Amazon SageMaker IP Insights 알고리즘을 사용하여 의심스러운 IP 주소 탐지하기
오늘은 Amazon SageMaker를 위한 새로운 IP Insights 알고리즘에 대해 살펴보겠습니다. IP Insights는 IP 주소를 기반으로 비정상적인 동작과 사용 패턴을 탐지하는 비지도 학습 알고리즘입니다. 이 블로그 게시물에서는 IP 주소를 이용한 사기성 동작을 식별하는 데 있어서의 문제점을 소개하고 Amazon SageMaker IP Insights 알고리즘을 설명합니다. 또한, 실제 애플리케이션에 활용하는 방법을 제시하고 해당 알고리즘을 사용하여 얻어진 몇 가지 결과를 공유합니다.
악의적인 활동 차단
악의적인 활동에는 계정 탈취 수법이 주로 이용됩니다. 계정 탈취란 온라인 뱅킹 계좌, 관리자 콘솔, 소셜 네트워킹 또는 웹메일 계정에 대한 액세스를 포함한 온라인 리소스에 대한 무단 액세스를 말합니다. 일반적으로 탈취 시도에는 도용되거나 도난 당하거나 유출된 자격 증명이 사용되며 무단 액세스는 해당 계정에 일반적이지 않은 IP 주소에서 발생하는 경우가 많습니다(예: 사용자의 컴퓨터가 아니라 해커의 컴퓨터에서 발생).
계정 탈취를 방지하기 위한 일반적인 방어 수단은 이전에 발견된 적 없는 IP 주소에서 온라인 리소스에 액세스할 경우 플래그를 지정하는 것입니다. 플래그가 지정된 상호 작용은 차단하거나, 해당 사용자에게 추가 인증 양식을 제시하고 추가 인증을 요구할 수 있습니다(예: SMS에 응답). 하지만 대부분의 사용자는 이전에 사용한 적 없는 IP 주소에서 온라인 리소스에 주기적으로 액세스합니다. 따라서 “새 IP에 플래그를 지정하는” 방법을 사용할 경우 오탐율이 비정상적으로 높아지고 고객 경험이 불량해집니다.
사용자들은 주기적으로 새로운 IP 주소에서 온라인 리소스에 액세스하지만 새로운 IP 주소가 완전히 무작위로 선택되는 것은 아닙니다. 사용자의 이동 습관과 인터넷 서비스 제공업체의 IP 할당 전략과 같은 몇 가지 잠재 요인이 할당에 영향을 미칩니다. 일반적으로 이 같은 잠재적 요인을 모두 명시적으로 열거하기는 어렵습니다. 하지만 온라인 리소스의 액세스 패턴을 파악하면 새로운 IP 주소가 예상된 이벤트인지 아니면 비정상적인 이벤트인지를 예측할 수 있습니다. Amazon SageMaker IP Insights 알고리즘은 이 같은 예측을 정밀하게 수행하도록 설계되었습니다.
Amazon SageMaker IP Insights 알고리즘
Amazon SageMaker IP Insights 알고리즘은 통계적 모델링과 신경망을 사용하여 온라인 리소스(예: 온라인 뱅킹 계좌) 및 IPv4 주소 간의 상관관계를 캡처합니다. 작동 원리를 설명하자면, 이 알고리즘은 함께 사용할 경우 각 포인트가 서로 인접하는 온라인 리소스와 IP 주소의 벡터 표현을 학습합니다. 알고리즘 자체는 명시적으로 모델링하지 않아도 잠재적 요인을 학습하고 적용할 수 있습니다.
학습 절차는 각각의 가능한 IP 주소와 리소스를 임의의 포인트에 무작위로 할당하는 식으로 시작됩니다. 온라인 리소스는 모든 불투명 문자열 식별자(예: 사용자 ID, UUID 등)입니다. 기본적으로 이 알고리즘은 IP 주소와 리소스를 나타내는 포인트가 학습 데이터에 서로 연관되어 있는 경우 함께 반복적으로 푸시하고 연관되지 않은 경우에는 서로 멀리 풀링합니다.
특별한 IPv4 주소를 사용하는 신경망 아키텍처로 인해 이 알고리즘은 IP 주소의 동작을 모델링합니다. 또한 이전에 학습 데이터에서 발견된 적 없는 경우에도 정확한 벡터 표현을 컴퓨팅할 수 있습니다.
