AWS 기반 SAP HANA 시스템 리플리케이션(SR) 비용 최적화 구성하기
일반적으로 많은 사용자들은 중요 시스템의 데이터를 보호하고 서비스의 연속성을 구현하기 위해 위해 고가용성 아키텍쳐를 고려하게 됩니다. SAP HANA Database 역시 SAP HANA System Replication (HSR) 기능을 사용하여 SAP HANA 데이터베이스의 고가용성과 재해 복구를 지원합니다. 이를 통해 동일한 데이터 센터 또는 다른 데이터 센터의 보조 위치에 데이터를 복사하고 지속적으로 동기화 할 수 있는 기능을 제공합니다. 일반적으로 이러한 고가용성 (High Availability , HA) 환경의 자동화 구성를 지원하기 위해 페이스메이커 (pacemaker) 등을 통한 HA 클러스터를 구성하고 운영하게 됩니다.
이 글에서는 AWS에서 SAP HANA Database의 고가용성 구성인 HSR을 비용 효율적으로 구축하고 운영할 수 있는 방법에 대해 알아보도록 하겠습니다.
SAP HANA Database 고가용성 개념
HANA Database는 단일 장비를 사용한 스케일-업 (Scale Up) 구조 또는 병렬적인 구성인 스케일 아웃 (Scale-out) 구조 중 하나의 형태로 설치 운영할 수 있습니다. 이 중 하나의 단일 인스턴스를 사용한 스케일-업 아키텍쳐 형태로 구성하는 경우 고가용성 환경을 구성할 수 있는 여러 시나리오들 중 성능 최적화(Performance Optimized) 시나리오와 비용 최적화 시나리오에 대해 알아보겠습니다.
두 시나리오 간의 가장 큰 차이는 보조 노드의 활용방식에 있습니다. 성능 최적화 시나리오의 경우, 보조 노드는 장애시 가장 빠르게 서비스를 재개할 수 있는 준비를 하는 형태로 구성합니다. 데이터를 메모리에 미리 로딩(Memory pre-load)함으로써 장애 발생 시 이를 감지하고 서비스를 넘겨 받는 (Takeover) 즉시 서비스를 재개할 수 있도록 평상시에 만반의 준비를 하고 있는 형태입니다. 평상시에도 동기화되는 Primary Database의 데이터가 주 노드와 동일하게 지속적으로 메모리에 적재되는 상태를 유지하기 때문에 별도의 절차 없이 Takeover가 완료되는 즉시 동기화된 데이터를 기반으로 서비스를 재개할 수 있습니다.

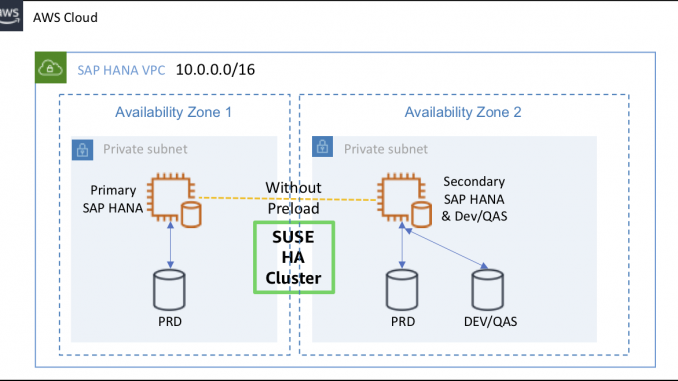
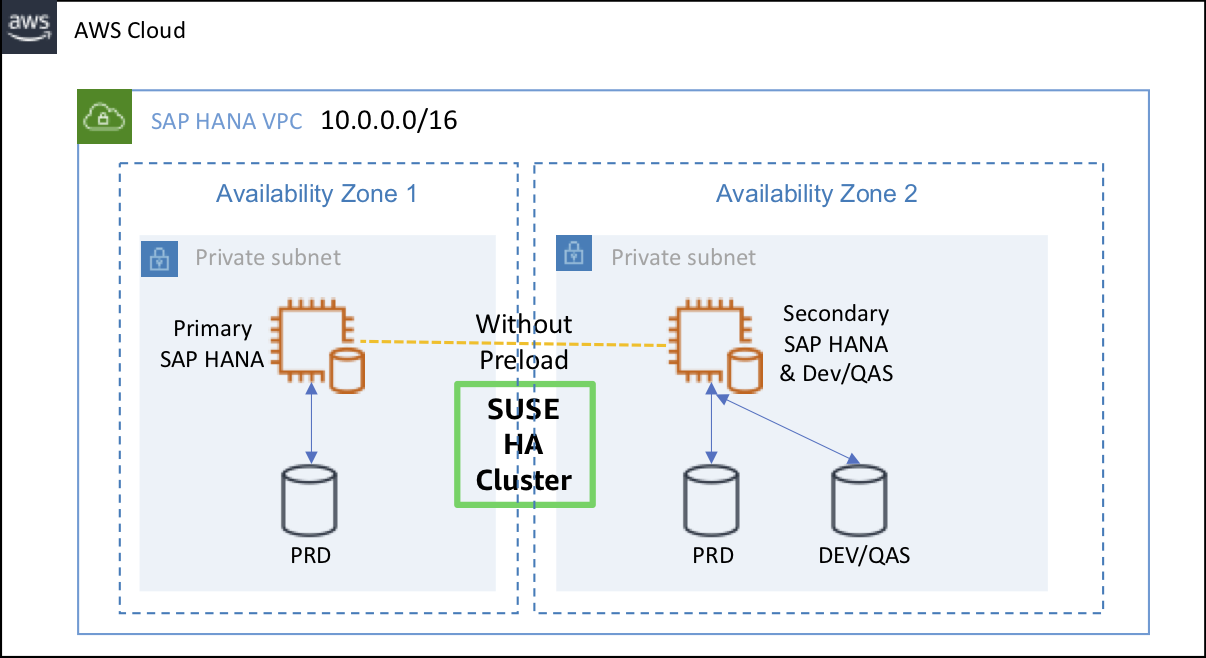
