Amazon S3 및 AWS Glue를 이용한 데이터 레이크 구축하기
데이터 레이크(Data Lake)는 다양한 유형의 대량 데이터를 처리해야 하는 과제를 해결하는 데이터 저장 및 분석 방법으로서 점차 인기를 얻고 있습니다. 데이터 레이크를 사용하면 모든 데이터(정형 및 비정형)를 중앙 집중식 리포지토리 한 곳에 저장할 수 있습니다. 데이터를 있는 그대로 저장할 수 있으므로 데이터를 사전 정의된 스키마로 변환할 필요가 없습니다.
많은 기업들은 데이터 레이크에서 Amazon S3를 사용하는 데 따르는 이점을 잘 알고 있습니다. 예를 들어, 스토리지를 컴퓨팅과 분리한 상태에서 오픈 데이터 형식을 지원하는 Amazon S3는 매우 내구력 있는 경제적 객체 시작점으로서 모든 AWS 분석 서비스와 연동됩니다. Amazon S3는 데이터 레이크의 토대이지만, 다른 서비스를 추가하여 업무상 필요에 맞게 데이터 레이크를 조정할 수 있습니다. AWS를 기반으로 데이터 레이크를 구축하는 방법에 대한 자세한 내용은 데이터 레이크란 소개를 참조하십시오.
데이터 레이크를 사용하는 데 따른 주요 과제 중 하나는 데이터를 찾고 스키마와 데이터 형식을 이해하는 것이므로 Amazon은 최근에 AWS Glue를 도입했습니다. AWS Glue를 사용하면 데이터의 구조와 형식을 검색하여 Amazon S3 데이터 레이크로부터 신속하게 비즈니스 통찰을 이끌어 내는 데 필요한 시간과 노력을 획기적으로 줄일 수 있습니다. 이 서비스는 자동으로 Amazon S3 데이터를 크롤링하여 데이터 형식을 식별한 후 다른 AWS 분석 서비스에 사용할 스키마를 제안합니다.
이 게시물에서는 AWS Glue를 사용하여 Amazon S3에서 데이터를 크롤링하고 다른 AWS 제품군에서 사용 가능한 메타데이터 저장소를 구축하는 과정을 안내합니다.
AWS Glue 기능
AWS Glue는 까다롭고 시간이 많이 소요되는 데이터 검색, 변환, 작업 일정 조정 등과 같은 작업은 간소화 및 자동화하는 종합 관리형 데이터 카탈로그 및 ETL(추출, 변환, 로드) 서비스입니다. AWS Glue는 데이터 소스를 크롤링하고 CSV, Apache Parquet, JSON 등을 비롯한 널리 사용되는 데이터 형식과 데이터 유형에 대해 사전 구축된 분류자를 사용하여 데이터 카탈로그를 생성합니다.
AWS Glue는 최신 데이터 아키텍처의 핵심 구성 요소인 Amazon S3, Amazon RDS, Amazon Athena, Amazon Redshift 및 Amazon Redshift Spectrum과 통합되어 있으므로 데이터 이동과 관리를 원활하게 조율할 수 있습니다.
AWS Glue 데이터 카탈로그는 Apache Hive 메타스토어와 호환되며 Hive, Presto, Apache Spark, Apache Pig 등 널리 사용되는 도구를 지원합니다. 또한 Amazon Athena, Amazon EMR 및 Amazon Redshift Spectrum과 직접 통합됩니다.
이와 함께 AWS Glue 데이터 카탈로그는 사용 편의성과 데이터 관리 기능을 지원하기 위해 다음과 같은 확장을 제공합니다.
- 검색을 통해 데이터 찾기
- 분류를 통해 파일 식별 및 구문 분석
- 버전 관리를 통해 변화하는 스키마 관리
자세한 내용은 AWS Glue 제품 세부 정보를 참조하십시오.
Amazon S3 데이터 레이크
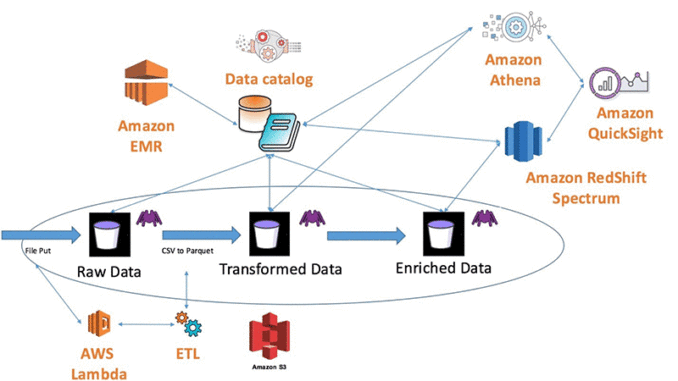
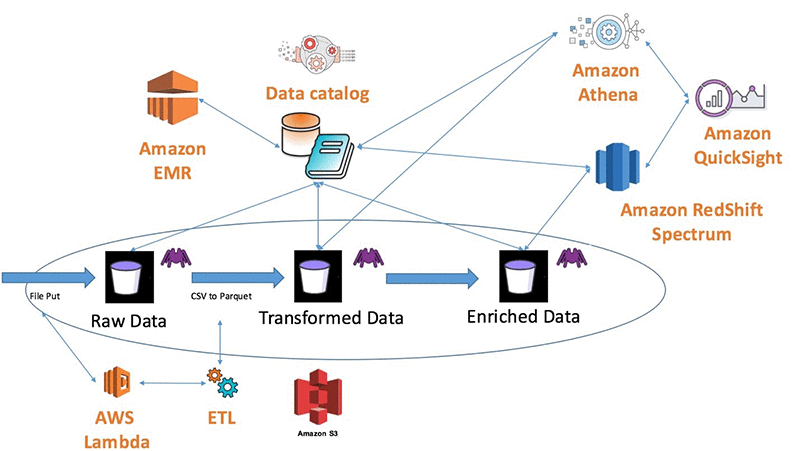
AWS Glue는 Amazon S3 데이터 레이크의 필수 구성 요소이며, 최신 데이터 분석을 위한 데이터 카탈로그 및 변환 서비스를 제공합니다.

