
Globo.com’s Live Video Platform for FIFA World Cup ’14- Part I: Delivery and Caching


The following is adapted from a presentation given by Leandro Moreira and Juarez Bochi of Globo.com at nginx.conf 2015, held in San Francisco in September. This blog post is the first of two parts, and is focused on using NGINX for streaming video delivery and caching. You can watch the video of the complete talk onYouTube.
Table of Contents
0:03 Introduction
1:51 Agenda
2:14 Architecture in 2010
4:08 The Good Part – Low Latency
4:19 Issue – Lack of Instrumentation
4:44 Issue – Scalability
5:52 FIFA 2010 – The Numbers
6:18 Mobile Support
7:29 How Does HLS Work?
9:18 First HLS Implementation
10:14 Generation and Distribution
10:55 First Solution Architecture
11:12 HLS Adoption
11:54 HLS vs RTMP Buffering
12:34 Instrumentation
13:22 Dashboard
13:45 Caching Configuration
15:30 OS Fine Tuning
17:50 Benefits from NGINX and HLS
18:43 Our Farm
0:03 Introduction
Leandro: Good morning. I am Leandro, my friend here is Juarez. We work for Globo.com. We were in the team that was responsible to deliver the live broadcast over the internet for the last World Cup; not the rugby one, the soccer one.

Although you will see only two of us in here, we are actually part of a team. So the work we are presenting today is not just from us but from this amazing team we are part of.
Another thing we need to mention up front, is that we were restricted to Brazil only. So, we were not responsible to broadcast live streaming for the entire world.
1:51 Agenda

We want to present our work as a timeline; showing you the past and coming to the time that we entered the team, and then how we started building upon the previous video platform to build what we have today.
So let’s take a look at the past – what we were using during the 2010 World Cup in Africa.
2:14 Architecture in 2010

Juarez: Thank you, Leandro. We are going to talk briefly about our experience in 2010, why it didn’t work, and why we decided to adopt NGINX.
In 2010, we were using Flash Media Server. For streaming live video, it basically works like this:

First, the camera on the field will send the raw video signal to an encoder. Then the encoder, will use a video and audio codec and transform it to RTMP. We used H.264, and we used the RTMP protocol to push this through the FMS server.
To deliver this signal to the audience, we then send this to another server or a farm of servers, where we used the RTMP protocol again to deliver the video directly to the users, via the Flash video player. RTMP uses its own port, 1935, and sometimes we ran into issues with firewalls.
You can see we were using RTMP for everything, and this is a stateful protocol which made it hard to do redundancy and failover, as well as some other drawbacks.
4:08 The Good Part – Low Latency

The good thing about using RTMP was that the video latency is very low. Just two to five seconds.
4:19 Issue – Lack of Instrumentation

One drawback we had, besides the difficulty implementing redundancy and failover, was that Flash media server is proprietary, closed-source software. That means we couldn’t debug it, we couldn’t add instrumentation. All we could do was tail the logs and use the shell to monitor what was going on.
4:44 Issue – Scalability
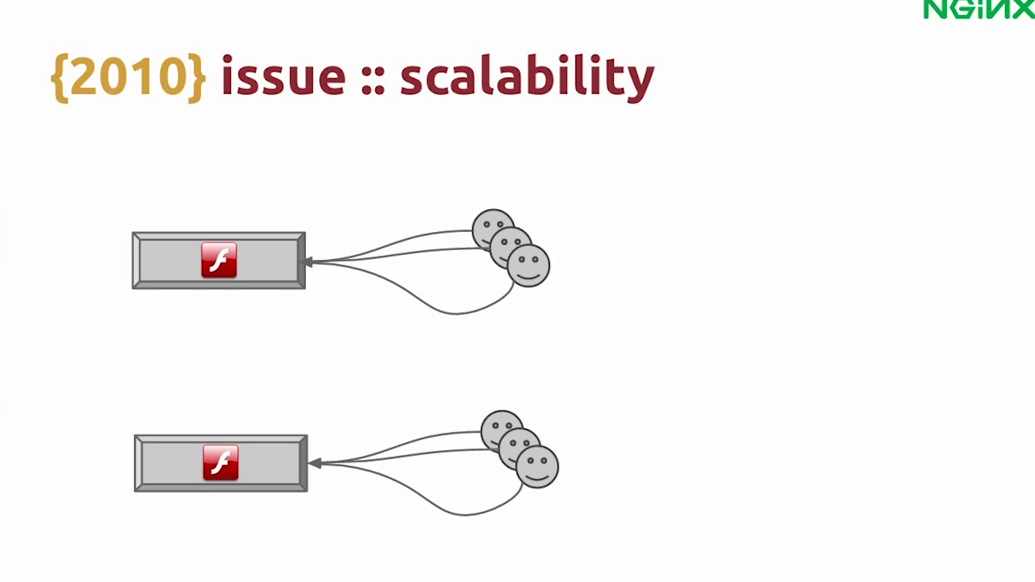
Since RTMP is a stateful protocol, another issue was scalability. If you have several users on one server and it fails, all the users will need to connect again to a different server.

