Amazon Kinesis와 Amazon Athena를 활용한 VPC 네트워크 트래픽의 분석과 시각화
네트워크 로그 분석은 많은 조직에서 일반적으로 수행하는 작업 중 하나입니다. 네트워크 로그를 캡처 및 분석하면 네트워크상의 디바이스가 어떻게 서로간에 그리고 인터넷과 통신하는지를 알 수 있습니다. 조직은 감사 및 규정 준수, 시스템 문제 해결 또는 보안 포렌직 등 다양한 이유로 인해 로그 분석을 수행합니다. Amazon Virtual Private Cloud(VPC)에서는 VPC Flow Logs를 통해 네트워크 플로우를 캡처할 수 있습니다. 플로우 로그는 VPC, 서브넷 또는 네트워크 인터페이스에 대해 생성될 수 있습니다. 서브넷 또는 VPC에 대한 플로우 로그를 생성하는 경우, VPC 또는 서브넷의 각 네트워크 인터페이스가 모니터링됩니다. 플로우 로그 데이터는 Amazon CloudWatch Logs의 로그 그룹에 게시되며, 각 네트워크 인터페이스는 고유의 로그 스트림을 가지게 됩니다.
CloudWatch Logs는 로그 데이터에 대한 통찰을 얻기 위한 뛰어난 도구를 제공합니다. 그러나 대부분의 경우 고객은 로그 데이터를 S3에 아카이브하고 SQL을 사용하여 이러한 정보를 쿼리하고자 할 것입니다. 이 방식은 로그 보존 및 원하는 분석 작업에 있어 더 많은 유연성과 제어력을 제공합니다. 그 외에도 고객들은 로그 데이터가 생성된 후 신속하게 자동 분석을 수행하여 거의 실시간으로 로그 데이터에 통찰력을 확보하기를 원하는 경우도 있으며, 또한 특정 네트워크 특성을 대시보드에 시각화하여 VPC 내의 네트워크 트래픽을 더욱 명확하게 이해하기를 원하기도 합니다. 그렇다면 S3로의 효율적인 로그 아카이브와 실시간 네트워크 분석 및 데이터 시각화를 모두 구현하려면 어떻게 해야 할까요? 해결책은 CloudWatch, Amazon Kinesis, AWS Glue 및 Amazon Athena의 기능을 조합하는 것이지만, 이 솔루션을 설정하고 모든 서비스를 구성하는 과정은 상당히 어렵게 느껴질 수 있습니다.
이 블로그 게시물에서는 VPC 플로우 로그 데이터를 수집, 분석 및 시각화하는 전체 솔루션을 설명해 드립니다. 그 뿐 아니라, AWS는 고객이 이 솔루션을 계정에서 효율적으로 배포할 수 있게 해 주는 단일 AWS CloudFormation 템플릿을 생성했습니다.
솔루션 개요
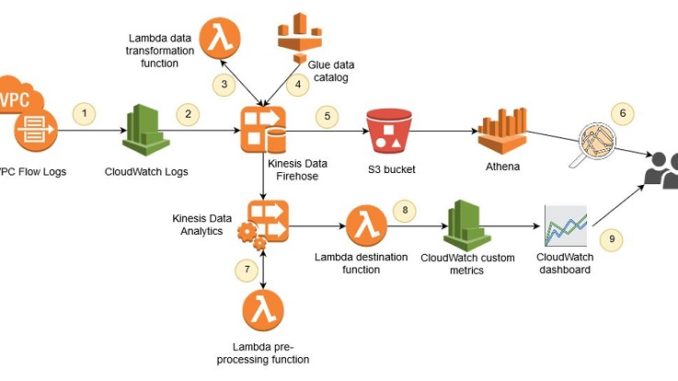
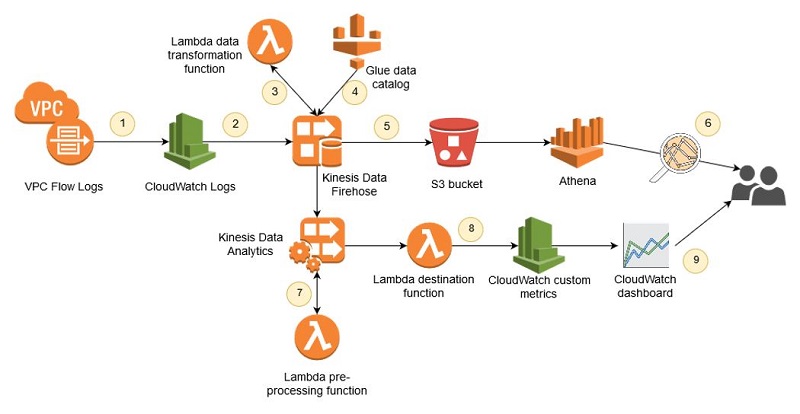
이 섹션은 전반적인 아키텍처와 각각의 솔루션 단계를 설명합니다.

