AWS Data Wrangler를 이용한 AWS Lake Formation 관리 테이블 구성하기
데이터 레이크를 통한 데이터 누적, 분석 및 활용이 기업의 경쟁력을 높이기 위한 필수 요건이 되었습니다. 많은 기업들이 현재 필요한 데이터뿐만 아니라, 미래를 대비한 다양한 종류의 데이터를 저장하고 있습니다. 데이터의 누적만큼, 데이터 보관 및 활용 관련 지켜야 할 다양한 규정 준수 요건들이 생겨나고, 데이터의 정합성과 관리 감독에 대한 필요성이 아래와 같이 발생하고 있습니다.
- 개인정보 보호법, GDPR(General Data Protection Regulation), CCPA(California Consumer Privacy Act)등 다양한 법규 관련 사항으로 인하여, 불필요한 데이터를 삭제할 필요가 있습니다.
- 데이터의 ACID(Atomicity, Consistency, Isolation, Durability)를 보장하는 데이터 레이크 관리 및 운영방안이 필요합니다.
- 관리 감독을 위한 코드를 기초로 한 데이터 레이크 생성 및 운영방안이 필요합니다.
AWS에서는 지난 AWS re:Invent 2021을 통하여 ACID를 지원하는 AWS Lake Formation에서 관리 테이블을 소개하였습니다. 또한, AWS ProServe팀에서 오픈소스 기반의 AWS Data Wrangler API를 개발하였고, 이를 통하여 관리 테이블을 포함한 데이터 레이크의 개발 및 운영이 API 코드 레벨로 가능해졌습니다. 이 글에서는 이 두 가지 기능을 통하여 향상된 데이터 레이크 개발 방법에 관해 소개하겠습니다.
AWS Data Wrangler란?
AWS Data Wrangler는 AWS Professional Services 팀에서 개발한 오픈소스 Python 라이브러리입니다.
- 해당 라이브러리는 Pandas 라이브러리를 기반으로 하여 AWS의 데이터 레이크 관련 서비스들을 연결할 수 있는 기능을 제공합니다. 대표적으로 Amazon Athena, AWS Glue, Amazon Redshift, Amazon Timestream, Amazon QuickSight, Amazon Chime, Amazon CloudWatch Logs, Amazon DynamoDB, Amazon EMR, AWS Secrets Manager, Amazon Simple Storage Service(Amazon S3)등과 쉽게 연결하여 사용할 수 있습니다.
- Amazon S3의 Parquet, CSV, JSON 그리고 EXCEL 포맷 등 다양한 데이터 타입의 처리를 지원합니다.
- Pandas나 Apache Arrow, Boto3의 기본적인 기능뿐만 아니라, 실제 AWS의 다양한 데이터 레이크 구성 서비스에 쉽게 데이터를 load/unload 할 수 있는 강력한 기능을 제공합니다.
AWS Lake Formation 관리 테이블이란?
관리 테이블은 Amazon S3의 새로운 타입의 테이블로써, ACID 및 강력한 보안 기능을 제공합니다.
- 데이터가 추가되거나 변경될 시, Lake Formation은 자동으로 데이터의 정합성을 보장하여 모든 유저가 동일한 데이터를 볼 수 있도록 지원합니다.
- 관리 테이블은 자동으로 데이터 저장을 최적화하여 데이터 조회 시간이 일관되고, 빠르게 처리할 수 있도록 지원합니다.
- 테이블과 column 단위뿐만 아니라, row 단위까지 유저의 접근 제어를 지원합니다.
- row 단위 접근 제어는 Amazon Athena, Amazon Redshift Spectrum, AWS Glue, Amazon QuickSight를 통하여 지원합니다.
AWS Lake Formation 관리 테이블의 ACID 작동 원리
- 관리 테이블은 각 Transaction의 ACID를 지원하기 위하여, 각 Transaction 별로 Transaction ID를 생성하고, 거래 완료 후 Commit을 통하여, 변경 내용을 반영합니다.
- Transaction Commit 후 각 Transaction 별로 별도의 파일이 Amazon S3에 생성됩니다. Transaction ID를 통하여 과거 데이터도 불러올 수 있습니다.
