GPU 딥러닝 모델 학습을 위한 Amazon EC2 스팟 인스턴스 활용법
여러분이 데이터 세트를 수집하고, 심층 신경망 아키텍처를 설계하고, 학습 루틴 코드를 작성을 완료 하셨다면 지금부터는 강력한 GPU 인스턴스를 사용해 여러 epoch에 걸쳐 대규모 데이터 세트를 이용한 학습을 실행할 차례입니다. 여러분은 이미 NVIDIA Tesla V100 GPU에 기반한 Amazon EC2 P3 인스턴스가 컴퓨팅 집약적인 딥러닝 학습 작업에 적합하다는 사실을 알고 있지만 예산이 빠듯한 관계로 가능한한 학습 비용은 낮추고 싶습니다.
몇 시간 또는 며칠에 걸쳐 학습 작업을 실행하는 딥러닝 연구자 및 개발자라면, 스팟 인스턴스 요금을 통해 훨씬 경제적인 비용으로 고성능 CPU를 이용할 수 있습니다. 스팟 인스턴스를 사용하면 온디맨드 요금에 비해 대폭 할인된 가격으로 여분의 Amazon EC2 컴퓨팅 용량에 액세스할 수 있습니다. 인스턴스 및 리전별 최근 요금 목록을 보려면 스팟 인스턴스 어드바이저를 방문하십시오. 스팟 인스턴스와 온디맨드 인스턴스 사이의 주요 차이점을 알아보려면 이 Amazon EC2 사용 설명서를 검토해 보시기 바랍니다.
스팟 인스턴스는 딥러닝 워크플로우에 적합하지만, 온디맨드 인스턴스와 비교했을 때 스팟 인스턴스를 사용할 경우 몇 가지 문제가 있습니다. 첫 번째는, 스팟 인스턴스는 미리 확보될 수 있으며, 불과2분 전에 통지하여 종료될 수 있습니다. 즉, 인스턴스에서 학습 작업을 완료 단계까지 실행할 수 있을지에 대해 신뢰할 수 없습니다. 따라서 시간에 민감한 워크로드에 대해서는 권장되지 않습니다. 두 번째는, 학습 진행 상황이 적절히 저장되지 않은 경우 인스턴스 종료로 인해 데이터가 손실될 수 있습니다. 세 번째는, 스팟 인스턴스를 시작한 후 애플리케이션을 중단하지 않도록 결정한 경우 사용자의 유일한 옵션은 스팟 인스턴스를 중지하고 온디맨드나 예약 인스턴스로 다시 시작하는 것뿐입니다.
이러한 문제를 해결하기 위해 여기에서는 스팟 중단이 발생한 경우 학습 진행 상황 손실을 최소화하면서 딥러닝 학습 워크플로우를 위해 스팟 인스턴스를 설정하는 방법에 대한 단계별 자습서를 제공합니다. 제 목표는 다음 특성을 반영한 설정을 구현하는 것입니다.
- 컴퓨팅, 스토리지, 코드 아티팩트를 분리하고, 컴퓨팅 인스턴스에 상태를 저장하지 않습니다. 그러면 인스턴스가 종료되고 대체된 경우에도 간단한 복구와 학습 상태 복원을 보장합니다.
- 데이터 세트, 학습 진행 상황(체크포인트) 및 로그에 대해 전용 볼륨을 사용합니다. 이 볼륨은 영구 볼륨이며, 인스턴스 종료로 영향을 받지 않아야 합니다.
- 학습 코드에 대해 버전 제어 시스템(예: Git)을 사용합니다. 학습을 시작/재개하려면 이 리포지토리를 복제해야 합니다. 그러면 인스턴스가 종료되어도 추적 기능을 통해 코드 변경 사항이 손실되지 않도록 방지할 수 있습니다.
- 학습 스크립트에 대한 코드 변경을 최소화합니다. 이를 통해 학습 스크립트를 독립적으로 개발하고, 학습 코드 외부에서 백업 및 스냅샷 작업을 수행할 수 있습니다.
- 모든 작업을 자동화합니다. 종료 후 대체 인스턴스 생성, 시작 시 데이터 세트 및 체크포인트 EBS 볼륨의 연결, 가용 영역에서 볼륨 이동, 인스턴스 상태 복원 수행, 학습 재개, 학습 종료 시 인스턴스 종료 작업을 자동화합니다.