우리가 원하는 것은 플로우 로그 데이터를 1회성 또는 임시 방식으로 쿼리하는 기능입니다. 또한 이러한 데이터를 거의 실시간으로 분석하기를 원합니다. 따라서 플로우 로그 데이터는 두 개의 솔루션 경로를 따라 이동하게 됩니다. 임시 쿼리의 경우에는 Amazon Athena를 사용합니다. Athena를 사용하면 표준 SQL을 통해 S3에 저장된 데이터를 쿼리할 수 있습니다. 쿼리 성능을 개선하고 비용을 절감하는 Athena 모범 사례 중 하나는 Apache Parquet과 같은 열 형식으로 데이터를 저장하는 것입니다. 이 솔루션은 Kinesis Data Firehose의 레코드 형식 변환 기능을 사용하여 플로우 로그 데이터를 Parquet으로 변환한 다음 파일을 S3에 저장합니다. 데이터를 열 형식의 압축 파일로 변환하면 Athena가 쿼리를 실행할 때 S3에서 더 적은 양의 데이터를 스캔하게 되므로 비용이 절감되고 쿼리 성능이 개선됩니다.
CloudWatch 로그에서 Kinesis Data Firehose로 데이터를 스트리밍하는 방식은 플로우 로그 데이터에 대한 실시간에 가까운 분석을 위한 두 번째 경로를 제공합니다. Kinesis Data Analytics는 로그 데이터가 Kinesis Data Firehose로 전달되는 즉시 분석을 수행하는 데 사용됩니다. 이 분석 애플리케이션은 플로우 로그에서 주요 데이터를 집계하고 거의 실시간으로 구현되는 CloudWatch 대시보드에 사용될 사용자 지정 CloudWatch 지표를 생성합니다.
각 단계를 자세히 살펴보겠습니다.
1. VPC Flow Logs
VPC Flow Logs 기능은 VPC 내의 네트워크 플로우를 포함합니다. 이 솔루션에서는 단일 VPC 내의 모든 네트워크 트래픽을 캡처하고자 한다고 가정하겠습니다. CloudFormation 템플릿을 사용하면 캡처하고자 하는 VPC를 정의할 수 있습니다. 플로우 로그의 각 라인은 네트워크에서 소스와 대상의 두 주체 사이를 이동하는 패킷에 대한 공백으로 구분된 정보를 포함하고 있습니다. 로그 라인은 소스 및 대상 IP 주소와 포트, 패킷 수, 해당 데이터에 수행한 작업을 비롯한 세부 정보를 포함합니다. 이러한 작업의 예로는 수락 또는 거부 여부에 대한 정보가 있습니다. 다음은 전형적인 플로우 로그의 예입니다.
라인의 각 항목에 대한 자세한 정보는 플로우 로그 레코드를 참조하십시오. 참고로 VPC 플로우 로그는 CloudWatch Logs에 전송되기 전에 약 10분의 버퍼링 시간을 가집니다.
2. Kinesis Data Firehose로의 스트리밍
CloudWatch Logs 구독을 생성하면 플로우 로그가 CloudWatch Logs에 도착했을 때 자동으로 스트리밍됩니다. 이 솔루션의 구독 필터는 Kinesis Data Firehose를 대상으로 사용합니다. Kinesis Data Firehose는 스트리밍 데이터를 Amazon S3와 같은 데이터 스토어로 로딩하는 가장 효과적인 방법입니다. 또한 CloudWatch Logs 구독 필터는 공백으로 분리된 로그 라인을 구문 분석하고 로그의 각 라인에 대해 구조화된 JSON 객체를 생성하도록 구성되어 있습니다. 객체의 각 속성에 대한 명명법은 VPC Flow Logs에 의해 각 요소에 대해 정의된 이름을 따릅니다. 따라서 앞에서 참조된 예제 로그 라인은 다음과 같은 JSON 레코드로 스트리밍됩니다.
CloudWatch Logs 구독은 데이터를 구성된 대상에 gzip으로 압축된 레코드 컬렉션 형태로 전송합니다. 데이터를 분석하려면 먼저 압축을 해제해야 합니다.