이전 그림에는 다양한 분석 사용 사례에 대한 데이터가 준비되어 있습니다. 처음에는 변경 불가능한 원본 형식으로 데이터를 수집합니다. 그런 다음 데이터를 변환하고 보강하여 각 사용 사례에 유용하게 만들 수 있습니다. 이 예에서는 원시 CSV 파일을 Amazon Athena에서 사용할 수 있는 Apache Parquet으로 변환합니다. Amazon Athena에서 변환된 데이터를 사용하여 성능을 높이고 비용을 절감할 수 있습니다.
또한 다른 데이터 세트와 결합하는 방식으로 데이터를 보강하여 추가적인 통찰력을 얻을 수 있습니다. AWS Glue 크롤러는 작업 트리거 또는 사전 정의된 일정에 따라 데이터 단계별로 테이블을 생성합니다. 이 예에서는 AWS Lambda 함수를 사용하여 원시 데이터 S3 버킷에 새 파일이 추가될 때마다 ETL 프로세스를 트리거합니다. 이 테이블을 사용하면 Amazon Athena, Amazon Redshift Spectrum 및 Amazon EMR에서 표준 SQL 또는 Apache Hive를 사용하여 모든 단계의 데이터를 쿼리할 수 있습니다. 이 구성은 민첩한 비즈니스 인텔리전스를 제공하여 다양한 데이터로부터 빠르고 쉽게 비즈니스 가치를 창출하는 인기 설계 패턴입니다.
직접 실습하기
이 연습에서는 데이터베이스 정의, Amazon S3 버킷에서 데이터를 탐색하도록 크롤러 구성, 테이블 생성, Parquet으로 CSV 파일 변환, Parquet 데이터에 대한 테이블 생성, Amazon Athena를 사용하여 데이터 쿼리 등과 같은 작업을 연습합니다.
데이터 검색
AWS Management Console에 로그인하고 AWS Glue 콘솔을 엽니다. [Analytics] 섹션에서 AWS Glue를 찾을 수 있습니다. AWS Glue는 현재 미국 동부(버지니아), 미국 동부(오하이오) 및 미국 서부(오레곤) 지역에서 사용 가능합니다. 다른 AWS 지역이 수시로 추가됩니다.
데이터를 검색하려면 먼저 데이터베이스를 추가해야 합니다. 데이터베이스는 다수의 테이블로 구성된 집합입니다.
- 콘솔에서 [Add database]를 선택합니다. [Database name]에 nycitytaxi를 입력하고 [Create]를 선택합니다.