Amazon SageMaker IP Insights 알고리즘은 액세스 로그를 분석하고 IP 주소와 사용자의 액세스 기록을 기준으로 로그인 이벤트 또는 온라인 트랜잭션과 같은 액세스 시도가 의심스러운 것인지 여부를 예측하는 데 사용할 수 있습니다. 이전에 발견된 적이 없는 IP 주소인 경우에도 마찬가지입니다.
실습 예제: 웹 애플리케이션에 대한 의심스러운 로그인 시도 탐지
이 예제에서는 Amazon SageMaker IP Insights 알고리즘을 사용하여 웹 애플리케이션에 대한 의심스러운 로그인 이벤트를 식별하는 방법을 설명합니다. 자세한 내용을 알아보거나 직접 사용해 보려면 여기에서 노트북 예제를 시험해 보십시오.
이 예제에서는 공격자가 자격 증명을 도용하여 사용자의 계좌에 대한 로그인을 시도하는 계좌 탈취 시나리오를 중점적으로 살펴봅니다. 이 같은 악의적인 로그인 시도는 평소 사용되지 않던 IP 주소에서 발생하는 경우가 많습니다. 따라서 Amazon SageMaker IP Insights 알고리즘을 사용하여 해당 IP 주소를 식별합니다. 먼저, 데이터 세트를 준비하고 모델을 학습시키는 방법을 설명한 다음, 인사이트에 대해 조치를 취할 애플리케이션에서 학습된 모델을 호출하는 방법을 설명합니다.
단계 1. 데이터 세트 준비
Amazon SageMaker IP Insights 알고리즘은 사용자 계정과 같은 리소스와 IP 주소를 연결하는 데이터가 있는 모든 상황에 적용할 수 있습니다. 이러한 데이터는 애플리케이션 또는 웹 서버 로그, 애플리케이션 데이터베이스 또는 데이터 웨어하우스에서 직접 가져오는 경우가 많습니다. 첫 단계로, 2개의 필드(EntityId, IpAddress)가 포함된 헤더 없는 CSV 파일에서 Amazon S3로 데이터를 가져옵니다. <EntityID>는 리소스의 모든 문자열 식별자일 수 있으며 <IpAddress>는 IPv4 점 표기법 형식이어야 합니다. 예를 들어 데이터 세트는 다음과 같은 형식어야 합니다.
모델이 어떻게 작동하는지 살펴보기 위해 데이터 세트를 학습 데이터 세트와 테스트 세트로 분할했습니다. 이 알고리즘은 테스트 세트를 사용하여 유효한 액세스 시도와 유효하지 않은 액세스 시도를 얼마나 정확하게 식별할 수 있는지를 평가하는 방식으로 예측을 합니다. 일반적으로 연속된 며칠 분량의 데이터 세트를 학습에 사용한 후 이후 며칠 간의 데이터 세트를 테스트 세트에 사용합니다.
모범 사례로서 가급적 긴 기간(최소 며칠에서 몇 주)에 걸친 데이터를 사용하고 주기적으로 새 데이터로 재학습시켜 모델을 새로 고치는 것을 권장합니다. 또한, 이 알고리즘은 학습 데이터 세트를 셔플링 한 경우 더 나은 성능을 발휘합니다.
단계 2. 모델 학습시키기
Amazon SageMaker에서 IP Insights 알고리즘을 사용하여 모델을 학습시킵니다. 몇 가지 하이퍼파라미터(알고리즘 구성)를 조정하면 성능을 높일 수 있습니다. vector_dim은 IP 주소와 계정이 모두 표시되는 잠재적 공간의 크기입니다. num_entity_vectors는 알고리즘이 계정에 대해 유지하는 서로 구분되는 벡터 표현의 수입니다. 계정에서 벡터로의 매핑은 해시 함수에 의해 결정되므로 num_entity_vectors를 고유한 계정의 총 수보다 크게 설정해야 해시 충돌의 악영향이 최소화됩니다. 마지막으로, shuffled_negative_sampling_rate 및 random_negative_sampling_rate는 각각 현재 미니 배치에서 IP 주소를 무작위로 선택하고 IP 주소를 무작위로 생성함으로써 학습 데이터의 각 기록에 대해 생성되는 부정적인 샘플의 수를 지정합니다. 모델 하이퍼파라미터에 대한 자세한 설명은 여기에서 확인할 수 있습니다.
