AWS Glue 기반 Amazon Aurora 데이터 추출 및 Quicksight 시각화 하기
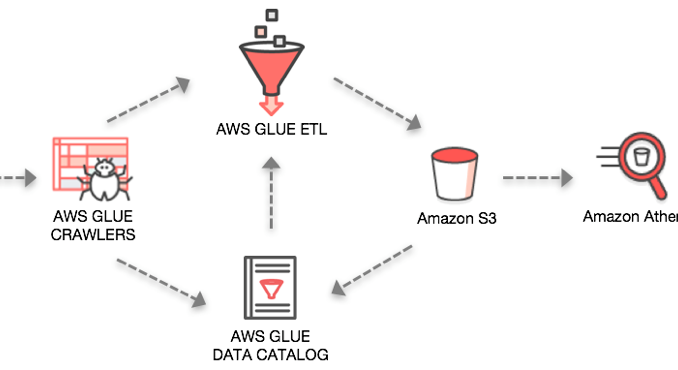
AWS Glue는 서버리스 ETL 서비스로 데이터 분석을 위해 손쉽게 데이터를 준비하고 로딩할 수 있도록 지원하는 서비스 입니다. AWS Glue는 AWS에 저장된 데이터의 메타 데이터를 통해 데이터 카탈로그를 생성하고, 해당 카탈로그로 다양한 서비스에서 데이터에 접근하여 사용할 수 있습니다.
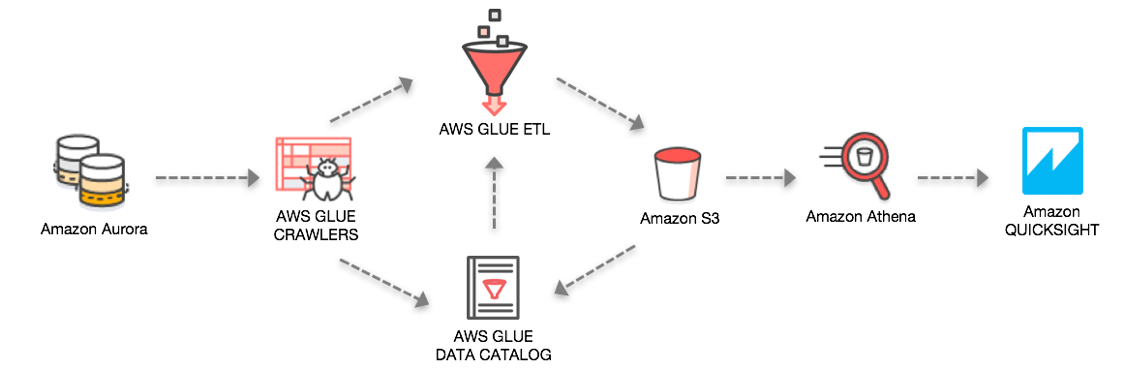
이 글에서는 실제 많은 고객들이 서비스 운영 데이터베이스로 사용하고 있는 Amazon Aurora의 DB 데이터를 AWS Glue를 통해 데이터 카탈로그를 생성하고, 생성된 카탈로그를 통해 데이터를 Amazon S3로 추출 / 로드 시킨 후에 해당 데이터를 통해 다양한 비즈니스 분석을 수행하는 예제를 소개합니다.
참고로 소스 데이터가 S3에 이미 저장되어 있는 경우, Amazon S3 및 AWS Glue를 이용한 데이터 레이크 구축하기을 참고하면 간단히 AWS Glue를 통해 데이터를 확인해 볼 수 있습니다.
실습을 위한 환경에서는 원본이 되는 데이터는 Amazon Aurora(postgreSQL) DB에 저장되어 있으며, 다음과 같은 단계로 해당 데이터를 추출/로드/분석에 활용해 보겠습니다.
- AWS Glue Crawler를 통해 Aurora DB에 들어 있는 데이터 카탈로그 생성
- 몇가지 설정이 필요한 부분 추가(Security Group에self-referencing 추가, S3 VPC 엔드포인트 생성)
- AWS Glue Job을 생성하여 Aurora에 테이블 데이터를 S3에 저장하는 ETL 작업 (parquet 파일로 동시에 변환)
- AWS Glue Crawler 통해 ETL이 수행된 S3 데이터에 대한 데이터 카탈로그 생성
- Amazon Athena 를 통한 데이터 조회
- Amazon QuickSight를 활용한 대시보드 작성

참고로 AWS Glue의 기능은 블로그 작성 시점(2018년 2월) 에 사용 가능한 기능을 위주로 사용하였으므로, 기능이 추가되는 경우 보다 단순한 흐름으로 진행이 가능할 수 있습니다. 또한, 사전에 원본 데이터로 사용할 Amazon Aurora DB가 계정에 생성이 되어 있어야 합니다.
1. Glue Crawler 카달로그 생성
먼저 Aurora Aurora에 저장되어 있는 샘플 데이터의 구조는 다음과 같습니다.