- Commit 이후에 데이터 변경이 반영되고, 다양한 데이터 호출에 동일한 응답을 전송할 수 있습니다. 아래 예제를 통하여 Commit 이후로 데이터가 변경됨을 확인할 수 있습니다.
# 기존 데이터셋에 남성 데이터를 추가하고자 함
df_male = df_raw[df_raw.gender.isin(['Female'])==False]
# 남성 데이터를 추가하는 트랜잭션을 선언함
transaction_2 = wr.lakeformation.start_transaction(read_only=False)
# governed_demo_table에 정의된 s3 경로에 해당 데이터를 append 함
wr.s3.to_parquet(
df=df_male,
path='s3://Datalake location 경로',
dataset=True,
compression='snappy',
database='governed_demo',
table='governed_demo_table',
parameters={"num_cols":str(len(df_male.columns)),"num_rows":str(len(df_male.index))},
mode='append',
table_type='GOVERNED',
transaction_id=transaction_2)
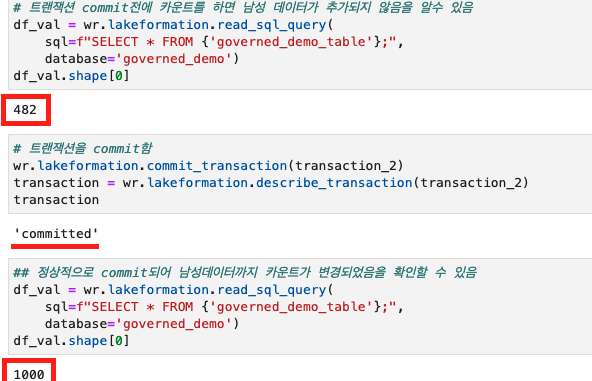
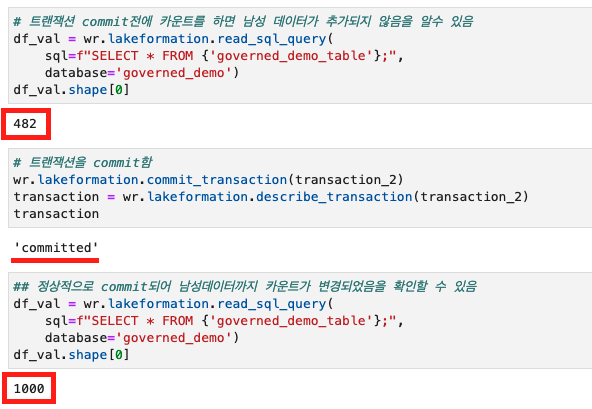
# 트랜잭션 commit 전에 카운트를 하면 남성 데이터가 추가되지 않음을 알수 있음
df_val = wr.lakeformation.read_sql_query(
sql=f"SELECT * FROM {'governed_demo_table'};",
database='governed_demo')
df_val.shape[0]
# 트랜잭션을 commit함
wr.lakeformation.commit_transaction(transaction_2)
transaction = wr.lakeformation.describe_transaction(transaction_2)
transaction
# 정상적으로 commit되어 남성 데이터까지 카운트가 변경되었음을 확인할 수 있음
df_val = wr.lakeformation.read_sql_query(
sql=f"SELECT * FROM {'governed_demo_table'};",
database='governed_demo')
df_val.shape[0]
Data Wrangler를 통한 관리 테이블 운영 방안을 쉽게 이해하고자 금융권 고객 정보 처리 가상 예제를 가지고 설명하겠습니다.
Data Wrangler를 통한 관리 테이블 이용 사례 – 금융권 고객 정보 처리 예제
지금까지 설명한 Data Wrangler와 관리 테이블을 이용하여 금융권 고객 정보 처리 사례를 구현해보겠습니다. 아래의 예제는 관리 테이블이 아닌 일반 테이블로도 진행이 가능합니다. 다만 금융권의 경우 거래의 일관성이 매우 중요하기에, ACID를 지원하는 관리 테이블로 생성을 진행합니다. 또한, 관리 테이블은 row/cell 단위 보안도 가능하여, 금융권 보안에 최적화되어 있습니다. 이번 글에서는 간단한 주요 코드만 소개할 예정이고, 모든 코드는 AWS Data Wrangler를 사용한 관리 테이블 작업 노트북을 통하여 공유합니다.
사전 작업 : 실행 환경 설정 및 유저 권한 등록
데이터 레이크 구성을 위하여, 먼저 AWS Lake Formation 콘솔에 접속하여, 데이터가 저장된 S3 위치를 데이터 레이크 장소로 등록합니다. 이후, 데이터 레이크에 접속 및 작업을 진행할 수 있도록 권한 부여를 합니다. (현재 관리 테이블 사용이 가능한 리전은 AWS 사이트에서 확인이 가능하며, 이번 글에서는 미국 서부(오레곤) 리전을 이용하였습니다.) Amazon SageMaker Notebook을 통하여, 실행 설정하는 방법을 설명하겠습니다.
- SageMaker Notebook 생성 후, SageMaker Notebook Role을 확인합니다.

