Amazon SageMaker Notebook에서 (Amazon EMR기반) Apache Spark와의 연동 환경 구축 방법
지난 AWS re:Invent 2017에서 처음 소개된 Amazon SageMaker는 데이터 과학과 머신 러닝 워크플로우를 위한 완전 관리형 서비스를 제공하고 있습니다. 특히 모델을 만드는데 사용되는 Jupyter notebook 인터페이스는 SageMaker에서 대단히 중요한 구성 요소 중 하나입니다. 한편Amazon Elastic MapReduce (Amazon EMR) 상에서 동작하는 Apache Spark 클러스터에 notebook 인스턴스를 연결시켜서 SageMaker의 성능을 훨씬 더 향상시킬 수 있습니다. 참고로 EMR은 대량의 데이터를 처리하기 위한 관리형 프레임워크입니다. 따라서 이와 같은 조합을 통해 대용량 데이터에 대한 모델 구축이 가능해집니다.
Apache Spark는 빅 데이터를 빠른 속도로 처리할 수 있게 해주는 오픈소스 기반의 클러스터 컴퓨팅 프레임워크로, MLlib이라는 머신 러닝 작업을 위한 라이브러리도 제공하고 있습니다. 여기서는 SageMaker notebook과 Spark EMR 클러스터 간의 연동을 손쉽게 하기 위해, Livy라는 툴을 사용하는 방법을 설명하겠습니다. 참고로 Livy는 Spark 클라이언트를 사용하지 않고도 어디서든 Spark 클러스터와 상호 연동할 수 있게 해주는 오픈소스 REST 인터페이스입니다.
이 글에서는, (1) Spark EMR 클러스터 생성 방법, (2) SageMaker와 EMR간에 통신을 위한 보안 그룹(Security groups) 설정 방법, (3) SageMaker 노트북 열기, (4) Livy를 이용하여 EMR 상의 Spark에 노트북을 연동하는 방법 등을 차근차근 알아보기로 합니다. 최종적으로 이렇게 만든 환경에서 PySpark, PySpark3, Spark, SparkR notebook을 실행시킬 수 있을 것입니다.
Amazon EMR Spark 와 Livy 설치
우선 AWS 관리 콘솔(console) 왼쪽 상단의 Services 를 클릭하시고 펼쳐진 AWS services 메뉴 중 Analytics군에 있는 EMR을 선택한 후, Create Cluster 버튼을 클릭합니다. 이후 나타나는 화면에서 “Quick Options” 옆에 파란색 굵은 글씨로 표시된 Go to advanced options를 클릭합니다
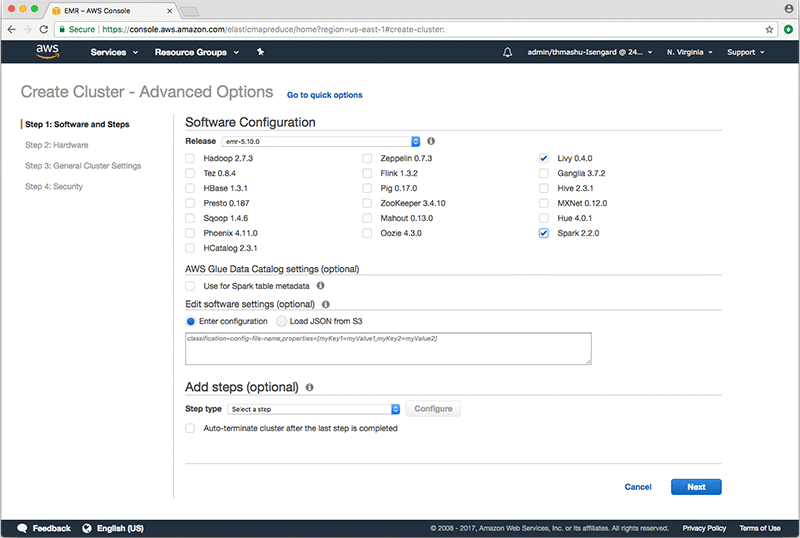