이에 반해 비용 최적화(Cost Optimized) 시나리오의 경우 평상시에는 Primary Database의 데이터에 대한 동기화만을 수행할 수 있는 최소한의 리소스만 사용하고 메모리 상에는 Data를 적재하지 않는 상태를 유지합니다. 그리고 이러한 구성에서 확보할 수 있는 미사용 리소스를 Non-Productive database (QAS, TST, 개발 등)로 운영할 수 있도록 구성하여 운영하는 방식입니다.
즉, 장애 상황이 아닌 평상시에는 보조 노드에는 운영 DB의 데이터 동기화 목적의 리소스 사용을 최소화한 Secondary Database와 QA 또는 테스트, 개발 환경 등을 위한 테스트용 DB (Non-Productive Database)가 동시에 운영되는 환경을 구성하게 되는 것입니다. 이를 통해서 별도 테스트 환경을 만들기 위한 별도의 인스턴스를 사용하지 않는 비용 효율적인 시스템을 구축하고 운영할 수 있는 장점이 있습니다.
또한, 테스트를 위해 운영 데이터와 동일하거나 유사한 데이터를 사용해야 하는 경우, 운영 데이터를 담을 수 있는 동일 사이즈의 추가적인 하드웨어를 마련하지 못한다면 테스트를 수행하지 못하여 시스템의 운영 품질을 포기해야하는 상황을 초래하게 될 수도 있습니다. 이러한 경우에도 비용 최적화 시나리오 환경에서는 평상시 Primary Database 동일한 사이즈의 장애 대비용 보조 노드를 사용 가능하므로 대량의 테스트 데이터를 사용할 수 있는 별도의 QAS, 테스트 환경을 구축하기 위한 추가 비용 지출을 최소화할 수 있을 것입니다.
비용 최적화 고려 사항
그렇다면 비용 최적화 시나리오에 대해 고려해야할 사항들은 어떤 것들이 있을까요? 이 시나리오는 비용 효율적인 구성이 가능하고 운영 품질을 향상시킬 수 있는 관점에서는 장점이 있지만 아래와 같은 사항들도 함께 고려해야 합니다.
복구 시간 목표 (Recovery Time Objective, RTO) 관점

성능 최적화 시나리오의 경우 즉각적으로 서비스를 재개할 수 있도록 평상시 Secondary 노드의 메모리상에 동기화된 데이터를 적재하고 있기 때문에 이름 그대로 장애 발생시 가장 빠르게 서비스를 복구할 수 있는 환경을 유지합니다. 이에 반해 비용 최적화 시나리오에서는 보조 노드로 서비스를 TakeOver하기 위해서는 사전 작업 단계가 필요합니다. 운영 시스템에 장애 발생 시 보조 노드는 비-운영 DB의 데이터가 메모리를 사용하고 있는 상태이므로 Takeover를 수행하려면 운영 데이터의 적재가 가능한 메모리를 확보해야하고 이를 위해서 현재 사용중인 비-운영 DB의 정지 작업이 선행되어야 합니다.