Since it’s already in a high load situation, the second server will probably fail as well, and all of your servers will fail in cascades.

We saw that happen and we could see the audience and the money flying away through the window.
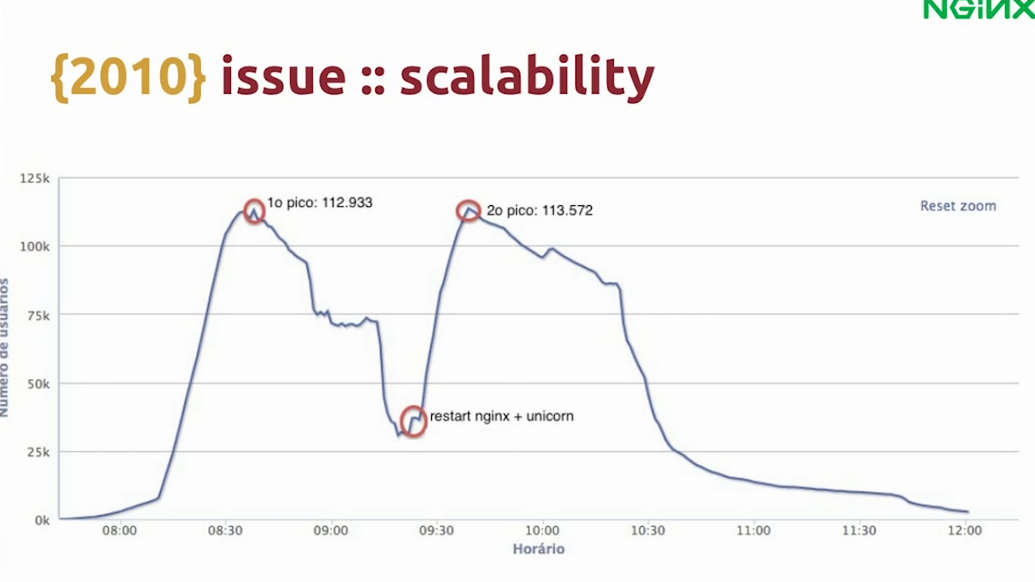
Here, you can see a chart of a match that we were broadcasting. At half-time, we had a traffic peak. The server failed and we lost more than half of our audience.
With live events like that you don’t always have a chance to recover – you just have one chance to do it right.
5:52 FIFA 2010 – The Numbers

Still, we achieved some respectable numbers, at least for Brazil. We had almost 300,000 simultaneous users. The maximum bitrate, that’s not that high, but it’s decent quality.
6:18 Mobile Support