TensorFlow 및 AWS Deep Learning AMI를 사용하여 스팟 인스턴스에서 딥러닝 수행
이 예제에서는 스팟 인스턴스와 AWS Deep Learning AMI를 사용하여 CIFAR10 데이터 세트에서 ResNet50 모델을 학습합니다. 저는 AWS Deep Learning AMI 버전 21에서 사용 가능한 CUDA 9로 구성된 TensorFlow 1.12를 사용합니다. AWS Deep Learning AMI는 자주 업데이트되므로, 먼저 AWS Marketplace에서 학습 코드와 호환 가능한 최신 버전을 사용하는지 확인하십시오. TensorFlow 1.13 및 CUDA 10의 경우 이 AWS Deep Learning AMI를 사용합니다.
저는 여기에서 딥러닝 학습 작업에 대한 스팟 플릿 요청을 설정하는 방법을 보여드릴 것입니다. 그러면 사용자의 특정 데이터 세트 및 모델에 맞는 방법을 구현할 때 이 방법을 시작점으로 활용할 수 있습니다.
이 과정에서는 사용자가 다음 전제 조건을 충족했다고 가정합니다.
- AWS 계정이 있고 호스트에 AWS CLI 도구가 설치되어 있음
- Python과 하나 이상의 딥러닝 프레임워크에 친숙함
구현 세부 정보를 검토하면 필요한 모든 정보를 배울 수 있습니다. 모든 코드, 구성 파일 및 AWS CLI 명령은 GitHub에서 사용 가능합니다.
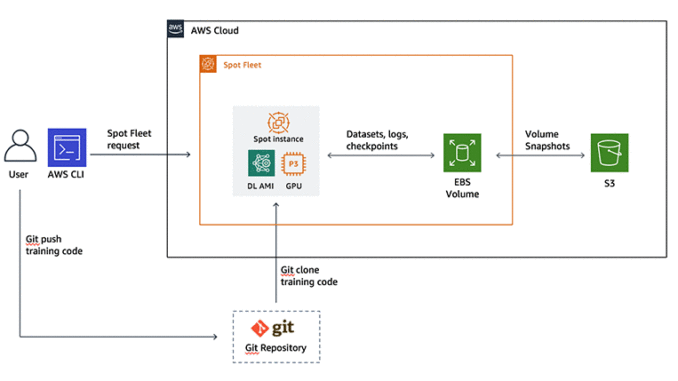
다음과 같은 AWS 및 오픈 소스 서비스/개념을 사용합니다. 그림 1에서는 예제에서 이 모든 요소를 적절히 조합해 사용하는 방법을 보여줍니다.
- AWS CLI: CLI를 사용하여 AWS 서비스와 상호 작용합니다. CLI에서 수행할 수 있는 모든 작업은 AWS 콘솔에서도 수행할 수 있습니다. CLI를 사용하면 자동화가 가능하고, 바로 이 점이 이 예제에서 제가 추구하는 목표이기도 합니다.
- Amazon EC2 스팟 인스턴스 및 스팟 인스턴스 요청: 스팟 요청을 통해 지정된 스팟 인스턴스만 실행되도록 합니다. 스팟 플릿은 대상 용량을 충족하도록 스팟 요청을 제출하고 중단된 인스턴스를 자동으로 보충합니다.
- AWS Deep Learning AMI: 딥러닝 프레임워크가 미리 설치된 Amazon Machine Image입니다. 이 예제에서는 학습을 위해 GPU 가속을 지원하는 TensorFlow 프레임워크를 사용합니다.
- Amazon Elastic Block Storage(EBS): 데이터 세트, 체크포인트 및 로그를 저장할 영구 볼륨입니다. 이 볼륨은 현재 실행 중인 인스턴스에 연결할 수 있습니다.
- Amazon EBS 스냅샷: 스냅샷을 사용하면 Amazon EBS 볼륨의 데이터를 Amazon S3에 백업할 수 있습니다. 스냅샷은 새 EBS 볼륨으로 데이터를 복원하는 데 필요한 모든 정보를 포함하며, 새 가용 영역으로 볼륨을 마이그레이션하는 데 사용할 수 있습니다.
- Amazon EC2 사용자 데이터 및 인스턴스 메타데이터: 인스턴스가 시작되면 볼륨 연결, 학습 시작 및 정리와 같은 작업을 수행하기 위해 사용자 데이터 쉘 스크립트를 실행할 수 있습니다. 인스턴스 메타데이터를 통해 인스턴스는 사용자 데이터 쉘 스크립트와 함께 사용할 인스턴스 ID와 같이 해당 인스턴스에 대한 자체 정보를 쿼리할 수 있습니다.