비용 최적화 시나리오의 경우에는 HANA Database 수준의 장애는 리소스 확보를 위한 사전 작업 단계를 생략하여 시간을 단축할 수 있도록 동일 노드에서 HANA Database만 다시 시작하는 옵션을 사용는 것이 권장됩니다. 각 사용자의 상황에 따라 이러한 작업 절차에 따라 추가되는 서비스 복구 시간이 비지니스 요구사항을 반영한 RTO를 만족 하는가에 대해 확인이 필요합니다.
비용 최적화 시나리오 시스템 구성 및 운영 절차 관점
성능 최적화 시나리오에 비하여 비용 최적화 시나리오 시스템을 구성하고 운영하는 절차는 상대적으로 복잡해 집니다. 비용 최적화 시나리오에서는 보조 노드에 QAS와 같은 비-운영 워크포드에 대한 고가용성 클러스터(HA Cluster) 리소스와 제약 사항들을 등록하고 관리 운영하는 절차들이 추가됩니다. 물론 이와 같은 복잡한 사항들은 HA Cluster 추가 구성 이후 많은 부분 자동화된 관리와 툴을 통해 운영하게 되지만 일정 부분 작업과 운영자의 판단이 필요한 작업 절차가 추가되므로 사용자는 작동원리를 잘 이해하고 정확한 운영 절차를 숙지할 필요가 있습니다.
그리고 주기적인 테스트를 통해 운영 안정성을 확보하는 것이 중요할 것입니다. SAP HANA on AWS 환경에서는 자동화와 더불어 쉽고 빠르게 다양한 테스트 환경을 구축하고 인프라스트렉처 레벨의 테스트도 직접 수행할 수 있기 때문에 이러한 사용자의 복잡한 시스템 환경 운영에 많은 도움이 됩니다.
장애 발생 시 중단되는 전체적인 시스템 관점

운영 절차와 관련하여 추가적으로 고려해야 할 또 하나의 내용은 보조 노드에서 중단되는 비-운영 시스템(Non Production)의 서비스 재개 문제입니다. 특히 많은 SAP HANA Database를 기반으로 하는 SAP 솔루션들이 전체적으로 운영-테스트-개발 환경 (PRD-QAS-DEV) 형태의 세가지 구성을 가집니다.
비용 최적화 시나리오에서는 장애가 발생하게 되면 비-운영 시스템인 QAS나 DEV의 DB가 중단됩니다. 이 상태에서는 운영 서비스는 정상 제공이 가능하지만 DEV 또는 QAS가 중단되기 때문에 PRD 시스템의 변경은 불가능한 상황이 전체 시스템이 복구될 때까지 지속됩니다. 일반적인 온프레미스 데이터 센터 환경에서는 시스템 복구가 물리적 서버를 추가하지 않는 이상 장애가 발생한 주 노드를 최대한 빨리 복구하여 운영 서비스를 다시 주 노드로 TakeBack하는 것 이외에는 다른 방안을 찾기 어려웠습니다.
이 TakeBack 과정 중 운영 서비스의 중단이 다시 발생하는 것도 고려해야하며 자칫 물리적인 하드웨어의 복구가 늦어지거나 서버가 대체 투입되고 다시 시스템 전체를 복구하는 등의 추가적인 시간과 노력을 필요로하는 어려운 복구 상황들 또한 자주 경험하게 됩니다. 이 부분이 물리적인 서버를 사용해야하는 데이터 센터 환경에서 비용 최적화 시나리오에 따라 구성된 HA환경에서 가장 해결하기 어려운 문제였습니다. 하지만 리소스를 탄력적으로 운영 가능한 AWS 클라우드 환경에서는 수작업 또는 AWS CloudFormation, CDK등 AWS에서 제공하는 인프라 기반 코드 (Infra as Code) 형태의 자동화를 통하여 비-운영 시스템을 별도의 인스턴스에서 실행시킬 수 있으므로 시스템 전체를 빠르게 복구할 수 있습니다.