Leandro: That was the past and we jumped on the team in 2012. At this time, the internet was growing and spreading to smartphones and tablets. So suddenly we had the need to deliver live video to mobile devices.
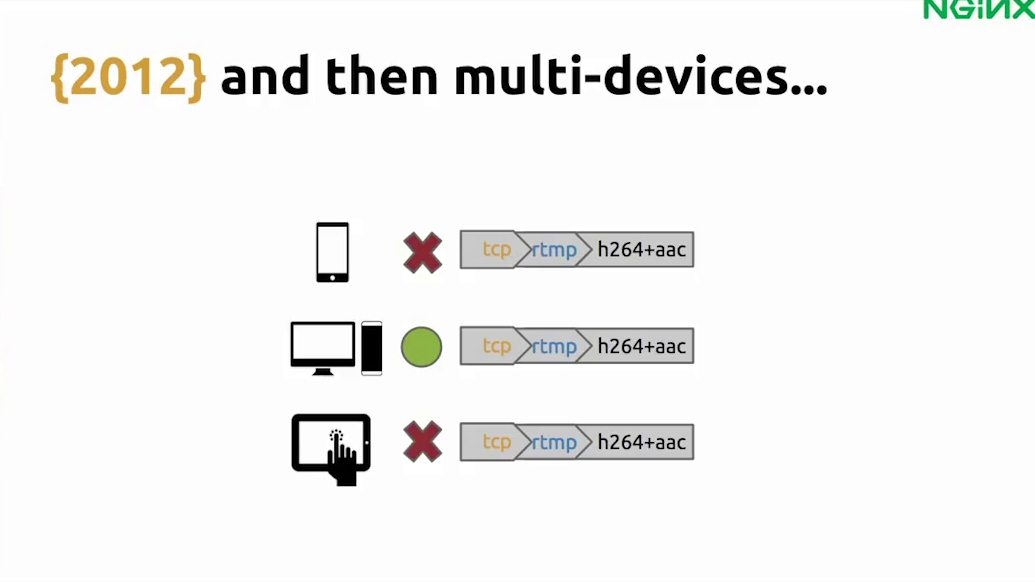
What we noticed was that not all mobile devices can play RTMP, which is a Flash thing. iPhones and iPads, the iOS devices, they really require you to use the HLS protocol to broadcast live content.
7:29 How Does HLS Work?
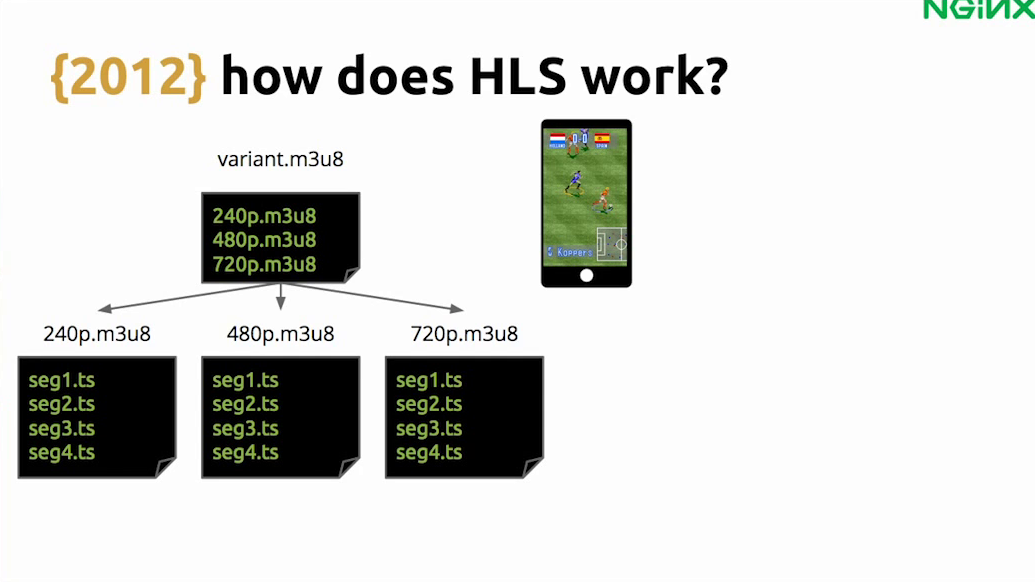
HLS was a protocol proposed by Apple, and it works like this. When a user wants to watch the stream, the first thing the video player does is request a playlist, which is a text file full of links. This first playlist is a list of links to other playlists showing which video qualities and bitrates are available.
Now the protocol will figure out which video quality it can play based on the connection speed. For instance, let’s say you are on a mobile phone with 4G, then