- Amazon IAM 역할 및 정책: 자동으로 AWS 서비스를 사용하도록 EC2 인스턴스 권한을 부여합니다. 모든 것을 자동화하는 것이 핵심입니다.
그림 1: 딥러닝 워크플로우에서 스팟 인스턴스 사용에 대한 참조 아키텍처
1단계: 범용 인스턴스를 사용하여 데이터 세트 및 체크포인트에 대한 전용 EBS 볼륨 설정
첫 번째 단계는 로그 및 기타 메타데이터와 같이 영구적이어야 하는 데이터 세트, 체크포인트 및 기타 정보를 저장할 전용 EBS 볼륨을 설정하는 것입니다. 이 단계는 한 번만 수행됩니다. 그래서 처음에는 온디맨드 m4.xlarge 인스턴스로 시작합니다. 데이터 세트가 작고 준비 중에 사전 처리 단계로 수행하지 않으려는 경우 메모리와 성능을 더 적게 소비하며(비용이 더 줄어들 수 있음) 인스턴스를 시작할 수 있습니다. 이미지를 트랜스코딩하거나 기타 멀티스레드 사전 처리 루틴을 실행하려는 경우 GPU 지원 또는 컴퓨팅에 최적화된 CPU 인스턴스를 선택합니다.
AWS CLI를 사용하여 터미널에서 다음 명령을 실행합니다. 아래 나온 모든 명령은 MacOS에서 테스트되었습니다.
image-id는 Deep Learning AMI Ubuntu 인스턴스를 나타냅니다. 인스턴스에 대한 SSH 연결을 허용하려면 보안 그룹, 키 ID 및 서브넷 ID를 업데이트해야 합니다. 자세한 내용은 이 문서 페이지를 참조하십시오.
중요: 특정 가용 영역에서 서브넷을 생성하고 선택한 내용을 기억해 두십시오. EBS 볼륨은 동일한 서브넷의 인스턴스에만 연결할 수 있습니다. 관련 설명은 그림 1을 참조하십시오. 이 예제에서는 설정을 위해 가용 영역으로 us-west-2b를 사용합니다. 3단계에서는 EBS 스냅샷을 사용하여 여러 가용 영역 간에 EBS 볼륨 마이그레이션을 자동화하는 방법을 보여줍니다.
이 예제에서, 기울임꼴로 표시된 모든 항목은 사용자 설정에 특정한 값으로 대체해야 하며, 나머지는 그대로 복사할 수 있습니다.
다음으로, 데이터 세트 및 체크포인트에 대한 EBS 볼륨을 생성합니다. 여기에서는 100GiB를 요청합니다. 여러분은 데이터 세트 요구에 적합한 값을 선택해야 합니다. EBS 볼륨은 인스턴스와 동일한 가용 영역에 있어야 합니다. 볼륨을 생성한 후에는 인스턴스에 연결합니다. run-instances 및 create-volume 명령 출력에서 ID 세부 정보를 지정합니다.
문서의 단계에 따라 SSH를 사용하여 인스턴스에 연결하고 연결된 볼륨을 포맷하고 마운트합니다. 이 예제에서는 이름이 /dltraining인 루트에서 마운트 지점 디렉터리를 사용합니다.
이 단계는 한 번만 수행합니다. 3단계 후반으로 가면, 학습을 위해 데이터 세트 및 체크포인트를 사용할 수 있도록, 새로운 각 스팟 인스턴스가 시작 시 볼륨을 자동으로 자체 마운트하는 방법을 확인할 수 있습니다.
이 예제에서는 다음 경로를 사용합니다.
- 데이터 세트:
/dltraining/datasets - 학습 진행 상황 체크포인트:
/dltraining/checkpoints
이 예제를 따라 진행하면 이 디렉터리를 생성하고 빈 상태로 둘 수 있습니다. 학습 스크립트 ec2_spot_keras_training.py는 Keras를 사용하여 CIFAR10 데이터 세트를 다운로드하며, 최초 학습이 시작됩니다.
다음 명령을 사용하여 이 인스턴스를 종료할 수 있습니다. 이제 볼륨 설정이 완료되었으며, 이 볼륨이 생성된 가용 영역에서 영구 볼륨이 됩니다.