학습 작업 파라미터와 모델 하이퍼파라미터를 설정한 후에는 다음과 같이 Amazon SageMaker IP Insights 모델의 학습을 시작합니다.
단계 3. 의심스러운 로그인 식별
학습이 완료되고 나면 온라인 추론을 위해 엔드포인트에 모델을 배포합니다.
이제 애플리케이션 코드에서 모델을 호출할 수 있습니다. Amazon SageMaker는 관리형 서비스이므로 Java, Python 등 다양한 언어에서 모델을 호출할 수 있습니다.
Python
Java 8
단계 4. 모델 성능 평가
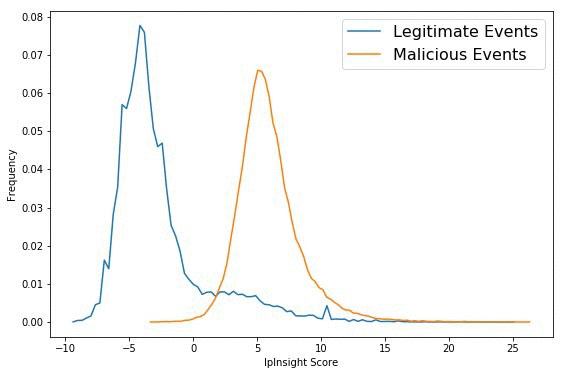
이제 모델이 배포되었으므로 이 모델이 인증된 로그인 이벤트와 의심스러운 시도 또는 사기성 시도를 서로 구분할 수 있는지를 검증해야 합니다. 이를 위해 모델이 테스트 데이터 세트에서 합법적인 로그인 이벤트에 할당한 점수와 부정적으로 샘플링된 무작위 이벤트의 점수를 서로 비교합니다. 부정적인 이벤트를 생성하기 위해 테스트 데이터 세트에서 로그인 이벤트를 선택하고 계정을 동일하게 유지하며 IP 주소를 무작위로 생성된 IP 주소로 바꿉니다. 이렇게 하면 부정적인 이벤트가 알 수 없는 IP 주소에서 알려진 계정에 액세스하는 기록이 되므로 어느 정도 악의적인 로그인 시도와 유사하게 됩니다.

보다시피 Amazon SageMaker IP Insights 모델은 악의적인 이벤트에 훨씬 높은 점수를 부여하며 2개의 분포가 명확하게 구분됩니다.
단계 5. 모델 성능 및 임계값 조정
이제 정상적인 이벤트와 악의적인 이벤트의 점수 범위를 확인할 수 있으므로 선택할 임계값과 취해야 할 조치를 더 효과적으로 선택할 수 있습니다. 모델의 점수를 사용하여 휴대폰에 일회용 코드를 전송하거나 보안 질문을 표시하는 등의 추가 인증 요청을 트리거한다면 임계값이 0 근처가 될 가능성이 큽니다. 이 경우 악의적인 로그인을 시도한 인물은 추가 인증 요청에 직면하게 됩니다. 플래그가 지정되는 합법적인 트래픽이 늘어나겠지만 이로 인해 불편을 겪는 사용자는 정상적인 사용자 중 극히 일부에 지나지 않습니다. 반면 이 점수를 기준으로 수동 조사를 트리거한다면 10 근처의 임계값을 선택할 것입니다. 이 경우 오탐률이 훨씬 적은 동작점에 해당합니다. 즉, 일부 악의적인 이벤트를 놓치지만 수동 조사 대상으로 선택된 이벤트는 실제로 악의적인 이벤트일 확률이 훨씬 높아집니다.
결과 및 기준선 방식과의 비교
알고리즘을 설계할 때는 사용자 로그인의 내부 데이터 세트에 대한 성능을 평가합니다. 이 섹션에서는 의심스러운 로그인을 탐지하는 데 사용했던 기준선 방식과 비교하는 방법으로 알고리즘의 성능을 평가하고자 합니다. 먼저, 앞서 설명한 “새로운 IP에 플래그를 지정하는” 방식의 두 가지 변형된 형태와 비교합니다.
- IP 테이블 방식: 이 방식에서는 학습 기간 동안 해당 IP 주소가 해당 계정에 사용된 적이 없는 경우 악의적인 로그인 이벤트로 간주합니다.