- AWS IAM에서 SageMaker Notebook Role에 아래의 Policy를 추가합니다.

- 데이터 레이크 DB를 생성합니다 – 메뉴 : AWS Lake Formation > Data catalog > Databases

- 데이터 레이크로 사용할 S3 버킷을 생성합니다. S3 버킷 생성 후 테스트 파일을 업로드합니다. 테스트 파일은 관리 테이블 GitHub에서 다운로드 가능합니다.

- 생성한 S3 Bucket을 데이터 레이크 S3 위치로 등록합니다- 메뉴 : AWS Lake Formation > Register and ingest > Data lake locations

- SageMaker Notebook Role에 데이터레이크 location으로 등록한 S3 접근 권한을 등록합니다 – 메뉴 : AWS Lake Formation > Permissions > Data locations

- 권한 설정 완료 후, Jupyter Notebook에서 awswrangler 라이브러리를 설치한 후 AWS Data Wrangler를 사용한 관리 테이블 작업 노트북 전체를 수행하실 수 있습니다.
Data Wrangler를 활용한 데이터 처리 코드 실행(금융권 고객 정보 처리 예제)
- 데이터 레이크에 테이블을 생성하기 위하여, 먼저 고객 정보를 저장하는 관리 테이블을 Glue Data Catalog에 생성합니다.
# Governed Table을 Glue Console이 아닌 Wrangle create_parquet_table library로 table metadata 생성. # Governed Table의 경우 table_type에 'GOVERNED'로 명시 필요. wr.catalog.create_parquet_table( database='governed_demo', table='governed_demo_table', path='s3://Datalake location 경로', columns_types={'registration_dttm':'Timestamp', 'id':'int', 'first_name':'String', 'last_name':'String', 'email':'String', 'gender':'String', 'ip_address':'String', 'cc':'String', 'country':'String', 'birthdate':'String', 'salary':'double', 'title':'string', 'comment':'string'}, compression='snappy', description='governed_table example', table_type='GOVERNED' ) - Glue Data Catalog 생성 후 등록된 S3 경로에 파일을 저장합니다.
# Governed Table Metadata생성 후 lake location에 지정된 S3에 데이터를 저장함. wr.s3.to_parquet( df=df_female, path='s3://Datalake location 경로', dataset=True, compression='snappy', database='governed_demo', table='governed_demo_table', parameters={"num_cols":str(len(df_female.columns)),"num_rows":str(len(df_female.index))}, mode='overwrite', table_type='GOVERNED', transaction_id=transaction_1) - 개인정보보호를 위하여 불필요하게 수집된 고객 정보는 삭제가 필요하고, 고객 정보를 통하여 마케팅 데이터 생성 역시 필요합니다. 데이터 레이크에서 Data Wrangler와 관리 테이블을 통해서 컬럼 삭제 및 생성을 진행합니다.
- ip_address가 불필요하게 수집된 개인정보라고 할 때, Data Wrangler API를 통하여 Glue Data Catalog에서 ip_address 컬럼 삭제를 진행합니다.