2단계: 인스턴스 권한을 부여할 IAM 역할 및 정책 생성
클라우드를 처음 접하는 경우 AWS Identity and Access Management(IAM) 개념도 새로울 수 있습니다. IAM 역할 및 정책은 자동으로 다른 AWS 서비스에 액세스하도록 허용하는 특정 권한을 인스턴스에 부여하는 데 사용됩니다.
저는 스팟 인스턴스를 사용하여 학습 중에 1단계에서 생성한 EBS 볼륨의 데이터 세트와 체크포인트에 액세스하려고 합니다. 하지만 인스턴스와 동일한 가용 영역의 볼륨만 인스턴스에 연결할 수 있습니다. 볼륨과 인스턴스가 서로 다른 가용 영역에 있으면 Amazon S3에 저장된 볼륨의 스냅샷을 사용하여 새 볼륨을 생성해야 합니다.
이 모든 단계는 AWS CLI 및 사용자 데이터 bash 스크립트를 사용하여 인스턴스를 시작할 때 수행할 수 있으며, 3단계에서 그 방법을 확인할 수 있습니다. 다음은 인스턴스를 시작할 때 실행해야 하는 모든 AWS CLI 명령입니다.
- 이름 태그가 DL-datasets-checkpoints인 볼륨 쿼리(하나만 존재해야 함)
- 태그가 DL-datasets-checkpoints-snapshot인 이 볼륨의 스냅샷 생성
- 인스턴스와 볼륨이 동일한 가용 영역에 있으면 인스턴스에 볼륨 연결
- 인스턴스와 볼륨이 서로 다른 가용 영역에 있으면, 이름이 DL-datasets-checkpoints인 인스턴스의 가용 영역에서 스냅샷을 통해 새 볼륨을 생성하고 인스턴스에 연결합니다. 하나의 사본만 존재하도록 다른 가용 영역의 볼륨은 삭제합니다.
- 학습이 완료되면 스팟 플릿 요청을 취소하고 모든 학습 인스턴스를 종료합니다.
인스턴스에서 이러한 작업을 수행할 수 있도록 자동으로 이를 수행할 권한을 인스턴스에 부여해야 합니다. 이 방법에서는 잠재적으로 남용될 소지가 있으므로, 사용자인 제가 갖고 있는 동일한 모든 권한을 인스턴스에 부여하지 않습니다.
먼저, IAM 역할이라고 하는, Amazon EC2 인스턴스에 대한 역할부터 생성합니다. 이후에는 정책이라고 하는 항목을 생성하여 이 역할에 특정 권한을 부여합니다. 다음 명령을 실행하여 새 IAM 역할을 생성합니다. 여기서 역할 이름은 DL-Training이라고 지정했지만, 다른 이름을 선택해도 좋습니다.
다음으로, 인스턴스에 다음 권한을 부여하는 정책을 생성해 연결합니다.
- 볼륨 설명, 생성, 연결 및 삭제
- 볼륨에 대한 스냅샷 생성
- 스팟 인스턴스 설명
- 스팟 플릿 요청 취소 및 인스턴스 종료
사용자 애플리케이션에서 사용하려는 경우 다른 AWS 서비스에 액세스할 권한을 부여할 수 있습니다. 일반적으로 작업이 구체적일수록 인스턴스 작업 효율성도 높아집니다. 권한은 예제 GitHub 리포지토리의 ec2-permissions-dl-training.json 파일에 있습니다.
그리고 다음을 실행하여 정책을 생성하고 이를 IAM 역할에 연결합니다.
attach-role-policy 명령에서 <account_id>를 사용자의 AWS 계정 ID로 대체해야 합니다.
3단계: EC2 사용자 데이터 bash 스크립트 생성
다음으로, 학습을 실행하려는 인스턴스에 대한 세부 정보를 사용하여 시작 사양 파일을 생성합니다. 이 예제에서는 p3.2xlarge를 사용하려고 합니다. 다중 GPU 기반 학습 작업을 실행 중이라면 GPU가 더 많은 인스턴스를 요청할 수 있습니다. 여기서, 다중 GPU 기반 작업은 동일한 인스턴스에 있는 다중 GPU를 말합니다. 현재 단일 인스턴스에서 가져올 수 있는 최대 GPU 수는 p3.16xlarge 또는 p3dn.24xlarge에서 8개 GPU입니다. 분산/다중 노드 학습 사용 사례는 향후 블로그 게시물에서 다룰 예정입니다.