your phone decides that you can run 720p, and it gets the 720p playlist which has a list of segments, with video segments. Then it starts to get the videos. It will fill the buffer, and then it will start to play the video.
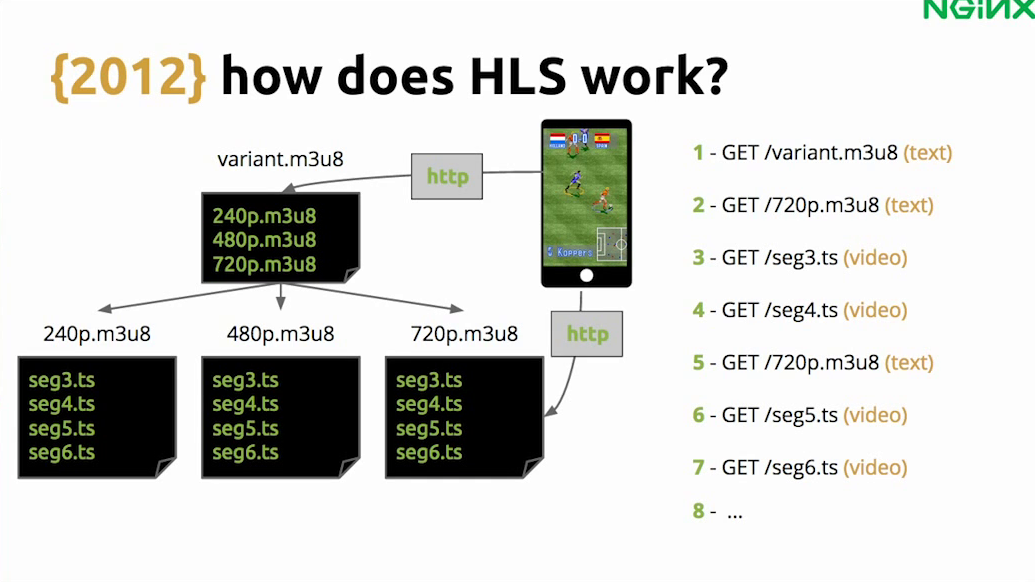
Then it will update the playlist by calling the 720p playlist again, get more segments, and cycle through the process again and again.
So basically, we moved from RTMP to HLS over HTTP, moving from a stateful protocol to a stateless protocol.
9:18 First HLS Implementation
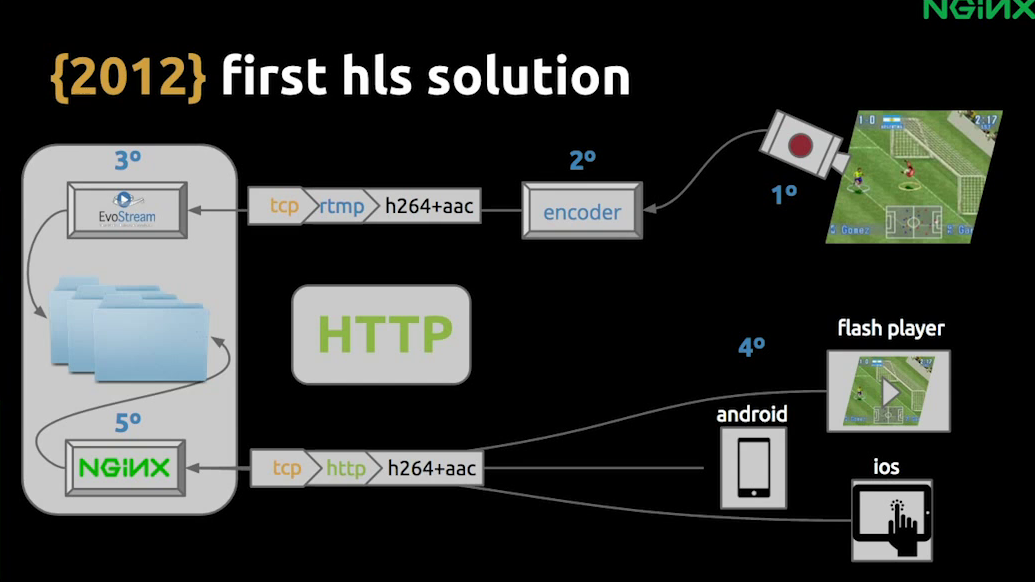
In our first HLS implementation, we still used the same process on the video capture side. We still pushed the stream with RTMP. and we were still using a proprietary server, but it was easier to integrate. With EvoStream, you can push RTMP, and you can get an HLS stream out of it – the chunks, the playlists I showed you before.