AWS Glue 에서 Crawler를 생성할때 데이터베이스이름, 스키마 이름, 테이블 명 관련 내용을 include path 항목에 넣어서 필터링 할 수 있으므로 미리 확인이 필요합니다. (예제에서는 데이터베이스명은 postgresDB, 스키마 이름은 postgres_dba, 테이블 명은 order 입니다.)
Aurora를 위한 Glue Crawler 생성
먼저 Aurora에 저장된 스키마 정보를 추출해주는 Glue Crawler를 만들어 보겠습니다.
AWS Management Console에서 AWS Glue 서비스 화면으로 이동하여 좌측 네비게이션에서 Crawlers 메뉴를 선택하면 Add crawler 버튼을 통해 신규로 Crawler를 생성할 수 있습니다.
이때 테스트 환경이므로 저는 우측 상단의 리전을 N.Virginia (US-EAST) 선택하여 진행하였습니다. 여러 서비스간 데이터의 이동과 저장이 이루어 지므로 기존에 만들어 놓은 Aurora DB의 리전도 체크하시기 바랍니다.

Crawler 명을 입력하고 나면 Data Store에서 JDBC를 선택합니다. Connection에서 Add Connection을 선택하여 새로운 Connection을 생성합니다.

새로 생성한 Connection을 선택하고 Include path에 대상이 되는 테이블의 경로를 적어줍니다.

추가로 필요한 Store, IAM Role(default), Schedule(Run on demand)를 선택하고 결과를 출력할 곳을 지정합니다.

다음과 같이 작업을 완료하면 Aurora_dataset Crawler가 생성되었고 바로 실행할지 물어봅니다.
2. Crawler를 위한 설정
Crawler실행에 앞서 보안 등에 관련되어 몇가지 설정이 필요합니다.
- AWS Glue 가 RDS와 통신을 하기 위해서는 모든 TCP 포트에 대해서 해당 Security Group에 Inbound self-referencing을 설정해야 합니다. 먼저 Aurora DB의 Security Group에 다음과 같이 자신을 참조하는 Inbound / Outbound 룰을 추가합니다. (기술 문서 참고)
- 실행중인 Aurora Instance의 상세 정보를 보면 Security Group을 확인할 수 있습니다. 다음과 같이 Inbound / Outbound Rules에 추가합니다.

- 다음과 같이 Source에 자신의 security group name을 적어주면 됩니다.

- 동일하게 Outbound 룰도 추가합니다.
- 다음으로는 S3의 데이터 접근을 위해 VPC 엔드포인트를 생성해 주어야 합니다. VPC 엔드포인트를 이용하면 Glue를 통해 S3에 저장하는 데이터가 내부 네트웤 망을 사용하여 안전하게 접근 할 수 있도록 해줍니다. 다음 그림이 VPC 엔드포인트를 통해 Glue가 S3에 접근하는 구성입니다.

- AWS Management Console에 가서 네비게이션 메뉴에서 Endpoint를 선택합니다. (https://docs.aws.amazon.com/ko_kr/glue/latest/dg/vpc-endpoints-s3.html?shortFooter=true)
- 아래쪽 Service Name에서 ‘com.amazonaws.us-east-1.s3’를 선택하고 Aurora가 실행중인 VPC를 선택합니다.

이로써 AWS Glue를 통해 Aurora의 데이터베이스의 스키마 정보를 읽어 올 준비가 끝이 났습니다. 앞에서 생성한 Crawler를 실행하면 잠시 후 다음과 같이 샘플 DB에 들어 있던 11개의 테이블 정보가 확인 가능합니다.

목록에서 하나의 항목을 선택해 보시면 다음처럼 Glue Data Catalog에서 수집되는 정보를 확인할 수 있습니다.

한가지 확인해야 할 사항은 지금까지는 AWS Glue Crawler를 통해 데이터 카탈로그를 생성하였고, 실제로 데이터를 쿼리해서 사용하려면 추가 작업이 필요합니다. S3에 있는 데이터를 크롤링 해서 카탈로그를 만드는 경우에는 아래의 View data 메뉴가 즉시 enable이 되어 바로 Athena의 콘솔에서 데이터를 확인 할 수 있습니다. 하지만, Aurora 데이터베이스에 카탈로그를 생성한 경우 아직까지 원본 데이터는 DB에만 저장되어 있으므로 직접 Amazon Athena를 통해 쿼리할 수 없습니다.

Amazon Athena는 S3에 저장되어 있는 데이터를 별도의 이동이나 전처리 없이 표준 SQL을 통해 조회할 수 있는 인터렉티브 쿼리 서비스 입니다. 즉, Aurora의 데이터를 Glue의 Job을 통해 S3로 추출, 로딩 하는 추가적인 작업이 먼저 필요합니다.
3. Glue ETL 작업
다음 단계는 생성된 카탈로그를 통해 Aurora에서 S3에 데이터를 추출하여 로딩하는 Job을 생성해 보겠습니다. 콘솔 좌측 Jobs 메뉴를 선택하고 Add job을 선택합니다. Job의 이름을 입력하고 나머지는 디폴트 값으로 진행합니다.