2단계에서 설명한 대로, Amazon EC2에서는 시작 시 실행할 인스턴스로 사용자 데이터 쉘 스크립트를 전달할 수 있습니다. 이제 사용자 데이터 쉘 스크립트를 살펴보겠습니다. 전체 스크립트(user_data_script.sh)는 GitHub에서 사용할 수 있습니다.
파일에는 4개의 주요 섹션이 있습니다.
인스턴스 ID 및 쿼리 볼륨 가져오기
이 섹션에서, 스크립트는 이 스크립트가 실행 중인 ID 인스턴스에 액세스하기 위해 인스턴스 메타데이터 API를 쿼리합니다. 그리고 이 정보를 사용하여 태그가 DL-datasets-checkpoints인 데이터 세트 및 체크포인트 볼륨을 검색합니다.
볼륨 및 인스턴스가 동일한 가용 영역에 있는지 확인
이 섹션에서는, 스크립트가 볼륨 및 인스턴스가 동일한 가용 영역에 있는지 확인합니다. 다른 가용 영역에 있으면 먼저 Amazon S3에서 볼륨의 특정 시점 스냅샷을 생성합니다. 스냅샷이 생성되면 볼륨을 삭제하고 인스턴스의 가용 영역에서 스냅샷을 통해 새 볼륨을 생성합니다. 그림 2에서는 두 개의 패턴을 보여줍니다.
aws ec2 wait 명령을 사용하면 다음 명령으로 진행하기 전에 스냅샷 및 볼륨 생성 완료를 보장합니다.
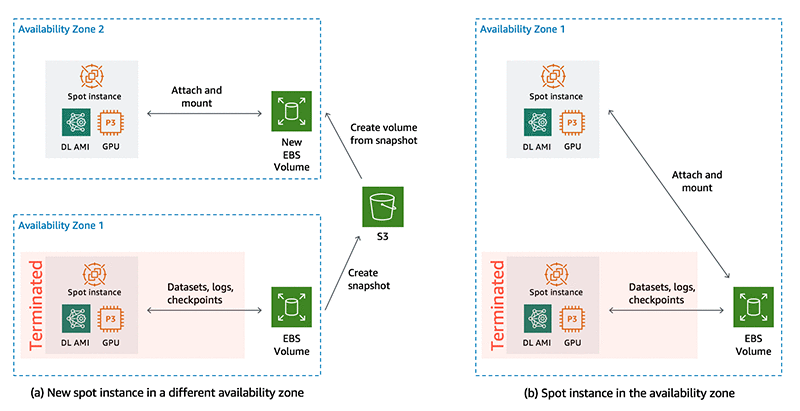
그림 2: 스팟 인스턴스 종료 시 다른 가용 영역에서 새 스팟 인스턴스가 시작되면 (a) EBS 볼륨 스냅샷이 S3에 저장되고 인스턴스의 가용 영역에서 스냅샷을 통해 새 볼륨이 생성됩니다. 볼륨과 동일한 가용 영역에서 새 스팟 인스턴스가 시작되면 (b) 동일한 EBS 볼륨이 새 인스턴스에 연결됩니다.
볼륨 연결 및 마운트: 이 섹션에서는, 스크립트가 먼저 인스턴스와 동일한 가용 영역에 있는 볼륨을 연결합니다. 그러면 /dltraining의 마운트 지점 디렉터리에 연결된 볼륨을 마운트합니다. 그리고 사용자 데이터 스크립트가 루트로 실행되므로 Ubuntu 사용자에 대한 소유권을 업데이트합니다.
학습 스크립트 가져오기: 이 섹션에서는, 스크립트가 학습 코드 git 리포지토리를 복제합니다.
학습 시작/재개: 스크립트가 tensorflow_p36 Conda 환경을 활성화하고 Ubuntu 사용자로 학습 스크립트를 실행합니다. 학습 스크립트는 Amazon EBS 볼륨의 데이터 세트 로드 작업과 체크포인트에서 학습 재개 작업을 관리합니다. 4단계에서는 학습 스크립트에 필요한 수정을 시작합니다.
정리: 학습이 완료되면 스크립트는 현재 인스턴스에 연결된 스팟 플릿 요청을 취소하여 정리합니다. 또한 cancel-spot-fleet-requests를 통해 플릿이 관리하는 인스턴스를 종료할 수 있습니다.