3. AWS Lambda를 사용한 레코드 압축 해제
스트리밍 데이터를 최종 대상 위치에 저장하기 전에 변환 또는 보강이 필요한 경우가 있습니다. 이 솔루션에서는 CloudWatch Logs에서 스트리밍되는 데이터의 압축을 해제해야 합니다. Amazon Kinesis Data Firehose 데이터 변환 기능을 사용하면 AWS Lambda 함수로 데이터의 압축을 해제할 수 있습니다. 함수 호출은 Kinesis Data Firehose에서 관리합니다. 함수 내에는 데이터는 압축이 해제되어 Kinesis Data Firehose로 반환됩니다. Lambda 함수의 완전한 소스 코드는 여기에서 찾을 수 있습니다.
4. Apache Parquet으로 데이터 변환
Amazon Athena의 성능을 활용하려면 데이터를 S3에 저장하기 전에 Apache Parquet으로 변환해야 합니다. 이 변환 작업은 Kinesis Data Firehose의 레코드 형식 변환 기능을 사용하여 수행합니다. JSON에서 Parquet으로 변환하려면 Kinesis Data Firehose가 스키마를 알아야 합니다. 이를 위해서는 Glue 데이터 카탈로그에서 테이블을 구성합니다. 이 테이블에서 수신되는 JSON 레코드의 속성을 테이블의 필드에 매핑합니다.

5. Amazon S3에 데이터 유지
Kinesis Data Firehose의 데이터 형식 변환 기능을 사용할 때 유일하게 지원되는 대상은 S3입니다. Kinesis Data Firehose는 S3에 Parquet 파일을 생성하기 전에 일정 시간 동안 또는 데이트 크기 임계값이 충족될 때까지 데이터를 버퍼링합니다. 일반적으로 Parquet으로 파일을 변환하면 효과적인 파일 압축 효과를 얻을 수 있습니다. 그러나 파일 크기가 너무 작은 경우에는 Athena 쿼리에 적합하지 않습니다. S3에서 생성되는 파일 크기를 최대화하려면 솔루션이 15분 또는 128MB 수준으로 버퍼링하도록 구성해야 합니다. 그러나 필요에 따라 Kinesis Data Firehose 콘솔을 사용하여 이 구성을 조정할 수 있습니다.
6. Athena에서 SQL을 사용하여 플로우 로그 쿼리하기
이 솔루션에서는 Athena가 Glue 데이터 카탈로그에 생성된 데이터베이스와 테이블을 사용하여 플로우 로그 데이터를 쿼리 가능한 상태로 만듭니다. 이 기사 뒷부분에서는 샘플 쿼리를 검토해 볼 것입니다.

7. Kinesis Data Analytics를 통해 거의 실시간으로 네트워크 플로우 분석
첫 여섯 단계를 따라 데이터를 처리하면 Athena에서 SQL을 사용하여 플로우 로그 데이터를 쿼리할 수 있습니다. 이는 임시 쿼리를 수행하거나 긴 시간에 걸쳐 생성된 데이터를 쿼리하는 데 이상적입니다. 그러나 데이터를 최대한 활용하려면 데이터가 생성된 즉시 분석을 실행해야 합니다. 이를 위해 솔루션은 Kinesis Data Analytics (KDA)를 사용하여 플로우 로그를 분석하고 즉각적인 통찰을 추출합니다. Kinesis Data Analytics (KDA)를 사용하면 SQL을 통해 스트리밍 데이터를 쿼리할 수 있으므로 데이터에 대한 즉각적인 통찰을 얻을 수 있습니다. 이 솔루션에서는 KDA 애플리케이션이 Kinesis Data Firehose에서 gzip으로 압축된 레코드를 Lambda 함수를 사용하여 압축 해제한 다음 플로우 로그 데이터를 분석하여 중요 정보를 집계합니다. KDA 애플리케이션은 다음과 같은 집계를 생성합니다.
- 15분마다 거부된 TCP 패킷 수
- 15분마다 프로토콜별로 거부된 TCP 패킷 수
이러한 지표는 15분 기간에 걸쳐 집계됩니다. 기간이 종료되면 KDA는 Lambda 함수를 호출하여 집계된 값을 함수 입력값으로 전달합니다.