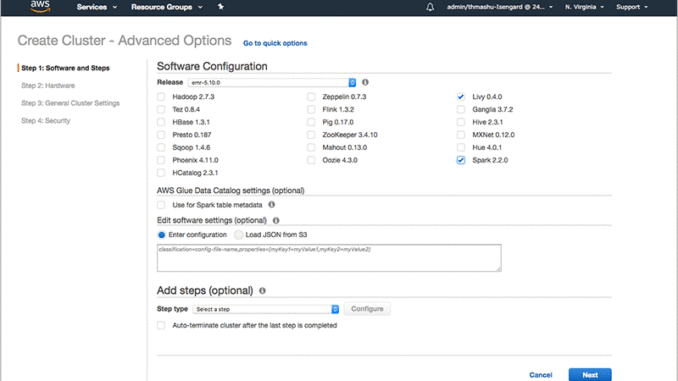
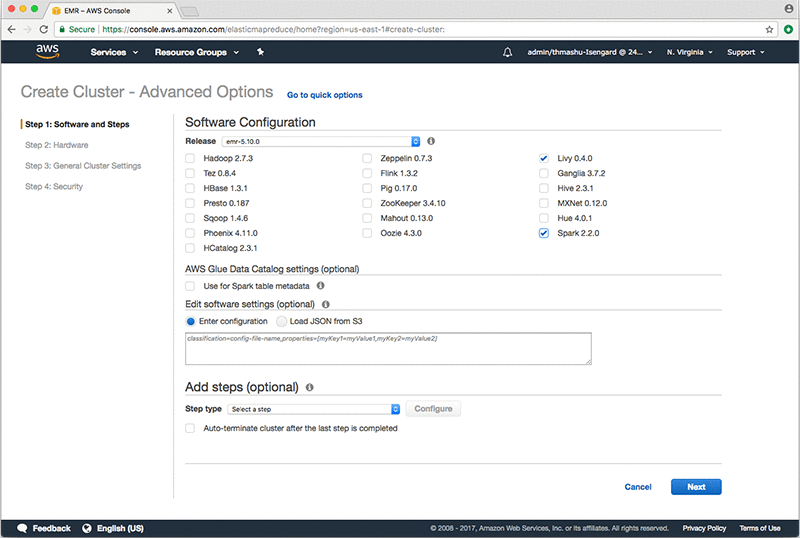
위의 그림과 같이 Spark와 Livy만 체크하고 나머지 솔루션의 체크박스는 모두 해제합니다 (각 솔루션 별 버전은 EMR Release 버전에 따라 다를 수 있습니다). 이제 Next 버튼을 클릭합니다.
다음으로 Step 2: Hardware 단계에서 Network 항목에 대해 여러분이 사용할 VPC를 선택합니다. 이 블로그에서는 그림 4와 같이 sagemaker-spark 라는 이름으로 미리 만들어놓은 VPC를 사용합니다 (default VPC를 사용해서 구축 방법을 익히신 후 따로 VPC를 만들어서 사용하시는 것도 좋습니다). EC2 Subnet도 조건에 맞게 지정합니다.
이제 Next 버튼을 클릭해서 Step 3: General Cluster Settings로 넘어갑니다. General Options 에서 Cluster name에 원하는 이름을 입력합니다. 여기서 특별히 따로 지정할 것이 없으면 Next 버튼을 클릭해서 다음 단계로 넘어갑니다. Step 4: Security 에서 (필요할 경우) EC2 key pair 지정 작업 등을 수행하시고 끝으로 Create Cluster 버튼을 클릭합니다.

EMR Spark 클러스터가 만들어지고 나면, Master 노드의 Private IP 를 알아둬야 합니다. 일단 그림 5와 같이 EMR Spark 클러스터 생성이 시작되었다면 상태(Status)가 Waiting (초록색)으로 표시될 때까지 기다립니다. 생성이 완료되면 Hardware 탭을 클릭합니다.

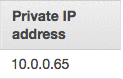
MASTER 노드의 ID를 클릭한 다음, 오른쪽 맨 끝에 있는 Private IP Address 항목을 확인합니다. 나중에 필요하므로 이 IP주소를 기록 해둡니다. 이 블로그에서는 10.0.0.65로 나와있는데, 여러분의 화면에는 다른 값으로 나타나 있을 것입니다.
보안 그룹(Security Groups) 과 포트(Ports) 설정
앞에서 EMR Spark 클러스터를 생성했으니, 다음으로 보안 그룹(Security Groups)과 관련 포트를 설정합니다. 이 작업이 완료되면 포트 번호 8998로 Livy를 통해서 SageMaker notebook과 Spark 클러스터가 서로 통신을 할 수 있게 됩니다.