4단계: 스팟 플릿 요청 구성 파일 생성
다음으로, 대상 용량(예제에서는 인스턴스 1개), 인스턴스에 대한 시작 사양 및 지불할 용의가 있는 최대 가격을 포함하는 스팟 플릿 구성 파일을 생성합니다. 스팟 플릿은 대상 용량을 충족하도록 요청을 제출하고 중단된 인스턴스를 자동으로 보충합니다.
LaunchSpecifications 섹션 아래에 두 개의 서로 다른 사양을 포함하였습니다.
- us-west-2 리전 내 모든 가용 영역에 배치할 수 있는 p3.2xlarge 인스턴스 유형
- us-west-2 리전 내 모든 가용 영역에 배치할 수 있는 p2.xlarge 인스턴스 유형
스팟 플릿 구성은 예제 GitHub 리포지토리의 spot_fleet_config.json 파일에 있습니다. 스팟 플릿 구성 파일을 사용하면 인스턴스 유형과 가용 영역을 탄력적으로 조합하여 사용할 수 있습니다. 사용자의 학습 스크립트에서 NVIDIA Tesla V100의 혼합 정밀도 Tensor Core를 사용한다면 인스턴스 유형을 p3.2xlarge로만 제한할 수도 있습니다. NVIDIA Tesla K80 기반 p2.xlarge는 단일 정밀도(FP32) 및 배정밀도(FP64)만 지원하며, 딥러닝 학습에 대해 V100보다 느리지만 더 저렴합니다. 요구 사항에 적합한 조합을 선택합니다.
수동으로 진행 상황을 확인하고 디버깅하는 경우에 SSH를 통해 인스턴스에 연결할 수 있는 보안 그룹을 사용하고, 인증을 위해 키 페어 이름을 사용해야 합니다. IAM 인스턴스 프로파일 아래에서, 2단계에서 생성한 IAM 역할을 업데이트하여 필요한 권한을 인스턴스에 부여합니다.
스팟 플릿 요청을 사용하려면 다음 명령을 실행하여 IAM 플릿 역할을 생성합니다.
위 구성의 짧은 코드 조각에서, 사용자 데이터 아래에 있는 base64_encoded_bash_script 텍스트는 base64로 인코딩된 사용자 데이터 쉘 스크립트로 대체해야 합니다. 이를 수행하기 위해 Mac 및 Linux 기반 OS에서 사용 가능한 base64 유틸리티를 사용할 수 있습니다. 다음은 Mac에서 작동합니다. Linux에서 작동하려면 -b를 -w로 대체하여 줄 바꿈을 제거합니다. sed 명령은 base64_encoded_bash_script 문자열의 모든 항목을 base64로 인코딩된 bash 스크립트로 대체합니다.
5단계: 딥러닝 학습 스크립트 업데이트
마지막 단계에서는, 데이터 세트를 연결된 Amazon EBS 볼륨에서 로드하고 이 볼륨에 체크포인트를 저장하도록 딥러닝 학습 스크립트를 업데이트합니다. 이 예제에서는 CIFAR10 데이터 세트에서 ResNet50 모델을 학습합니다. 일반적인 딥러닝 학습 스크립트는 다음 단계를 수행할 수도 있습니다. 아래의 유사 코드에는, 우리가 다룬 설정과 함께 사용하도록 학습 스크립트에서 수정해야 하는 변경 사항이 나와 있습니다.
요약하면,
- 마운트된 Amazon EBS 볼륨(예제에서는,
/dltraining)에서 데이터를 로드합니다. - 체크포인트가 있는지 확인하고, 체크포인트를 로드하고 epoch 번호를 업데이트하여 학습을 재개합니다. 그렇지 않으면, 모델 아키텍처를 정의하고 처음부터 학습을 새로 시작합니다.
- 학습 루프에서 종료 공지가 발행되었는지 확인합니다. 그렇다면, 손상되거나 불완전한 체크포인트를 방지하기 위해 체크포인트 설정 중에 종료되지 않도록 학습을 일시 중지합니다.
- 종료 공지가 발행되지 않은 경우
/dltraining/checkpoints/에 모델 체크포인트를 저장합니다.
이 예제의 학습 스크립트는 ec2_spot_keras_training.py이며, 예제 리포지토리에서 사용 가능합니다. 다음은 우리가 다룬 학습 스크립트의 짧은 코드 조각입니다. load_checkpoint_model() 함수는 학습을 재개하도록 최신 체크포인트를 로드합니다.