8. 사용자 지정 CloudWatch 지표로 집계 저장
15분 기간이 종료되면 KDA가 Lambda 함수를 호출하여 집계된 값을 전달합니다. Lambda 함수는 이 값을 CloudWatch에 사용자 지정 지표로 저장합니다. 이렇게 하면 솔루션에서 CloudWatch 경보를 사용하여 해당 지표에 대한 경보를 지원하고 해당 지표를 기반으로 한 사용자 지정 대시보드를 활성화합니다.
9. CloudWatch 대시보드의 집계 데이터 보기
CloudWatch 대시보드는 CloudWatch 콘솔에서 사용자 지정 가능한 홈 페이지로서 리소스를 모니터링하는 단일 보기를 제공합니다. CloudWatch 대시보드를 사용하면 AWS 리소스의 지표와 경보에 대한 사용자 지정 보기를 생성할 수 있습니다. 이 솔루션에서는 KDA 애플리케이션에서 생성된 사용자 지정 집계를 모니터링하는 대시보드를 생성합니다. 이 솔루션에서는 시작을 위한 샘플 대시보드를 생성하지만, 고객은 지표를 검토하여 자신의 요구 사항을 충족하는 대시보드와 경보를 생성해야 합니다.
솔루션 배포
이 솔루션을 고객 자신의 계정에 배포하려면 CloudFormation 템플릿을 사용하여 스택을 생성해야 합니다. 솔루션 스택은 미국 동부(버지니아 북부), 미국 서부(오레곤) 및 EU(아일랜드) AWS 리전에 배포할 수 있습니다. 배포하려면, 원하는 배포 리전에 대한 링크를 선택합니다. 해당 리전에 대한 CloudFormation 콘솔이 열리고 템플릿 URL이 미리 채워집니다.
이제 다음 리전에 솔루션을 배포합니다.
CloudFormation을 위한 스택 생성 마법사가 열립니다. 템플릿 위치 정보는 미리 채워집니다. [다음]을 클릭하면 몇 가지 템플릿 파라미터에 대한 값을 제공할 수 있는 메시지가 표시됩니다.

각 파라미터의 속성을 살펴보겠습니다.
- Stack name – CloudFormation 스택에 대한 이름입니다. 기본 이름을 재지정할 수 있지만 재지정할 때에는 최대 16자의 짧은 이름을 선택하고 소문자만 사용하도록 합니다. 여기에 사용하는 값은 이 스택에서 생성하는 다양한 리소스의 이름에 접두사로 사용됩니다. 짧은 소문자 이름을 제공해야 이러한 리소스의 이름이 리소스 이름 지정 규칙을 통과할 수 있습니다.
- S3BucketName — Parquet 파일이 전달되는 S3 버킷의 이름입니다. 이 이름은 전역적으로 고유해야 합니다.
- VPCId — 플로우 로그를 캡처할 기존 VPC의 ID입니다.
[Next]을 선택하고 CloudFormation 마법사의 나머지 부분에 대한 기본값을 수락합니다. 몇 분 내에 스택이 생성됩니다.
플로우 로그 데이터 분석
스택을 배포한 후에는 최대 15분을 기다려야 Athena에서 데이터를 쿼리하거나 CloudWatch 대시보드에서 데이터를 볼 수 있습니다. VPC 내의 네트워크 트래픽에 대해 자세히 알아보기 위해 Athena에서 실행 가능한 몇 가지 샘플 쿼리를 살펴보겠습니다.
스택을 배포한 리전의 Athena 콘솔로 이동합니다. 콘솔에서 “vpc_flow_logs”라는 이름의 데이터베이스를 선택합니다. 이 데이터베이스는 “flow_logs”라는 이름의 테이블 하나를 포함하고 있는 것을 볼 수 있습니다. 다음 쿼리를 실행하여 해당VPC에서 어느 프로토콜이 가장 많이 거부되는지 확인합니다.
다음 예와 같은 결과를 얻을 수 있습니다.

이 예에서는 프로토콜 상자에 대한 값이 IANA (Internet Assigned Numbers Authority)에서 정의한 표준을 따릅니다. 그러므로 이전 예에서 상위 두 개의 거부된 프로토콜은 TCP 및 ICMP을 의미합니다.
VPC 내의 네트워크 트래픽을 이해하는 데 도움이 되는 몇 가지 추가적인 쿼리를 소개해 드리겠습니다.
다음은 지난 2주 동안 패킷이 거부된 상위 10개의 IP 주소를 식별합니다.
다음은 가장 많은 수의 HTTPS 요청을 수신하는 상위 10개 서버를 식별합니다.
