
kakao의 오픈소스 Ep9 – Khaiii : 카카오의 딥러닝 기반 형태소 분석기

“카카오의 오픈소스를 소개합니다” 아홉 번째는 jamie.lim과 자연어 처리 파트 동료들이 함께 개발한 khaiii(Kakao Hangul Analyzer III)입니다.
khaiii는 세종 코퍼스를 이용하여 CNN(Convolutional Neural Network, 합성곱 신경망) 기술을 적용해 학습한 형태소 분석기입니다. 디코더를 C++로 구현하여 GPU 없이도 비교적 빠르게 동작하며, Python 바인딩을 제공하고 있어서 편리하게 사용하실 수 있습니다.
앞으로 오픈소스 생태계를 통해 자연어 처리를 연구하는 분들께 도움이 되고, 또한 부족한 부분에 대해 도움을 받을 수 있으면 좋겠습니다.
아래는 카카오 AI 리포트에 포스팅한 카카오의 딥러닝 기반 형태소 분석기를 옮긴 것입니다.
khaiii는 “Kakao Hangul Analyzer III”의 첫 글자들만 모아 만든 이름으로 카카오에서 개발한 세 번째 형태소 분석기입니다. 두 번째 버전의 형태소 분석기 이름인 dha2(Daumkakao Hangul Analyzer 2)를 계승한 이름이기도 합니다. 기존의 분석기(dha1, dha2)는 규칙 기반으로 동작하기 때문에 사람이 직접 지속적으로 규칙을 입력해야 하지만, khaiii는 데이터 기반으로 동작하기 때문에 기계학습 알고리즘(딥러닝)을 사용합니다.
‘형태소’는 언어학에서 특정한 의미를 가지는 가장 작은 말의 단위로 발화체 내에서 따로 떼어낼 수 있는 것을 말합니다. 즉, 더 분석하면 뜻이 없어지는 말의 단위입니다. 형태소 분석기는 단어를 보고 형태소 단위로 분리해내는 소프트웨어를 말합니다. 이러한 형태소 분석은 자연어 처리의 가장 기초적인 절차로 이후 구문 분석이나 의미 분석으로 나아가기 위해 가장 먼저 이루어져야 하는 과정이라고 볼 수 있습니다1.
데이터 기반
기존 버전이 사전과 규칙에 기반해 분석을 하는 데 반해 khaiii는 데이터(혹은 기계학습) 기반의 알고리즘을 이용하여 분석을 합니다. 학습에 사용한 코퍼스(corpus)는 국립국어원에서 배포한 21세기 세종계획 최종 성과물을 카카오에서 일부 내용을 추가하거나 오류를 수정한 것입니다. 전처리 과정에서 오류가 발생하는 문장을 제외하고 약 85만 개의 문장, 그리고 1천만 개 어절의 코퍼스를 사용하여 학습을 했습니다. 코퍼스와 품사 체계에 대한 구체적인 내용은 뒤에 자세히 설명드리도록 하겠습니다.
알고리즘
기계학습을 위해서는 신경망 알고리즘들 중 CNN(Convolutional Neural Network, 콘볼루션 신경망)을 사용하였습니다. 한국어에서 형태소 분석은 자연어 처리를 위한 가장 기본적인 전처리 과정이므로 속도가 매우 중요한 요소라고 생각합니다. 따라서 자연어 처리에 많이 사용하는 LSTM(Long-Short Term Memory, 장단기 메모리)와 같은 RNN(Recurrent Neural Network, 순환 신경망) 알고리즘은 속도 면에서 활용도가 떨어질 것으로 예상하여 고려 대상에서 제외하였습니다.