저는 TensorFlow 백엔드에서 Keras를 사용했기 때문에 학습 루프를 명시적으로 작성하지 않아도 되었습니다. Keras에서는 각 epoch 이후에 체크포인트를 저장하고 진행 상황을 기록하는 간편한 콜백 함수를 제공합니다.
참고: TensorFlow의 로우 레벨 API, PyTorch 또는 기타 프레임워크를 사용하여 사용자만의 학습 루프를 구현하는 경우 사용자가 진행 상황 체크포인트를 관리해야 합니다. 무엇을 할지 잘 모르는 경우 매우 까다로울 수 있습니다. 학습을 적절히 재개하려면 (1) 모델을 재정의하기 위해 모델 아키텍처, (2) 현재 epoch 종료 시 모델의 완료된 epoch 번호와 가중치, (3) 손실 함수, 최적화 도구, 학습 비율 일정 등의 학습 하이퍼 파라미터 (4) epoch 종료 시 최적화 도구 상태를 저장해야 합니다.
진행 상황 체크포인트를 설정하고 종료 상태를 확인하기 위해 사용하는 Keras 콜백은 다음과 같습니다.
6단계: 학습을 시작하도록 스팟 요청 시작
이제 4단계에서 생성한 spot_fleet_config.json 구성 파일을 사용하여 스팟 플릿 요청을 제출할 준비가 되었습니다.
종합
지금까지 많은 코드, 구성 파일, AWS CLI 명령을 소개했습니다. 그림 3에서는 이러한 코드와 구성 아티팩트를 조합하는 방법을 보여줍니다. 이러한 요소가 모두 어떻게 연결되었는지 더 잘 파악할 수 있도록 그 과정을 살펴보겠습니다.
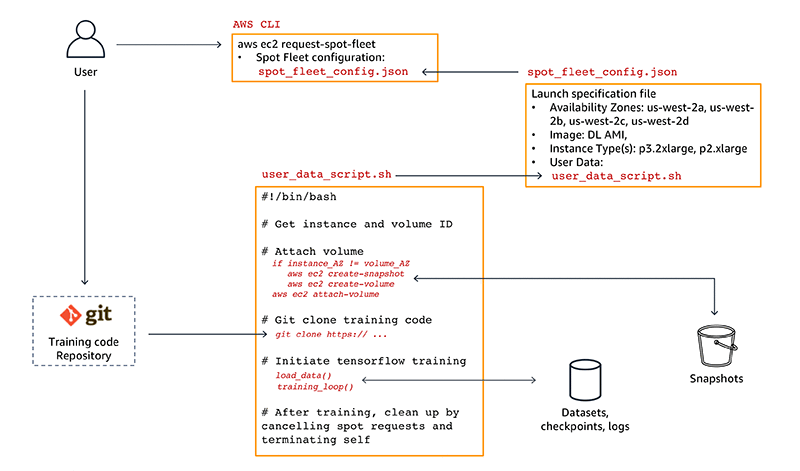
그림 3: 데이터, 코드, 구성 아티팩트 종속성 차트
여러분도 시작해 보세요!
딥러닝 연구자나 개발자는 먼저 로컬로, 아니면 저렴한 CPU 전용 Amazon EC2 온디맨드 인스턴스에서 AWS Deep Learning AMI를 사용하여 모델 프로토타입을 만들고 개발합니다. GPU에서 학습을 실행할 준비가 되었다면 학습 스크립트를 Git 리포지토리로 옮겨보십시오.
그리고 6단계에서 보여준 aws ec2 request-spot-fleet 명령을 사용하여 스팟 요청을 제출합니다. 그러면 이제 모두 작동됩니다.
스팟 요청은 스팟 플릿 구성 파일 spot_fleet_config.json을 사용하여 원하는 스팟 인스턴스 유형을 시작합니다. 이 예제에서는 us-west-2 리전의 가용 영역에 있는 p3.2xlarge 인스턴스에서 학습 작업을 실행합니다. 학습 스크립트는 GPU에 최적화된 TensorFlow 프레임워크를 포함하는, AWS Deep Learning AMI를 사용하여 이미지로 생성된 인스턴스에서 실행됩니다.
스팟 플릭 구성 파일에는 user_data_script.sh bash 스크립트 파일도 있습니다. 사용자 데이터 bash 스크립트는 시작 시 스팟 인스턴스에서 실행됩니다. 이 스크립트는 데이터 세트 및 체크포인트 볼륨 마운트, 학습 스크립트 복제 및 3단계에서 보여준 학습 시작 작업을 관리합니다.