또한 HANA Database 환경에서는 상대적으로 사이즈가 큰 전용 호스트를 사용하게 되는 경우가 많은데, 전용 호스트 복구 기능을 사용하면 네트워크 연결 끊김, 시스템 전원 중단, 물리적 호스트의 하드웨어 또는 소프트웨어 문제장애 발생 등으로 인한 시스템 장애가 감지되면 Amazon EC2가 자동으로 대체 전용 호스트를 할당하여 새로운 정상 상태의 대체 호스트로 인스턴스를 자동으로 다시 시작합니다.
이를 사용하여 다시 HA Cluster를 구성하게 되므로 TakeOver상황에서도 또 다시 발생 할 수 있는 장애에 대비할 수 있는 고가용성 환경을 빠르게 복구할 수 있고 이는 동시에 언제든 장애 발생 이전의 환경과 동일한 구성으로 TakeBack을 수행 가능한 환경이 준비됨을 의미하기도합니다. SAP HANA on AWS 환경에서는 물리적인 서버를 사용하는 환경에서의 제한 요소가 많았던 비용 최적화 시나리오와는 달리 더 비용 효율적인 방법으로 다양하고 유연한 장애 대응 운영 전략을 마련할 수 있을 것입니다.
비용 최적화 시나리오에 따른 SAP HANA SR 설치 및 테스트
AWS에서 보다 개선된 운영 정책과 비용 효율을 높일 수 있는 비용 최적화 시나리오를 고려하시는 사용자들을 위해 직접 SAP HANA SR on AWS 환경을 쉽고 빠르게 구성하고 테스트 해볼 수 있는 방법을 소개해 드립니다.
AWS SAP HANA Quick Start와 Launch Wizard for SAP

많은 작업자들이 AWS에서도 전통적인 방식에 따라 수작업을 통해 시스템을 구축하는 작업에 익숙하실 것입니다. 물론 이러한 작업 방식도 물리적인 서버를 도입하여 구축하는 것에 비해서는 훨씬 빠르게 작업할 수 있지만 그럼에도 여전히 많은 시간과 작업자의 노력을 필요로 하는 것이 사실입니다. 이에 SAP HANA Quick Start와 Launch Wizard for SAP와 같은 AWS의 서비스들은 SAP on AWS의 HA Cluster를 포함한 SAP HANA 환경을 AWS에서 시작할 수 있는 가장 쉽고 빠른 방법을 제공합니다. 단순 테스트, 설치 후 운영전환 등 여러가지 상황에 따라 활용할 수 있도록 다양한 옵션과 시나리오를 적용할 수 있습니다.
- SAP HANA on the AWS Cloud: Quick Start Reference Deployment
- AWS Launch Wizard for SAP (한국어 출시 블로그 참조)
아래와 같은 작업 절차를 수행하시면 여러분들이 직접 비용 최적화 시나리오에 따른 AWS 기반 SAP HANA SR를 설치하시고 직접 테스트할 수 있습니다. 본 블로그에는 전체 작업 절차의 개념과 주요 키워드를 중심으로 설명합니다. 실제 작업을 위한 전체 단계별 명령어, 예시 코드, Test 시나리오들은 관련 서비스의 설치가이드를 참조하시거나 저희가 마련한 SAP on AWS Advanced Workshop에서 직접 확인할 수 있습니다. 해당 워크샵의 Lab01. Setup SAP HANA Cluster와 Lab05. Config Cost Optimized Scenario를 수행하시면 시스템을 직접 설치하고 테스트할 수 있습니다.
전체 작업 절차 개념
예시 시스템의 사전 정의 요소는 다음과 같습니다.
- OS 환경 : Suse Enterprise Linux for SAP 12SP4
- SAP HANA SR on AWS HA Cluster 설치 방법 : SAP HANA QuickStart
- Node1 : 주 노드 – prihana
- Node2 : 보조 노드 – sechana
- 운영 시스템 HANA Database의 SID : PRD
- PRD System No : 00
- Primary HA Site Name : HAP
- Non-Productive Workload Dbatbase의 SID : QAS
- QAS System No : 10
- Secondary HA Site Name : HAS
- <PASSWORD> : SAP HANA QuickStart 또는 Launch Wizard for SAP 설치 시 사용한 Master Password
1. SAP HANA QuickStart 또는 Launch Wizard for SAP로 운영 HANA DB PRD의 HA 환경 구성
AWS에서 네트워크, 인스턴스를 구성하고 SAP HANA Database 설치 및 HA Cluster 구성을 수작업으로 진행하는 것보다 빠르고 쉽게 SAP HANA HA환경을 구성할 수 있습니다.