AWS Management 콘솔 상단의 Services를 클릭하고 Compute – EC2 메뉴를 선택합니다. EC2의 왼쪽 메뉴에서 Security Groups를 클릭합니다. 그런 다음 버튼을 클릭합니다.
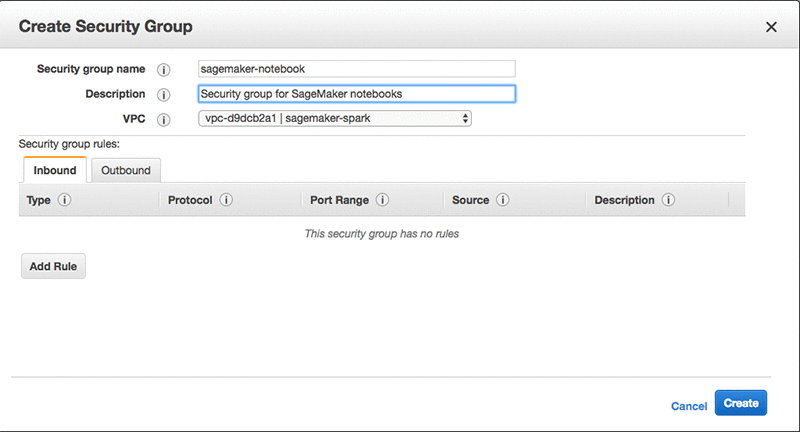
위와 같이 Security Group Name (여기서는 sagemaker-notebook), Description, 그리고 EMR 클러스터 생성에 사용했던 VPC정보 등을 입력합니다 (여기서는 sagemaker-spark).
입력을 완료한 후, Create 버튼을 클릭합니다.
이렇게 보안 그룹을 생성했습니다. 이를 통해 이 그룹에 속한 인스턴스들에 대해서만 포트를 열어줄 수 있게 되었습니다. 하지만 아직 ElasticMapReduce-master group내 포트를 열어줘야 합니다.
AWS Management 콘솔의 EC2 내 Security Groups에서, 여러분이 앞에서 만든 SageMaker notebook 용 보안 그룹 (이 블로그에서는 sagemaker-notebook 이라고 이름 붙인) 의 Group ID를 기록해둡니다. 여기서는 sg-35610640이라고 표시되어 있지만, 아마 여러분의 ID는 다른 값으로 되어 있을 것입니다.

이제 앞에서 EMR Spark클러스터를 생성할 때 자동으로 만들어졌던 EMR 마스터 노드에 대한 보안 그룹을 수정합니다. Security Groups 에서 ElasticMapReduce-master를 선택한 다음 Inbound 탭을 클릭합니다. Edit 버튼을 클릭한 후 Add Rule 버튼을 클릭합니다.
Custom TCP Rule 으로 지정하고, Protocol은 TCP, Port Range는 8998, Source는 Custom 과 앞에서 만든 SageMaker notebook 보안 그룹의 Group ID (예: sg-35610640)로 설정합니다. 필요할 경우 Description에 Livy Port라고 입력 해놓으면 나중에 관리를 효율적으로 할 수 있습니다.
앞의 작업을 다 마친 후, Save 버튼을 클릭합니다. 이렇게 해서 SageMaker notebook인스턴스와EMR Spark 클러스터가 Livy를 통해서 통신할 수 있는 중요한 포트를 성공적으로 열었습니다.
Amazon SageMaker Notebook 세팅
지금까지 우리는 Livy를 이용해서 동작하는 EMR Spark 클러스터도 마련했고, 사용 가능한 포트도 확보했습니다. 하지만, 아직 SageMaker notebook 인스턴스는 없죠. 이제 만들어서 실행시켜 보기로 합니다.
AWS Management 콘솔의 Services 에서 Amazon SageMaker를 클릭합니다. 그런 다음 버튼을 클릭합니다.
