Amazon Kinesis Analytics을 이용한 실시간 핫스팟 기능
오늘 Amazon은 스트리밍 데이터에서 “핫스팟”을 감지하는 Amazon Kinesis Data Analytics의 새로운 Machine Learning 기능을 발표합니다. Kinesis Data Analytics는 2016년 8월에 출시된 이래 꾸준히 기능이 추가되었습니다.
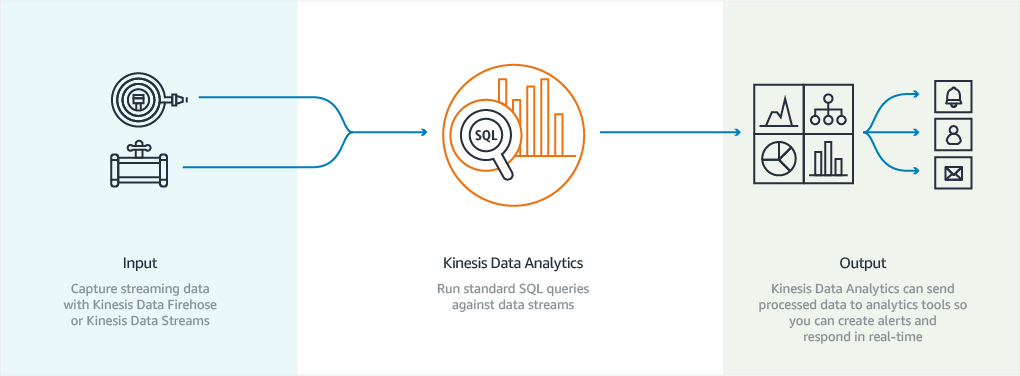
알다시피 Kinesis Data Analytics는 완벽하게 관리되는 스트리밍 데이터용 실시간 처리 엔진으로, SQL 쿼리를 작성하여 데이터에서 의미를 도출하고 결과를 Kinesis Data Firehose, Kinesis Data Streams 또는 AWS Lambda 함수에 출력합니다.
새로운 HOTSPOT 함수는 Kinesis의 기존 Machine Learning 기능에 추가되어 고객이 자율 스트리밍 기반 Machine Learning 알고리즘을 활용할 수 있도록 합니다. 데이터 과학 또는 Machine Learning과 관련한 전문 지식이 없는 고객도 이 기능을 활용할 수 있습니다.

핫스팟
이 HOTSPOTS 함수는 새로운 Kinesis Data Analytics SQL 함수로, 복잡한 Machine Learning 모델을 명시적으로 구축하거나 교육하지 않고도 데이터에서 상대적으로 밀집한 리전을 찾는 데 사용할 수 있습니다. 즉각적인 주의가 필요한 데이터의 하위 섹션을 파악하고 핫스팟을 Kinesis 데이터 스트림 또는 Firehose 제공 스트림으로 스트리밍하거나 AWS Lambda 함수를 실행하여 프로그래밍 방식으로 조치를 취하는 데 필요합니다.
이 기능을 활용하여 운영을 간소화할 수 있는 시나리오는 무궁무진합니다. 교통 체증에 대한 시공간 데이터를 주고받는 카 쉐어링 프로그램 또는 자율 주행 자동차 플릿을 떠올려보십시오. 또는 여러 대의 서버가 과열되기 시작하면서 HVAC 문제를 나타낸다고 상상해보십시오. HOTSPOTS 은 시공간 데이터에 국한되지 않으면 여러 문제 도메인에 걸쳐 적용할 수 있습니다.
이 함수는 몇 가지 간단한 구문을 따르며 DOUBLE, INTEGER, FLOAT, TINYINT, SMALLINT, REAL및 BIGINT 데이터 형식을 받습니다.
이 HOTSPOT 함수는 커서를 입력으로 받아 핫스팟을 설명하는 JSON 문자열을 반환합니다. 예를 살펴보면 더 쉽게 이해할 수 있습니다.
Kinesis Data Analytics를 사용한 핫스팟 감지
일례로 택시 승하차 위치를 추적하는 NY 택시 및 리무진 위원회의 간단한 데이터 세트를 살펴보겠습니다. 이 데이터는 대부분 이미 S3에 포함되어 있으며 s3://nyc-tlc/에서 공개적으로 이용할 수 있습니다. Kinesis Data Analytics에 피드로 전송될 택시 레코드를 사용하여 Kinesis Data Stream을 로드하는 간단한 python 스크립트를 작성해보겠습니다. 마지막으로, 이 모든 데이터를 Amazon Elasticsearch Service 클러스터에 연결된 Kinesis Data Firehose에 출력하여 Kibana를 사용하여 시각화해보겠습니다. 뉴욕에서 5년 동안 살았던 경험으로 미루어볼 때, 이 데이터에서는 핫스팟이 한두 개 발견될 것입니다.
먼저, 입력 Kinesis 스트림을 만들고 NYC 택시 운행 데이터를 해당 스트림으로 전송하기 시작합니다. CSV 파일 중 하나에서 데이터를 읽는 간단한 python 스크립트를 작성하고 boto3를 사용하여 레코드를 Kinesis로 푸시했습니다. 레코드는 어떤 방법으로든 입력할 수 있습니다.
import csv
import json
import boto3
def chunkit(l, n):
"""Yield successive n-sized chunks from l."""
for i in range(0, len(l), n):
yield l[i:i + n]
kinesis = boto3.client("kinesis")
with open("taxidata2.csv") as f:
reader = csv.DictReader(f)
records = chunkit([{"PartitionKey": "taxis", "Data": json.dumps(row)} for row in reader], 500)
for chunk in records:
kinesis.put_records(StreamName="TaxiData", Records=chunk)다음으로, Kinesis Data Analytics 애플리케이션을 만들고 택시 데이터의 입력 스트림을 원본으로 추가합니다.