서비스를 통해 구성되는 SAP HANA on AWS는 성능 최적화 시나리오에 따라 구성되어있습니다.
설치된 HANA HSR, HA Cluster 설정을 점검합니다.
2. HA Cluster Maintenance Mode로 변경
(Cluster Command와 관련된 상세 내용은 참조 링크에 게시되어있는 가이드 문서를 참조하시기 바랍니다.)
PRD Database의 HSR 변경, QAS 추가 설치, HA Cluster 설정 변경을 위해 HA Cluster를 Maintenance 모드로 변경
sudo su -
crm configure property maintenance-mode=truePRD의 HSR 설정 변경
3. PRD의 보조 노드의 Memory reduce 설정- global.ini에 preload 옵션, Memory limit 추가
vi /usr/sap/PRD/SYS/global/hdb/custom/config/global.ini
...
[system_replication]
...
preload_column_tables = false
[memorymanager]
global_allocation_limit = <MEMORY SIZE for Secondary PRD>
...4. Takeover Hook 스크립트(SAPHanaSR.py) 수정
vi /usr/share/SAPHanaSR/SAPHanaSR.py
...
from hdb_ha_dr.client import HADRBase, Helper
import os, time
from hdbcli import dbapi
dbuser = "SYSTEM"
dbpwd = "<PASSWORD>"
dbport = 30013
stmnt1 = "ALTER SYSTEM ALTER CONFIGURATION ('global.ini','SYSTEM') UNSET ('memorymanager','global_allocation_limit') WITH RECONFIGURE"
stmnt2 = "ALTER SYSTEM ALTER CONFIGURATION ('global.ini','SYSTEM') UNSET ('system_replication','preload_column_tables') WITH RECONFIGURE"
...
def postTakeover(self, rc, **kwargs):
"""Post takeover hook."""
self.tracer.info("%s.postTakeover method called with rc=%s" % (self.__class__.__name__, rc))
if rc == 0:
# normal takeover succeeded
conn = dbapi.connect('localhost', dbport, dbuser, dbpwd)
cursor = conn.cursor()
cursor.execute(stmnt1)
cursor.execute(stmnt2)
return 0
elif rc == 1:
# waiting for force takeover
conn = dbapi.connect('localhost', dbport, dbuser, dbpwd)
cursor = conn.cursor()
cursor.execute(stmnt1)
cursor.execute(stmnt2)
return 0
elif rc == 2:
# error, something went wrong
return 0
...PRD의 HSR HA 테스트
HSR의 구성 변경과 HA 정상 작동을 테스트합니다. 이 단계는 HA Cluster 구성이 완료되지 않았으므로 수작업으로 진행됩니다.
5. HSR TAKEOVER
단계 3에서 변경된 HSR 설정이 Takeover Hook 스크립트에 의해 원상 복구됨을 확인합니다. (Node2에서 prdadm으로 수행)
sudo su - prdadm
hdbnsutil -sr_takeoverHSR TAKEBACK
6. Node1을 seconadry Database로 등록합니다. (Node1에서 prdadm으로 수행)
sudo su - prdadm
HDB stop
hdbnsutil -sr_register --remoteHost=sechana --remoteInstance=00 --replicationMode=sync —name=HAP —operationMode=logreplay
HDB start7. 동기화 상태 활성화 확인
8. HDB를 Node1로 takeback합니다. (Node1에서 prdadm으로 수행)
sudo su - prdadm
hdbnsutil -sr_takeover9. Node2에서 PRD 중지 후seconadry Database를 재등록합니다.
sudo su - hdbadm
HDB stop
hdbnsutil -sr_register --remoteHost=prihana --remoteInstance=00 --replicationMode=sync —name=HAS —operationMode=logreplay10. Node2의 PRD global.ini 재구성 후 HDB를 시작합니다. (Node2 prdadm으로 수행)
vi /usr/sap/PRD/SYS/global/hdb/custom/config/global.ini
...