- 탐색 창에서 [ Tables]를 선택합니다. 테이블은 열 이름, 데이터 유형 정의, 데이터 세트에 대한 기타 메타데이터로 구성됩니다.

- nycitytaxi 데이터베이스에 테이블을 추가합니다. 크롤러를 사용하거나 수동으로 테이블을 추가할 수 있습니다. 크롤러는 데이터 스토어에 연결하여 분류자의 우선 순위 지정 목록을 통해 데이터의 스키마를 결정하는 프로그램입니다. AWS Glue는 CSV, JSON, Avro 등과 같은 일반 파일 형식에 대한 분류자를 제공합니다. grok 패턴을 사용하여 고유한 분류자를 작성할 수도 있습니다.

- 크롤러를 추가하려면 데이터 원본을 입력합니다(Amazon S3 버킷 즉, s3://aws-bigdata-blog/artifacts/glue-data-lake/data/). 이 S3 버킷에는 2017년 1월 한 달 동안의 녹색 택시에 대한 모든 승차 정보로 구성된 데이터 파일이 포함되어 있습니다.

- [Next]를 선택합니다.

- [IAM role]에 대한 드롭다운 목록에서 기본 역할 AWSGlueServiceRoleDefault를 선택합니다.

- [Frequency]에서 [Run on demand]를 선택합니다. 크롤러를 온디맨드로 실행하거나 일정에 따라 실행하도록 설정할 수 있습니다.

- [Database]에서 nycitytaxi를 선택합니다. 적절한 방법을 선택하려면 AWS Glue에서 스키마 변경을 처리하는 방법을 잘 알고 있어야 합니다. 이 예에서는 테이블을 변경 사항으로 업데이트합니다. 스키마 변경에 대한 자세한 내용은 AWS Glue 개발자 안내서에서 크롤러를 사용하여 테이블 카탈로그 작성을 참조하십시오.

- 단계를 검토하고 [Finish]를 선택합니다. 크롤러를 실행할 준비가 되었습니다. [Run it now]를 선택합니다.

크롤러가 종료되면 테이블 한 개가 추가되었습니다.

- 왼쪽 탐색 창에서 [Tables]를 선택한 다음 [data]를 선택합니다. 이 화면에서는 스키마, 속성 및 기타 중요한 정보를 비롯한 테이블에 대해 설명합니다.


CSV에서 Parquet 형식으로 데이터 변환
이제 CSV에서 Parquet로 데이터를 변환하는 작업을 구성하여 실행할 수 있습니다. Parquet는 Amazon Athena 및 Amazon Redshift Spectrum과 같은 AWS 분석 서비스에 적합한 컬럼 형식입니다.
- 왼쪽 탐색 창에서 [ETL]을 선택하고 [Jobs]를 선택한 다음 [Add job]을 선택합니다.

- [Name]에 nytaxi-csv-parquet를 입력합니다.
- [IAM role]에서 AWSGlueServiceRoleDefault를 선택합니다.
- [This job runs]에서 [A proposed script generated by AWS Glue]를 선택합니다.
- 스크립트를 저장할 고유한 Amazon S3 경로를 제공합니다.
- 임시 디렉터리에 대한 고유한 Amazon S3 디렉터리를 제공합니다.
- [Next]를 선택합니다.

- 데이터 원본에서 [data]를 선택합니다.

- [Create tables in your data target]을 선택합니다.
- [Parquet]를 형식으로 선택합니다.
- 결과를 저장할 새 위치(기존 객체가 없는 새 접두사 위치)를 선택합니다.

- 스키마 매핑을 확인하고 [Finish]를 선택합니다.

- 작업을 확인합니다. 이 화면에서는 전체 작업 보기를 제공하며 작업을 편집, 저장 및 실행할 수 있습니다. AWS Glue에서 이 스크립트를 생성했습니다. 필요한 경우 스크립트를 직접 생성할 수 있습니다.

- [Save]를 선택한 다음 [Run job]을 선택합니다.
Parquet 테이블 및 크롤러 추가
작업이 완료되면 크롤러를 사용하여 Parquet 데이터에 대한 새 테이블을 추가합니다.
- [Crawler name]에 nytaxiparquet를 입력합니다.

- S3를 [Data store]로 선택합니다.
- [ETL]에서 선택한 Amazon S3 경로 포함

- [IAM role]에서 AWSGlueServiceRoleDefault를 선택합니다.