EvoSteam saved those to a common folder, and then we introduced NGINX to distribute the load. Now, we could broadcast to the iPhone, the Android, and even to the Flash Player. At the time there wasn’t a HLS Flash Player on the market so we had to do that in-house, which was good fun.
10:14 Generation and Distribution
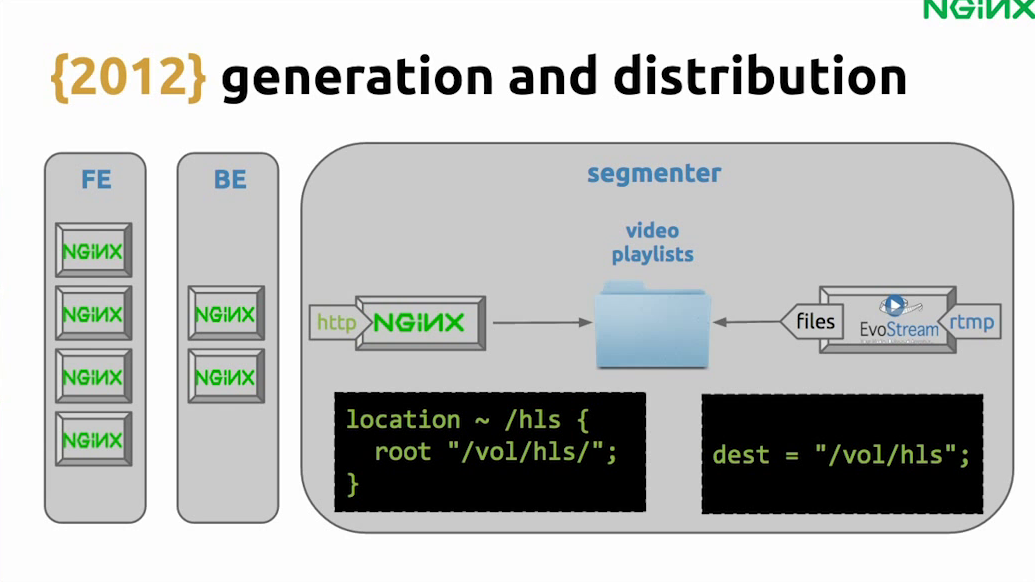
Our first HLS implementation was very basic: just taking the root path and making it available. Let’s dig into this part, which I like to call generation and distribution.
We have the frontend and the backend, and then we have NGINX doing something very simple. We set up the EvoStream to generate the HLS videos in a folder, and then we say that the root for that location will be the same folder we use that EvoStream pushes to.
10:55 First Solution Architecture
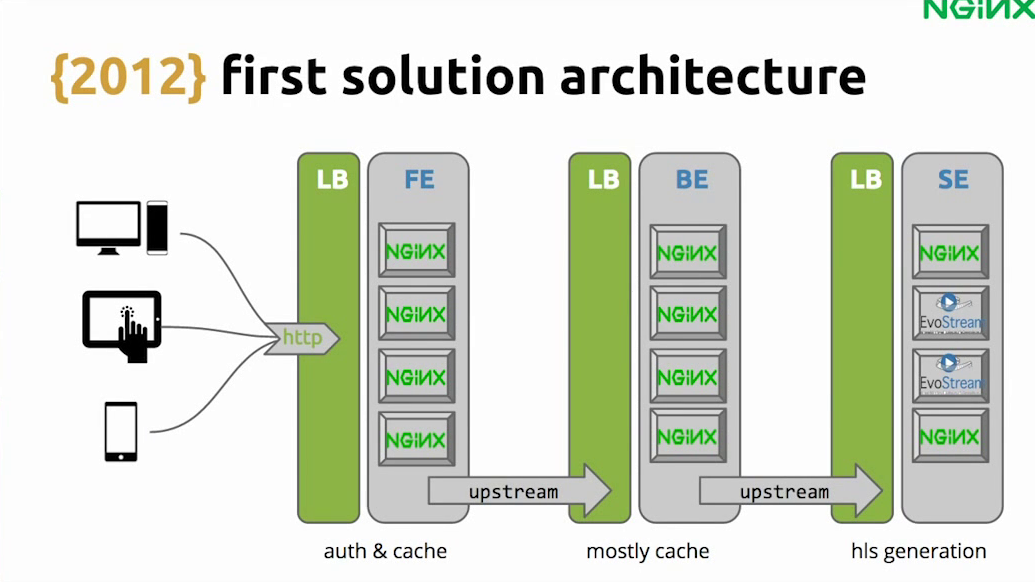
That simple solution worked well. We had all the basic things. There’s a load balancer in front of each layer doing the caching, authentication and generation, and it worked quite well.
11:12 HLS Adoption