용량이 부족하거나 비싼 스팟 인스턴스 요금 때문에 스팟 중단이 발생하면, 인스턴스가 종료되고 데이터 세트 및 체크포인트 Amazon EBS 볼륨이 분리됩니다. 그리고 스팟 플릿은 중단된 인스턴스를 자동으로 보충하는 또 다른 요청을 제출합니다.
요청이 다시 이행되면 새 스팟 인스턴스가 시작되고, 시작 시 user_data_script.sh를 실행합니다. 이 스크립트는 데이터 세트 및 체크포인트 볼륨을 쿼리합니다. 볼륨 및 인스턴스가 서로 다른 가용 영역에 있으면, 먼저 볼륨의 스냅샷을 생성하고 현재 인스턴스의 가용 영역에 스냅샷에 기반한 새 볼륨을 생성합니다. 단일 출처를 보장하기 위해 이전 가용 영역의 볼륨은 삭제됩니다.
그리고 스크립트는 인스턴스에 볼륨을 연결하고 최신 체크포인트부터 학습을 재개합니다. 학습이 완료되면 스팟 플릿 요청이 취소되고 현재 실행 중인 인스턴스는 종료됩니다.
더 비싼 최대 스팟 인스턴스 요금을 지정하거나 인스턴스 유형 또는 가용 영역을 변경하려는 경우 aws ec2 cancel-spot-fleet-requests를 실행하고 업데이트된 스팟 플릿 구성 파일 spot_fleet_config.json에서 새 요청을 시작하여 실행 중인 스팟 플릿 요청을 취소하기만 하면 됩니다.
요약
본 게시물은 스팟 인스턴스를 사용하여 온디맨드 인스턴스보다 훨씬 더 저렴한 비용으로 GPU 인스턴스에서 딥러닝 학습 실험을 실행하는 방법에 대한 개요을 설명합니다.
이 블로그 게시물에 나온 설정은 다음과 같이 고급 딥러닝 워크플로우를 다루도록 확장할 수 있습니다.
- 다중 GPU 학습. 다중 GPU 학습을 지원하도록 학습 스크립트 업데이트.
- 하위 epoch 세분화 체크포인트 지정 및 재개. 이 예제에서, 체크포인트는 각 epoch가 끝나는 시점에만 저장됩니다. epoch를 완료하는 데 더 오래 걸리는 큰 데이터 세트와 복잡한 모델의 경우 체크포인트를 자주 지정하면 중단 중에 진행 상황 손실을 최소화합니다.
- 다중 병렬 실험. 서로 다른 하이퍼 파라미터를 통해 여러 개의 독립된 학습 작업을 실행하도록 스팟 플릿 대상 용량을 늘립니다.
본 게시물이 여러분에게 도움이 되었기를 바랍니다. 궁금한 점이나 의견이 있으시면 아래 댓글 섹션을 이용해 주십시오. 스팟 학습을 직접 구현해 보십시오!
작성자 소개
 Shashank Prasanna 는 Amazon Web Services(AWS)에 근무하는 AI 및 Machine Learning 기술 에반젤리스트이며, 엔지니어, 개발자, 데이터 과학자가 기계 학습에 관한 문제를 해결할 수 있도록 도움을 주는 데 주력하고 있습니다. AWS에 입사하기 전에는, NVIDIA, MathWorks(MATLAB & Simulink의 제작사), 그리고 Oracle에서 근무하며, 제품 마케팅, 제품 관리, 소프트웨어 개발 역할을 맡았습니다.
Shashank Prasanna 는 Amazon Web Services(AWS)에 근무하는 AI 및 Machine Learning 기술 에반젤리스트이며, 엔지니어, 개발자, 데이터 과학자가 기계 학습에 관한 문제를 해결할 수 있도록 도움을 주는 데 주력하고 있습니다. AWS에 입사하기 전에는, NVIDIA, MathWorks(MATLAB & Simulink의 제작사), 그리고 Oracle에서 근무하며, 제품 마케팅, 제품 관리, 소프트웨어 개발 역할을 맡았습니다.
이 글은 AWS Machine Learning Blog의 Train Deep Learning Models on GPUs using Amazon EC2 Spot Instances의 한국어 번역으로 정도현 AWS 테크니컬 트레이너가 감수하였습니다.


Leave a Reply