음절 기반 모델
한국어 형태소 분석 결과는 원형 복원, 불규칙 활용 등의 이유로 입력 문자와는 형태와 길이가 달라지게 됩니다. 예를 들어, ‘져줄래’와 같은 입력 어절의 분석 결과는 ’지/VV + 어/EC + 주/VX + ㄹ래/EF’와 같이 출력의 길이와 형태 모두 쉽게 예측이 가능하지 않습니다. 이러한 길이의 불일치 문제가 있기에 기계학습 분류기에 기반한 모델의 출력을 설계하는 부분이 중요합니다.
기존에 고전적인 HMM(Hidden Markov Model, 은닉 마르코프 모델), CRF(Conditional Random Fields, 조건부 랜덤 필드) 등의 방법에서는 트라이(TRIE) 사전을 이용하여 들쑥날쑥한 형태의 격자(lattice)를 비터비(Viterbi) 알고리즘을 통해 최적의 경로를 탐색하는 형식으로 많이 접근해 왔습니다.
최근의 딥러닝 방법으로는 번역에서 많이 사용하는 seq2seq(sequence to sequence) 방식을 가장 먼저 생각해 볼 수 있습니다. ‘져, 줄, 래’라는 입력 원문에 대해 인코더를 통해 latent 벡터를 생성하고 디코더를 통해 차례대로 ’지/VV, 어/EC, 주/VX, ㄹ래/EF’라는 출력을 생성하는 것입니다. 여기에 당연히 어텐션(attention) 메커니즘을 적용할 수 있겠습니다. 그러나 seq2seq 방식에서 주로 사용하는 RNN은 속도가 느리고, 입력 음절과 출력 형태소 간의 연결 정보가 끊어져 형태소 분석 결과가 입력의 어느 부분으로부터 나왔는지에 대한 정보가 소실되는 단점이 있습니다. 이에 khaiii는 입력된 각 음절에 대해 하나의 출력 태그를 결정하는 분류 문제로 접근합니다.
음절과 형태소의 정렬
입력의 경우 각각의 음절이 분류 대상입니다. 형태소 분석 결과를 다시 형태소 각각의 음절 별로 나누어 IOB1 방식으로 표현하면 다음과 같습니다.
![[ 표 1 ] 형태소 분석 결과를 각 음절 별로 나누어 IOB1 방식으로 표현한 결과](https://t1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/1oU7/image/ESzWrCKIx10bcJsWhBsKMY2QMyQ.png) 

이렇게 나뉜 각각의 음절들은 아래와 같이 정렬됩니다.
![[ 표 2 ] [ 표 1 ]의 음절들을 정렬한 결과](https://t1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/1oU7/image/EU142ZOXXekH8q_ysOHsdp4RY_Q.png)
‘했’은 ‘I-VX:I-EP:0’라는 복합 태그를 갖는 반면, 나머지 음절들은 단순 태그를 갖습니다. 복합 태그와 단순 태그의 차이는 원형 복원 사전의 사용 여부와 관련이 있습니다. 음절과 복합 태그를 합친 ‘했/I-VX:I-EP:0’를 key로 하여 원형 복원 사전을 검색하면 ‘하/I-VX, 였/I-EP’이라는 복원 정보를 얻게 됩니다. 이렇게 음절과 형태소를 정렬하고 태그로부터 원형을 복원하는 방식은 심광섭 교수님의 논문2에서 기본적인 아이디어를 차용했습니다.
코퍼스에서 모든 음절에 대해 형태소 분석 결과와 정렬을 수행하고, 필요한 경우 복합 태그를 ‘I-VX:I-EP:1’, ‘I-VX:I-EP:2’와 같이 순차적으로 생성하면 자동으로 원형 복원 사전도 생성하게 됩니다. 아래는 이렇게 생성된 학습 데이터의 예시입니다.
![[ 표 3 ] 원형 복원 사전으로 생성된 학습 데이터의 예시](https://t1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/1oU7/image/VISNx8lH8Lt0c-9-DIky58XQTM0.png) 

그리고 아래는 동시에 자동으로 생성된 원형 복원 사전입니다.