이제 Kinesis Data Analytics을 통해 실시간으로 수행하는 분석을 살펴 보겠습니다. 기본적으로 이 솔루션은 “VPC-Flow-Log-Analysis”라는 이름의 대시보드를 생성합니다. 이 대시보드에는 몇 가지 위젯을 생성해 두었습니다. KDA에 의해 생성되는 집계 데이터는 아래 예와 같이 몇 가지 차트를 통해 표시됩니다.

이 예는 Rejected Packets per Protocol 차트가 모든 사용 가능한 프로토콜의 부분 집합만 표시하도록 생성되었음을 보여줍니다. 이 위젯을 수정하면 해당 환경과 관련성이 있는 프로토콜을 표시할 수 있습니다.
다음 단계
이 블로그 게시물에서 설명한 솔루션은 VPC Flow Logs의 분석을 시작하는 효율적인 방법을 제공합니다. 이 솔루션을 최대한 활용하려면 다음과 같은 단계를 고려해 보십시오.
- Glue 테이블에 파티션을 생성하여 Athena의 쿼리 성능을 최적화합니다. 현재 솔루션은 Y/M/D/H에 의해 파티셔닝된 S3에 데이터를 생성하지만 이러한 S3 접두사는 Glue 파티션에 자동으로 매핑되지 않습니다. 이는 Athena 쿼리가 모든 Parquet 파일을 스캔함을 의미합니다. 데이터 양이 증가함에 따라 Athena 쿼리 성능은 점차 감소합니다. 파티셔닝 및 Athena 튜닝에 대한 자세한 내용은 Top 10 Performance Tuning Tips for Amazon Athena를 참조하십시오.
- 추가의 VPC 또는 다른 리전에 솔루션을 적용합니다. 계정이 여러 VPC를 포함하거나 인프라가 여러 리전에 배포된 경우, 해당 리전에 스택을 생성해야 합니다. 동일한 리전 내에 여러 VPC가 있는 경우에는 VPC 콘솔을 사용하여 각각의 추가 VPC에 대해 새로운 플로우 로그를 생성할 수 있습니다. 스택을 최초로 생성할 때 함께 생성된 대상 로그 그룹(CloudFormation 템플릿의 CWLogGroupName 파라미터 값)으로 전송되도록 플로우 로그를 구성하십시오.
- CloudWatch 대시보드의 기본 위젯을 수정합니다. 스택은 몇 가지 기본 CloudWatch 대시보드를 생성합니다. 그러나 필요에 따라 해당 환경의 플로우 로그에서 얻고자 하는 통찰을 기반으로 더 많은 대시보드를 생성할 수 있습니다.
- Athena에서 추가 쿼리를 생성하여 네트워크의 동작에 대해 더 많은 정보를 학습합니다.
결론
이 블로그 게시물에서 제공해 드린 솔루션을 사용하면 VPC의 네트워크 트래픽을 신속하게 분석할 수 있습니다. 이 솔루션은 거의 실시간으로 정보를 제공할 뿐 아니라 데이터 기록을 쿼리하는 기능도 제공합니다. 시스템의 요구 사항을 충족하는 추가적인 쿼리와 시각화로 확장하면 이 솔루션의 활용도를 극대화할 수 있습니다.
참고 자료
이 게시물이 도움이 되었다면 Analyze Apache Parquet optimized data using Amazon Kinesis Data Firehose, Amazon Athena, and Amazon Redshift 및 Preprocessing Data in Amazon Kinesis Analytics with AWS Lambda도 읽어보십시오.
 Allan MacInnis는 Amazon Web Services의 솔루션스 아키텍트입니다. 그는 AWS의 고객이 Amazon Kinesis를 사용한 스트리밍 데이터 솔루션을 구축하도록 돕습니다. 그는 여가 시간에 산악 자전거를 타고 가족과의 소중한 시간을 즐깁니다.
Allan MacInnis는 Amazon Web Services의 솔루션스 아키텍트입니다. 그는 AWS의 고객이 Amazon Kinesis를 사용한 스트리밍 데이터 솔루션을 구축하도록 돕습니다. 그는 여가 시간에 산악 자전거를 타고 가족과의 소중한 시간을 즐깁니다.
이 글은 AWS Bigdata 블로그의 Analyze and visualize your VPC network traffic using Amazon Kinesis and Amazon Athena 한국어 번역본입니다.
Source: Amazon Kinesis와 Amazon Athena를 활용한 VPC 네트워크 트래픽의 분석과 시각화


Leave a Reply