이미 Glue Data Catalog에 등록되어 있는 모든 테이블 리스트가 보입니다. 여기에서 데이터 추출을 원하는 테이블을 선택해줍니다. 여러 테이블에 대한 작업을 추가하고 싶은 경우 이후 단계에서 추가할 수 있습니다.

Aurora에서 추출한 데이터를 S3에 저장하기 위해서 다음처럼 선택합니다.

다음 단계에서는 Source와 Target 스키마 간의 컬럼 단위의 변경을 UI에서 손쉽게 변경할 수 있는 단계입니다.

불필요한 컬럼은 삭제하고 분석에 필요한 항목만 남기고 다음 단계로 넘어갑니다. 수정이 종료되면 다음처럼 전체 Job의 실행 타스크와 pyspark 코드가 보여집니다. 해당 화면에서 사용자들은 손쉽게 코드를 수정, 추가, 실행 시킬 수 있습니다. 수 분이 지나 작업이 완료되면, 원하는 데이터를 지정한 S3 폴더에서 확인 할 수 있습니다.

4. S3 데이터를 위한 Crawler 생성
이제 데이터를 활용하기 위한 마지막 단계가 남아 있습니다. S3에 저장된 데이터는 Glue의 Data Catalog와 Job을 통해 변환 작업을 수행하여, 실제 Aurora에 저장된 데이터와는 다른 데이터 이므로 추가 Crawler를 생성하여 활용할 수 있도록 해야 합니다.
앞에서 진행한 것처럼 새로운 Crawler를 추가합니다 .

ETL이 완료된 테이블임을 인지하기 위해 별도의 데이터베이스를 타겟으로 설정하거나, prefix를 잘 명명하여 식별하도록 합니다.

해당 Crawler가 실행이 완료되면 다음처럼 Tables 에서 해당 테이블을 확인할 수 있습니다. 이제는 데이터가 S3에 로딩이 완료된 상태이므로 View data 메뉴를 선택하면 바로 Athena를 통해 쿼리를 수행할 수 있습니다.

다음과 같이 바로 Athena 콘솔에서 원하는 쿼리를 실행할 수 있습니다.

5. QuickSight로 BI 대시보드 작성
마지막으로 비지니스 분석 서비스인 Amazon QuickSight를 통해 해당 데이터를 탐색하고, Visualization 해보도록 하겠습니다. 콘솔을 통해 QuickSight로 이동하여 좌상단의 New Dataset을 선택하면 다양한 데이터 소스를 선택할 수 있는 화면을 볼 수 있습니다.

QuickSight에서는 데이터의 형태와 변환 작업을 어디에서 수행하는 가에 따라 다양한 선택이 가능합니다.
우리의 원본 데이터는 Aurora DB에 있고, Glue를 통해 S3에 추출한 데이터를 저장하였고, Athena를 통해 추가적으로 다양한 데이터 필터링, 어그리게이션 등을 수행 할 예정이이므로, BI를 위한 최종 데이터 소스는 Athena 를 선택하도록 합니다.

BI 소스로 사용할 테이블을 선택해 줍니다.

혹시 QuickSight 에서 해당 데이터 소스와의 연결에서 접속 에러가 발생하면 아래와 같이 S3 버킷의 접근 권한을 체크해 보기 바랍니다.

접근 권한에서는 S3의 해당 폴더 또는 전체 폴더를 접근 할 수 있도록 설정해 주어야 합니다.

Source Data 선택이 완료되면 다음과 같은 QuickSight 대시보드가 나타납니다. 원하는 유형의 그래프를 아래에서 선택하고 해당 그래프에 표현하고자 하는 항목을 좌측 리스트에서 선택만 해주면 비지니스에 유의미한 다양한 대시보드를 구성할 수 있습니다.

마무리
이 글에서는 AWS Glue를 활용하여 Amazon Aurora에 들어 있는 데이터를 S3로 추출, 변환, 로딩 하고, 해당 데이터를 Amazon Athena를 통해 간단히 쿼리해보거나, Amazon QuickSight를 통해 빠르게 대시보드를 만들어 보았습니다. 이 서비스 조합은 매우 빠르게 운영 Database를 S3를 활용한 데이터레이크로 이동시키고 다양한 분석 도구를 활용해 비지니스에 유의미한 인사이트를 찾아낼 수 있도록 해줍니다.
 이 글은 정세웅 AWS 빅데이터 솔루션즈 아키텍트가 작성하였으며, 게임 / 금융 / 커머스 등 다양한 산업 부문에서 대규모의 데이터를 저장, 분석, 활용 하기 위한 데이터 레이크 구축 프로젝트에 참여하고 있습니다.
이 글은 정세웅 AWS 빅데이터 솔루션즈 아키텍트가 작성하였으며, 게임 / 금융 / 커머스 등 다양한 산업 부문에서 대규모의 데이터를 저장, 분석, 활용 하기 위한 데이터 레이크 구축 프로젝트에 참여하고 있습니다.
Source: AWS Glue 기반 Amazon Aurora 데이터 추출 및 Quicksight 시각화 하기


Leave a Reply