![[ 표 4 ] 동시에 자동으로 생성된 원형 복원 사전](https://t1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/1oU7/image/GF1Jy5U2cxOQc7RJPQRgrSelaJY.png)
이렇게 모든 코퍼스 내 어절의 정렬을 마치고 나면 92개의 고정된 단순 태그와 400여 개의 복합 태그가 생성됩니다. 이때 정렬은 수작업으로 작성한 규칙과 매핑(mapping) 사전을 사용해 자동으로 정렬이 이뤄지고, 정렬에 실패한 문장은 학습에서 제외했습니다. 그러면 비로소 각각의 입력 음절에 대해 500여 개의 출력 태그를 판단하는 분류 문제로 접근할 수 있게 됩니다.
윈도우와 문맥
하나의 음절에 대한 태그를 판단하기 위해 윈도우 크기만큼 좌/우로 확장한 문맥을 사용합니다. 예를 들어 ‘프랑스의 세계적인 의상 디자이너 엠마누엘 …’이라는 입력에 대해 ‘세’라는 음절의 태그를 판단하기 위해 윈도우 크기가 7인 문맥은 아래와 같습니다.
![[ 표 5 ] 위의 입력에 대해 ‘세'라는 음절의 태그를 판단하기 위한 윈도우 크기 7의 문맥](https://t1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/1oU7/image/Zv1-KBLayL1aJawlyxyhYdcc-dI.png) 

실질적인 음절 이외에 가상의 음절들도 문맥으로 사용하는데, 이는 아래와 같습니다.
![[ 표 6 ] 문맥으로 사용하는 가상의 음절들](https://t1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/1oU7/image/4pScfTux2KvHatzQGMmWx1php0w.png)
네트워크 구조
![[그림 1] khaiii의 CNN 모델 네트워크 구조](https://t1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/1oU7/image/DXlTnCNYfeYzWIR4kN428VouYKQ.png) 

위 네트워크는 윈도우가 7이고 음절의 임베딩 크기는 5, 커널(kernel)의 크기가 3인 4개의 필터를 사용한 콘볼루션(convolution)입니다. 크기가 [15, 5]인 문맥을 하나의 필터를 거치면 길이가 13인 하나의 벡터가 생성되고 전체에 대해 최댓값 선택(max pooling)을 적용하면 하나의 스칼라 값(scalar value)이 됩니다. 4개의 필터를 사용했으므로 최종적으로 길이가 4인 벡터가 나오게 됩니다.
이런 방식으로 커널의 크기가 {2, 3, 4, 5}에 대해 각각 길이가 4인 벡터를 연결하여 길이가 16인 벡터를 생성합니다. 이것을 히든(hidden) 레이어와 출력 레이어를 거쳐 최종적으로 태그를 결정하게 됩니다.
실제로 베이스(base) 모델의 경우 윈도우 크기가 3, 임베딩 크기는 30입니다. 필터의 출력 차원은 임베딩과 같이 30을 사용했고, {2, 3, 4, 5} 네 종류의 커널을 거치고 나면 길이가 120인 벡터가 생성됩니다. 최종 출력 태그 개수는 500이며 hidden 레이어의 차원은 120과 500의 중간인 310입니다.
이러한 콘볼루션 방식은 김윤님의 문장 분류에 관한 논문3을 참고하였습니다. 문장을 문맥에 대입하고 단어는 음절에 대입하여 적용하면 됩니다.
성능
1. 정확도
CNN 모델의 주요 하이퍼파라미터(hyperparameter)는 분류하려는 음절의 좌/우 문맥의 크기를 나타내는 win 값과, 음절 임베딩의 차원을 나타내는 emb 값입니다. win 값은 {2, 3, 4, 5, 7, 10}의 값을 가지며, emb 값은 {20, 30, 40, 50, 70, 100, 150, 200, 300, 500}의 값을 가집니다. 따라서 이 두 가지 값의 조합은 6 x 10으로 총 60가지를 실험하였고 아래와 같은 성능을 보였습니다. 성능 지표는 정확률과 재현율의 조화 평균값인 F-Score입니다.