[system_replication]
...
preload_column_tables = false
[memorymanager]
global_allocation_limit = <MEMORY SIZE for Secondary PRD>
...11. HDB를 시작합니다. (Node2에서 prdadm으로 수행)
sudo su - hdbadm
HDB startQAS Database 설치
12. 보조 노드에 Non Productive Workload인 SAP HANA Database(SID:QAS/SystmeNo:10)를 추가 설치합니다.
13. . HA Cluster인 pacemaker의 PRD 설정 변경과 QAS resource agent 추가합니다.
(Cluster Command와 관련된 상세 내용은 Guide나 Workshop을 참조하시기 바랍니다.)
14. Cluster Configuration 변경- 비용 최적화 시나리오에 맞춰 설정을 변경합니다.
vi crm-SAPHana-update.txt
# enter the following to crm-SAPHana-update.txt
primitive rsc_SAPHana_PRD_PRD00 ocf:suse:SAPHana
operations $id=rsc_sap_PRD_PRD00-operations
op start interval=0 timeout=3600
op stop interval=0 timeout=3600
op promote interval=0 timeout=3600
op monitor interval=60 role=Master timeout=700
op monitor interval=61 role=Slave timeout=700
params SID=PRD InstanceNumber=00 PREFER_SITE_TAKEOVER=false DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true15. 변경 내용을 반영합니다.
sudo su -
crm configure load update crm-SAPHana-update.txt16. QAS의 Resource Agent를 추가 등록합니다.
vi crm-qas.txt
# enter the following to crm-qas.txt
primitive rsc_SAP_QAS_HDB10 ocf:heartbeat:SAPDatabase
params DBTYPE="HDB" SID="QAS" InstanceNumber="10"
MONITOR_SERVICES="hdbindexserver|hdbnameserver"
op start interval="0" timeout="600"
op monitor interval="120" timeout="700"
op stop interval="0" timeout="300"
meta priority="100"17. 변경 내용을 반영합니다.
sudo su -
crm configure load update crm-qas.txt18. Constraints 설정을 추가합니다.
vi crm-cs-qas.txt
# enter the following to crm-cs-qas.txt
location loc_QAS_never_on_prihana rsc_SAP_QAS_HDB10 -inf: prihana
colocation col_QAS_never_with_AWS_IP -inf: rsc_SAP_QAS_HDB10:Started
res_AWS_IP
order ord_QASstop_before_HDB-promote inf: rsc_SAP_QAS_HDB10:stop
msl_SAPHana_HDB_HDB00:promote19. 변경 내용을 반영합니다.
sudo su -
crm configure load update crm-cs-qas.txt20. HA Cluster Maintenance Mode를 운영 모드로 복구합니다.
PRD Database의 HSR변경, QAS 추가설치, HA Cluster 설정 변경이 완료 되었으므로 HA Cluster를 운영 모드로 변경합니다.
sudo su -
crm configure property maintenance-mode=falseHA Cluster HA 테스트
구성된 HA Cluster의 정상 작동을 테스트합니다.
21. HANA Database의 장애 상황 (Node1에서 HDB stop 또는 Kill)
Node1에서 HANA Database가 재시작 확인합니다.
22. Node1의 장애 상황 shutdown
Node2에서 QAS가 중단되고 PRD Primary 실행 확인합니다.
23. Note. TakeBack (Node2에서 Node1으로 Primary Dbatbase 원복) 수행시 Node2 (sechana)의 PRD global.ini 재수정(HSR TAKEBACK단계 참조) 후 PRD Secondary Database를 시작할 수 있도록 주의가 필요합니다.
상세한 커맨드 레벨의 예시는 SAP HANA on AWS Advanced WorkShop를 참조하시기 바랍니다.
지금까지 AWS에서 SAP HANA Database의 고가용성 구성인 HSR을 비용 효율적으로 구축하고 운영할 수 있는 방법을 살펴 보았습니다. 더 자세한 기술적인 내용은 아래 문서들을 참조하시면 도움이 될 것입니다.
- SAP Note 2196941-SAP HANA Software Replication Takeover Hook Changes (SUserID필요)
- Suse SAP HANA SR Cost Optimized Scenario
- SAP_HANA_Administration_Guide_en.pdf
- SAP SCN document : DOC-47702 – How to Perform System Replication for SAP HANA
– 이진욱, AWS Specialist Solutions Architect, SAP


Leave a Reply