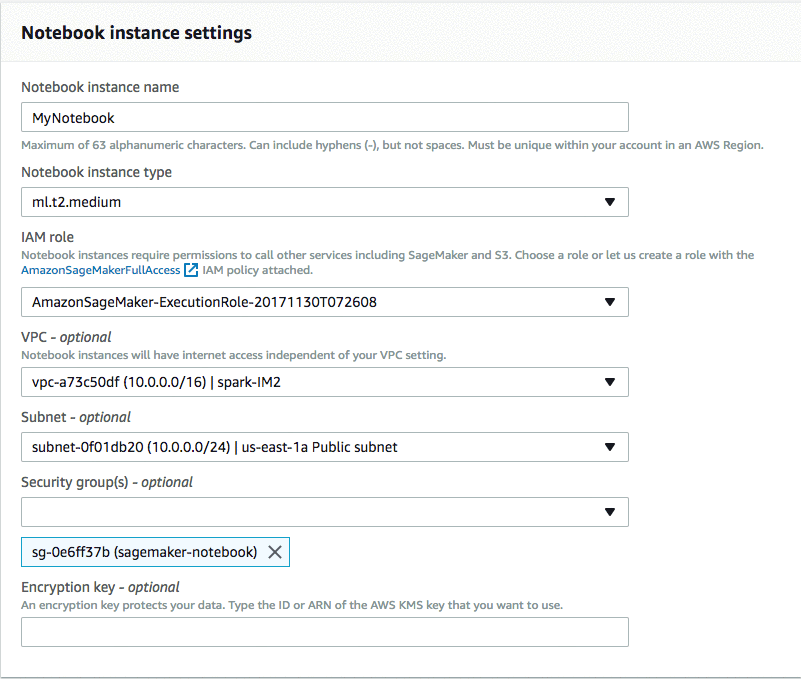
Notebook instance name을 입력하고, Notebook instance type을 선택합니다. 여러분의 notebook 인스턴스 이름을 작성할 때 제약이 있으니 주의하기 바랍니다(최대 63개의 alphanumeric글자, 하이픈(-) 포함 가능, 공백문자 사용 불가, AWS 리전 내에 여러분의 계정에서 중복 불가). 또, IAM role을 만들어야 합니다. 여기에는 AmazonSageMakerFullAccess과 액세스가 가능한 Amazon S3 버킷 정보가 포함되어야 합니다. 그림 11과 같이 role 생성 단계에서 액세스할 S3 버킷을 지정해줘야 합니다. 하지만 SageMaker가 Role을 생성하게끔 할 수도 있습니다.
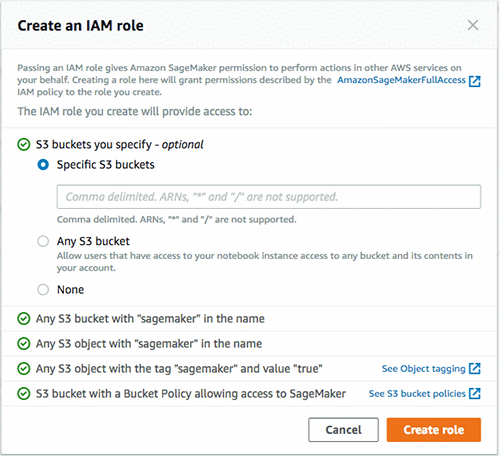
여러분이 생성할 notebook 인스턴스는 앞에서 생성한 EMR 클러스터(예: sagemaker-spark)와 동일한 VPC에 있어야 합니다. 또, EMR클러스터와 동일한 서브넷을 선택해야 합니다(EMR 클러스터 생성 단계에서 설정 정보를 참고). 끝으로 notebook 인스턴스를 위해 앞에서 생성한 보안 그룹(Security group)(예: sagemaker-notebook)을 설정합니다.
이제 Create Notebook Instance 를 클릭합니다.
SageMaker Notebook의 상태가 In Service로 바뀔 때까지 기다립니다.
Notebook과 EMR 연동
이제 EMR Spark 클러스터와 SageMaker notebook 을 확보했습니다. 하지만, 이들은 아직 연결되지 않은 상태입니다. 다음 단계로 SageMaker에 있는 Sparkmagic을 세팅해서 EMR 클러스터를 찾도록 해줍니다. Amazon SageMaker콘솔 화면에서 왼쪽의 Notebook 메뉴를 클릭하고 (Notebook instances 화면이 나타납니다), 방금 생성한 notebook 을 찾아서 맨 오른쪽에 있는 Open 을 클릭합니다.
Jupyter 콘솔 안에서, New 를 클릭해서 나타나는 메뉴 중 아래쪽에 Terminal을 클릭합니다.

터미널 창을 열고 다음 명령어를 순서대로 입력 합니다.