![[그림 2] 하이퍼파라미터 win, emb 변화에 따른 F-Score](https://t1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/1oU7/image/C8mVo7TGusVOtv8d94PYFNMgEMM.png) 

파라미터 win의 경우 3 혹은 4에서 가장 좋은 성능을 보이며 그 이상에서는 오히려 성능이 떨어집니다. 파라미터 emb의 경우 150까지는 성능도 같이 높아지다가 그 이상에서는 별 차이가 없습니다. 최상위 5위 중 비교적 작은 모델은 win=3, emb=150으로 F-Score 값은 97.11입니다. 이 모델을 라지(large) 모델이라 명명합니다.
2. 속도
모델의 크기가 커지면 정확도가 높아지기는 하지만 그만큼 계산량 또한 많아져 속도가 떨어집니다. 그래서 적당한 정확도를 갖는 모델 중에서 크기가 작아 속도가 빠른 모델을 기본(base) 모델로 선정하였습니다. F-Score 값이 95 이상이면서 모델의 크기가 작은 모델은 win=3, emb=30, F-Score의 값은 95.30입니다.
속도를 비교하기 위해 1만 문장(총 903KB, 문장 평균 91)의 텍스트를 분석하여 비교했습니다. 기본 모델의 경우 약 10.5초, large 모델의 경우 약 78.8초가 걸립니다.
코퍼스
1. 세종 코퍼스
세종 코퍼스는 국립국어원에서 1998년부터 2007년까지 10년간 진행한 ‘21세기 세종계획’ 사업의 결과물 중 코퍼스 부분을 말합니다. 여기에 있는 다양한 코퍼스 중 형태 분석 말뭉치가 바로 khaiii의 학습 데이터입니다. 세종 코퍼스에 관한 자세한 내용은 황용주 님이 새국어생활에 2016년에 게재한 글4을 참고하시기 바랍니다.
세종 결과물 배포 이후 이를 활용한 여러 논문이 발표되고, 여러 차례 시스템 경진대회의 개최와 오픈소스 바람으로 인해 세종 코퍼스와 품사 집합은 사실상 표준으로 자리 잡고 있습니다. 그러나 1천만 개 어절이라는 방대한 양에 걸맞게 오류 또한 많이 포함하고 있습니다.
2. 문종 프로젝트
카카오에서는 이러한 오류 중 약 30만 개 이상의 어절을 수정하였고 여전히 발견되는 오류를 수정하고 있습니다. 내부적으로는 이것을 ‘문종 프로젝트’라는 이름으로 진행하고 있습니다.5 문종 프로젝트의 결과물을 공개하여 협력을 통해 발전해 가고자 제안6을 드렸지만, 아쉽게도 저작권 문제로 공개할 수 없게 되었습니다.
3. 학습 코퍼스
세종 코퍼스를 수정한 1천만 개의 어절에 더해 저희가 자체적으로 구축한 6만 개 어절의 코퍼스를 합하여 학습에 사용했습니다. 음절과 형태소의 정렬을 거치고 나면 최종적으로 약 85만 개의 문장과 1,003만 개의 어절이 전체 학습 코퍼스가 됩니다. 이 중 1만 개의 문장을 제외한 뒤 학습을 하고, 1만 개의 문장은 다시 5천 개씩 나눠 각각 dev, test 코퍼스로 활용했습니다.