그런 다음 스키마를 자동으로 감지합니다.

이제 핫스팟을 감지하여 애플리케이션의 Real Time Analytics 섹션에 추가하는 간단한 SQL 스크립트를 작성합니다.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
"pickup_longitude" DOUBLE,
"pickup_latitude" DOUBLE,
HOTSPOTS_RESULT VARCHAR(10000)
);
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
SELECT "pickup_longitude", "pickup_latitude", "HOTSPOTS_RESULT" FROM
TABLE(HOTSPOTS(
CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM_001"),
1000,
0.013,
20
)
);

이 HOTSPOTS 함수는 입력 스트림, 창 크기, 스캔 반경, 핫스팟으로 카운팅할 최소 포인트 수를 받습니다. 이들 값은 애플리케이션에 따라 달라지지만 원하는 결과를 얻을 때까지 콘솔에서 손쉽게 조작할 수 있습니다. 파라미터 자체에 대한 세부 정보는 설명서에서 참조할 수 있습니다. 이 HOTSPOTS_RESULT 는 핫스팟을 중심으로 경계 상자를 그릴 수 있는 몇 가지 유용한 JSON을 반환합니다.
{
"hotspots": [
{
"density": "elided",
"minValues": [40.7915039, -74.0077401],
"maxValues": [40.7915041, -74.0078001]
}
]
}
원하는 결과를 얻은 경우 스크립트를 저장하고 애플리케이션을 Amazon Elastic Search Service Firehose Delivery Stream에 연결할 수 있습니다. 그러면 Firehose에서 중간 Lambda 함수를 실행하여 레코드를 지리적 작업에 보다 적합한 형식으로 변환할 수 있습니다. 그런 다음 Elasticsearch에서 매핑을 업데이트하여 핫스팟 객체를 Geo-Shape로 인덱싱할 수 있습니다.
마지막으로, Kibana에 연결하여 결과를 시각화할 수 있습니다.

맨하튼은 역시 매우 분주한 도시군요.
지금 이용 가능
이 기능은 Kinesis Data Analytics가 제공되는 모든 기존 리전에서 사용할 수 있습니다. 이 기능은 수많은 애플리케이션에 즉각적으로 가치를 가져올 수 있는 Kinesis Data Analytics의 매우 흥미로운 신기능이라고 생각합니다. Twitter 또는 댓글을 통해 이 기능을 어디에 활용할 수 있는지 의견을 나누어봅시다.
– Randall

Leave a Reply