comprehend를 사용한 결과, 처음 예상했던 것과 같이 긍/부정 분석을 성공적으로 빠르게 마칠 수 있었으며 나아가 몇 가지 추가적인 장점도 확인할 수 있었습니다.
우선 기존의 알고리즘으로 분석을 진행했을 경우, 분석 대상을 긍/부정 이분법으로만 분류시킨다는 문제가 있었습니다. 텍스트를 긍/부정으로 나눌 수 없거나 긍정과 부정을 혼합하여 사용한 경우에는 이를 정확하게 판단하기 어려운 경우입니다. Amazon Comprehend는 총 4개의 분류 기준으로 긍/부정뿐만 아니라, 긍/부정으로 분류할 수 없는 혼합이나 중립 같은 분류가 가능한 점이 분석에 유용했습니다.
예를 들면, 리뷰 데이터의 포인트 적립을 위한 의미 없는 글자를 기입하거나, ‘맛은 있지만, 너무 비싸다’는 것과 같은 긍/부정을 혼합한 리뷰의 분류가 가능했습니다. 기존 단순 긍/부정의 이분화 알고리즘을 통한 상품 만족도의 분석은 의미 없거나 중의적인 리뷰를 판단할 수 없어서 이것이 전체 신뢰도를 하락 원인 중 하나가 되었지만, Amazon Comprehend를 통해서는 최종 상품별 분석 결과 수치화에서 왜곡된 데이터를 사전 정제할 수 있었기 때문에 분석 정확도를 높일 수 있었습니다.
또한, Word Cloud를 만들 때도 긍/부정으로 정확하게 나뉘지 않는 리뷰데이터를 사전 정제하는 부분이 왜곡된 의사 결정을 내리지 않도록 분석 방향과 인사이트 도출하는데 중요한 역할을 수행했습니다. 동일한 상품에 대한 분석을 통한 키워드 추출시 해당 키워드가 정확하게 긍정 분석에서 도출된 키워드인지, 부정 분석에서 도출된 키워드인지, 아니면 혼합(Mixed)분석에서 도출된 키워드인지를 파악하는 것이 매우 중요하기 때문입니다.
초벌 분석 결과의 재학습을 통한 정확도 향상
일종의 Model Stacking 기법을 활용하기 위해, Amazon Comprehend의 긍/부정 분석 결과물 중 뚜렷하게 점수가 높은 데이터를 다시 별도 알고리즘에 학습시켰습니다. 데이터가 매우 많았고, 높은 정확도가 더 중요한 상황이었기에 Amazon Comprehend와 학습 알고리즘을 교차 유효성 확인(Cross Validation)하여 일치하지 않는 데이터를 과감히 제거하니 유의미한 정확도 상승이 있었습니다.
총 20개 상품의 리뷰 데이터를 여러 차례 샘플링하여 검증한 결과 94.5%의 정확도를 확인할 수 있었고 충분히 유의미한 정확도라는 판단하에 트렌드 분석 리포트를 작성할 수 있었습니다.

재학습 결과를 통해 높은 정확도의 고객 만족도 분석 데이터를 기반으로 어떤 옵션(맛)의 판매량이 많은지, 재구매가 높을지를 긍/부정 상대지수를 통하여 유추하고 이를 시각화할 수 있었습니다. (아래 이미지의 시각화된 데이터 결과는 예시이며, 표시된 결과에 대해 보증하지 않습니다.)

설공 상품기획팀은 이를 토대로 개인의 직관을 데이터로 확인할 수 있어서 만족도가 높았으며, 이를 기반으로 신상품을 기획하여 현재 출시 준비 중입니다. 설공은 이후로도 데이터 분석을 통해서 고객 니즈를 포착해 새로운 상품 기획에 반영할 계획입니다.
이 프로젝트를 수행한 이랜드 이노플의 나은혜 연구원은 “주어진 데이터에 대한 긍정/부정 분석을 일회성으로 실시하는 경우나 분석 작업을 빠르게 진행해야 하는 경우에 Amazon Comprehend의 사용이 분석 효율 및 생산성 향상에 큰 도움이 되는 것을 확인할 수 있었다”라고 이야기해 주셨습니다.
마무리
이랜드 이노플의 컨설팅 사례와 같이, Amazon Comprehend를 활용하면 핵심 문구 추출, 긍/부정/혼합과 같은 감성 분석 및 구문 분석 등의 다양한 텍스트 분석을 통해서 유용한 인사이트를 빠르게 도출할 수 있습니다. Amazon Comprehend를 바로 시작하시려면, 기술 문서나 핸즈온 랩 가이드 (영문)을 참고하시면 됩니다.
이 게시물의 내용과 의견은 제3자 작성자의 것이며, AWS는 이 게시물의 내용이나 정확성에 대해 책임을 지지 않습니다.
– 나은혜 이랜드 이노플 선임연구원
– 김양수 AWS 솔루션스 아키텍트


Leave a Reply