At this point we did an experiment where we used HLS as the only protocol. This was only for about two percent of the users. We found that the results were nice, so we could change RTMP to HLS for 100% of our users, changing from a multi-protocol system to just one.
11:54 HLS vs RTMP Buffering
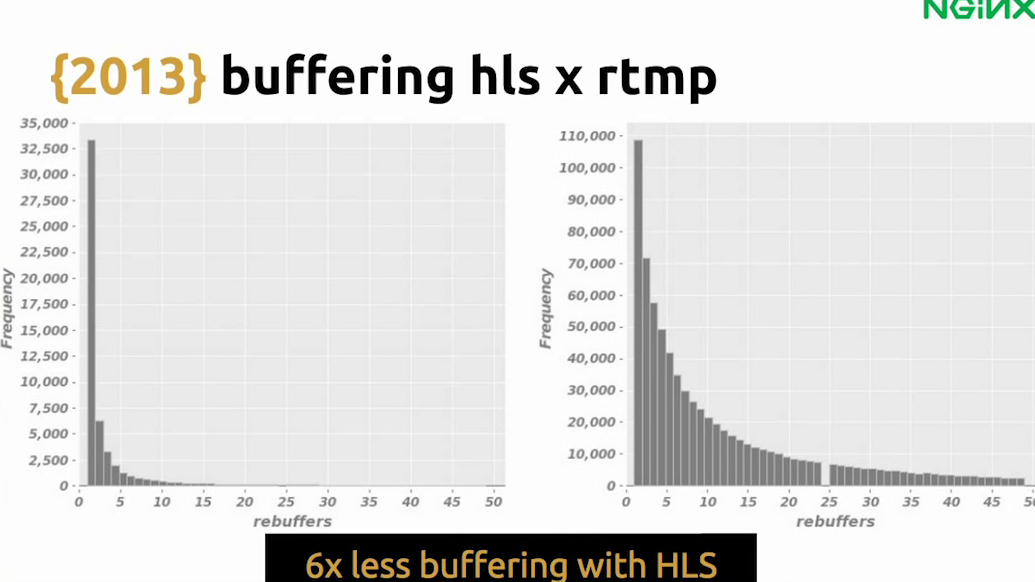
We captured metrics to see if this change would be a better or a worse experience for users and we we saw that buffering was much, much better while using HLS comparing to RTMP. Besides buffering, we had tons of different metrics which showed that the user experience was better while using HLS.
Juarez: Yes, the startup time was lower and the playing time was, on average, much higher so we were sure that HLS was working much better than RTMP.
Leandro: Yes. With that information, we decided to moved to HLS 100%.
12:34 Instrumentation
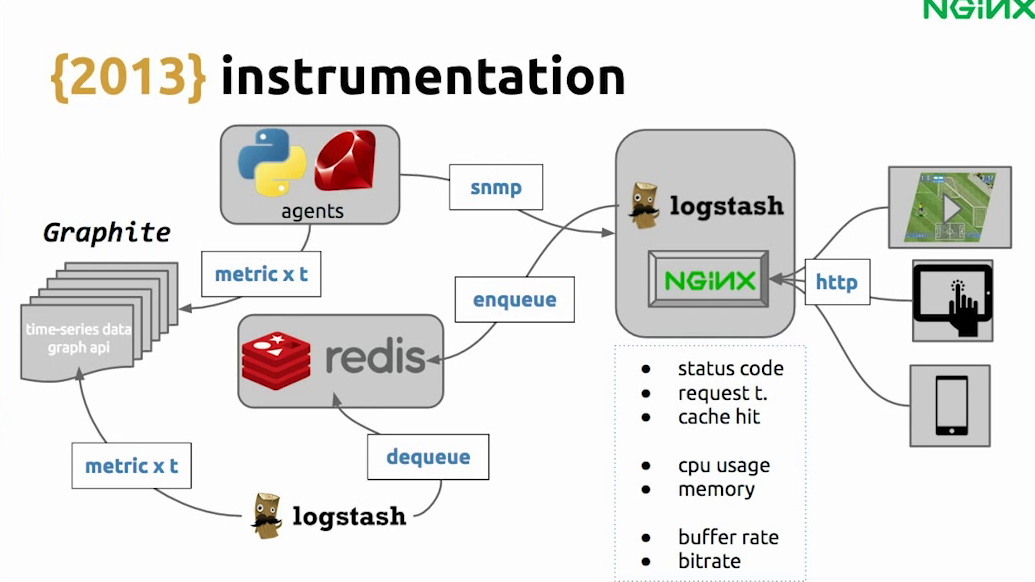
Since we changed to an HTTP-based protocol, a huge benefit was being able to start using instrumentation. We could set up a logstash to get the data log and send it to Redis. And then we have another logstash and send it to Graphite. We have some agents too, which useSNMP to understand how the CPU is working and send the metrics also to Graphite.
With this we could create a dashboard.
13:22 Dashboard
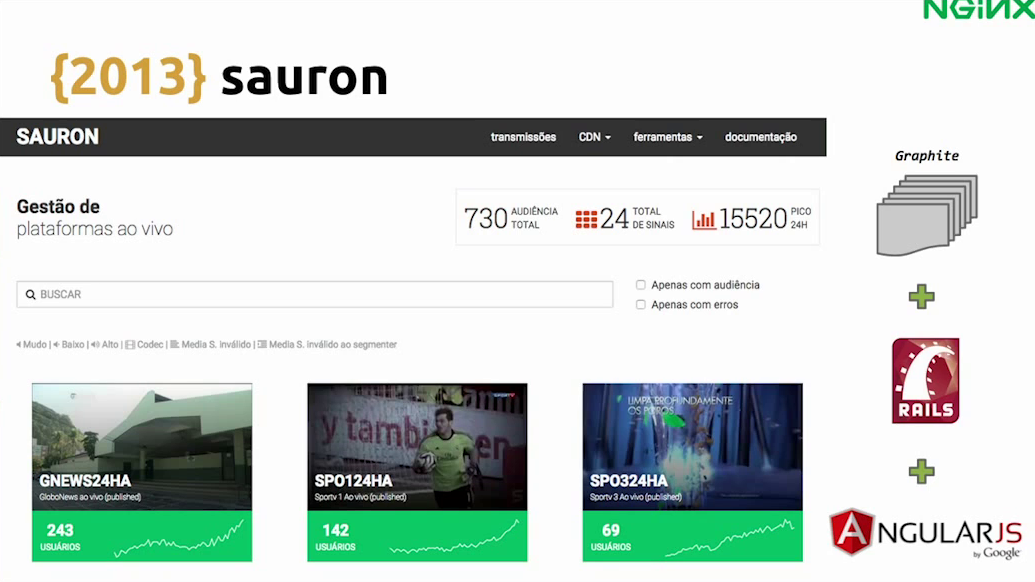
We called it Sauron.
We built Sauron just with Graphite, Rails, and Angular. It wasn’t something too complicated or hard to do, but it was a very useful dashboard because we get a picture of the whole farm. We could see if we are having more cache misses, pretty much standard dashboard stuff, but very nice to have, and we are able to get this by switching to HLS.
13:45 Caching Configuration
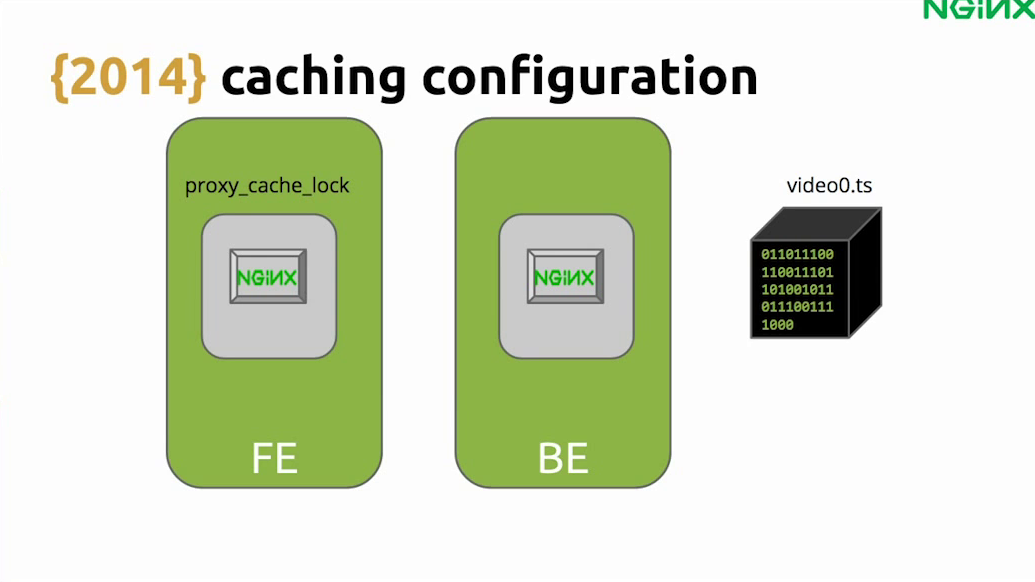