# Metadata상 컬럼 삭제는 wrangler delete_column libary로 진행 wr.catalog.delete_column( database='governed_demo', table='governed_demo_table', column_name='ip_address', transaction_id = transaction_3 ) - 이미 수집된 급여 정보를 통하여, 마케팅을 위한 고객 세그먼트를 추가하고자 합니다. Data Wrangler API를 통하여 세그먼트 컬럼을 추가합니다.
# Metadata상 컬럼 추가는 wrangler add_column libary로 진행 wr.catalog.add_column( database='governed_demo', table='governed_demo_table', column_name='segment', column_comment='segment', column_type='string', transaction_id=transaction_4 ) - Glue Data Catalog에 컬럼 정보가 추가된 후, 데이터 레이크 위치로 지정된 S3에 실제 데이터를 overwrite 합니다.
# 컬럼 삭제 및 추가가 metadata상 완료 된 후, datalake location으로 지정된 S3에 데이터 반영함. wr.s3.to_parquet( df=df_add, path='s3://Datalake location 경로', dataset=True, compression='snappy', database='governed_demo', table='governed_demo_table', parameters={"num_cols":str(len(df_add.columns)),"num_rows":str(len(df_add.index))}, mode='overwrite', table_type='GOVERNED', transaction_id=transaction_5)
- ip_address가 불필요하게 수집된 개인정보라고 할 때, Data Wrangler API를 통하여 Glue Data Catalog에서 ip_address 컬럼 삭제를 진행합니다.
- 거래 종료 5년이 경과한 고객 데이터를 삭제합니다.
- 실제 삭제할 고객들을 제외한 정보를 필터링하여, S3에 overwrite 합니다.
- Transaction Table에서는 overwrite 시에 자신의 Transaction ID에 해당하는 파일만 삭제 후 데이터를 입력합니다. 이런 이유로, 과거 Transaction ID로 생성된 파일에는 여전히 거래 종료 5년 지난 데이터가 존재하게 됩니다.
- 과거 Transaction ID로 생성된 파일까지 정리가 필요하면 delete_objects를 통하여 S3 버킷에 생성된 파일을 삭제합니다.
- 관리 테이블의 row level upsert 기능은 추후 기능 개선으로 추가될 예정입니다.
#active 고객만 선택함. df_del = df_del[df_del.id.isin(inactive_customer.id)==False] #과거 transaction file에도 inactive고객이 있기에, 필요에 따라 삭제를 진행함. wr.s3.delete_objects('s3://Datalake location 경로') #선택된 active고객으로 전체 파일을 overwrite진행함. wr.s3.to_parquet( df=df_del, path='s3://Datalake location 경로', dataset=True, compression='snappy', database='governed_demo', table='governed_demo_table', parameters={"num_cols":str(len(df_del.columns)),"num_rows":str(len(df_del.index))}, mode='overwrite', table_type='GOVERNED', transaction_id=transaction_6)
- 위 과정을 마치면, 기존 고객 데이터가 아래와 같이 변경됩니다.
- 불필요한 고객 정보 ip_address가 삭제되었습니다.
- 마케팅 정보 segment가 추가되었습니다.
- 5년이 지난 고객 ID 2/3 번 record가 삭제되었습니다.

<변경 전 데이터>

<변경 후 데이터>
마무리
데이터 레이크의 활용이 가속화되면서, 이와 함께 데이터 관리에 대한 규정 준수가 중요해졌습니다. 또한 다양한 서비스들이 이용되는 데이터 레이크의 특성상 통합 관리 감독에 대한 필요성도 지속해서 떠오르고 있습니다. 이를 해결하기 위한, Data Wrangler를 이용한 관리 테이블 구성에 대한 방법을 알아보았습니다. Data Wrangler에 대한 자세한 내용은 Data Wrangler 공식 사이트를 통해 더 많은 정보를 접하실 수 있습니다. 또한, AWS Online Tech Talk 동영상에서 관리 테이블에 대한 전반적인 사항은 확인하실 수 있으며, row/cell 단위의 접근통제는 AWS Lake Formation을 활용한 행 단위, 열 단위 접근 통제 구현에 대한 블로그를 참고해주세요.
– 정회종, AWS 솔루션즈 아키텍트
Source: AWS Data Wrangler를 이용한 AWS Lake Formation 관리 테이블 구성하기


Leave a Reply