- cd .sparkmagic
- wget https://raw.githubusercontent.com/jupyter-incubator/sparkmagic/master/sparkmagic/example_config.json
- mv example_config.json config.json
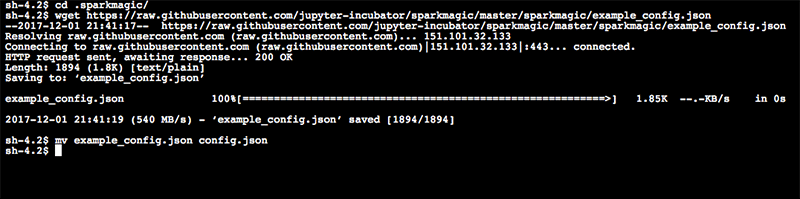
다음으로 config.json파일을 편집기로 띄워서, ‘localhost’를 앞에서 생성한 EMR Master 노드의 Private IP (예: 10.0.0.65)로 바꿉니다. 참고로, 다음과 같은 명령어를 순서대로 실행하는 것도 방법입니다:
- nano config.json
- ctrl+
- localhost
- <your EMR Master private IP>
- a
- ctrl+x
- y
- enter
이렇게 하면3가지 커널 자격 증명의 “URL” 필드에 있는 localhost의 3개 인스턴스를 대체합니다. 각자 사용하기 편리한 에디터를 사용해서 앞에서 설명한 변경사항을 적용한 후 저장합니다.
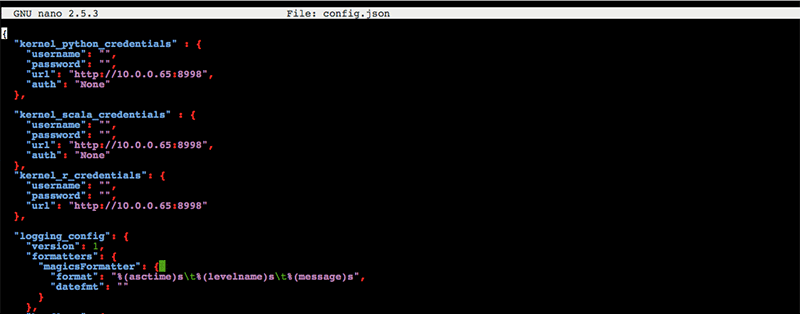
다음 단계로 넘어가기 전에 Livy 상에서 EMR 연동 테스트를 합니다. 다음 명령어를 실행합니다 (이 명령어에서 <EMR Master Private IP>라고 써 있는 부분에 여러분이 생성한 EMR 클러스터 Master 노드 인스턴스 IP 주소를 입력합니다):
- curl <EMR Master Private IP>:8998/sessions
실행 결과가 제대로 나오면 아래 그림과 같습니다:

에러가 날 경우, 보안 그룹(Security Group)에서 포트 번호를 열지 않은 것이 원인일 수 있습니다. 따라서 앞으로 돌아가서 우리가 작업했던 것들을 하나씩 점검해보시기 바랍니다!
이제 터미널 창을 닫습니다. ‘exit’ 명령어를 입력하여 터미널을 종료한 후, 해당 브라우저 창을 닫습니다. Jupyter를 이용하여 탭을 열고, ‘New’를 클릭한 다음 Sparkmagic (PySpark)를 선택합니다. 이렇게 해서 PySpark 기반의 notebook창을 엽니다. 확인 차원에서 커널을 재시작 하는 것이 좋습니다. 방법은 간단합니다. Kernel 메뉴를 선택한 다음 Restart를 실행시키면 됩니다.
이제 notebook의 첫번째 셀(cell)에서 다음 명령어를 입력한 후 실행시켜서 연동 여부를 테스트합니다
- %%info
Shift 키와 Enter 키를 동시에 눌러서 셀(cell)을 실행시킵니다. 그러면 다음과 같은 결과가 화면에 나타날 것입니다:

이제 Livy를 이용하여 EMR Spark 클러스터와 연동된 Jupyter notebook 에서 동작하는 Sparkmagic 커널 엔진을 이용할 수 있는 환경을 성공적으로 구축했습니다. 여러분의 딥러닝 데이터 분석에 도움이 되시길 바랍니다.
이 글은 AWS Professional Service의 데이터 사이언티스트인 Thomas Hughes, Stefano Stefani이 작성한 Build Amazon SageMaker notebooks backed by Spark in Amazon EMR의 번역본으로, 남궁 영환 AWS AI/ML 전문 솔루션즈아키텍트께서 정리해 주셨습니다.
Source: Amazon SageMaker Notebook에서 (Amazon EMR기반) Apache Spark와의 연동 환경 구축 방법

Leave a Reply