When we switched from RTMP to HLS it was mostly good but we ran into some hiccups as well.
We used NGINX for caching. When you are caching, you often lock your cache so you don’t pass all the requests to the backend – that’s a pretty common thing to do. But we forgot about one silly thing.
Let’s say, for instance, a request comes in for an expired video. This request will pass to the backend. But what happens if more and more requests for that expired video come while NGINX is still updating that cached file?
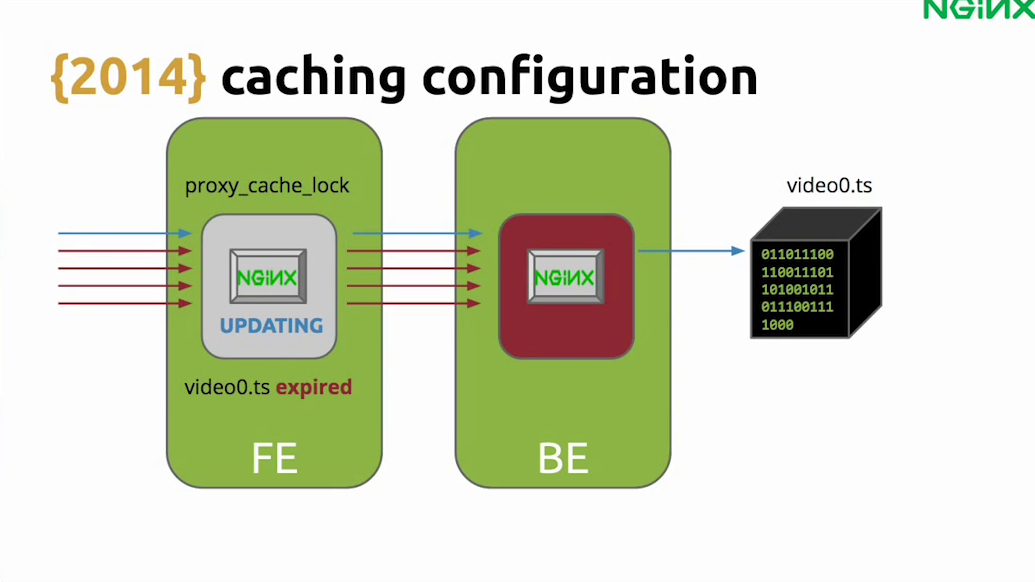
If you don’t configure it properly, all those requests will pass through and your backend would be in a high-load situation. So don’t forget to use proxy_cache_use_stale, especially while updating.
15:30 OS Fine Tuning
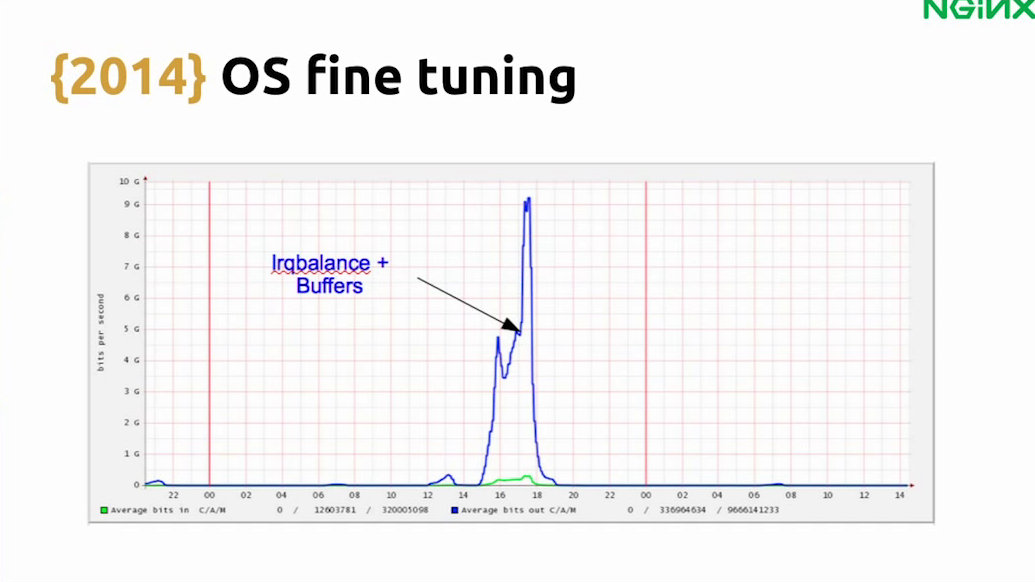
We also did some load testing to see how much we can get from one machine, and we noticed that just throwing NGINX and the stuff on the servers we have, we only were capable of getting network throughput of about 5Gbps, and we have 10G network cards, so this performance was not so good.
We started looking on the internet to understand where the issue was, and we figured out the problem was not with NGINX. Each time a request comes in to your network, it will trigger an interrupt and there needs to be something to handle that. I’m not sure if this is true for all servers but if you don’t specifically configure this properly on our servers, you will have a problem because all the requests will come to the same CPU. So we found this out and used irqbalance, and then, we were able to reach 10 Gbps throughput.
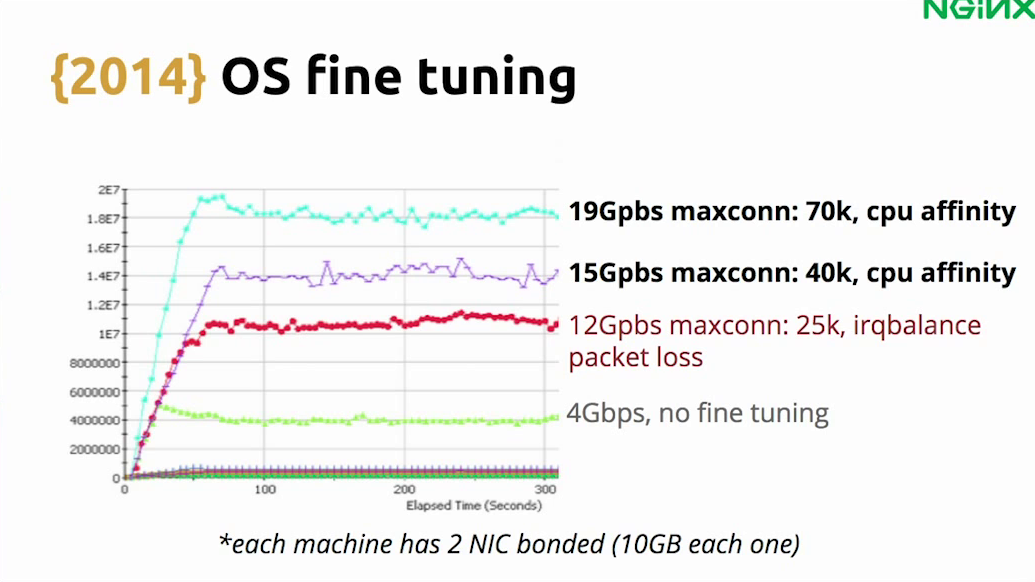