- 서브넷 테이블 방식: 이 방식은 앞서 설명한 방식보다 느슨한 버전입니다. 이 방식에서는 학습 기간 동안 동일한 /24 서브넷의 IP 주소가 해당 계정에 사용된 적이 없는 경우 악의적인 로그인 이벤트로 간주합니다.
공격자의 IP 주소는 피해자가 사용하는 IP 주소와 다를 확률이 매우 높기 때문에 이 두 방식은 간단하지만 효과적이며 100%에 가까운 정탐률을 실현하는 경우도 많습니다. 하지만 보다시피 합법적인 사용자가 학습 기간 동안 사용한 적이 없는 IP 주소에서 로그인하는 경우도 있기 때문에 오탐률이 높다는 단점이 있습니다. Amazon SageMaker IP Insights 알고리즘의 가장 중요한 이점 중 하나는 이전에 사용된 적이 없더라도 가능성이 높은 IP 주소를 계정과 연관 지음으로써 높은 오탐률을 줄이는 것입니다.
Amazon SageMaker IP Insights를 기준선과 비교하기 위해 레이블이 지정된 테스트 사례를 만들었습니다. 이 사례에서는 합법적인 트래픽의 데이터 세트에 1%의 악의적인 트래픽을 인위적으로 주입합니다. 그런 다음 두 가지 방식을 사용하여 데이터 세트의 각 이벤트에 점수를 매깁니다.

ROC(Receiver Operating Characteristics) 곡선에서 기준선 방식이 20%의 FPR(오탐률)로 100%의 TPR(정탐률)에 도달하는 것으로 관찰됩니다. 반면 Amazon SageMaker IP Insights 모델은 약 10%의 훨씬 낮은 오탐률로 100%의 정탐률을 실현합니다. 또한 기준선 모델은 유연성이 낮으며 유일한 동작점은 TPR=100% 및 FPR~20%입니다. 반면 Amazon SageMaker IP Insights 모델은 임계값 조정을 통해 더 낮은 FPR 값에서 작동하도록 구성할 수 있습니다. 앞서 설명하듯이 FPR이 낮으면 점수가 높은 이벤트가 수동 조사를 트리거하는 경우에 유용합니다.
결론
이 게시물에서는 Amazon SageMaker IP Insights 모델을 사용하여 의심스러운 로그인 이벤트를 식별하는 방법을 설명하고 Amazon SageMaker IP Insights 모델이 기준선 방식보다 훨씬 나은 성능을 발휘한다는 것을 보여 주었습니다. 또한 이제 Amazon SageMaker에 IP Insights 모델이 있으므로 Amazon SageMaker 자동 모델 튜닝을 이 모델에 사용하여 더 나은 성능을 실현할 수도 있습니다.
 Jared Katzman은 AWS AI Labs 조직의 소프트웨어 엔지니어입니다. 이 조직은 기계 학습 및 기술을 사회적 선행에 활용하는 방법을 연구합니다. 여가 시간을 활용하여 기술에 관심이 있는 LGBTQ+ 학생들을 위한 멘토링 프로그램도 운영하고 있습니다.
Jared Katzman은 AWS AI Labs 조직의 소프트웨어 엔지니어입니다. 이 조직은 기계 학습 및 기술을 사회적 선행에 활용하는 방법을 연구합니다. 여가 시간을 활용하여 기술에 관심이 있는 LGBTQ+ 학생들을 위한 멘토링 프로그램도 운영하고 있습니다.
 Baris Coskun은 AWS External Security Services의 수석 응용 과학자로, 기계 학습과 정보 보안을 연구하는 과학자 팀을 이끌고 있습니다.
Baris Coskun은 AWS External Security Services의 수석 응용 과학자로, 기계 학습과 정보 보안을 연구하는 과학자 팀을 이끌고 있습니다.
감사의 말
이 프로젝트의 연구 내용에 대해 소중한 의견을 준 AWS Payments & Fraud 팀의 Jakub Zablocki, Jianbo Liu, Zak Jost와 초기에 도움을 준 Amazon AI의 Eric Kim, Pranav Garg에게 감사를 전합니다.
이 글은 AWS Machine Learning Blog의 Detect suspicious IP addresses with the Amazon SageMaker IP Insights algorithm의 한국어 번역으로 정도현 AWS 테크니컬 트레이너가 감수하였습니다.
Source: Amazon SageMaker IP Insights 알고리즘을 사용하여 의심스러운 IP 주소 탐지하기


Leave a Reply