4. 품사 집합
세종 코퍼스의 품사 집합을 대부분 그대로 따르고 있지만, SWK・ZN・ZV・ZZ 4가지만 원본 품사 집합과 다릅니다. ZN・ZV・ZZ는 세종 품사 집합에서 각각 NF・NV・NA와 동일합니다. SWK의 경우 한글 자모만으로 이뤄진 형태소에 한해 사용했고 SW에 완전히 포함되는 하위 품사입니다. NF・NV의 경우 품사는 정의되어 있지만 세종 코퍼스에 한 번도 나타나지 않습니다. 추정 범주에 해당하는 품사는 NA만 나타나고 있는데, 카카오는 한글 자모가 나타나는 경우, 또는 띄어쓰기에 오타가 있는 경우에 한해 제한적으로 사용하였습니다. 아래는 그러한 예시들입니다.
![[ 표 7 ] SWK, ZN, ZV, ZZ 태그가 사용된 예](https://t1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/1oU7/image/1_FgnAhzEVb7FIQd2bxm9LAXRog.png) 

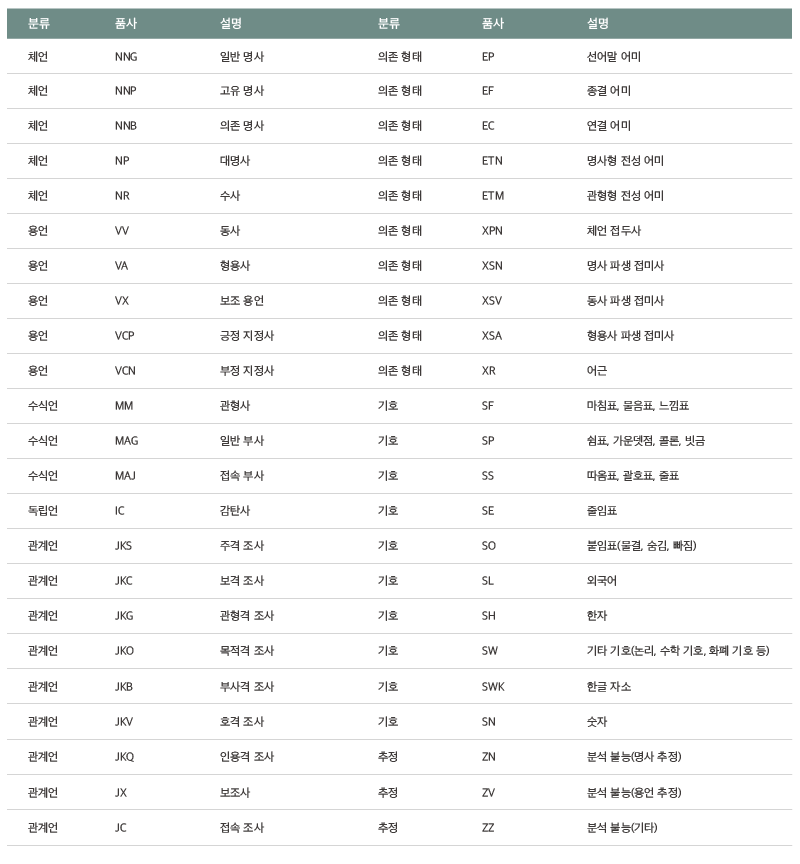
Appendix – 품사 집합
참고문헌
-
참고 https://ko.wikipedia.org/wiki/%ED%98%95%ED%83%9C_%EB%B6%84%EC%84%9D ↩
-
논문 : 심광섭, “음절 단위의 한국어 품사 태깅에서 원형 복원”, 소프트웨어 및 응용 제40권 제3호, 2013. ↩
-
논문 Yoon Kim, “Convolutional Neural Networks for Sentence Classification”, EMNLP, 2014. ↩
-
참고 황용주 외 1인, “21세기 언어 말뭉치 제대로 살펴보기”, 새국어생활, 2016. ↩
-
논문 한경은 외 2인, “공개와 협업을 통한 세종 형태 분석 말뭉치 오류 개선 방법”, 한글 및 한국어정보처리학술대회, 2017. ↩
-
참고 https://ithub.korean.go.kr/user/member/memberQnaView.do?boardSeq=7&articleSeq=94 ↩


Leave a Reply