Then we realized we may be able to get more Gigabits, but using irqbalance, we were losing a lot of packets. After some further research, we discovered that it’s better to use CPU affinity.
Juarez: Yes. We create several interrupts for each network card, and each interrupt is pinned to a CPU. So instead of a single CPU handling all the interrupts, you can spread the load across several CPUs. With that, we could increase the throughput to almost the limit of the network interface card.
Leandro: Yes. Since we have two network cards, we could bond them and have 20 Gbps per machine.
Juarez: [slide 00:17:33] And the main takeaway is that we didn’t have to tune NGINX by itself, but the operating system. NGINX worked like a charm.
17:50 Benefits from NGINX and HLS

Leandro: And just to summarize. By moving to HLS and using NGINX we got rid of the problem of the port being blocked by firewalls because we are using port 80 for HTTP.
NGINX gave us amazing caching. It also gave us easy scalability, because it’s just matter of spinning up another machine or virtual server. We were able to achieve a better user experience because HLS was better at determining which bitrate stream the user should get. And we also loved the instrumentation thing, that let us see what was going on on the farm.
18:43 Our Farm

And this is the farm we had – just 80 nodes, and we use CentOS.
This blog post is the first of two parts, and is focused on using NGINX for streaming video delivery and caching. Part II is coming soon and will talk about how the Globo.com team built microservices for its video platform using NGINX with the LUA third party module.
The post Globo.com’s Live Video Platform for FIFA World Cup ’14- Part I: Delivery and Caching appeared first on NGINX.
Source: Globo.com’s Live Video Platform for FIFA World Cup ’14- Part I: Delivery and Caching


Leave a Reply