- [Database]에 대해 nycitytaxi를 선택합니다.
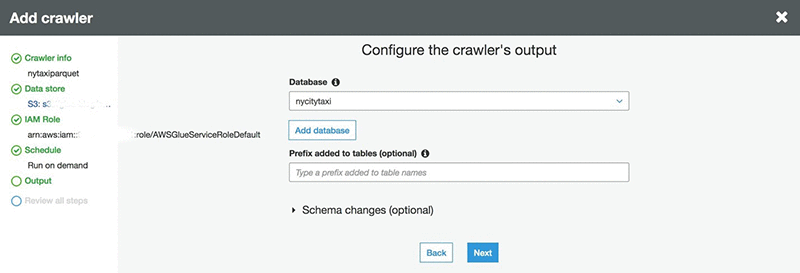
- [Frequency]에서 [Run on demand]를 선택합니다.

크롤러가 완료되면 nycitytaxi 데이터베이스에 두 개의 테이블이 있습니다. 즉, 원시 CSV 데이터용 테이블 한 개와 변환된 Parquet 테이블 한 개가 있습니다.
Amazon Athena를 사용하여 데이터 분석
Amazon Athena는 표준 SQL을 사용해 Amazon S3에 저장된 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스입니다. Athena를 사용하여 CSV 데이터를 쿼리할 수 있습니다. 하지만 Parquet 파일 형식을 사용하면 데이터를 쿼리하는 데 필요한 시간과 비용을 획기적으로 줄일 수 있습니다. 자세한 내용은 Analyzing Data in Amazon S3 using Amazon Athena 블로그 게시물을 참조하십시오.
AWS Glue를 Amazon Athena와 함께 사용하려면 Athena 데이터 카탈로그를 AWS Glue 데이터 카탈로그로 업그레이드해야 합니다. Athena 데이터 카탈로그를 업그레이드하는 방법에 대한 자세한 내용은 이 단계별 지침을 참조하십시오.
-
- Athena용 AWS Management Console을 엽니다. 쿼리 편집기에 nycitytaxi의 두 테이블이 표시됩니다.

- Athena용 AWS Management Console을 엽니다. 쿼리 편집기에 nycitytaxi의 두 테이블이 표시됩니다.
표준 SQL을 사용하여 데이터를 쿼리할 수 있습니다.
- nytaxigreenparquet를 선택합니다.
- 유형
"nycitytaxi"에서 *를 선택합니다."data" limit 10; - [Run Query]를 선택합니다.

마무리
이 게시물에서는 AWS Glue 및 Amazon S3를 사용하여 데이터 레이크의 기초를 얼마나 쉽게 구축할 수 있는지를 보여 줍니다. AWS Glue를 사용하여 Amazon S3에서 데이터를 크롤링하고 Apache Hive 호환 메타데이터 저장소를 구축하면 AWS 분석 서비스와 주요 Hadoop 에코시스템 도구를 통해 메타데이터를 사용할 수 있습니다. 이 AWS 서비스 조합은 강력하고 간편하며 비즈니스 통찰을 더 빠르게 얻을 수 있도록 해줍니다.
자세한 내용은 다음 블로그 게시물을 참조하십시오.
- Amazon Athena를 사용하여 스키마-온-리드(Schema-On-Read) 분석 파이프라인 구축
- AWS Glue, Amazon Athena 및 Amazon QuickSight를 사용하여 다양한 공급자의 데이터 조율, 쿼리, 시각화
작성자 소개
 Gordon Heinrich는 글로벌 SI(Systems Integrator)로 활동 중인 솔루션 아키텍트이며, 파트너 및 고객과 협력하여 데이터 레이크를 구축하고 AWS 분석 서비스를 사용하는 데 유용한 설계 지침을 제공합니다. 여가 시간에는 가족과 함께 시간을 보내거나 콜로라도에서 스키, 하이킹, 산악 자전거 등을 즐깁니다.
Gordon Heinrich는 글로벌 SI(Systems Integrator)로 활동 중인 솔루션 아키텍트이며, 파트너 및 고객과 협력하여 데이터 레이크를 구축하고 AWS 분석 서비스를 사용하는 데 유용한 설계 지침을 제공합니다. 여가 시간에는 가족과 함께 시간을 보내거나 콜로라도에서 스키, 하이킹, 산악 자전거 등을 즐깁니다.
이 글은 AWS BigData 블로그의 Build a Data Lake Foundation with AWS Glue and Amazon S3의 한국어 버전입니다.

Leave a Reply